") GNN與聯(lián)邦學習的強強組合又會擦出怎樣的火花?
GNN與聯(lián)邦學習的強強組合又會擦出怎樣的火花?
聯(lián)邦學習和 GNN 都是當前 AI 領(lǐng)域的研究熱點。聯(lián)邦學習的多個參與方可以在不泄露原始數(shù)據(jù)的情況下,安全合規(guī)地聯(lián)合訓練業(yè)務模型,目前已在諸多領(lǐng)域取得了較好的結(jié)果。GNN 在應對非歐數(shù)據(jù)結(jié)構(gòu)時通常有較好的表現(xiàn),因為它不僅考慮節(jié)點本身的特征還考慮節(jié)點之間的鏈接關(guān)系及強度,在諸如:異常個體識別、鏈接預測、分子性質(zhì)預測、地理拓撲圖預測交通擁堵等領(lǐng)域均有不俗表現(xiàn)。
那么 GNN 與聯(lián)邦學習的強強組合又會擦出怎樣的火花? 通常一個好的 GNN 算法需要豐富的節(jié)點特征與完整的連接信息,但現(xiàn)實場景中數(shù)據(jù)孤島問題比較突出,單個數(shù)據(jù)擁有方往往只有有限的數(shù)據(jù)、特征、邊信息,但我們借助聯(lián)邦學習技術(shù)就可以充分利用各方數(shù)據(jù)安全合規(guī)地訓練有強勁表現(xiàn)的 GNN 模型。
一、GNN 原理
1.1 圖場景及數(shù)據(jù)表示
能用圖刻畫的場景很多,比如:社交網(wǎng)絡(luò)、生物分子、電商網(wǎng)絡(luò)、知識圖譜等。
圖最基礎(chǔ)且通用的分類是將其分為:同構(gòu)圖(一種節(jié)點 + 一種邊)與異構(gòu)圖(節(jié)點類型 + 邊類型 > 2),相應的示意圖如下。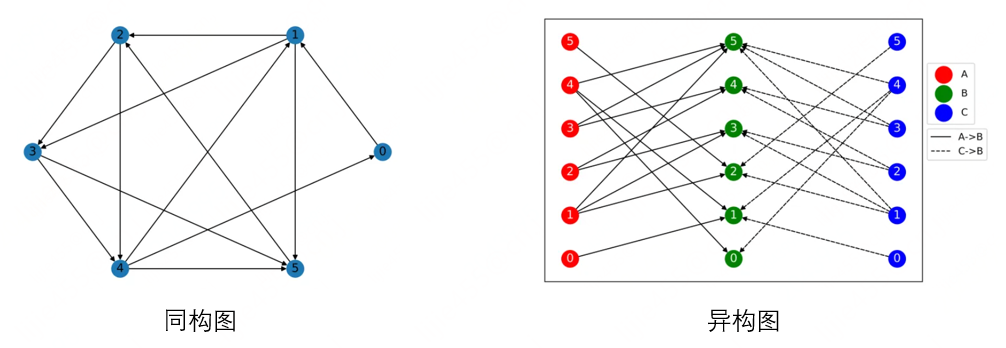
一般來說,原始的圖數(shù)據(jù)由兩部分組成:節(jié)點數(shù)據(jù)(節(jié)點類型 + 節(jié)點 ID + 節(jié)點特征)、邊數(shù)據(jù)(邊類型 + 起點 + 終點)。原始數(shù)據(jù)經(jīng)過解析處理后載入圖存儲模塊,圖存儲的基本形式為鄰接矩陣(COO),但一般出于存儲與計算開銷考慮采用稀疏存儲表示(CSC/CSR)。
1.2 GNN 任務分類
GNN 任務一般分為如下四類:
?節(jié)點 / 邊分類:異常用戶識別。
?鏈接預測:user-item 購物傾向、知識圖譜補全。
?全圖分類:生物分子性質(zhì)預測。
?其他:圖聚類、圖生成。
1.3 GNN 算法原理
我們以 GraphSAGE 為例講解 GNN 的計算原理 [1],大致包含三個過程:采樣、聚合、擬合目標。GraphSAGE 示意圖如下: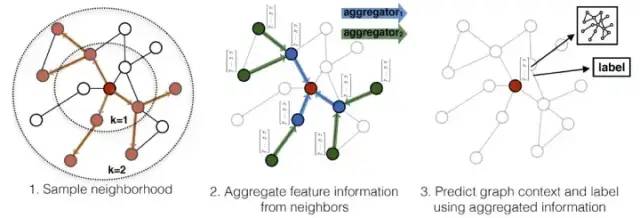
GraphSAGE 算法的偽代碼如下:
下面我們給合實例與公式詳細說明其計算過程,下圖先給出采樣過程與消息傳遞過程的框架原理。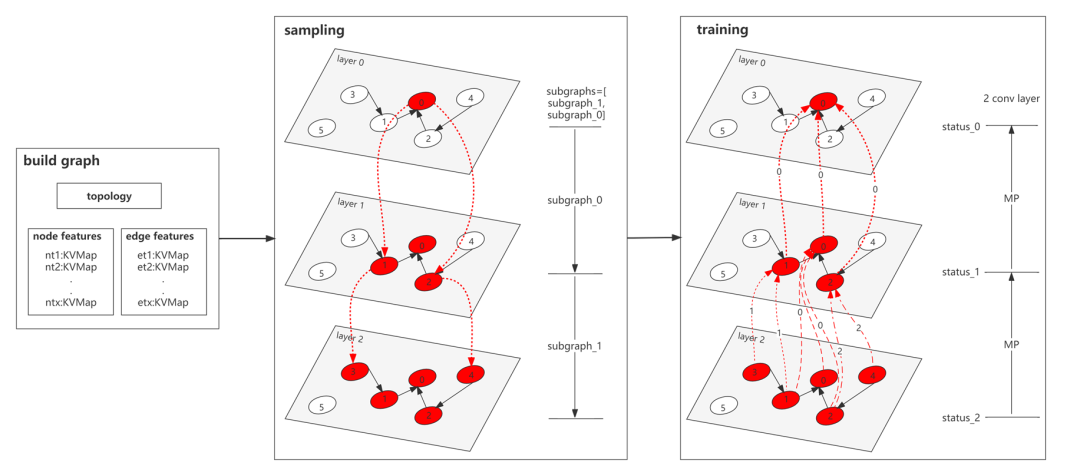
下圖給出了具體的消息傳遞執(zhí)行過程。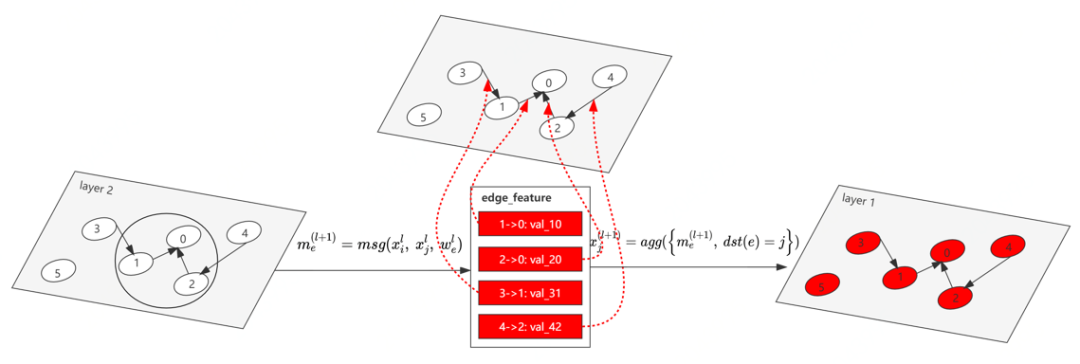
二、聯(lián)邦學習
之前機器學習模型訓練的經(jīng)典架構(gòu)是:數(shù)據(jù)中心從各客戶端或機構(gòu)收集原始數(shù)據(jù)后,在數(shù)據(jù)中心對收集的全體數(shù)據(jù)進行模型訓練。近年來隨著數(shù)據(jù)隱私保護法規(guī)的頒布和數(shù)據(jù)安全意識的提升,機構(gòu)間交換明文數(shù)據(jù)就不可行了。如何綜合多個用戶或機構(gòu)間數(shù)據(jù)來訓練模型?聯(lián)邦學習技術(shù)應運而生。聯(lián)邦學習一般分為如下兩大類 [2]:
?聯(lián)邦學習(橫向):兩個機構(gòu)擁有較多相同特征,但是重合樣本 ID 很少。比如:北京醫(yī)院和上海醫(yī)院的病人數(shù)據(jù)。
?聯(lián)邦學習(縱向):兩個機構(gòu)擁有較多相同樣本 ID,但是機構(gòu)間重合特征較少。比如:北京銀行和北京保險公司的客戶數(shù)據(jù)。
2.1 橫向聯(lián)邦學習
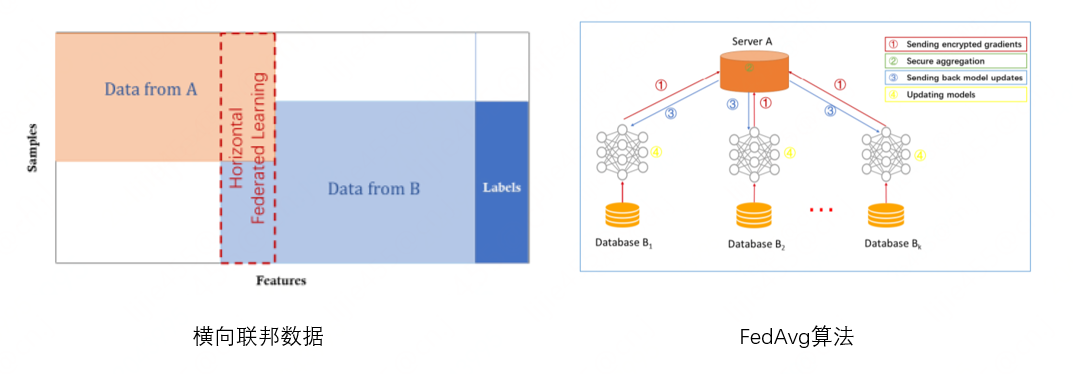
如上圖所示,左邊紅虛線框內(nèi)是數(shù)據(jù)表示,即重合樣本較少,但特征相同。右邊是經(jīng)典的橫向 FedAvg 算法,每個客戶端擁有同樣的模型結(jié)構(gòu),初始權(quán)重由 server 下發(fā)至客戶端,待各客戶端更新本地模型后,再將梯度 / 權(quán)重發(fā)送至 server 進行聚合,最后將聚合結(jié)果下發(fā)給各客戶端以更新本地模型。
2.2 縱向聯(lián)邦學習
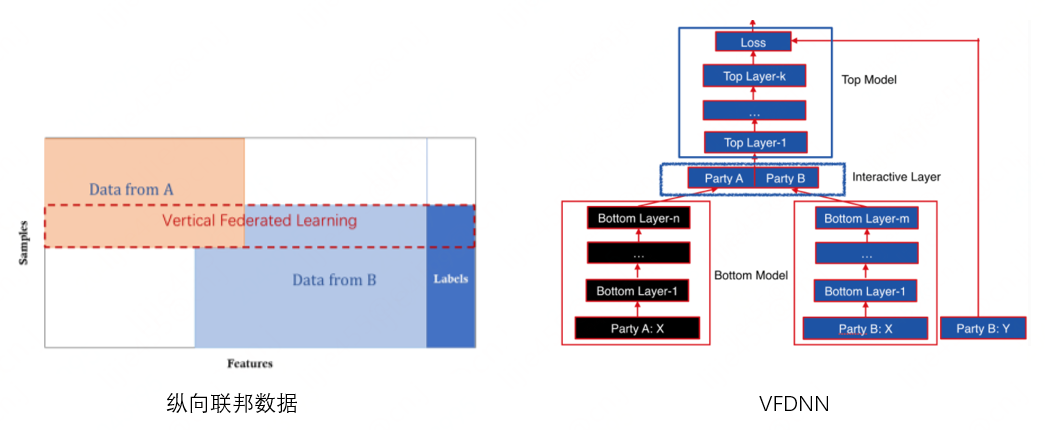
如上圖所示,左邊紅虛線框內(nèi)代表數(shù)據(jù)表示,即兩方擁有較多相同樣本 ID,但是重合特征較少。右邊是經(jīng)典的兩方縱向 DNN 模型訓練架構(gòu) [3],其中 A 方 bottom 層結(jié)果要發(fā)送至 B 方,而 B 方擁有 label,用來計算 loss 及梯度,詳細過程參考 [4]。
三、聯(lián)邦 GNN
3.1 聯(lián)邦 GNN 分類
3.1.1 圖對象 + 數(shù)據(jù)劃分
根據(jù)圖數(shù)據(jù)在客戶端的分布規(guī)則,具體以圖對象(圖、子圖、節(jié)點)與數(shù)據(jù)劃分(橫向、縱向)角度來看,可以將聯(lián)邦 GNN 分為四類 [5]: 1)inter-graph FL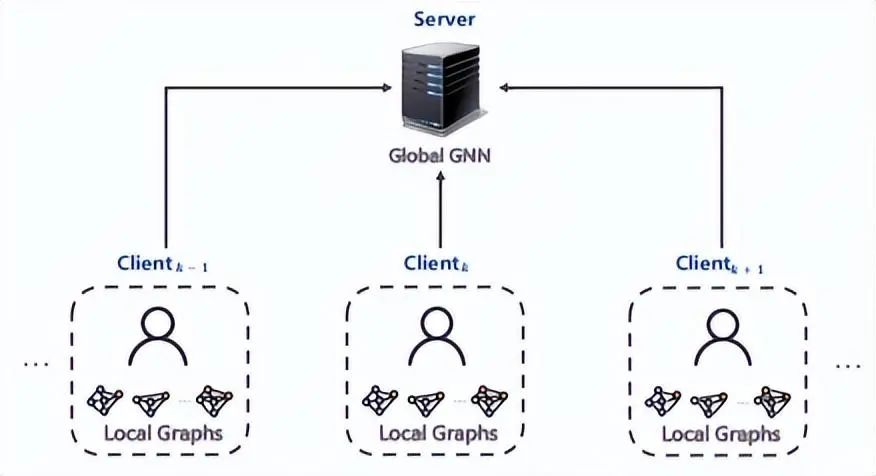
在此分類中,客戶端的每條樣本是圖數(shù)據(jù),最終的全局模型處理圖級別的任務。此架構(gòu)廣泛應用在生物工程領(lǐng)域,通常用圖來表示分子結(jié)構(gòu),其中節(jié)點表示原子,邊表示原子間的化學鍵。在藥物特性研究方面可以應用此技術(shù),每個制藥廠 k 都維護了自己的分子 - 屬性數(shù)據(jù)集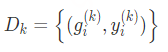 ,但都不想分享給競爭對手。借助 inter-graph FL 技術(shù),多家藥廠就可以合作研究藥物性質(zhì)。在此例中,全局模型為:
,但都不想分享給競爭對手。借助 inter-graph FL 技術(shù),多家藥廠就可以合作研究藥物性質(zhì)。在此例中,全局模型為: 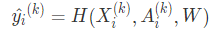 2)horizontal intra-graph FL
2)horizontal intra-graph FL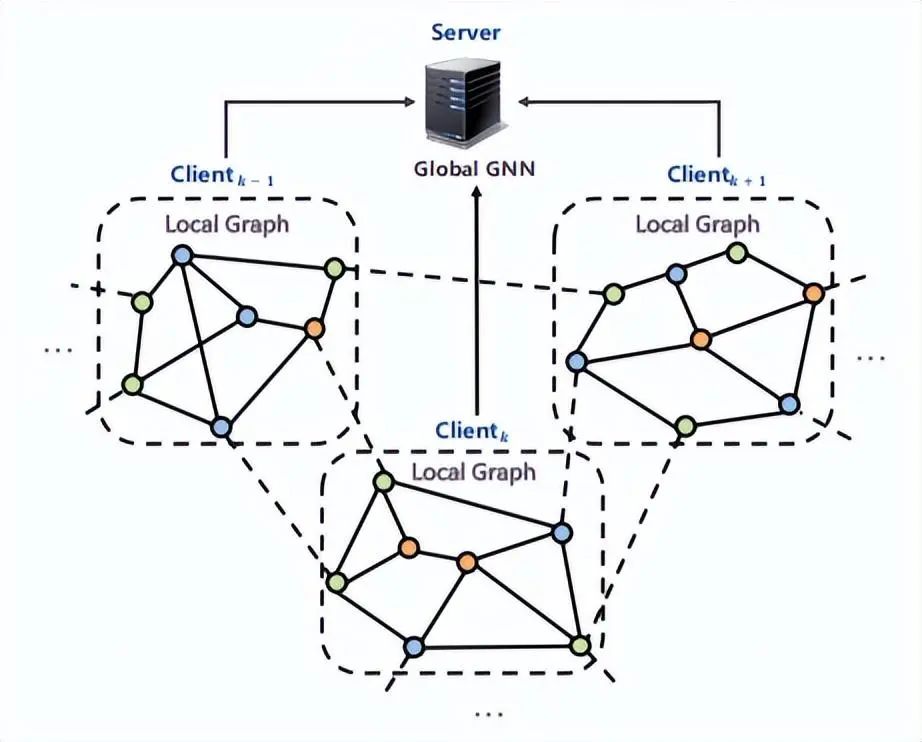
上圖中全部客戶端擁有的數(shù)據(jù)構(gòu)成完整的圖,其中虛線表示本應存在但實際不存在的邊。此類架構(gòu)中,每個客戶端對應的子圖擁有相同的特征空間和標簽空間但擁有不同的 ID。在此設(shè)置下,全局 GNN 模型一般處理節(jié)點類任務和邊任務: 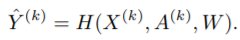
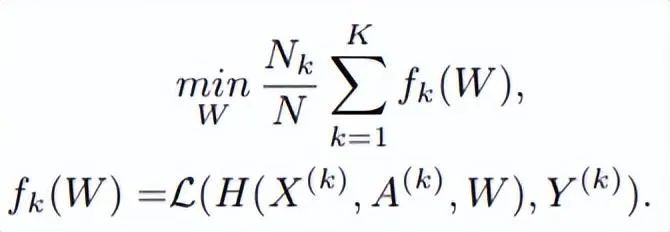
3)vertical intra-graph FL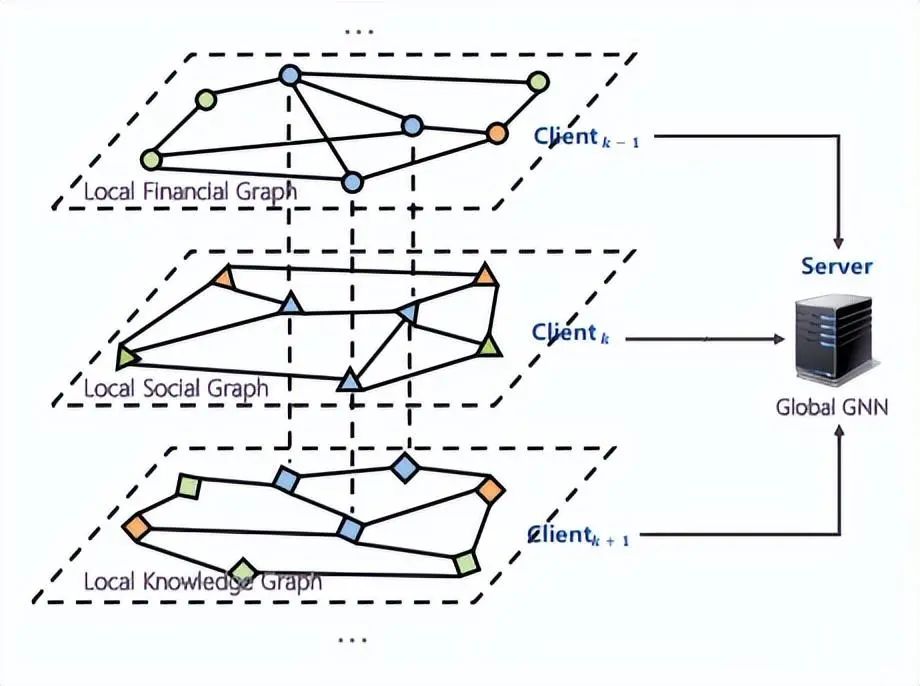
此類架構(gòu)中,客戶端共享相同的 ID 空間,但不共享特征和標簽空間。上圖中的垂直虛線代表擁有相同 ID 的節(jié)點。在此架構(gòu)中全局模型不唯一,這取決于多少客戶端擁有標簽,同時也意味著此架構(gòu)可進行 multi-task learning。此架構(gòu)主要用來以隱私保護的方式聚合各客戶端相同節(jié)點的特征,共享相同節(jié)點的標簽。如果不考慮數(shù)據(jù)對齊和數(shù)據(jù)共享問題,則相應的目標函數(shù)定義為: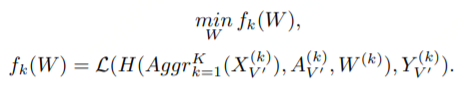
此架構(gòu)一般應用在機構(gòu)間合作,如反洗錢。犯罪分子采用跨多個機構(gòu)的復雜策略進行洗錢活動,這時可應用此架構(gòu),通過機構(gòu)間合作識別出洗錢行為。
4)graph-structured FL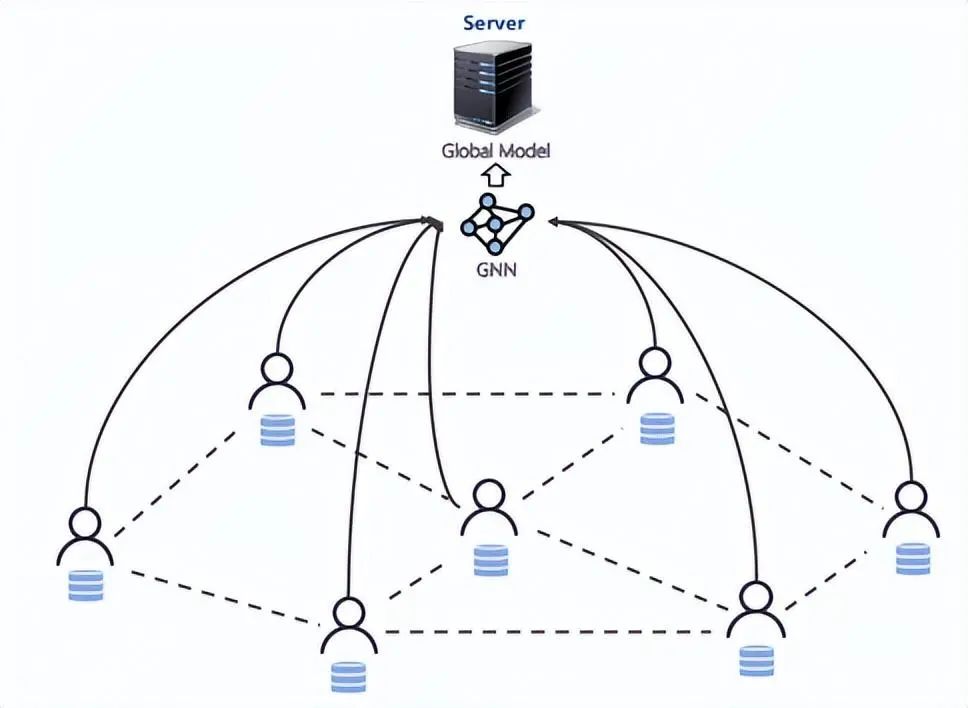
此架構(gòu)用來表示客戶端之間的拓撲關(guān)系,一個客戶端相當于圖中一個節(jié)點。此架構(gòu)會基于客戶端拓撲聚合本地模型,全局模型可以處理聯(lián)邦學習領(lǐng)域的各種任務和目標函數(shù)。
全局 GNN 模型旨在通過客戶端之間的拓撲關(guān)系挖掘背后的隱含信息。此架構(gòu)的經(jīng)典應用是聯(lián)邦交通流量預測,城市中的監(jiān)控設(shè)備分布在不同的地方,GNN 用來描述設(shè)備間的空間依賴關(guān)系。
以上圖為例全局 GNN 模型的聚合邏輯如下: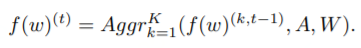
本節(jié)總結(jié)
3.1.2 二維分類法
根據(jù)參考文獻 [6],我們可以從 2 個維度對 FedGNNs 進行分類。第一個維度為主維度,聚焦于聯(lián)邦學習與 GNN 如何結(jié)合;第二個維度為輔助維度,聚焦于聯(lián)邦學習的聚合邏輯,用來解決不同 level 的圖數(shù)據(jù)異構(gòu)性。其分類匯總圖大致如下: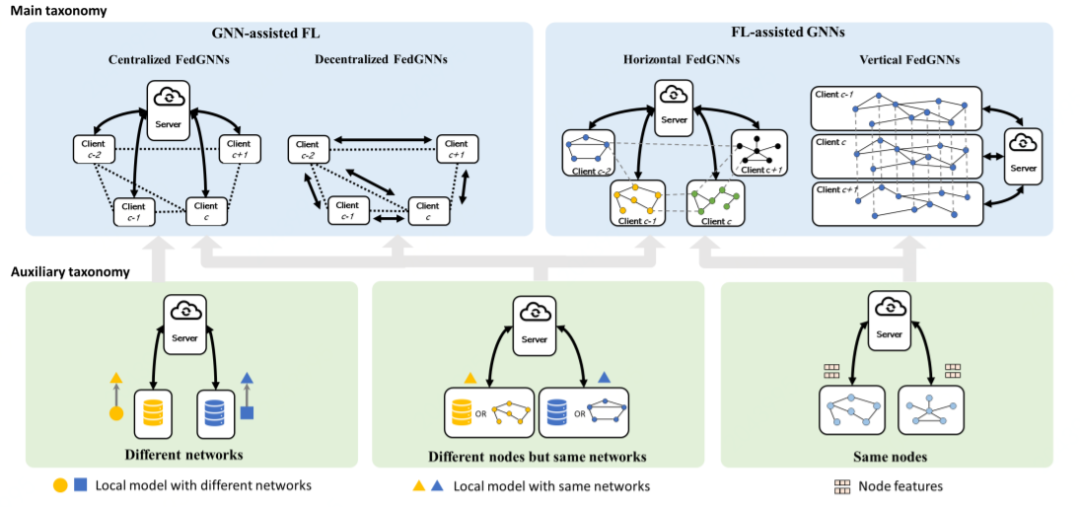
1)GNN-assisted FL
借助結(jié)構(gòu)化的客戶端來提升聯(lián)邦學習訓練效果,用虛線來表示客戶端之間的網(wǎng)絡(luò)拓撲關(guān)系。此架構(gòu)一般分為兩種形式:
?中心化架構(gòu):擁有客戶端間的全局網(wǎng)絡(luò)拓撲。可訓練 GNN 模型提升聯(lián)邦聚合效果,也可幫助客戶端更新本地模型。
?非中心化架構(gòu):客戶端間的全局網(wǎng)絡(luò)拓撲必須提前給定,這樣擁有子圖的客戶端就可以找到它在圖中的鄰居。
2)FL-assisted GNN
借助分散的圖數(shù)據(jù)孤島來提升 GNN 模型效果,具體通過聯(lián)邦學習把圖數(shù)據(jù)孤島組織起來訓練一個全局 GNN 模型。根據(jù)客戶端是否有相同節(jié)點,此架構(gòu)可分為如下兩類:
?horizontal FedGNN:各客戶端擁有的重疊節(jié)點不多,有可能會丟失跨客戶端的鏈接,通常需要較復雜的處理方法。
?vertical FedGNN:各客戶端擁有相同的節(jié)點集合,但持有的特征不相同。根據(jù)特征的分區(qū)方式不同,相應的處理方法也隨之變化。
3)Auxiliary taxonomy 輔助分類聚焦于解決聯(lián)邦學習客戶端之間的異構(gòu)性問題。具體可以分為三類:
?客戶端擁有相同 ID:可將節(jié)點特征或中間表征上傳至聯(lián)邦服務器進行聯(lián)邦聚合。常用于 vertical FedGNN 和有部分重復節(jié)點的水平 FedGNN。
?客戶端擁有不同節(jié)點但相同網(wǎng)絡(luò)結(jié)構(gòu):聯(lián)邦聚合對象主要是模型權(quán)重和梯度。常用于 GNN-assisted FL 和無重復節(jié)點的 horizontal FedGNN。
?客戶端擁有不同網(wǎng)絡(luò)結(jié)構(gòu):先把本地模型做成圖,然后將 GNN 作用于圖之上。聯(lián)邦聚合對象是 GNN 權(quán)重和梯度,常用于 centralized FedGNN。
3.2 FedGNN
3.2.1 問題定義

3.2.2 FedGNN 原理與架構(gòu)
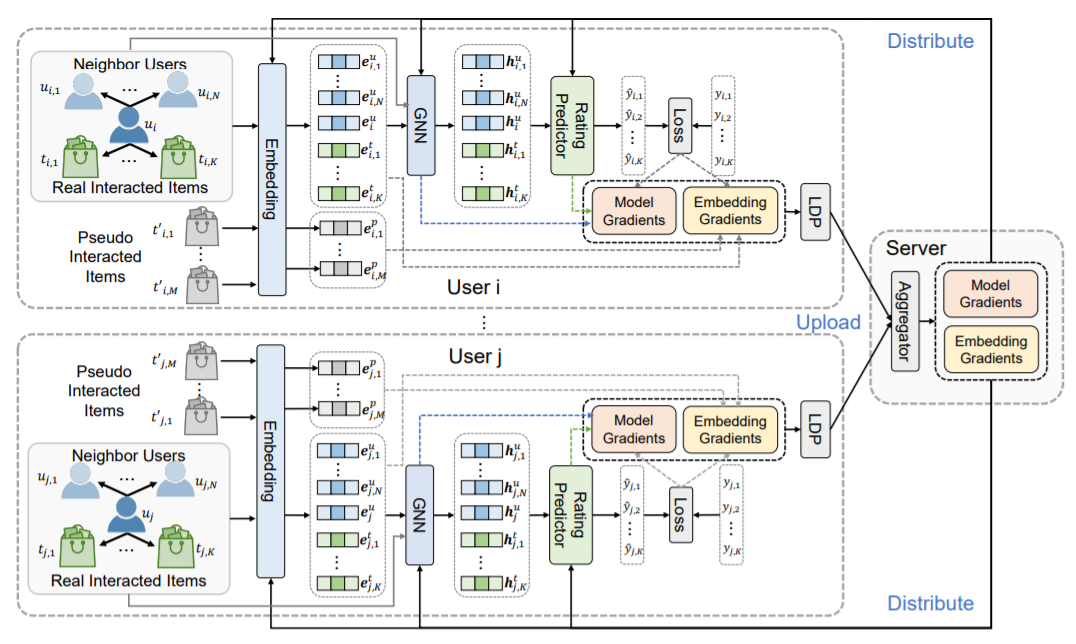
如上圖,F(xiàn)edGNN [7] 由一個中心服務器和大量客戶端組成。客戶端基于其用戶交互物品與鄰居客戶端在本地維護了一個子圖。客戶端基于本地子圖學習 user/item embedding,以及 GNN 模型,然后將梯度上傳給中心服務器。中心服務器用來協(xié)調(diào)客戶端,具體是在訓練過程中聚合從多個客戶端收集的梯度(基于 FedAvg 算法),并將聚合后的梯度回傳給客戶端。如下我們將依次介紹一些技術(shù)細節(jié)。
FedGNN 的完整算法流程見下述 Algorithm1,其中有兩個隱私保護模塊:其一是隱私保護模型更新(Algorithm1 的 9-11 行),用來保護梯度信息;其二是隱私保護 user-item 圖擴充模塊(Algorithm1 中第 15 行),用來對 user 和 item 的高階交互進行建模。
3.2.3 隱私保護模型更新
embedding 梯度和模型梯度(GNN+rating predictor)直接傳輸會泄露隱私,因此需要對此進行安全防護。因為每個客戶端維護了全量 item 的 embedding 表,通過同態(tài)加密保護梯度就不太現(xiàn)實(大量的存儲和通信開銷),文獻 [7] 提出兩個機制來保護模型更新過程中的隱私保護。
1)偽交互物品采樣 隨機采樣 M 個用戶并未交互過的物品,根據(jù)交互物品 embedding 梯度分布隨機生成偽交互物品 embedding 梯度。于是第 i 個用戶的模型和 embedding 梯度修改為 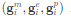
2)采用 LDP(本地差分隱私)護本地梯度 首先通過梯度的無窮范數(shù)和閾值?δ對梯度進行截斷,然后基于 LDP 思想采用 0 均值拉普拉斯噪聲對前述梯度進行擾動,從而實現(xiàn)對用戶隱私的保護。相應的公式表達為:
gi=clip(g_i_,δ)+Laplace(0,λ)。受保護的梯度再上傳到中心服務器進行聚合。
3.2.4 隱私保護圖擴充
客戶端本地 user-item 圖以隱私保護方式找到鄰居客戶端,以達到對本地圖自身的擴充。在中心化存儲的 GNN 場景中,user 與 item 的高階交互可通過全局 user-item 圖方便獲取。但非中心化場景中,在遵守隱私保護的前提下要想求得 user-item 高階交互不是易事。文章提出通過尋找客戶端的匿名鄰居以提升 user 和 item 的表征學習,同時用戶隱私不泄露,詳細過程如下: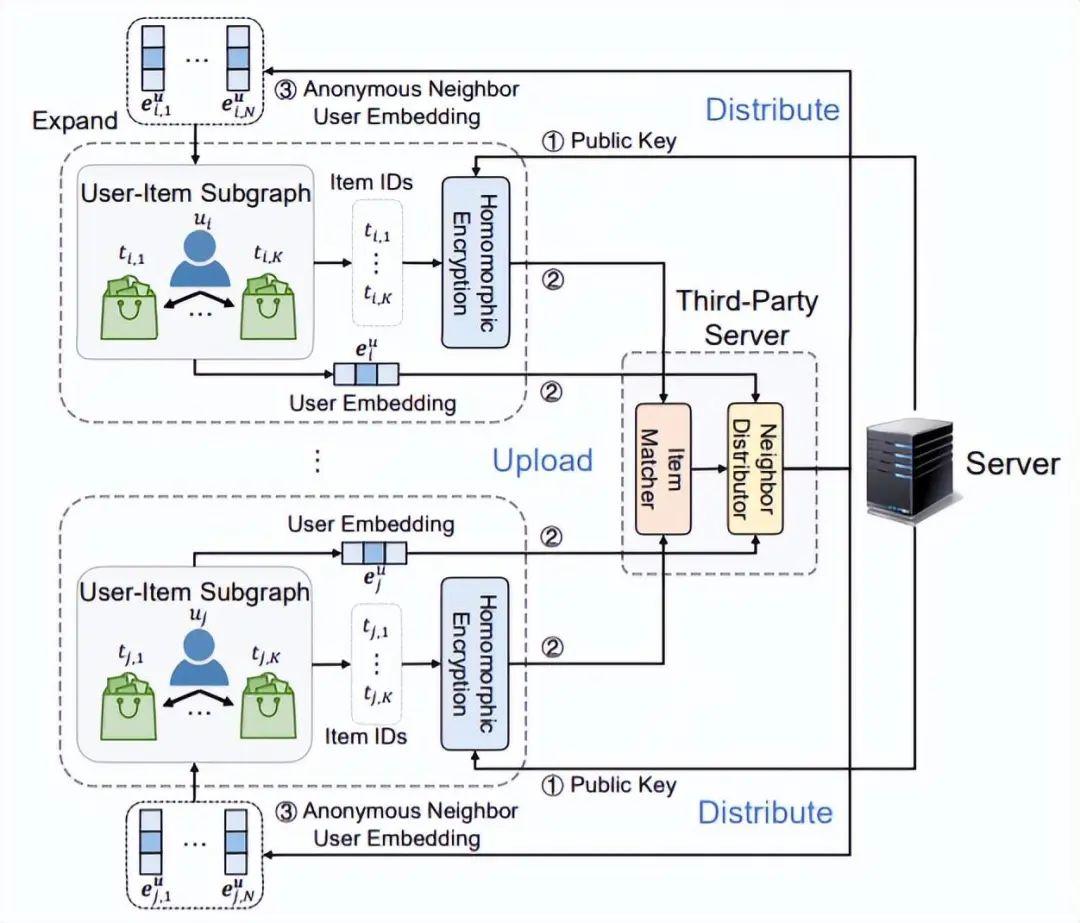
首先,中心服務器生成公鑰并分發(fā)給各客戶端。客戶端收到公鑰后,利用同態(tài)加密技術(shù)對交互物品 ID 進行加密處理。前述加密 ID 和用戶 embedding 被上傳至第三方服務器(不需要可信),通過 PSI 技術(shù)找到有相同交互物品的用戶,然后為每個用戶提供匿名鄰居 embedding。最后,我們把用戶的鄰居用戶節(jié)點連接起來,這樣就以隱私保護的方式添加了 user-item 的高階交互信息,豐富了客戶端的本地 user-item 子圖。
3.3 VFGNN
3.3.1 數(shù)據(jù)假設(shè)
訓練一個好的 GNN 模型通常需要豐富的節(jié)點特征和完整的連接信息。但是節(jié)點特征和連接信息通常由多個數(shù)據(jù)方擁有,也就是所謂的數(shù)據(jù)孤島問題。下圖我們給出圖數(shù)據(jù)縱向劃分的例子 [8],其中三方各自擁有節(jié)點不同的特征,各方擁有不同類型的邊。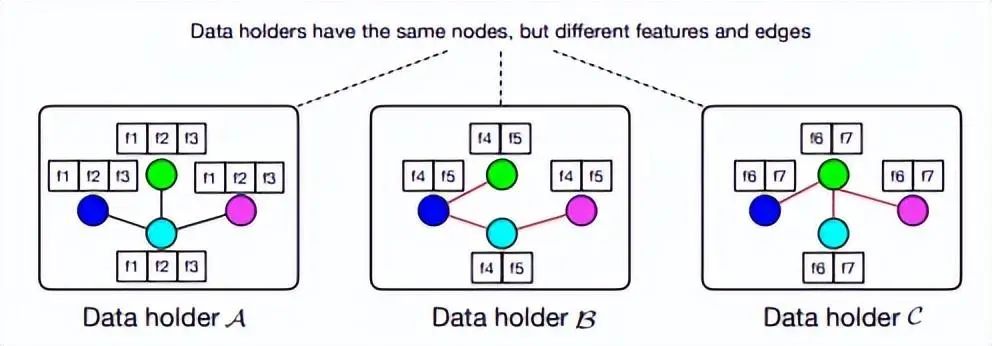
3.3.2 算法架構(gòu)及流程
安全性假設(shè):數(shù)據(jù)擁有方 A,B,C 和服務器 S 都是半誠實的,并且假定服務器 S 和任一數(shù)據(jù)擁有方不會合謀。這個安全假設(shè)符合大多數(shù)已有工作,并且和現(xiàn)實場景比較契合。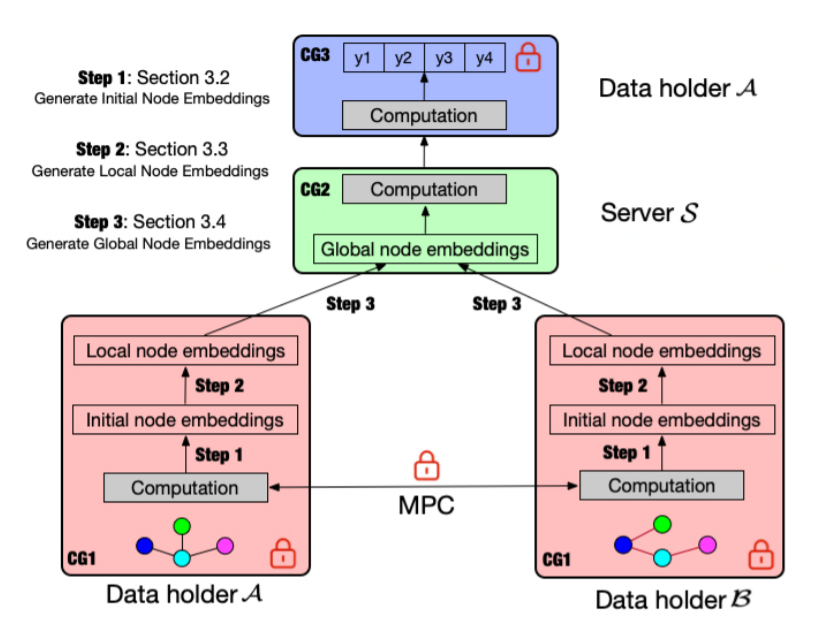
上圖即為 VFGNN 的架構(gòu)圖,它的計算分為兩大部分:
?隱私數(shù)據(jù)相關(guān)計算:一般在數(shù)據(jù)擁有方本地進行。在 GNN 場景中,隱私數(shù)據(jù)有:節(jié)點特征、label、邊信息。
?非隱私數(shù)據(jù)相關(guān)計算:一般將計算權(quán)委托給半誠實 server,主要是出于計算效率的考慮。
考慮到數(shù)據(jù)隱私性的問題,上述計算圖分為如下三個計算子圖,且各自承擔的工作如下:
?CG1:隱私特征和邊相關(guān)計算。先利用節(jié)點隱私特征生成 initial node embedding,這個過程是多方協(xié)同工作的。接著通過采樣找到節(jié)點的多跳鄰居,再應用聚合函數(shù)生成 local node embedding。
?CG2:非隱私數(shù)據(jù)相關(guān)計算。出于效率考慮,作者把非隱私數(shù)據(jù)相關(guān)計算委托給半誠實服務器。此服務器把從各方收集的 local node embedding 通過不同的 COMBINE 策略處理生成 global node embedding。接著可以進行若干明文類的操作,比如 max-pooling、activation(這些計算在密文狀態(tài)下不友好)。進行一系列明文處理后,我們得到最后一個隱層輸出_ZL_?,然后把它發(fā)送給擁有 label 的數(shù)據(jù)方計算預測值。
?CG3:隱私標簽相關(guān)計算。以節(jié)點分類任務為例 ,當收到_ZL_?后可以快速計算出預測值,具體通過 softmax 函數(shù)進行處理。
3.3.3 重要組件
Generating Initial Node Embedding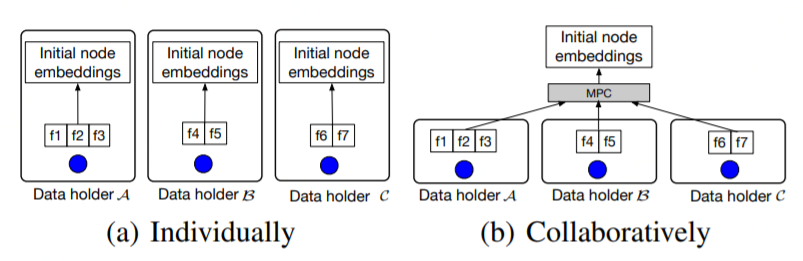
如果各方獨立生成 initial node embedding(上圖 a),則遵循如下計算公式: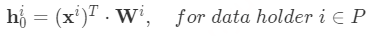
如果各方協(xié)同生成 initial node emb,則可按上圖 b 中應用 MPC 技術(shù)進行處理。 Generating Local Node Embedding 基于前述生成的 initial node embedding,及節(jié)點的多跳鄰居節(jié)點,應用聚合函數(shù)可以生成 local node embedding。鄰居節(jié)點的聚合操作必須在本地進行而不需要多方協(xié)同,目的是保護隱私的邊信息。一個節(jié)點的鄰居節(jié)點聚合操作和常規(guī) GNN 一樣,以 GraphSAGE 為例節(jié)點的聚合操作是通過采樣和聚合特征形成了 local node embedding,具體公式如下: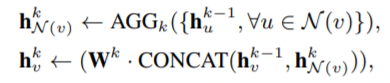
GraphSAGE 中,常用的聚合函數(shù)有:Mean、LSTM、Pooling。接著數(shù)據(jù)擁有方把 local node embedding 發(fā)送給半誠實服務器,以進行 COMBINE 操作及后續(xù)的非隱私數(shù)據(jù)計算邏輯。 Generating Global Node Embedding 對各方傳來的 local node embedding 執(zhí)行 combine 操作可以生成 global node embedding。combine 策略一般是可訓練且高表達容量,文章給出了三種策略:
1)Concat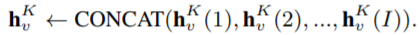
2)Mean
3)Regression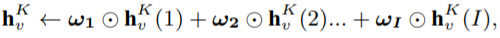
3.3.4 隱私保護 DP
如果在前向過程中把 local node embedding 直接傳給半誠實服務器,或在反向傳播過程中直接傳遞梯度信息很可能造成信息泄露。本文提出了兩種基于 DP 的方法用來保護信息發(fā)布過程,算法流程如下:
3.3.5 VFGNN 前向算法
以 GraphSAGE 處理節(jié)點分類任務為例,VFGNN 算法的前向過程描述如下:
3.4 其他算法及項目
最近四年出現(xiàn)的聯(lián)邦 GNN 算法 [9]: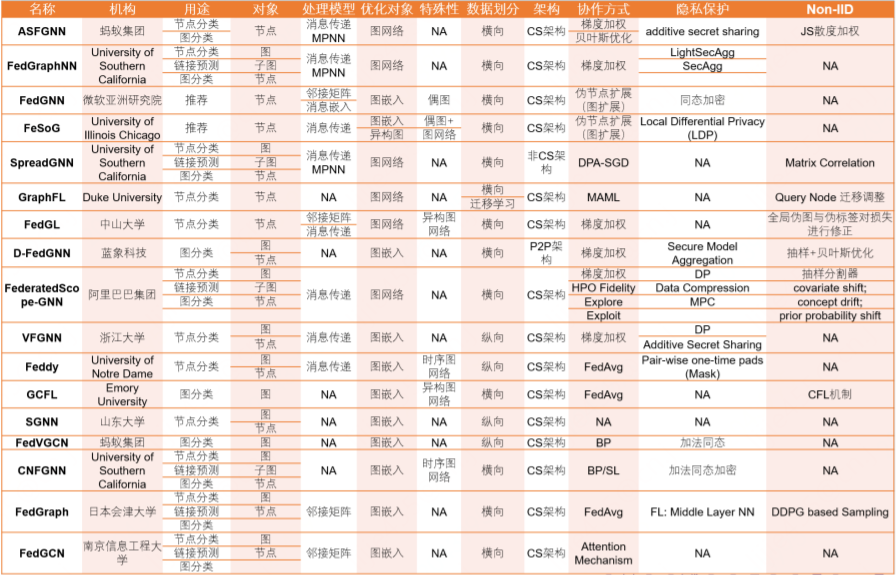
開源項目有:FedGraphNN [10]。
審核編輯:劉清
-
CSR
+關(guān)注
關(guān)注
3文章
118瀏覽量
69598 -
機器學習
+關(guān)注
關(guān)注
66文章
8377瀏覽量
132409 -
CSC
+關(guān)注
關(guān)注
0文章
5瀏覽量
2381 -
GNN
+關(guān)注
關(guān)注
1文章
31瀏覽量
6328
原文標題:聯(lián)邦GNN綜述與經(jīng)典算法介紹
文章出處:【微信號:OSC開源社區(qū),微信公眾號:OSC開源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
東芝和日本半導體擦出火花,新技術(shù)為模擬電源IC提高可靠性

楊強教授:從機器學習到遷移學習
機器學習實戰(zhàn):GNN加速器的FPGA解決方案
Python遇上物聯(lián)網(wǎng)又會碰撞出怎樣的火花呢
FPC軟板補強設(shè)計
聯(lián)邦濾波器在船舶組合導航系統(tǒng)中的應用
一加5對比三星GalaxyS8深度評測:剛與柔之爭能擦好大的火花
如果將人工智能和區(qū)塊鏈相結(jié)合,會擦出怎樣的火花呢?
人臉識別碰撞智慧機場 新科技不斷擦出火花
物聯(lián)網(wǎng)與教育行業(yè)相結(jié)合會擦出怎樣的火花

LoRa和Sigfox的強強聯(lián)手





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論