 那些年在pytorch上踩過的坑
那些年在pytorch上踩過的坑
今天又發現了一個pytorch的小坑,給大家分享一下。手上兩份同一模型的代碼,一份用tensorflow寫的,另一份是我拿pytorch寫的,模型架構一模一樣,預處理數據的邏輯也一模一樣,測試發現模型推理的速度也差不多。一份預處理代碼是為pytorch模型寫的,用到的庫是torch,另一份是為tensorflow寫的,用到的是numpy。在訓練時,每個epoch耗時居然差距非常大,pytorch的代碼在140w條數據上訓練每輪耗時約45min,而tensorflow版的代碼耗時僅約12min。
我把代碼看了又看,百思不得其解,預處理的代碼比較復雜,都包含兩個for循環,pytorch版代碼我把更多的預處理步驟放到了Dataset里,這樣訓練時加載每個batch后,再要處理的步驟就更少了,速度也應該更快,而tensorflow版代碼的for循環里預處理的步驟明明更多,怎么會速度比我的代碼還快呢?然而,經過我的測試發現,從加載每個batch的數據進來開始,經過預處理,直到輸入到模型做計算前,兩者的耗時差了約7~8倍。最后發現問題出在對pytorch的tensor進行了頻繁的索引操作。
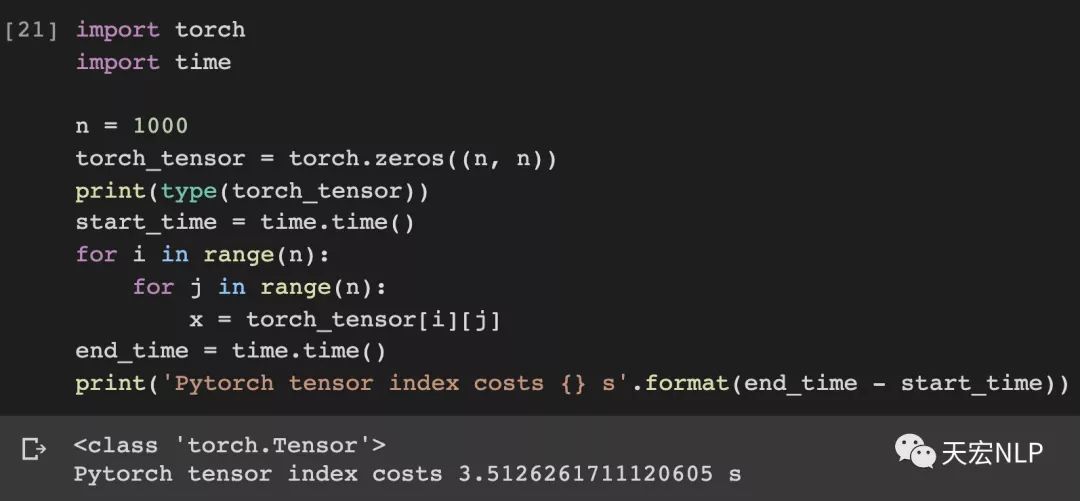
下面做個實驗給大家直觀體驗一下,對tensor做索引和對array做索引的速度差距有多大,tensor和array都是大小(1000x1000)的二維數組。
Pytorch(version==1.4.1)索引1000000次耗時:3.51秒
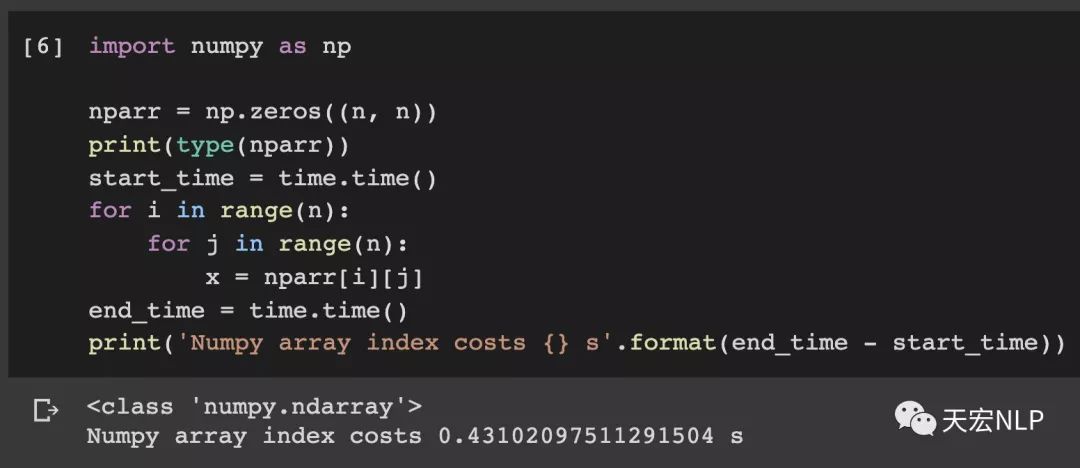
Numpy索引1000000次耗時:0.43秒
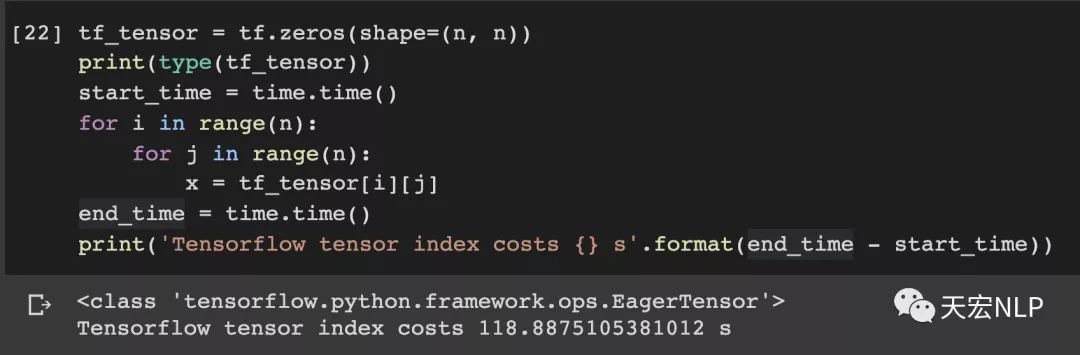
我還特意對比了一下對TensorFlow的tensor做索引的耗時
TensorFlow(version==2.1.0)索引1000000次耗時:118.89秒
由此可見tensor和array的索引速度至少差距在10倍,不過這也在情理之中,畢竟tensor要比array“重”得多。因此在使用pytorch和tensorflow時,頻繁需要索引的操作一定要先把tensor轉換為numpy.array來做!
除此之外,與其對二維數組進行索引,不如將其展平為一維數組,算上展平的時間,速度還會有不少提升。
Pytorch從3.51秒降到了1.94秒
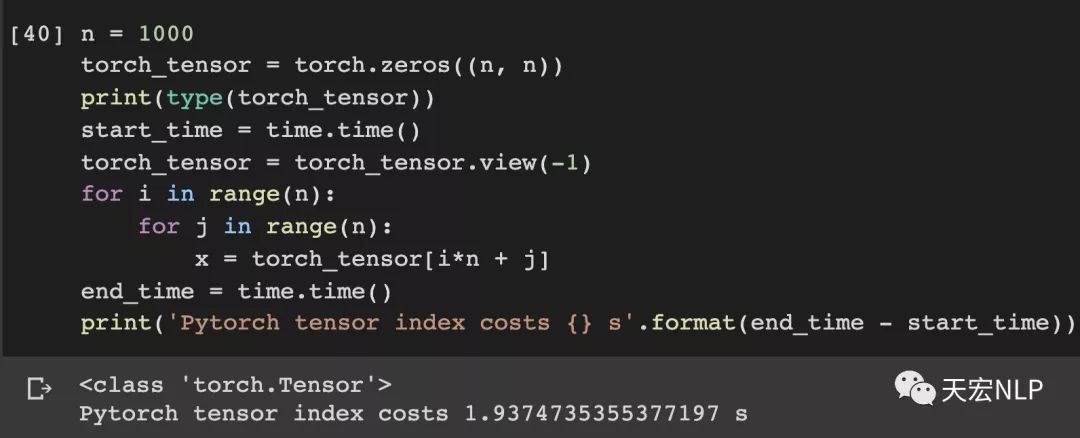
Numpy從0.43秒降到了0.29秒
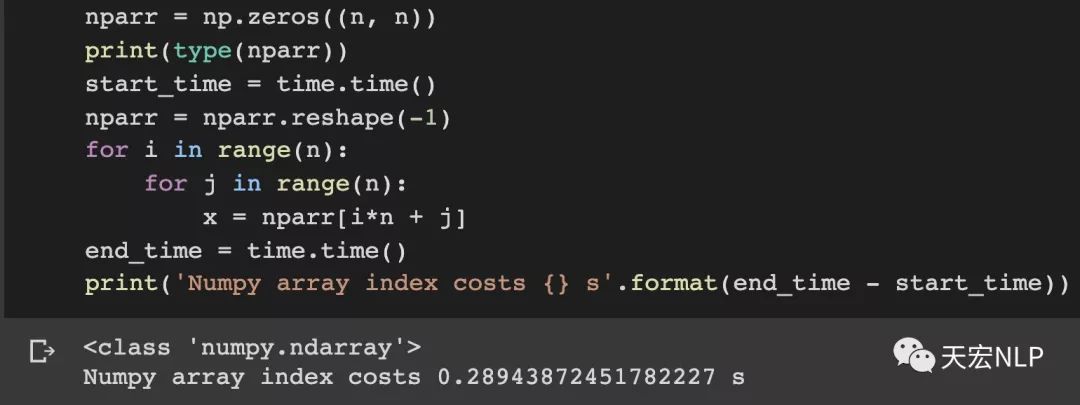
如果在訓練和數據預處理過程中發現自己的代碼跑起來速度非常慢,記得看一看有沒有對tensor做太多次索引,如果有的話,要把它轉為numpy.array,還有,盡量把二維、三維的索引變成一維的索引,這些都能加快你訓練模型的速度。
PS:最后我的代碼終于訓練一輪也只需要不到12min了,后來又找了點加速的辦法,把訓練一輪的時間控制到了9min以內,這些就放在以后再寫吧~
-
代碼
+關注
關注
30文章
4747瀏覽量
68348 -
tensorflow
+關注
關注
13文章
328瀏覽量
60498 -
pytorch
+關注
關注
2文章
803瀏覽量
13146
發布評論請先 登錄
相關推薦
使用STM32采集電池電壓踩過的那些坑
開發STM32 USB HID踩過的坑
使用樹莓派搭建stm32開發環境踩過的坑以及碰到的問題
移植debian系統踩過的坑
使用STM32采集電池電壓踩過的坑資料下載







 工商網監
工商網監
評論