 Python-爬蟲開發01
Python-爬蟲開發01
爬蟲基本概念
爬蟲的定義
**爬蟲的分類
**
- 通用爬蟲 :通常指搜索引擎的爬蟲
- 聚集爬蟲 :針對特定網站或某些特定網頁的爬蟲
ROBOTS協議
- Robots協議: 也叫robots.txt(統一小寫)是一種存放于網站根目錄下的ASCII編碼的文本文件,它通常告訴網絡搜索引擎的漫游器(又稱網絡蜘蛛),此網站中的哪些內容是不應被搜索引擎的漫游器獲取的,哪些是可以被漫游器獲取的
- 如果將網站視為酒店里的一個房間,robots.txt就是主人在房間門口懸掛的“請勿打擾”或“歡迎打掃”的提示牌。這個文件告訴來訪的搜索引擎哪些房間可以進入和參觀,哪些房間因為存放貴重物品,或可能涉及住戶及訪客的隱私而不對搜索引擎開放。但robots.txt不是命令,也不是防火墻,如同守門人無法阻止竊賊等惡意闖入者

舉例:
-
訪問淘寶網的robots文件: https://www.taobao.com/robots.txt
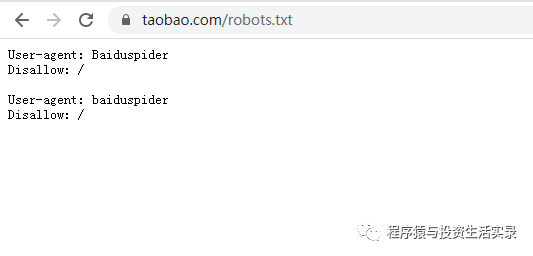 * 很顯然淘寶不允許百度的機器人訪問其網站下其所有的目錄
* 很顯然淘寶不允許百度的機器人訪問其網站下其所有的目錄 -
如果允許所有的鏈接訪問應該是:Allow:/
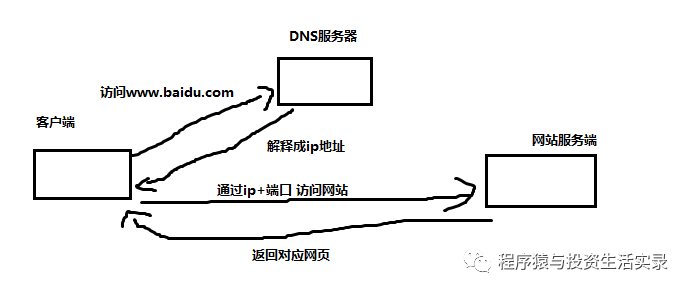
http和https的概念
-
http
- 超文本傳輸協議
- 默認端口號:80
-
https
- HTTP+SSL(安全套接字層)
- 默認端口號:443
-
**HTTPS比HTTP更安全,但是性能更低
**
URL的形式
- sheme://host[:port#]/path/.../[?query-string][#anchor]
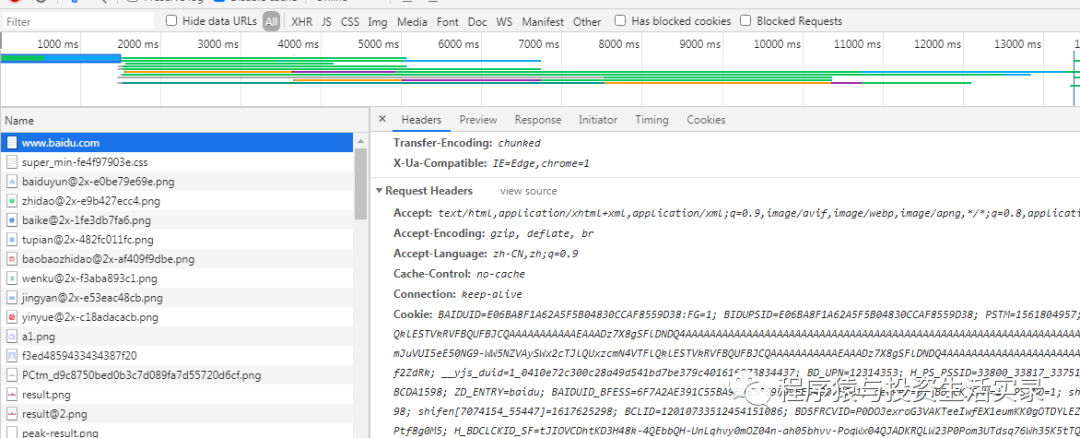
Http常見請求頭
- Host (主機和端口號)
- Connection(鏈接類型)
- Upgrade-insecure-Requests(升級為https請求)
- User-Agent(瀏覽器名稱)
- Accept(傳輸文件類型)
- Referer(頁面跳轉處)
- Accept-Encoding(文件編解碼格式)
- Cookie
- x-requested-with:XMLHttpRequest(是Ajax異步請求)
Http常見響應碼
- 200:成功
- 302:臨時性重定向到新的url
- 404:請求的路徑找不到
- 500:服務器內部錯誤
rquests模塊
requests的官網
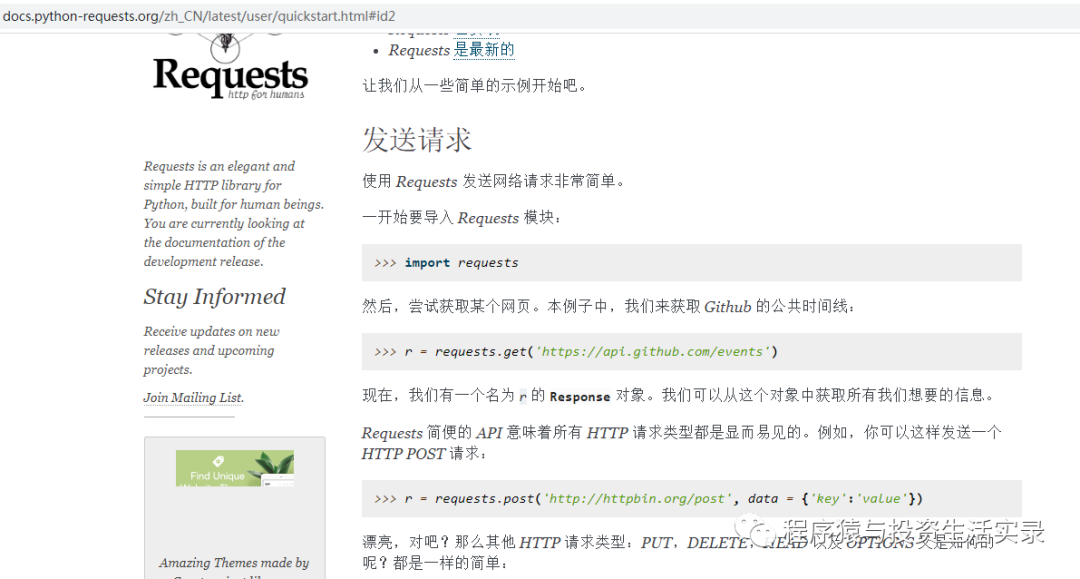
**示例:下載官網上的圖片
**
import requests
url="https://docs.python-requests.org/zh_CN/latest/_static/requests-sidebar.png"
response=requests.get(url)
# 響應狀態碼為200,表示請求成功
if response.status_code==200:
# 生成圖片
with open("aa.png","wb") as f:
f.write(response.content)
response.text 和 response.content 的區別
- response.text
- 類型:str
- 解碼類型:根據http頭部對響應的編碼作出有根據的推測,推測的文本編碼
- 修改編碼的方法:response.encoding='gbk'
- response.content
- 類型:bytes
- 解碼類型:沒有指定
- 修改編碼的方法:response.content.decode('utf-8')
**requests請求帶header
**
- 主要是模擬瀏覽器,欺騙服務器,獲取和瀏覽器一致的內容
- header的數據結構是 字典
示例
import requests
respons=requests.get("http://www.baidu.com")
print(respons.request.headers)
# 設置header 模擬谷歌瀏覽器
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36"
}
respons2=requests.get("http://www.baidu.com",headers=headers)
print(respons2.request.headers)
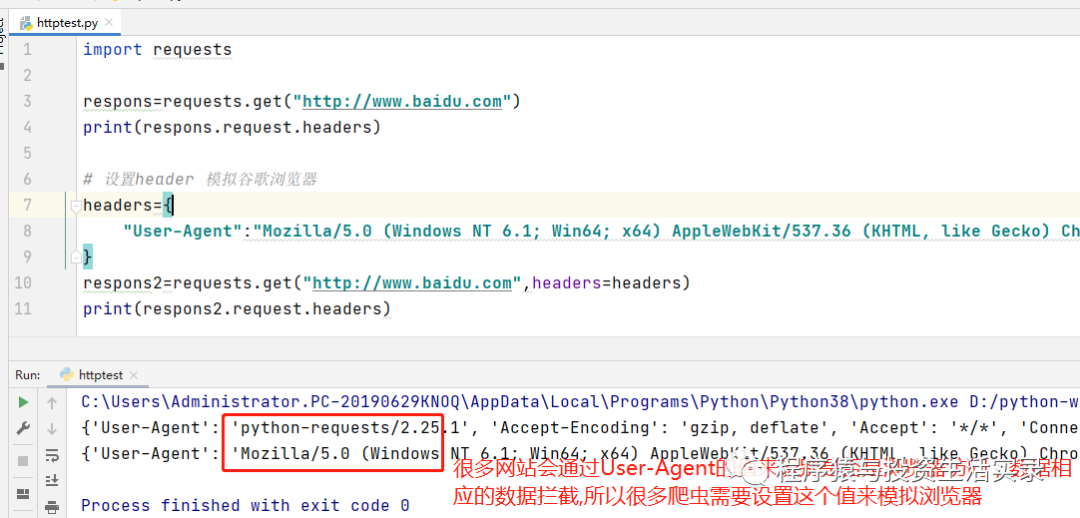
獲取User-Agent的值
帶參數的requests請求
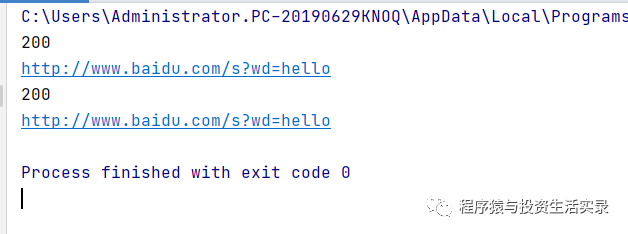
import requests
url="http://www.baidu.com/s?"
# 添加參數
params={
"wd":"hello"
}
# 方式一
respons=requests.get(url,params=params)
# 方式二
respons2=requests.get("http://www.baidu.com/s?wd={}".format("hello"))
print(respons.status_code)
print(respons.request.url)
print(respons2.status_code)
print(respons2.request.url)
requests發送post請求
- 語法
- response=requests.post("http://www.baidu.com/",data=data,headers=headers)
- data的數據結構是 字典
- 示例
import requests
url="https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=LST___t=1617719326771"
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36"
}
params={
"curr_iss_amt": 20
}
respons=requests.post(url,data=params,headers=headers)
print(respons.content.decode())
requests使用代理方式
- 使用代理的原因
- 讓服務器以為不是同一個客戶端請求
- 防止我們的真實地址被泄露,防止被追究
- 語法
- requetst.get("http://www.baidu.com",proxies=proxies)
- proxies的數據結構 字典
- proxies={ "http":"http://12.33.34.54:8374","https":"https://12.33.34.54:8374" }
- 示例
import requests
url="http://www.baidu.com"
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36"
}
proxies={
"http": "175.42.158.211:9999"
}
respons=requests.post(url,proxies=proxies)
print(respons.status_code)
**cookie和session的區別
**
- cookie數據存放在客戶的瀏覽器上,session數據放在服務器上
- cookie不是很安全,別人可以分析存放在本地的cookie并進行cookie欺騙
- session會在一定時間內保存在服務器上。當訪問增多會比較占用服務器性能
- 單個cookie保存的數據不能超過4k,很多瀏覽器都限制一個站點最多保存20個cookie
爬蟲處理cookie和session
- 帶上cookie、session的好處
- 能夠請求到登錄之后的頁面
- 帶上cookie、session的壞處
- 一套cookie和session往往和一個用戶對應,請求太快,請求次數太多,容易被服務器識別為爬蟲
- 如果不需要cookie的時候盡量不去使用cookie
**requests 處理cookies、session請求
**
- reqeusts 提供了一個session類,來實現客戶端和服務端的會話保持
- 使用方法
- 實例化一個session對象
- 讓session發送get或者post請求
- 語法
- session=requests.session()
- response=session.get(url,headers)
- 示例
import requests
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36"
}
data={
"email":"用戶名",
"password":"密碼"
}
session=requests.session()
# session發送post請求,cookie保存在其中
session.post("http://www.renren.com/PLogin.do",data=data,headers=headers)
# 使用session請求登錄后才能訪問的頁面
r=session.get("http://www.renren.com/976564425",headers=headers)
print(r.content.decode())
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
互聯網
+關注
關注
54文章
11105瀏覽量
103015 -
程序
+關注
關注
116文章
3777瀏覽量
80851 -
網絡爬蟲
+關注
關注
1文章
52瀏覽量
8642
發布評論請先 登錄
相關推薦
Python數據爬蟲學習內容
,利用爬蟲,我們可以解決部分數據問題,那么,如何學習Python數據爬蟲能?1.學習Python基礎知識并實現基本的爬蟲過程一般獲取數據的過
發表于 05-09 17:25
Python爬蟲與Web開發庫盤點
Python爬蟲和Web開發均是與網頁相關的知識技能,無論是自己搭建的網站還是爬蟲爬去別人的網站,都離不開相應的Python庫,以下是常用的
發表于 05-10 15:21
0基礎入門Python爬蟲實戰課
學習資料良莠不齊爬蟲是一門實踐性的技能,沒有實戰的課程都是騙人的!所以這節Python爬蟲實戰課,將幫到你!課程從0基礎入門開始,受眾人群廣泛:如畢業大學生、轉行人群、對Python
發表于 07-25 09:28
Python爬蟲簡介與軟件配置
Python爬蟲練習一、爬蟲簡介1. 介紹2. 軟件配置二、爬取南陽理工OJ題目三、爬取學校信息通知四、總結五、參考一、爬蟲簡介1. 介紹網絡爬蟲
發表于 01-11 06:32
python網絡爬蟲概述
的數據,從而識別出某用戶是否為水軍學習爬蟲前的技術準備(1). Python基礎語言: 基礎語法、運算符、數據類型、流程控制、函數、對象 模塊、文件操作、多線程、網絡編程 … 等(2). W3C標準
發表于 03-21 16:51


python爬蟲入門教程之python爬蟲視頻教程分布式爬蟲打造搜索引擎
本文檔的主要內容詳細介紹的是python爬蟲入門教程之python爬蟲視頻教程分布式爬蟲打造搜索引擎
發表于 08-28 15:32
?29次下載
python為什么叫爬蟲 python工資高還是java的高
人工智能的現世,讓python學習成風,由于其發展前景好,薪資高,一時成為眾多語言的首選。Python是一門非常適合開發網絡爬蟲的編程語言,十分的簡潔方便所以是網絡
發表于 02-19 17:56
?528次閱讀
python爬蟲框架有哪些
本視頻主要詳細介紹了python爬蟲框架有哪些,分別是Django、CherryPy、Web2py、TurboGears、Pylons、Grab、BeautifulSoup、Cola。
如何解決Python爬蟲中文亂碼問題?Python爬蟲中文亂碼的解決方法
如何解決Python爬蟲中文亂碼問題?Python爬蟲中文亂碼的解決方法 在Python爬蟲過程





 工商網監
工商網監
評論