 MySQL自增主鍵一定是連續的嗎?
MySQL自增主鍵一定是連續的嗎?
眾所周知,自增主鍵可以讓聚集索引盡量地保持遞增順序插入,避免了隨機查詢,從而提高了查詢效率
但實際上,MySQL 的自增主鍵并不能保證一定是連續遞增的。
下面舉個例子來看下,如下所示創建一張表:
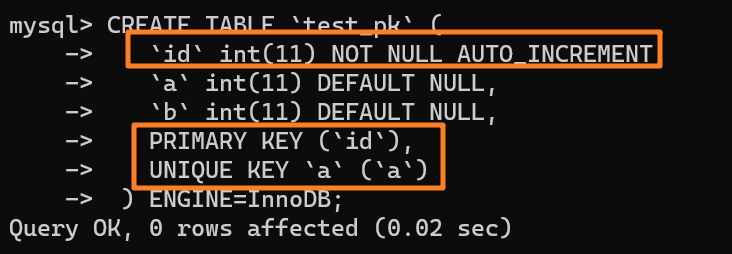
自增值保存在哪里?
使用 insert into test_pk values(null, 1, 1) 插入一行數據,再執行 show create table 命令來看一下表的結構定義:
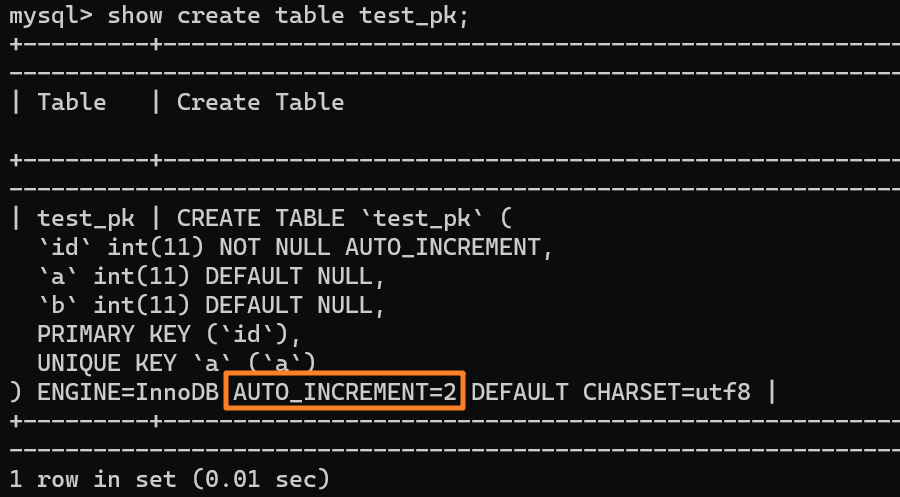
上述表的結構定義存放在后綴名為 .frm 的本地文件中,在 MySQL 安裝目錄下的 data 文件夾下可以找到這個 .frm 文件:
 img
img
從上述表結構可以看到,表定義里面出現了一個 AUTO_INCREMENT=2,表示下一次插入數據時,如果需要自動生成自增值,會生成 id = 2。
但需要注意的是,自增值并不會保存在這個表結構也就是 .frm 文件中,不同的引擎對于自增值的保存策略不同:
1)MyISAM 引擎的自增值保存在數據文件中
2)InnoDB 引擎的自增值,其實是保存在了內存里,并沒有持久化。第一次打開表的時候,都會去找自增值的最大值 max(id),然后將 max(id)+1 作為這個表當前的自增值。
舉個例子:我們現在表里當前數據行里最大的 id 是 1,AUTO_INCREMENT=2,對吧。這時候,我們刪除 id=1 的行,AUTO_INCREMENT 還是 2。
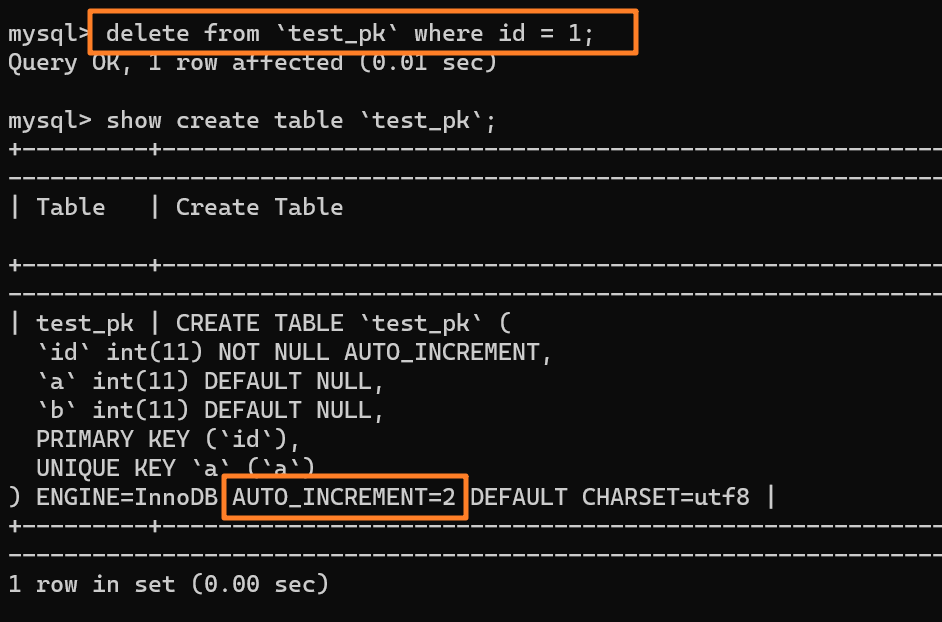
但如果馬上重啟 MySQL 實例,重啟后這個表的 AUTO_INCREMENT 就會變成 1。?也就是說,MySQL 重啟可能會修改一個表的 AUTO_INCREMENT 的值。

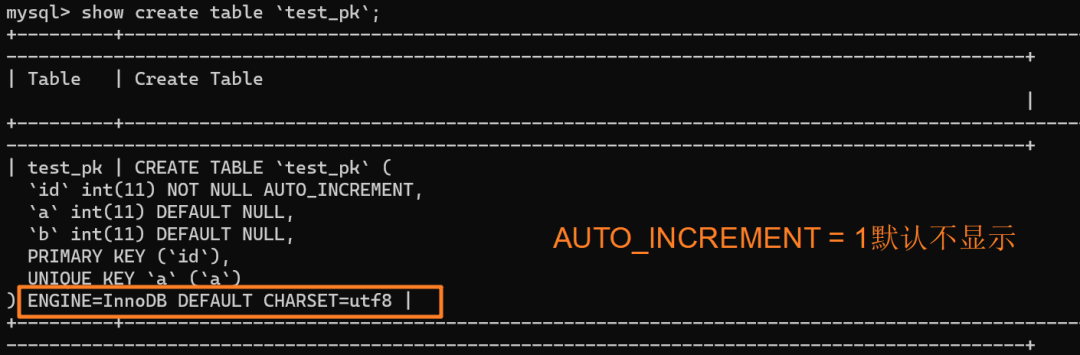
以上,是在我本地 MySQL 5.x 版本的實驗,實際上,到了 MySQL 8.0 版本后,自增值的變更記錄被放在了 redo log 中,提供了自增值持久化的能力,也就是實現了“如果發生重啟,表的自增值可以根據 redo log 恢復為 MySQL 重啟前的值”
也就是說對于上面這個例子來說,重啟實例后這個表的 AUTO_INCREMENT 仍然是 2。
理解了 MySQL 自增值到底保存在哪里以后,我們再來看看自增值的修改機制,并以此引出第一種自增值不連續的場景。
自增值不連續場景 1
在 MySQL 里面,如果字段 id 被定義為 AUTO_INCREMENT,在插入一行數據的時候,自增值的行為如下:
如果插入數據時 id 字段指定為 0、null 或未指定值,那么就把這個表當前的 AUTO_INCREMENT 值填到自增字段;
如果插入數據時 id 字段指定了具體的值,就直接使用語句里指定的值。
根據要插入的值和當前自增值的大小關系,自增值的變更結果也會有所不同。假設某次要插入的值是 insert_num,當前的自增值是 autoIncrement_num:
如果 insert_num < autoIncrement_num,那么這個表的自增值不變
如果 insert_num >= autoIncrement_num,就需要把當前自增值修改為新的自增值
也就是說,如果插入的 id 是 100,當前的自增值是 90,insert_num >= autoIncrement_num,那么自增值就會被修改為新的自增值即 101
一定是這樣嗎?
非也~
了解過分布式 id 的小伙伴一定知道,為了避免兩個庫生成的主鍵發生沖突,我們可以讓一個庫的自增 id 都是奇數,另一個庫的自增 id 都是偶數
這個奇數偶數其實是通過 auto_increment_offset 和 auto_increment_increment 這兩個參數來決定的,這倆分別用來表示自增的初始值和步長,默認值都是 1。
所以,上面的例子中生成新的自增值的步驟實際是這樣的:從 auto_increment_offset 開始,以 auto_increment_increment 為步長,持續疊加,直到找到第一個大于 100 的值,作為新的自增值。
所以,這種情況下,自增值可能會是 102,103 等等之類的,就會導致不連續的主鍵 id。
更遺憾的是,即使在自增初始值和步長這兩個參數都設置為 1 的時候,自增主鍵 id 也不一定能保證主鍵是連續的
自增值不連續場景 2
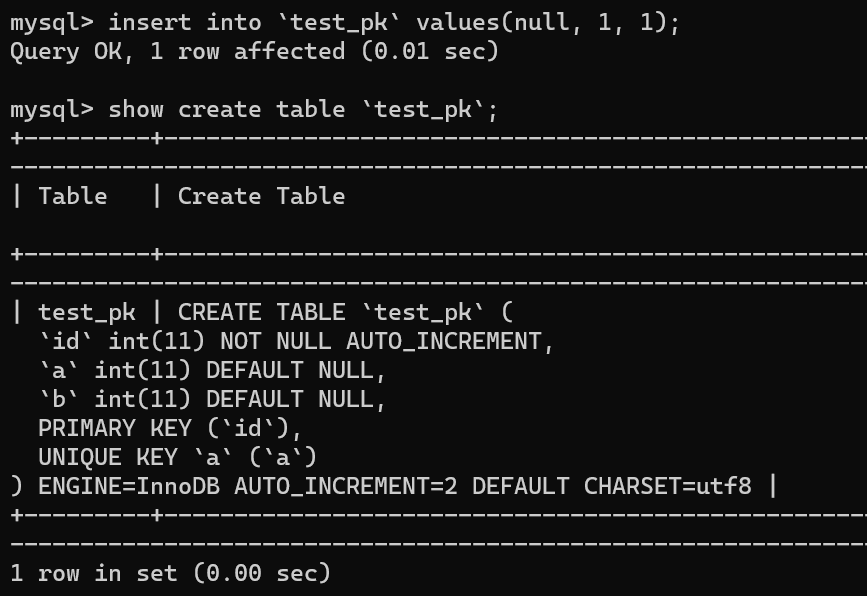
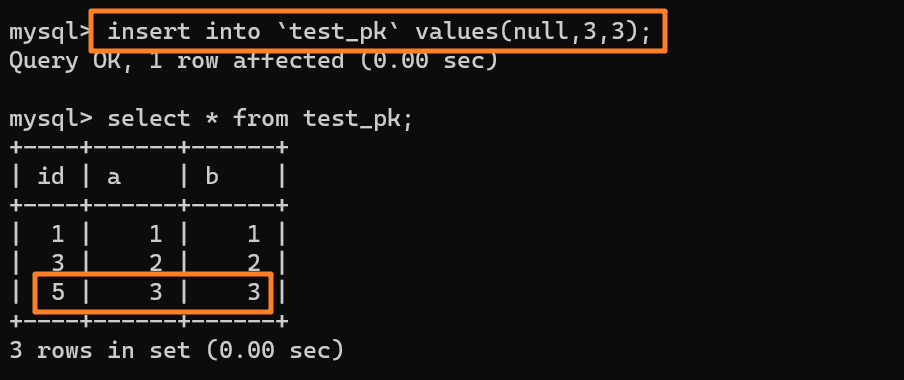
舉個例子,我們現在往表里插入一條 (null,1,1) 的記錄,生成的主鍵是 1,AUTO_INCREMENT= 2,對吧
 img
img
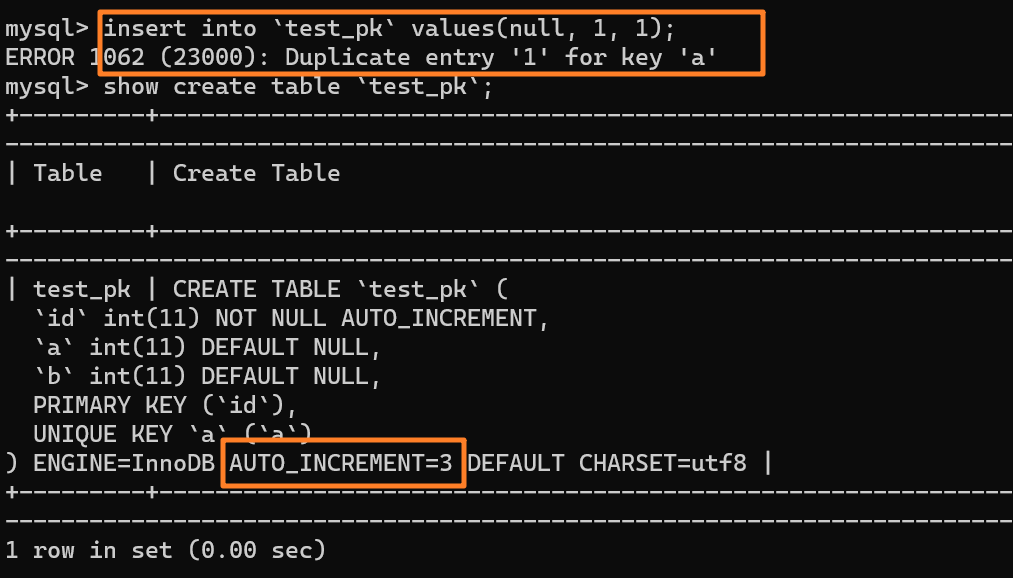
這時我再執行一條插入 (null,1,1) 的命令,很顯然會報錯 Duplicate entry,因為我們設置了一個唯一索引字段 a:
 img
img
但是,你會驚奇的發現,雖然插入失敗了,但自增值仍然從 2 增加到了 3!
這是為啥?
我們來分析下這個 insert 語句的執行流程:
執行器調用 InnoDB 引擎接口準備插入一行記錄 (null,1,1);
InnoDB 發現用戶沒有指定自增 id 的值,則獲取表 test_pk 當前的自增值 2;
將傳入的記錄改成 (2,1,1);
將表的自增值改成 3;
繼續執行插入數據操作,由于已經存在 a=1 的記錄,所以報 Duplicate key error,語句返回
可以看到,自增值修改的這個操作,是在真正執行插入數據的操作之前。
這個語句真正執行的時候,因為碰到唯一鍵 a 沖突,所以 id = 2 這一行并沒有插入成功,但也沒有將自增值再改回去。所以,在這之后,再插入新的數據行時,拿到的自增 id 就是 3。也就是說,出現了自增主鍵不連續的情況。
至此,我們已經羅列了兩種自增主鍵不連續的情況:
自增初始值和自增步長設置不為 1
唯一鍵沖突
除此之外,事務回滾也會導致這種情況
自增值不連續場景 3
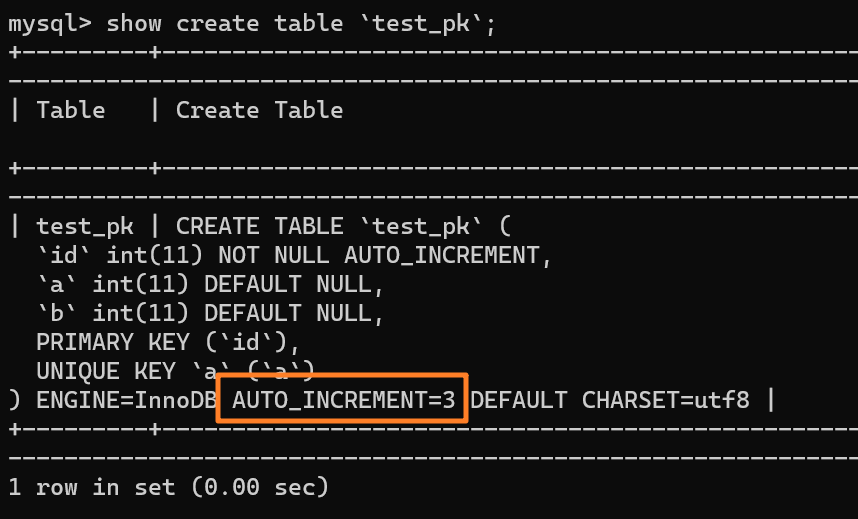
我們現在表里有一行 (1,1,1) 的記錄,AUTO_INCREMENT = 3:
 img
img
我們先插入一行數據 (null, 2, 2),也就是 (3, 2, 2) 嘛,并且 AUTO_INCREMENT 變為 4:
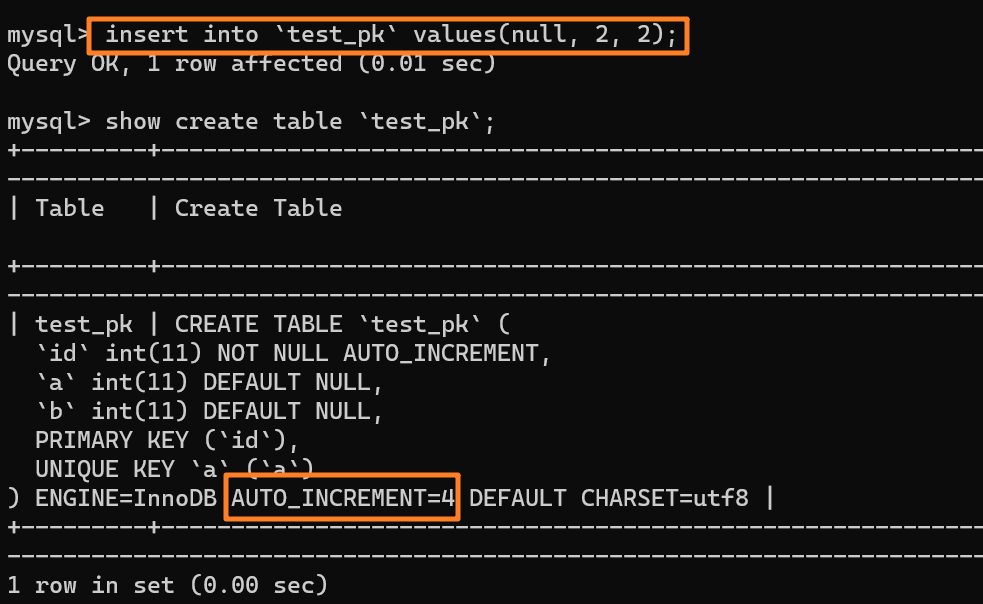 img
img
再去執行這樣一段 SQL:
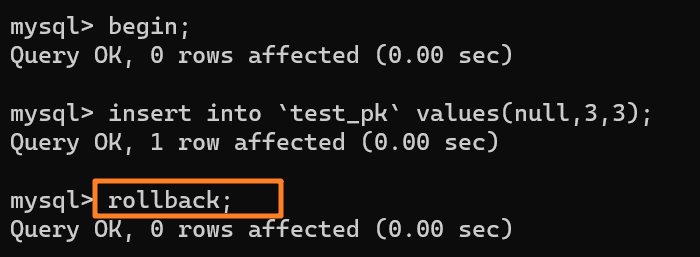 img
img
雖然我們插入了一條 (null, 3, 3) 記錄,但是使用 rollback 進行回滾了,所以數據庫中是沒有這條記錄的:
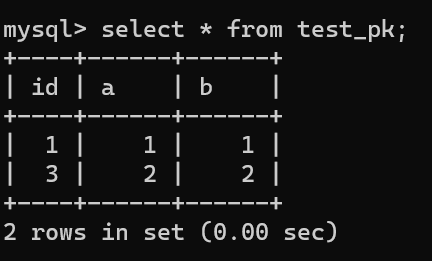
在這種事務回滾的情況下,自增值并沒有同樣發生回滾!如下圖所示,自增值仍然固執地從 4 增加到了 5:
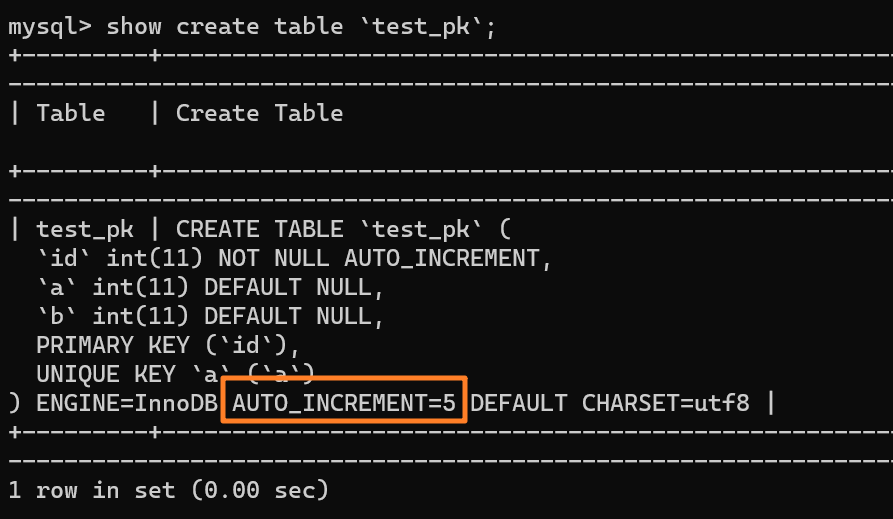
所以這時候我們再去插入一條數據(null, 3, 3)的時候,主鍵 id 就會被自動賦為 5 了:
那么,為什么在出現唯一鍵沖突或者回滾的時候,MySQL 沒有把表的自增值改回去呢?回退回去的話不就不會發生自增 id 不連續了嗎?
事實上,這么做的主要原因是為了提高性能。
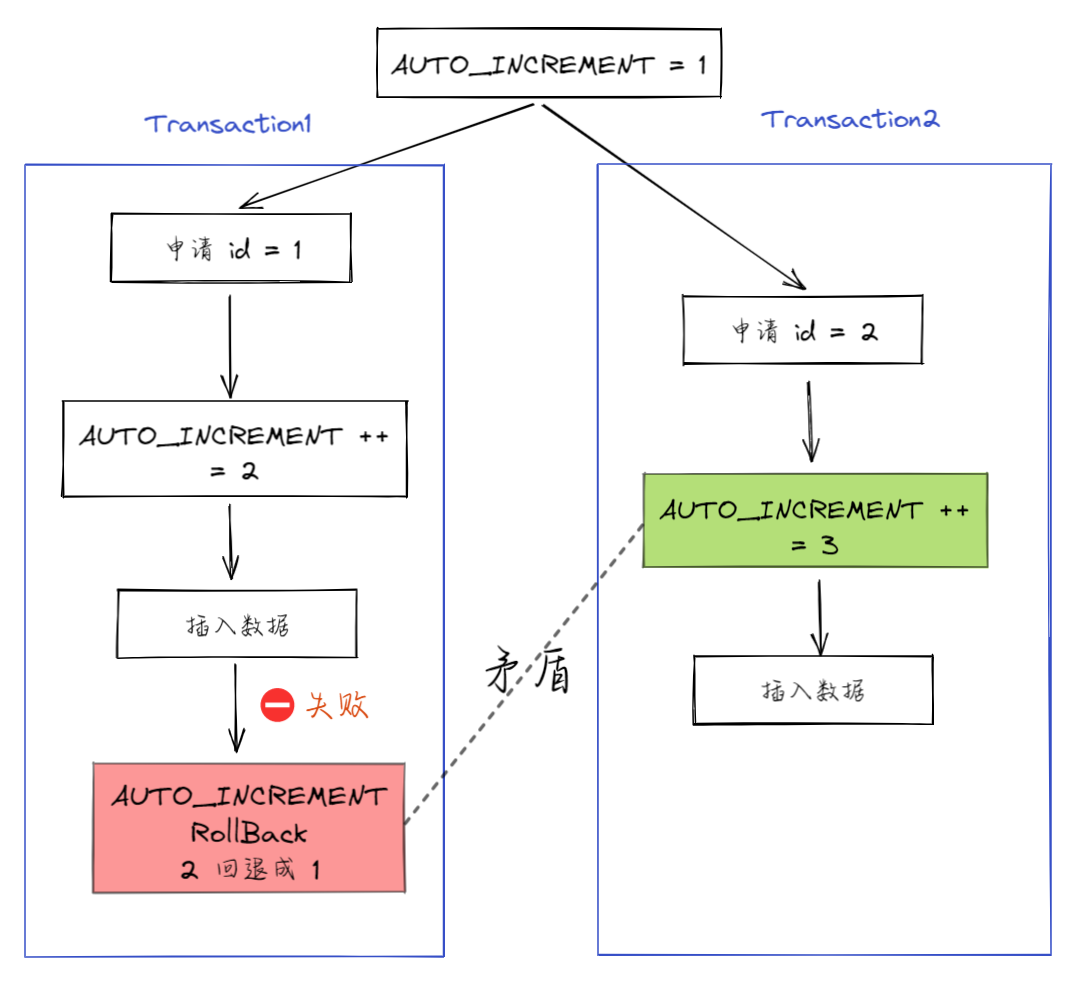
我們直接用反證法來驗證:假設 MySQL 在事務回滾的時候會把自增值改回去,會發生什么?
現在有兩個并行執行的事務 A 和 B,在申請自增值的時候,為了避免兩個事務申請到相同的自增 id,肯定要加鎖,然后順序申請,對吧。
假設事務 A 申請到了 id = 1, 事務 B 申請到 id=2,那么這時候表 t 的自增值是3,之后繼續執行。
事務 B 正確提交了,但事務 A 出現了唯一鍵沖突,也就是 id = 1 的那行記錄插入失敗了,那如果允許事務 A 把自增 id 回退,也就是把表的當前自增值改回 1,那么就會出現這樣的情況:表里面已經有 id = 2 的行,而當前的自增 id 值是 1。
接下來,繼續執行的其他事務就會申請到 id=2。這時,就會出現插入語句報錯“主鍵沖突”。
而為了解決這個主鍵沖突,有兩種方法:
每次申請 id 之前,先判斷表里面是否已經存在這個 id,如果存在,就跳過這個 id
把自增 id 的鎖范圍擴大,必須等到一個事務執行完成并提交,下一個事務才能再申請自增 id
很顯然,上述兩個方法的成本都比較高,會導致性能問題。而究其原因呢,是我們假設的這個 “允許自增 id 回退”。
因此,InnoDB 放棄了這個設計,語句執行失敗也不回退自增 id。也正是因為這樣,所以才只保證了自增 id 是遞增的,但不保證是連續的。
綜上,已經分析了三種自增值不連續的場景,還有第四種場景:批量插入數據。
自增值不連續場景 4
對于批量插入數據的語句,MySQL 有一個批量申請自增 id 的策略:
語句執行過程中,第一次申請自增 id,會分配 1 個;
1 個用完以后,這個語句第二次申請自增 id,會分配 2 個;
2 個用完以后,還是這個語句,第三次申請自增 id,會分配 4 個;
依此類推,同一個語句去申請自增 id,每次申請到的自增 id 個數都是上一次的兩倍。
注意,這里說的批量插入數據,不是在普通的 insert 語句里面包含多個 value 值!!!,因為這類語句在申請自增 id 的時候,是可以精確計算出需要多少個 id 的,然后一次性申請,申請完成后鎖就可以釋放了。
而對于 insert … select、replace … select 和 load data 這種類型的語句來說,MySQL 并不知道到底需要申請多少 id,所以就采用了這種批量申請的策略,畢竟一個一個申請的話實在太慢了。
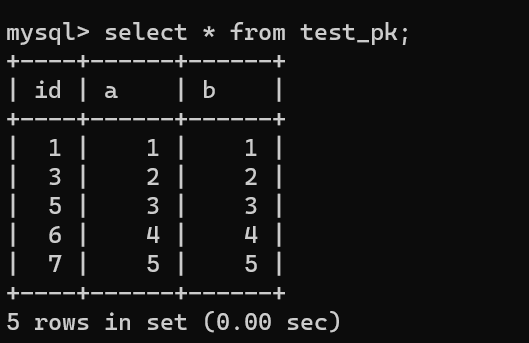
舉個例子,假設我們現在這個表有下面這些數據:
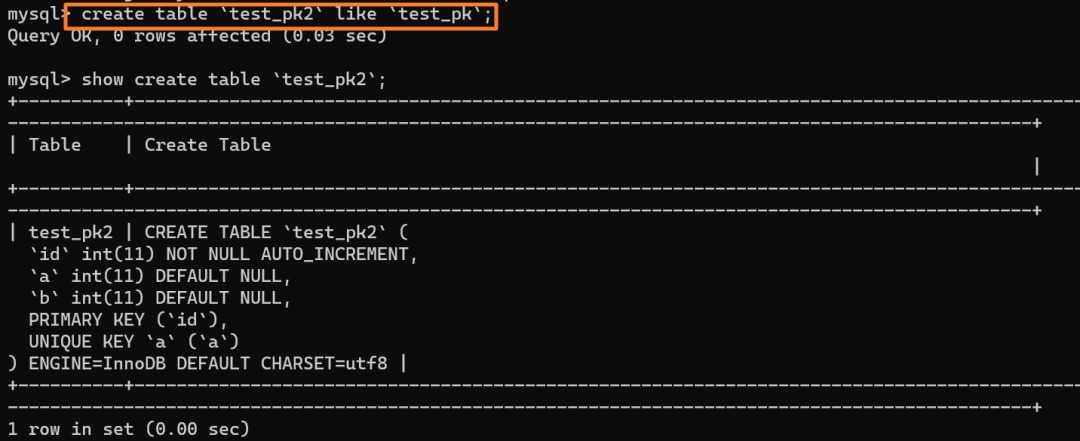
我們創建一個和當前表 test_pk 有相同結構定義的表 test_pk2:
 img
img
然后使用 insert...select 往 teset_pk2 表中批量插入數據:
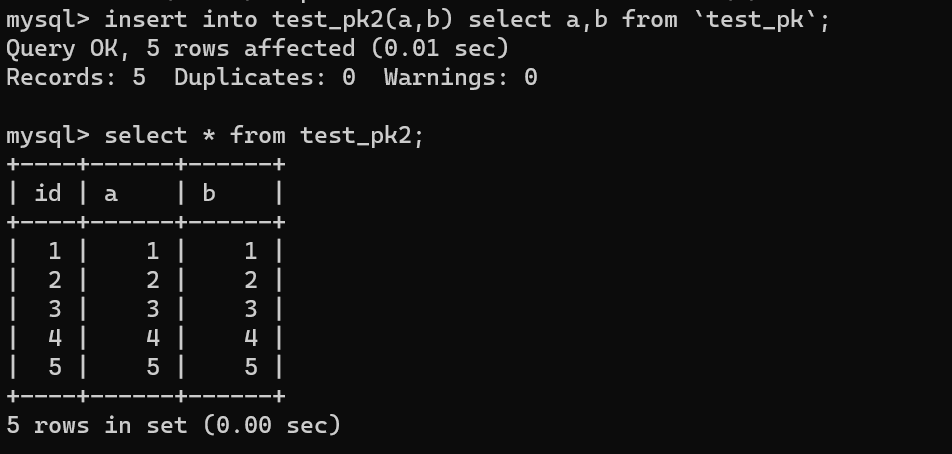
可以看到,成功導入了數據。
再來看下 test_pk2 的自增值是多少:
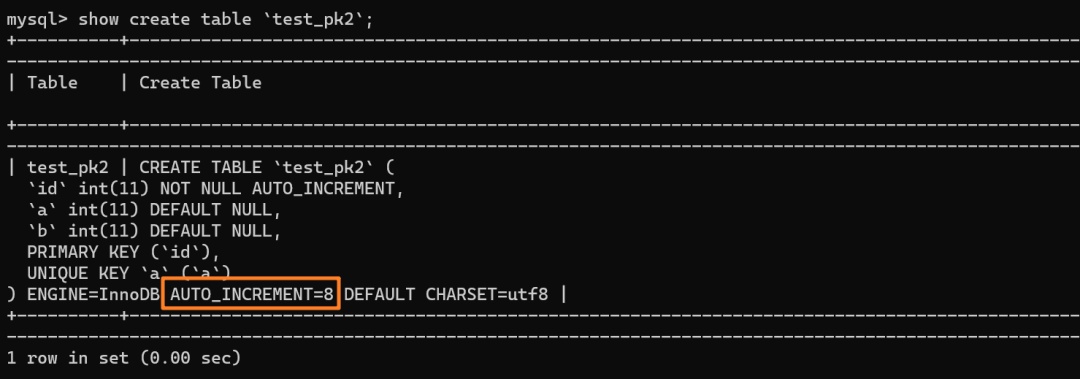
如上分析,是 8 而不是 6
具體來說,insert…select 實際上往表中插入了 5 行數據 (1 1)(2 2)(3 3)(4 4)(5 5)。但是,這五行數據是分三次申請的自增 id,結合批量申請策略,每次申請到的自增 id 個數都是上一次的兩倍,所以:
第一次申請到了一個 id:id=1
第二次被分配了兩個 id:id=2 和 id=3
第三次被分配到了 4 個 id:id=4、id = 5、id = 6、id=7
由于這條語句實際只用上了 5 個 id,所以 id=6 和 id=7 就被浪費掉了。之后,再執行 insert into test_pk2 values(null,6,6),實際上插入的數據就是(8,6,6):

小結
總結下自增值不連續的四個場景:
自增初始值和自增步長設置不為 1
唯一鍵沖突
事務回滾
批量插入(如 insert...select 語句)
審核編輯:劉清
-
Auto
+關注
關注
0文章
41瀏覽量
15237 -
MySQL
+關注
關注
1文章
789瀏覽量
26283 -
MYSQL數據庫
+關注
關注
0文章
95瀏覽量
9346 -
mysql觸發器
+關注
關注
0文章
6瀏覽量
1099
原文標題:美團面試:MySQL 自增主鍵一定是連續的嗎?
文章出處:【微信號:小林coding,微信公眾號:小林coding】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
怎么簡單實現由Labview讀取的串口數據自增寫入mysql5.7數據庫中?

阿里云mysql數據庫怎么設置主鍵自增和時間格式怎么顯示時分秒?
Python常用自增運算寫法
labview向oracle插入數據,怎樣可以主鍵自增1?如果不插入主鍵的字段,會報插入的數目與表中的數據不相等
MySQL表分區類型及介紹
關于MySQL的基礎知識簡析
21個MySQL表設計的經驗準則
線上MySQL的自增id用盡怎么辦?

id的機制不同在mysql的索引結構以及優缺點

MySQL索引的常用知識點
自增主鍵去哪了?---一次開發過程中的思考






 工商網監
工商網監
評論