") 什么是FM模型對用戶分類
什么是FM模型對用戶分類

一.項目背景
新零售時代背景下,商家要提升顧客的價值,讓20%的顧客貢獻(xiàn)80%的業(yè)績(二八定律),這就是超級用戶思維。超級用戶,是指對品
牌認(rèn)可、購買頻次多、購買金額大且能給商家反饋意見、并能把產(chǎn)品推薦別人購買,對商家具有較高忠誠度、與商家建立起強關(guān)系的用戶。
該項目尋找的是準(zhǔn)超級用戶(FM模型,也即購買頻次多和購買金額大的客戶),為將來轉(zhuǎn)化為超級用戶打好基礎(chǔ)。
二.理論基礎(chǔ)
1.購買頻次篩選標(biāo)準(zhǔn)
通過分組法,按買家賬號進(jìn)行分組,確定每個買家的購買頻次。然后按購買頻次進(jìn)行等距分組,統(tǒng)計每個頻次區(qū)間內(nèi)買家數(shù)量,找出人數(shù)差最大的兩個相鄰頻次區(qū)間并把這兩個相鄰區(qū)間的中間值作為購買頻次的篩選標(biāo)準(zhǔn)。
比如這兩個相鄰頻次區(qū)間是[3, 7), [7, 10), 選擇7作為購買頻次篩選標(biāo)準(zhǔn)。>=7的購買頻次被認(rèn)定為高購買頻次。該方法的思想是尋找第一個異常點,特別適合隨著頻次區(qū)間數(shù)值上的增加,人數(shù)遞減的情況,比如這樣的人數(shù)分布:
{[1, 3):1000, [3, 5):550, [5, 7):230, [7, 9):96, [9, 11):22, [11, 13):6}
2.購買金額篩選標(biāo)準(zhǔn)
通過箱線圖法,將購買金額排序,然后進(jìn)行四分位,得到三個分位數(shù):Q1,Q2,Q3。接著按下面公式計算購買金額篩選標(biāo)準(zhǔn):
V(購買金額篩選標(biāo)準(zhǔn))=Q3+IQR_coefficient*IQR,其中IQR=Q3-Q1,IQR_coefficient的值可以自定義,一般選為1.5或3。
>=V的購買金額為高購買金額
三.實現(xiàn)步驟
1.獲取數(shù)據(jù)
import pandas as pd
import numpy as np
#獲取數(shù)據(jù)
def get_data(file_path):
#讀取數(shù)據(jù)
df=pd.read_excel(file_path,index=0)
#篩選數(shù)據(jù)
data=df[['買家賬號','已付金額']]
#返回數(shù)據(jù)
return data
#獲取數(shù)據(jù)
data=get_data('./data.xlsx')
#查看數(shù)據(jù)
data.head()
2.處理數(shù)據(jù)
#處理數(shù)據(jù)
def process_data(df):
#判斷是否有重復(fù)值
if df.duplicated().sum()==0:
print('沒有重復(fù)值')
else:
#計算重復(fù)數(shù)據(jù)數(shù)量
len_dup=len(df[df.duplicated()==True])
print(f'重復(fù)數(shù)據(jù)有{len_dup}條')
#刪除重復(fù)值
df.drop_duplicates(inplace=True)
#判斷是否有缺失值
if df.isnull().any().sum()==0:
print('沒有缺失值')
else:
#計算缺失數(shù)據(jù)數(shù)量
len_null=len(df[df.isnull().T.any()])
print(f'缺失數(shù)據(jù)有{len_null}條')
#刪除數(shù)據(jù)
df.dropna(inplace=True)
#返回數(shù)據(jù)
return df
#處理數(shù)據(jù)
data=process_data(data)
#查看數(shù)據(jù)
data.head()
3.按照分組標(biāo)準(zhǔn)對用戶分類
#獲取準(zhǔn)超級用戶
def before_superCustomer(data,coeff,bin_num):
#統(tǒng)計客戶購買次數(shù)
df1=data['買家賬號'].value_counts().reset_index().rename(columns={'index':'買家賬號','買家賬號':'購買頻次'})
#統(tǒng)計客戶購買金額
df2=data.groupby(['買家賬號'])['已付金額'].sum()
#通過買家賬號連接數(shù)據(jù),
df=pd.merge(df1,df2,on='買家賬號')
#篩選所需數(shù)據(jù)
df_res=df[['買家賬號','購買頻次','已付金額']]
#對購買頻詞進(jìn)行切分
cut = pd.cut(df['購買頻次'], bins=bin_num)
#統(tǒng)計購買頻詞
top = pd.value_counts(cut)
#獲取高度差值最大的兩個分組區(qū)間,前一個分組區(qū)間的右區(qū)間值用于高購買頻次客戶的評判標(biāo)準(zhǔn)
top_index = top.diff().abs().values.argmax()
#獲取四分之三分位數(shù)
Q3 = df_res.describe()['已付金額'][6]
#獲取四分之一分位數(shù)
Q1 = df_res.describe()['已付金額'][4]
#計算IQR
IQR = Q3-Q1
#獲取準(zhǔn)超級用戶購買金額最小值
min_value = Q3 + 1.5* IQR
# 根據(jù)高購買金額和高購買頻次用戶標(biāo)準(zhǔn)過濾用戶
df_res=df_res[(df_res['購買頻次'] >top.index[top_index].right) & (df_res['已付金額'] >min_value)]
#按照已付金額進(jìn)行降序排序
df_res.sort_values('已付金額',ascending=False,inplace=True)
#返回數(shù)據(jù)
return df_res
#對用戶進(jìn)行分類
df_res=before_superCustomer(data,3,16)
#查看數(shù)據(jù)
df_res.head()
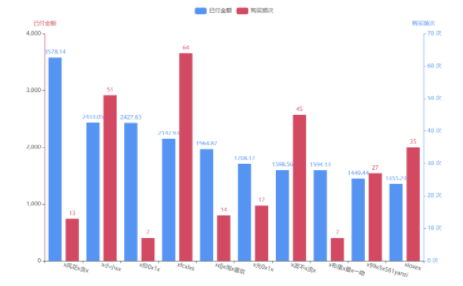
4.對Top10用戶進(jìn)行可視化
import pyecharts.options as opts
from pyecharts.charts import Bar
#設(shè)置顏色
colors = ["#5793f3", "#d14a61"]
#x軸數(shù)據(jù)買家賬號
x_data = df_res.iloc[:10]['買家賬號'].tolist()
#設(shè)置圖例
legend_list = ["已付金額", "購買頻次"]
#y軸已付金額
customer_buy =df_res.iloc[:10]["已付金額"].round(2).tolist()
#y軸購買頻次
customer_count=df_res.iloc[:10]["購買頻次"].tolist()
#初始化
bar = (
Bar(init_opts=opts.InitOpts(width="1000px", height="600px"))
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="已付金額",
yaxis_data=customer_buy,
yaxis_index=0,
color=colors[1],
)
.add_yaxis(
series_name="購買頻次",
yaxis_data=customer_count,
yaxis_index=1,
color=colors[0]
)
.extend_axis(
yaxis=opts.AxisOpts(
name="購買頻次",
type_="value",
position="right",
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(color=colors[0])
),
axislabel_opts=opts.LabelOpts(formatter="{value} 次"),
)
)
.extend_axis(
yaxis=opts.AxisOpts(
name="已付金額",
type_="value",
position="left",
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(color=colors[1])
),
axislabel_opts=opts.LabelOpts(),
)
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
)
)
#加載顯示圖形
bar.render_notebook()
結(jié)論:應(yīng)加強和這些客戶溝通,盡可能提供個性化服務(wù),讓它們發(fā)展為我們超級用戶
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
FM
+關(guān)注
關(guān)注
1文章
181瀏覽量
59115 -
模型
+關(guān)注
關(guān)注
1文章
3171瀏覽量
48711
發(fā)布評論請先 登錄
相關(guān)推薦
基于隱馬爾可夫模型的音頻自動分類
音頻的自動分類,尤其是語音和音樂的分類,是提取音頻結(jié)構(gòu)和內(nèi)容語義的重要手段之一,它在基于內(nèi)容的音頻檢索、視頻的檢索和摘要以及語音文檔檢索等領(lǐng)域都有重大的應(yīng)用價值.由于隱馬爾可夫模型能夠很好地刻畫音頻
發(fā)表于 03-06 23:50
怎么設(shè)計FM天線?
的天線,例如有線耳機,從而限制了許多沒帶有線耳機的用戶。另外,隨著無線使用模型在便攜式設(shè)備中的不斷普及,更多用戶可以從使用其他類型FM天線的無線FM
發(fā)表于 08-13 06:02
Edge Impulse的分類模型淺析
Edge Impulse是一個應(yīng)用于嵌入式領(lǐng)域的在線的機器學(xué)習(xí)網(wǎng)站,不僅為用戶提供了一些現(xiàn)成的神經(jīng)網(wǎng)絡(luò)模型以供訓(xùn)練,還能直接將訓(xùn)練好的模型轉(zhuǎn)換成能在單片機MCU上運行的代碼,使用方便,容易上手。本文
發(fā)表于 12-20 06:51
FM8302 API用戶手冊
此用戶手冊包含了 FM8302 API 的文件列表,簡單描述了 FM8302 DEMO 的使用流程。目的是為了開發(fā)人員能夠快速掌握 FM8302 API 的使用方法。
發(fā)表于 09-14 08:47
系統(tǒng)模型及其分類
系統(tǒng)模型及其分類系統(tǒng):具有特定功能的總體,可以看作信號的變換 器、處理器。系統(tǒng)模型:系統(tǒng)物理特性的數(shù)學(xué)抽象,一般也稱為數(shù)學(xué)模型。 電路的微分方程為:該微
發(fā)表于 09-08 21:00
?10次下載
DNA序列的分類模型
DNA序列的分類模型本文提出了DNA序列分類的三種模型,基一,基于A,G,T,C四種堿基出現(xiàn)的頻率,其二利用了同一堿基在序列中的間隔,這一信息是單純考慮頻率所不能包含的.
發(fā)表于 09-16 11:52
?17次下載
基于非參數(shù)方法的分類模型檢驗
本文主要研究了基于非參數(shù)方法的分類模型交叉驗證結(jié)果比較,主要是對實例通過非參數(shù)的方法進(jìn)行模型比較的假設(shè)檢驗,檢驗兩分類模型是否存在顯著差異。
發(fā)表于 12-08 15:28
?1次下載
Hadoop云平臺用戶動態(tài)訪問控制模型
輪廓。然后利用前向輪廓建立全局K模型,對后續(xù)行為序列進(jìn)行分類并對分類結(jié)果進(jìn)行評估。隨后將評估結(jié)果與改進(jìn)Hadoop訪問控制機制結(jié)合,使云平臺用戶的訪問權(quán)限隨自身行為動
發(fā)表于 01-10 16:37
?0次下載
依據(jù)待分類實例顯著局部特征的懶惰式分類模型
shapelets集合,一般所獲得的shapelets只在平均意義上具有某種鑒別性;與此同時,普通模型往往忽略了待分類實例所具有的局部特征。為此,我們提出了一種依據(jù)待分類實例顯著局部特征的懶惰式
發(fā)表于 03-31 10:50
?6次下載
基于LSTM的表示學(xué)習(xí)-文本分類模型
的關(guān)鍵。為了獲得妤的文本表示,提高文本分類性能,構(gòu)建了基于LSTM的表示學(xué)習(xí)-文本分類模型,其中表示學(xué)習(xí)模型利用語言模型為文本
發(fā)表于 06-15 16:17
?18次下載
OpenCV中支持的非分類與檢測視覺模型
前面給大家分別匯總了OpenCV中支持的圖像分類與對象檢測模型,視覺視覺任務(wù)除了分類與檢測還有很多其他任務(wù),這里我們就來OpenCV中支持的非分類與檢測的視覺






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論