") 什么情況下使用RabbitMQ或 Kafka
什么情況下使用RabbitMQ或 Kafka
如果你問自己是否Apache Kafka比RabbitMQ更好或RabbitMQ是否比Apache Kafka更可靠,我想在這里阻止你。本文將從更廣泛的角度討論這兩種情況。它關(guān)注的是這兩個系統(tǒng)提供的功能,并將指導(dǎo)您做出正確的決定,決定何時使用哪個系統(tǒng)。
web上的一些文章讓Apache Kafka在RabbitMQ面前大出風(fēng)頭,而另一些文章則恰恰相反。我們中的很多人可能會因為聽了大肆宣傳,跟著人群跑而認罪。我覺得重要的是要知道是使用RabbitMQ還是Kafka取決于您項目的需求,只有當(dāng)您在合適的場景中使用了正確的設(shè)置,才能進行真正的比較。
我和84codes在業(yè)界工作了很長時間,通過服務(wù)CloudAMQP為RabbitMQ提供托管解決方案,通過服務(wù)CloudKarafka為Apache Kafka提供托管解決方案。由于我已經(jīng)看到了CloudAMQP和CloudKarafka用戶的許多用例和不同的應(yīng)用程序設(shè)置,我覺得我可以根據(jù)我的經(jīng)驗,在RabbitMQ和Apache Kafka上權(quán)威地回答用例問題。
在本文中,我的任務(wù)是根據(jù)多年來開發(fā)人員與開發(fā)人員之間的許多交談來分享自己的見解,并試圖傳達他們關(guān)于為什么選擇特定的message broker服務(wù)而不是其他服務(wù)的想法。
本文中使用的術(shù)語包括:
消息隊列在RabbitMQ中是一個隊列,而這個“隊列”在Kafka中被稱為日志,但是為了簡化本文中的信息,我將一直使用隊列而不是切換到“日志”。
卡夫卡的信息通常被稱為記錄,但是,為了簡化這里的信息,我將再次提到信息。
當(dāng)我在Kafka中撰寫一個主題時,您可以把它看作是消息隊列中的一個分類。卡夫卡主題被分成若干分區(qū),這些分區(qū)以不變的順序包含記錄。
這兩個系統(tǒng)都通過隊列或主題在生產(chǎn)者和消費者之間傳遞消息。消息可以包含任何類型的信息。例如,它可以包含網(wǎng)站上發(fā)生的事件的信息,也可以是觸發(fā)另一個應(yīng)用程序上的事件的簡單文本消息。
這種系統(tǒng)非常適合于連接不同的組件、構(gòu)建微服務(wù)、實時數(shù)據(jù)流或?qū)⒐ぷ鱾鬟f給遠程工作者。
根據(jù)Confluent的數(shù)據(jù),超過三分之一的財富500強公司使用Apache Kafka。各種大型行業(yè)也依賴于RabbitMQ,如Zalando、WeWork、Wunderlist和Bloomberg。
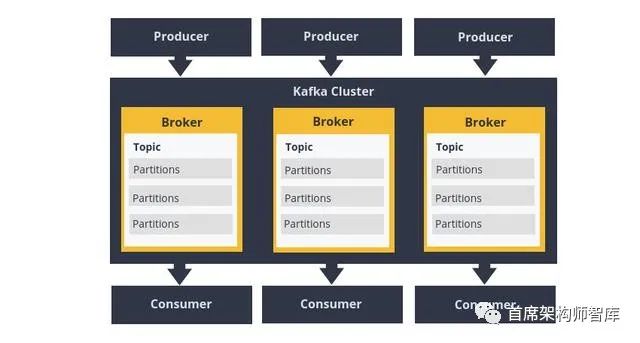
最大的問題;什么時候使用Kafka,什么時候使用RabbitMQ?
不久前,我在Stackoverflow上寫了一個答案來回答這個問題,“有任何理由使用RabbitMQ而不是Kafka嗎?”答案只有幾行字,但它已經(jīng)被證明是一個許多人發(fā)現(xiàn)有用的答案。
我將試著把答案分解成子答案,并試著解釋每一部分。首先,我寫道——“RabbitMQ是一個可靠的、成熟的、通用的消息代理,它支持一些協(xié)議,如AMQP、MQTT、STOMP等。RabbitMQ可以處理高吞吐量。它的一個常見用例是處理后臺作業(yè)或充當(dāng)微服務(wù)之間的消息代理。Kafka是一個消息總線優(yōu)化的高接入數(shù)據(jù)流和重放。Kafka可以看作是一個持久的消息代理,應(yīng)用程序可以在其中處理和重新處理磁盤上的流數(shù)據(jù)。
關(guān)于“成熟”一詞;RabbitMQ在市場上出現(xiàn)的時間比Kafka(分別是2007年和2011年)要長。RabbitMQ和Kafka都是“成熟的”,這意味著它們都被認為是可靠的、可擴展的消息傳遞系統(tǒng)。
消息處理(消息重放)
這是他們之間的主要區(qū)別;與大多數(shù)消息傳遞系統(tǒng)不同,Kafka中的消息隊列是持久的。發(fā)送的數(shù)據(jù)將一直存儲到經(jīng)過指定的保留期(一段時間或一個大小限制)為止。消息將一直停留在隊列中,直到超過保留期/大小限制,這意味著消息被使用后不會被刪除。相反,它可以被重放或多次使用,這是一個可以調(diào)整的設(shè)置。
在RabbitMQ中,消息被存儲起來,直到接收應(yīng)用程序連接并接收到隊列外的消息。客戶端可以在接收到消息或在完全處理完消息后ack(確認)消息。在任何一種情況下,一旦消息被處理,它就會從隊列中刪除。
如果您在Kafka中使用重播,請確保您使用它的方式和原因是正確的。將一個事件重復(fù)播放多次,而這個事件應(yīng)該只發(fā)生一次;例如,如果您碰巧多次保存客戶訂單,在大多數(shù)使用場景中并不理想。當(dāng)用戶中存在需要部署新版本的bug,并且需要重新處理部分或全部消息時,重播就會派上用場了。
協(xié)議
我還提到了“RabbitMQ支持一些標準化協(xié)議,如AMQP, MQTT, STOMP等”,其中它本機實現(xiàn)AMQP 0.9.1。使用標準化消息協(xié)議允許您將RabbitMQ代理替換為任何基于AMQP的代理。
Kafka在TCP/IP之上使用自定義協(xié)議在應(yīng)用程序和集群之間進行通信。Kafka不能被簡單地移除和替換,因為它是唯一實現(xiàn)這個協(xié)議的軟件。
RabbitMQ支持不同協(xié)議的能力意味著它可以在許多不同的場景中使用。
AMQP的最新版本與官方支持的0.9.1版本有很大不同。RabbitMQ不太可能偏離AMQP 0.9.1。該協(xié)議的1.0版本于2011年10月30日發(fā)布,但尚未獲得開發(fā)人員的廣泛支持。AMQP 1.0可通過插件使用。
路由
答案的下一部分是關(guān)于路由的,我寫道:“Kafka有一個非常簡單的路由方法。如果你需要以復(fù)雜的方式將消息傳遞給用戶,RabbitMQ有更好的選擇。”
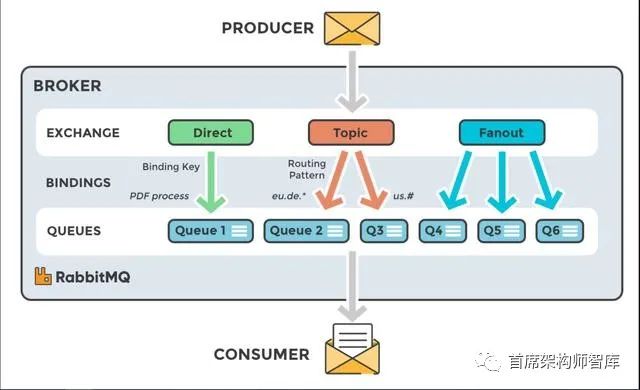
RabbitMQ的主要優(yōu)點是能夠靈活地路由消息。直接或基于正則表達式的路由允許消息到達特定隊列,而無需附加代碼。RabbitMQ有四種不同的路由選擇:直接、主題、扇出和頭交換。直接交換路由消息到所有隊列,這些隊列與所謂的路由密鑰完全匹配。扇形交換器可以向綁定到該交換器的每個隊列廣播一條消息。topics方法類似于direct,因為它使用一個路由鍵,但是允許通配符匹配和精確匹配。有關(guān)不同交換類型的更多信息可以在這里找到。
Kafka不支持路由;Kafka主題被劃分為多個分區(qū),這些分區(qū)以不變的順序包含消息。您可以使用消費者組和持久主題來替代RabbitMQ中的路由,在該路由中,您將所有消息發(fā)送到一個主題,但讓您的消費者組從不同的偏移量訂閱。
您可以在Kafka streams的幫助下自己創(chuàng)建動態(tài)路由,即動態(tài)地將事件路由到主題,但這不是默認特性。
消息優(yōu)先級
RabbitMQ支持所謂的優(yōu)先隊列,這意味著隊列可以被設(shè)置為具有一系列優(yōu)先級。可以在發(fā)布消息時設(shè)置每個消息的優(yōu)先級。根據(jù)消息的優(yōu)先級,它被放置在適當(dāng)?shù)膬?yōu)先級隊列中。那么,什么時候可以使用優(yōu)先隊列呢?下面是一個簡單的示例:我們每天都在為托管的數(shù)據(jù)庫服務(wù)ElephantSQL運行數(shù)據(jù)庫備份。數(shù)以千計的備份事件被無序地添加到RabbitMQ中。客戶還可以按需觸發(fā)備份,如果發(fā)生這種情況,我將一個新的備份事件添加到隊列中,但具有更高的優(yōu)先級。
在卡夫卡中,消息不能以優(yōu)先級發(fā)送,也不能按優(yōu)先級順序發(fā)送。無論客戶端有多忙,Kafka中的所有消息都按照接收它們的順序存儲和發(fā)送。
確認(提交或確認)
“確認”是在通信進程之間傳遞的信號,表示確認。,接收發(fā)送或處理的信息。
Kafka和RabbitMQ都支持生產(chǎn)者確認(RabbitMQ中的發(fā)布者確認),以確保發(fā)布的消息已安全到達代理。
當(dāng)節(jié)點向使用者傳遞消息時,它必須決定是否應(yīng)將該消息視為由使用者處理(或至少是接收)。客戶端可以在接收到消息時或在客戶端完全處理完消息后進行ack。
RabbitMQ可以考慮發(fā)送出去的消息,也可以等待使用者在收到消息后手動確認。
Kafka為分區(qū)中的每條消息維護一個偏移量。提交的位置是保存的最后一個偏移量。如果進程失敗并重新啟動,這是它將恢復(fù)到的偏移量嗎?Kafka中的使用者既可以定期地自動提交偏移量,也可以選擇手動控制提交的位置。
在不同版本的Apache Kafka中,Kafka是如何記錄哪些被使用了,哪些沒有被使用的。在早期版本中,使用者跟蹤偏移量。
當(dāng)RabbitMQ客戶端不能處理消息時,它也可以nack(否定確認)消息。消息將被返回到它來自的隊列中,就像它是一個新消息一樣;這在客戶端出現(xiàn)臨時故障時非常有用。
如何處理隊列?
RabbitMQ的隊列在空的時候是最快的,而Kafka被設(shè)計用來保存和分發(fā)大量的消息。Kafka用很少的開銷保留大量的數(shù)據(jù)。
嘗試RabbitMQ的人可能沒有意識到惰性隊列的特性。惰性隊列是將消息自動存儲到磁盤的隊列,從而最大限度地減少RAM的使用,但延長了吞吐量時間。根據(jù)我們的經(jīng)驗,惰性隊列創(chuàng)建了更穩(wěn)定的集群,具有更好的預(yù)測性能。如果你要一次發(fā)送很多消息(例如處理批處理任務(wù)),或者你認為你的用戶跟不上發(fā)布者的速度,我們建議你啟用惰性隊列。
擴展
擴展是指增加或減少系統(tǒng)容量的過程。RabbitMQ和Kafka可以以不同的方式伸縮,你可以調(diào)整消費者的數(shù)量,代理的能力或者向系統(tǒng)中添加更多的節(jié)點。
消費者擴展
如果發(fā)布速度更快,那么就可以使用RabbitMQ,那么隊列將開始增長,最終可能會產(chǎn)生數(shù)百萬條消息,最終導(dǎo)致RabbitMQ耗盡內(nèi)存。在這種情況下,您可以擴展處理(消費)您的消息的消費者數(shù)量。RabbitMQ中的每個隊列可以有許多使用者,而這些使用者都可以“競爭”使用來自隊列的消息。消息處理分布在所有活動的使用者中,因此在RabbitMQ中通過簡單地添加和刪除使用者就可以實現(xiàn)上下伸縮。
在Kafka中,分配使用者的方法是使用主題分區(qū),其中組中的每個使用者專用于一個或多個分區(qū)。您可以使用分區(qū)機制按業(yè)務(wù)鍵(例如,按用戶id、位置等)向每個分區(qū)發(fā)送不同的消息集。
擴展代理
我在stackoverflow的回答中寫道;“Kafka是基于水平擴展(添加更多機器)的想法而建立的,而RabbitMQ主要是為垂直擴展(添加更多功能)而設(shè)計的。”答案的這一部分是提供有關(guān)運行Kafka或RabbitMQ的機器的信息。
在RabbitMQ中,水平伸縮并不總是提供更好的性能。通過垂直擴展(添加更多Power)可以獲得最佳性能級別。在RabbitMQ中可以進行水平伸縮,但這意味著必須在節(jié)點之間建立集群,這可能會降低設(shè)置的速度。
在Kafka中,您可以通過向集群添加更多節(jié)點或向主題添加更多分區(qū)來擴展。這有時比像在RabbitMQ中那樣在現(xiàn)有的機器中添加CPU或內(nèi)存更容易。
許多人和博客,包括Confluent,都在談?wù)揔afka在縮放方面有多棒。當(dāng)然,卡夫卡可以比RabbitMQ擴展得更遠,因為對于你能買到的機器的強度總是有限制的。但是,在這種情況下,我們需要記住使用代理的原因。你可能有一個Kafka和RabbitMQ都可以支持的消息量,而沒有任何問題,我們大多數(shù)人不會處理RabbitMQ耗盡空間的規(guī)模。
日志壓縮
值得一提的是,在Apache Kafka中,RabbitMQ中不存在的一個特性是日志壓縮策略。日志壓縮確保Kafka始終保留單個主題分區(qū)隊列中每個消息鍵的最后已知值。Kafka只是簡單地保留消息的最新版本,并用相同的密鑰刪除舊版本。
日志壓縮可以看作是使用Kafka作為數(shù)據(jù)庫的一種方式。您可以將保留期設(shè)置為“永久”,或者對某個主題啟用日志壓縮,這樣數(shù)據(jù)就會永久存儲。
使用日志壓縮的一個示例是,在數(shù)千個正在運行的集群中顯示一個集群的最新狀態(tài)。我們存儲最終狀態(tài),而不是存儲集群是否一直在響應(yīng)。可以立即獲得最新信息,比如隊列中當(dāng)前有多少條消息。
監(jiān)控
RabbitMQ有一個用戶友好的界面,讓你監(jiān)控和處理你的RabbitMQ服務(wù)器從一個網(wǎng)絡(luò)瀏覽器。除了其他功能外,隊列、連接、通道、交換器、用戶和用戶權(quán)限可以在瀏覽器中處理(創(chuàng)建、刪除和列出),并且可以手動監(jiān)控消息率和發(fā)送/接收消息。
對于Kafka,我們有很多用于監(jiān)控的開源工具,也有一些商業(yè)工具,提供管理和監(jiān)控功能。有關(guān)Kafka的不同監(jiān)視工具的信息可以在這里找到。
推或拉
消息從RabbitMQ推送到使用者。配置預(yù)取限制以防止令使用者不堪重負(如果消息到達隊列的速度比使用者處理它們的速度快)是很重要的。消費者也可以從RabbitMQ獲取消息,但不推薦這樣做。另一方面,Kafka使用拉取模型,如前所述,消費者從給定的偏移量請求一批消息。
許可證
RabbitMQ最初由Rabbit Technologies Ltd公司創(chuàng)建。該項目于2013年5月成為Pivotal Software的一部分。RabbitMQ的源代碼是在Mozilla公共許可下發(fā)布的。牌照從未更改(截至2019年11月)。
Kafka最初是由LinkedIn創(chuàng)建的。2011年,它被授予開源地位,并移交給了Apache基金會。Apache Kafka受Apache 2.0許可證的保護。一些經(jīng)常與Kafka組合使用的組件由另一個名為Confluent Community許可證所涵蓋,例如Rest Proxy、Schema Registry和KSL。這個許可證仍然允許人們免費下載、修改和重新分發(fā)代碼(非常像Apache 2.0所做的),但是它不允許任何人以SaaS的形式提供軟件。
這兩個許可證都是免費和開源軟件許可證。如果Kafka再一次將許可證更改為更嚴格的東西,這就是RabbitMQ的優(yōu)勢所在,因為它可以很容易地被另一個AMQP經(jīng)紀人取代,而Kafka不能。
復(fù)雜性
就我個人而言,我認為開始使用RabbitMQ更容易,并且發(fā)現(xiàn)它很容易使用。正如我們的一位客戶所說;
“我們沒有花任何時間學(xué)習(xí)RabbitMQ,它工作了很多年。在DoorDash的高速增長期間,它無疑降低了大量的運營成本。”Zhaobang Liu Doordash
在我看來,Kafka的架構(gòu)帶來了更多的復(fù)雜性,因為它從一開始就包含了更多的概念,比如主題/分區(qū)/消息偏移量等等。你必須熟悉消費者群體以及如何處理抵消。
作為Kafka和RabbitMQ操作符,我們覺得在Kafka中處理失敗有點復(fù)雜。恢復(fù)或修復(fù)某些東西的過程通常更耗費時間,也更麻煩一些。
卡夫卡的生態(tài)系統(tǒng)
Kafka不僅僅是一個經(jīng)紀人,它是一個流媒體平臺,還有很多工具可以在主發(fā)行版之外很容易地與Kafka集成。Kafka生態(tài)系統(tǒng)由Kafka核心、Kafka流、Kafka連接、Kafka REST代理和模式注冊表組成。請注意,Kafka生態(tài)系統(tǒng)的大多數(shù)附加工具都來自于Confluent,而不是Apache的一部分。
所有這些工具的好處是,您可以在需要編寫一行代碼之前配置一個巨大的系統(tǒng)。
Kafka Connect讓您集成其他系統(tǒng)與Kafka。您可以添加一個數(shù)據(jù)源,允許您使用來自該數(shù)據(jù)源的數(shù)據(jù)并將其存儲在Kafka中,或者相反,將主題中的所有數(shù)據(jù)發(fā)送到另一個系統(tǒng)進行處理或存儲。使用Kafka Connect有很多可能性,而且很容易上手,因為已經(jīng)有很多可用的連接器。
Kafka REST代理讓您有機會從集群接收元數(shù)據(jù),并通過簡單的REST API生成和使用消息。可以從集群的控制面板輕松啟用該特性。
常見用例——RabbitMQ vs Apache Kafka
關(guān)于一個系統(tǒng)能做什么或不能做什么,有很多信息。下面是兩個主要用例,描述了我和我們的許多客戶是如何考慮和決定使用哪個系統(tǒng)的。當(dāng)然,我們也看到過這樣的情況:客戶在構(gòu)建一個系統(tǒng)時,應(yīng)該使用一個系統(tǒng),而不是另一個系統(tǒng)。
RabbitMQ的用例
一般來說,如果您想要一個簡單/傳統(tǒng)的發(fā)布-訂閱消息代理,那么RabbitMQ是一個明顯的選擇,因為它的規(guī)模很可能比您所需要的更大。如果我的需求足夠簡單,可以通過通道/隊列來處理系統(tǒng)通信,并且不需要保留和流,我就會選擇RabbitMQ。
我選擇RabbitMQ主要有兩種情況;對于長時間運行的任務(wù),當(dāng)我需要運行可靠的后臺作業(yè)時。以及應(yīng)用程序內(nèi)部和應(yīng)用程序之間的通信和集成。e作為微服務(wù)之間的中間人,系統(tǒng)只需通知系統(tǒng)的另一部分開始處理一項任務(wù),比如在網(wǎng)上商店的訂單處理(下訂單、更新訂單狀態(tài)、發(fā)送訂單、付款等)。
長時間運行的任務(wù)
消息隊列支持異步處理,這意味著它們允許您在不立即處理消息的情況下將消息放入隊列。RabbitMQ非常適合長時間運行的任務(wù)。
在我們的RabbitMQ初學(xué)者指南中可以找到一個例子,它遵循一個經(jīng)典的場景,即一個web應(yīng)用程序允許用戶上傳信息到一個web站點。該網(wǎng)站將處理這些信息,生成PDF,并通過電子郵件發(fā)送給用戶。完成本例中的任務(wù)需要幾秒鐘,這就是為什么要使用消息隊列的原因之一。
我們的許多客戶讓RabbitMQ隊列充當(dāng)事件總線,使web服務(wù)器能夠快速響應(yīng)請求,而不是被迫當(dāng)場執(zhí)行計算密集型任務(wù)。
以Softonic為例,他們在一個每月支持1億用戶的基于事件的微服務(wù)體系結(jié)構(gòu)中使用了RabbitMQ。
微服務(wù)架構(gòu)中的中間人
RabbitMQ也被許多客戶用于微服務(wù)體系結(jié)構(gòu),作為應(yīng)用程序之間通信的一種方式,避免了傳遞消息的瓶頸。
例如,您可以閱讀Parkster(一個數(shù)字停車服務(wù))如何使用RabbitMQ將一個系統(tǒng)分解為多個微服務(wù)。
MapQuest是一個大方向服務(wù),每月支持2310萬獨立移動用戶。地圖更新被發(fā)布到組織和公司的個人設(shè)備和軟件上。這里,RabbitMQ主題分布在適當(dāng)數(shù)量的隊列上。數(shù)千萬用戶通過該框架接收到準確的企業(yè)級地圖信息。
Apache Kafka的用例
通常,如果您需要一個用于存儲、讀取(重復(fù)讀取)和分析流數(shù)據(jù)的框架,請使用Apache Kafka。它非常適合被審計的系統(tǒng)或需要永久存儲消息的系統(tǒng)。這些也可以分解為兩個主要用例,用于分析數(shù)據(jù)(跟蹤、攝取、日志記錄、安全等)或?qū)崟r處理。
數(shù)據(jù)分析:跟蹤、攝入、日志記錄、安全
在所有這些情況下,需要收集、存儲和處理大量的數(shù)據(jù)。需要洞察數(shù)據(jù)、提供搜索功能、審計或分析大量數(shù)據(jù)的公司證明使用Kafka是合理的。
據(jù)Apache Kafka的創(chuàng)建者說,Kafka最初的用例是跟蹤網(wǎng)站活動,包括頁面瀏覽、搜索、上傳或用戶可能采取的其他行動。這種類型的活動跟蹤通常需要非常高的吞吐量,因為會為每個操作和每個用戶生成消息。許多這些活動——實際上是所有的系統(tǒng)活動——都可以存儲在Kafka中并根據(jù)需要進行處理。
數(shù)據(jù)生產(chǎn)者只需要將數(shù)據(jù)發(fā)送到單個位置,而后端服務(wù)主機可以根據(jù)需要使用數(shù)據(jù)。主要的分析、搜索和存儲系統(tǒng)都與Kafka集成。
Kafka可以用來將大量的信息流傳輸?shù)酱鎯ο到y(tǒng)中,而且這些天硬盤空間的花費并不大。
實時處理
Kafka作為一個高吞吐量分布式系統(tǒng);源服務(wù)將數(shù)據(jù)流推入目標服務(wù),目標服務(wù)實時拉出數(shù)據(jù)流。
卡夫卡可以在系統(tǒng)處理許多生產(chǎn)者實時與少數(shù)消費者;例如,財務(wù)IT系統(tǒng)監(jiān)控股票數(shù)據(jù)。
從Spotify到荷蘭合作銀行的流媒體服務(wù)通過Kafka實時發(fā)布信息。實時處理高吞吐量的能力增強了應(yīng)用程序的能力。,使得這些應(yīng)用程序比以往任何時候都更強大。
CloudAMQP在服務(wù)器設(shè)置的自動化過程中使用了RabbitMQ,但我們在發(fā)布日志和指標時使用了Kafka。
-
Apache
+關(guān)注
關(guān)注
0文章
64瀏覽量
12454 -
kafka
+關(guān)注
關(guān)注
0文章
50瀏覽量
5211 -
rabbitmq
+關(guān)注
關(guān)注
0文章
17瀏覽量
1016
發(fā)布評論請先 登錄
相關(guān)推薦
什么情況下使用DMA?如何去使用DMA
什么情況下數(shù)據(jù)能恢復(fù)和不能恢復(fù)
volte語音通話有什么用,什么情況下可以開/關(guān)volte
什么情況下芯片容易壞呢
什么情況下使用示波器
什么情況下選用工業(yè)主板

什么情況下使用RabbitMQ或 Kafka





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論