") 那些年在pytorch上過的當
那些年在pytorch上過的當
起因
最近在修改上一個同事加載和預處理數(shù)據(jù)的代碼,原版的代碼使用tf1.4.1寫的,數(shù)據(jù)加載也是完全就是for循環(huán)讀取+預處理,每讀入并預處理好一個batch就返回丟給模型訓練,如此往復,我覺得速度實在太慢了,而且我新寫的代碼都是基于pytorch,雖然預處理的過程很復雜,我還是下決心自己改寫。
用pytorch加載預處理數(shù)據(jù),最常用的就是torch.utils.data.Dataset和torch.utils.data.DataLoader組合起來,把數(shù)據(jù)預處理都在Dataset里寫好,再在DataLoader里設定batch_size, shuffle等參數(shù)去加載數(shù)據(jù),網(wǎng)上的教程非常多,這里我就不展開講了。
過程
現(xiàn)在我已經(jīng)獲得了train_loader和test_loader,可以從它們里面每次讀取一個batch出來訓練,可照理說加載Dataset時占用了大量內(nèi)存是正常的,因為數(shù)據(jù)都預加載好了,就只需要用DataLoader讀取就行了,但在訓練的過程中,內(nèi)存不應該隨著訓練而逐漸增加。我眼睜睜看著內(nèi)存占用從8、9個g,逐漸漲到了25個g,程序最終因為占滿內(nèi)存而崩潰。檢查了半天自己的代碼都沒找出問題所在,后來用memory_profiler查看內(nèi)存占用情況,發(fā)現(xiàn)問題主要出現(xiàn)在這一行代碼:actual_labels += list(correctness),correctness的類型是torch.FloatTensor,actual_labels是python原生的list。
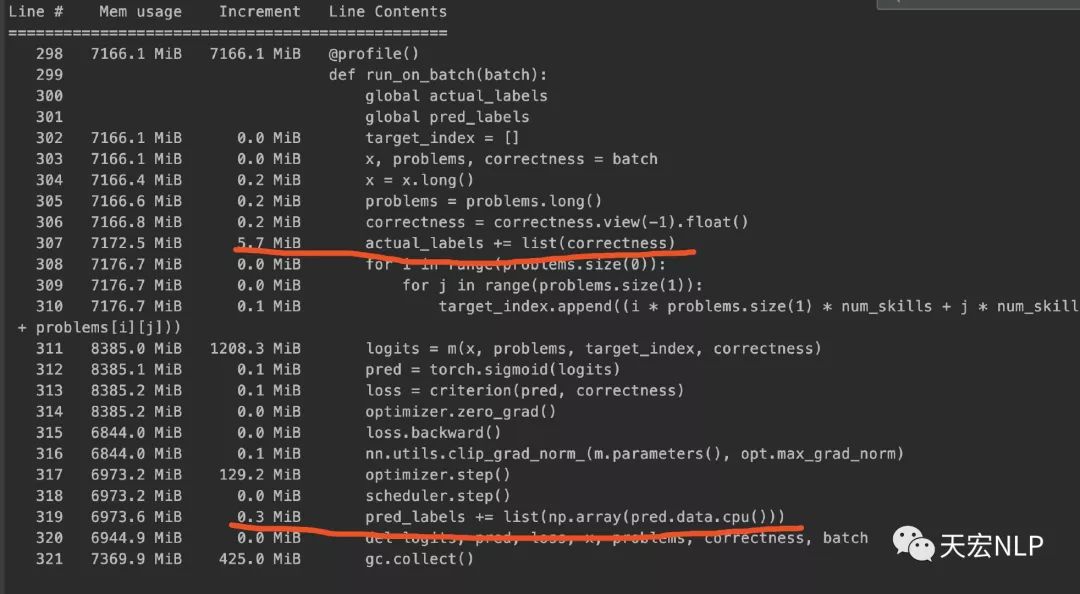
pred和correctness是同類型同長度的tensor,在將其轉(zhuǎn)換為list再添加到已有的list中時,占用的內(nèi)存相差了約5個Mb,于是我將上面代碼改寫為:

問題解決了!
為什么下面的代碼就沒事,上面直接將Tensor轉(zhuǎn)為list就會發(fā)生這種奇怪的現(xiàn)象?我去github和知乎看到了遇到類似問題的issue與文章,下面是鏈接
- https://github.com/pytorch/pytorch/issues/13246
- https://zhuanlan.zhihu.com/p/86286137
- https://github.com/pytorch/pytorch/issues/17499
結(jié)論
目前得到的結(jié)論大概是python list的design有問題,導致了這種情況發(fā)生,pytorch團隊雖然竭力修復,但他們表示因為這是python設計的缺陷,超出了他們的能力范圍,上面第一個issue主要是針對DataLoader里num_workers>0時會導致內(nèi)存泄漏,里面也提到了list與tensor互轉(zhuǎn)亦會發(fā)生內(nèi)存泄漏,這個issue已經(jīng)一年多了還沒能close。
因此,在使用pytorch時,應該盡力避免list的使用,一定不能讓tensor和list直接互相轉(zhuǎn)換,如果一定要做,應該將tensor從cuda轉(zhuǎn)到cpu上,轉(zhuǎn)為numpy.array,最后轉(zhuǎn)為list,反之亦然。
-
代碼
+關(guān)注
關(guān)注
30文章
4751瀏覽量
68359 -
for循環(huán)
+關(guān)注
關(guān)注
0文章
61瀏覽量
2493 -
pytorch
+關(guān)注
關(guān)注
2文章
803瀏覽量
13150
發(fā)布評論請先 登錄
相關(guān)推薦
Pytorch模型訓練實用PDF教程【中文】
如何往星光2板子里裝pytorch?
pytorch模型轉(zhuǎn)換需要注意的事項有哪些?
基于PyTorch的深度學習入門教程之PyTorch簡單知識
PyTorch1.8和Tensorflow2.5該如何選擇?
那些年在pytorch上踩過的坑





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論