 LabVIEW圖形化的AI視覺開發平臺(非NI Vision),大幅降低人工智能開發門檻
LabVIEW圖形化的AI視覺開發平臺(非NI Vision),大幅降低人工智能開發門檻
前言
之前每次進行機器學習和模型訓練的時候發現想要訓練不同模型的時候需要使用不同的框架,有時候費了九牛二虎之力終于寫下了幾百行代碼之后,才發現環境調試不通,運行效率也差強人意,于是自己寫了一個基于LabVIEW的機器視覺工具包,讓編程變得更簡單便捷的同時,還能夠使用多種框架和硬件加速。
一、工具包內容
此人工智能視覺工具包主要優勢如下:
- 圖形化編程,無需掌握文本編程基礎即可完成機器視覺項目。
- 多種攝像頭數據采集和矩陣計算。
- 數百種圖像算子的調用。
- 提供tensorflow、pytorch、caffe、darknet、onnx、paddle等多種框架深度學習模型的調用并實現推理。
- 支持Nvidia GPU、Intel、TPU、NPU多種加速。
- 提供近百個應用程序范例,包括物體分類、物體檢測、物體測量、圖像分割、 人臉識別、自然場景下OCR等多種實用場景。**
工具包中的函數選版如下:
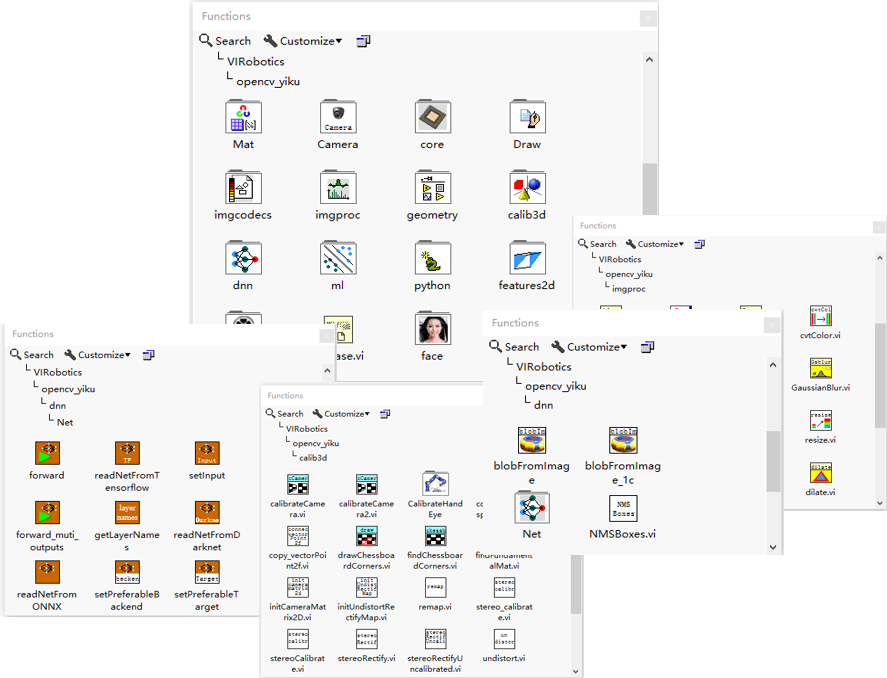
例如,一個攝像頭采集并進行yolov5目標檢測的范例程序,只需在LabVIEW中編寫簡單的圖形化程序,即可實現。在大量簡化編程難度的同時,也保持了c++的高效運行特性。
?
二、工具包下載鏈接
https://pan.baidu.com/s/1nyclNG8uMLnYBmcGKVDtWQ?pwd=yiku
三、實現物體識別
無論使用何種框架訓練物體檢測模型,都可以無縫集成到LabVIEW中,并使用智能視覺工具包提供的CUDA接口實現加速推理,模型包括但不限于:
- yolov3/yolov4/yolov5//yolox/pp-yolo
- SSD,Fastest-RCNN(物體檢測)
- mobileNet、VGGnet、Resnet、Densenet、Efficientnet等(物體分類)
通過算法優化,在LabVIEW中運行模型的速度明顯好于python,這對于對性能要求較高的工業現場來說非常友好實用。比如說:工地安全帽檢測、物體表面缺陷檢測等,如下圖使用yolov4進行物體識別,在GPU模式下,無論是運行速度和識別率都可以達到工業級別。。

實測過程中我們發現同一系統環境下,使用labview工具包的識別效率遠高于python識別效率。

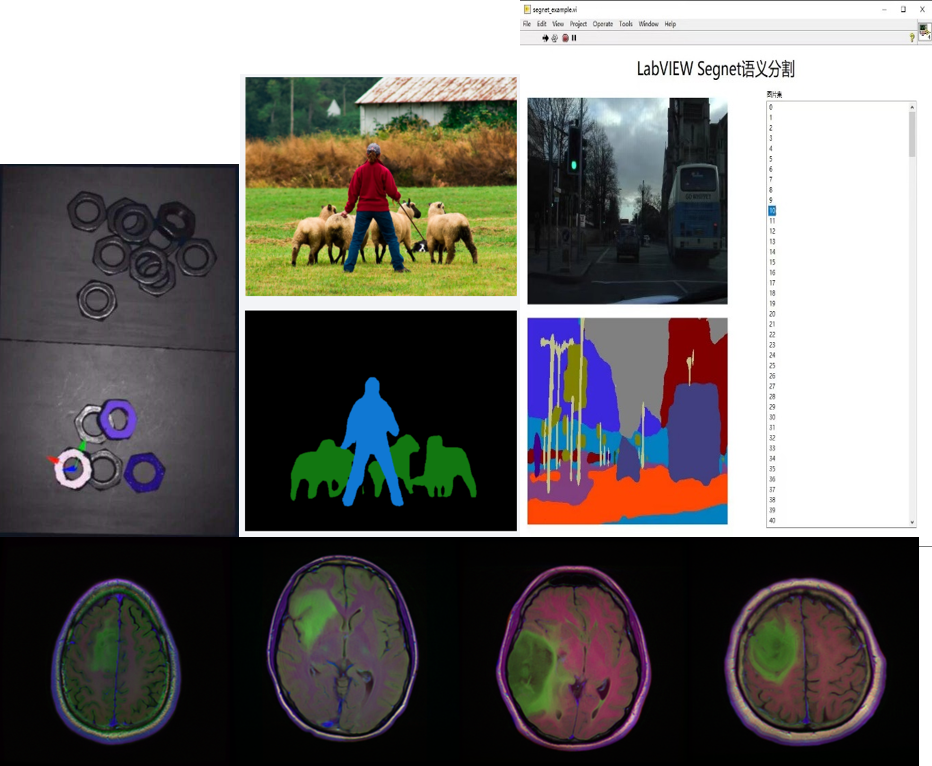
四、實現圖像分割
圖像分割是當今計算機視覺領域的關鍵問題之一。從宏觀上看,圖像分割是一項高層次的任務,為實現場景的完整理解鋪平了道路。場景理解作為一個核心的計算機視覺問題,其重要性在于越來越多的應用程序通過從圖像中推斷知識來提供營養。隨著深度學習軟硬件的加速發展,一些前沿的應用包括自動駕駛汽車、人機交互、醫療影像等,都開始研究并使用圖像分割技術。
本次集成的智能工具包提供了多種圖像分割的調用模塊,并實現了GPU模式下的加速運行。如:
語義分割:Segnet、deeplabv1~deeplabv3、u-net等;實例分割:Mask-RCNN、PANet等
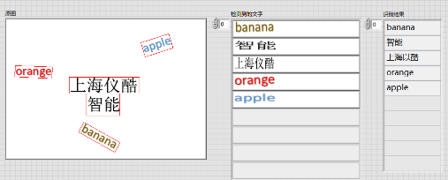
五、自然場景下的文字識別
人工智能提供了文本檢測定位(DB_TD500_resnet50、EAST)、文本識別的模塊(CRNN),用戶可以使用該模塊實現自然場景下的中英文文字識別
應用:身份證識別、表單識別、包裝盒標簽檢測等

總結
可以通過鏈接進行工具包的下載,如有問題可添加技術交流群進行進一步的探討。
審核編輯 黃宇
-
LabVIEW
+關注
關注
1963文章
3652瀏覽量
322400 -
AI
+關注
關注
87文章
30116瀏覽量
268403 -
人工智能
+關注
關注
1791文章
46851瀏覽量
237539 -
深度學習
+關注
關注
73文章
5492瀏覽量
120975
發布評論請先 登錄
相關推薦
《AI for Science:人工智能驅動科學創新》第6章人AI與能源科學讀后感
AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
risc-v在人工智能圖像處理應用前景分析
人工智能ai4s試讀申請
名單公布!【書籍評測活動NO.44】AI for Science:人工智能驅動科學創新
報名開啟!深圳(國際)通用人工智能大會將啟幕,國內外大咖齊聚話AI
浪潮信息發布AIStation 人工智能開發平臺V5升級版
意法半導體ST Edge AI Suite人工智能開發套件上線
5G智能物聯網課程之Aidlux下人工智能開發(SC171開發套件V2)
5G智能物聯網課程之Aidlux下人工智能開發(SC171開發套件V1)
嵌入式人工智能的就業方向有哪些?
圖漾科技發布3D工業視覺應用開發平臺Vision++





 工商網監
工商網監
評論