 如何度量知識蒸餾中不同數據增強方法的好壞?
如何度量知識蒸餾中不同數據增強方法的好壞?
1. 研究背景與動機
知識蒸餾(knowledge distillation,KD)是一種通用神經網絡訓練方法,它使用大的teacher模型來 “教” student模型,在各種AI任務上有著廣泛應用。數據增強(data augmentation,DA) 更是神經網絡訓練的標配技巧。
知識蒸餾按照蒸餾的位置通常分為(1)基于網絡中間特征圖的蒸餾,(2)基于網絡輸出的蒸餾。對于后者來說,近幾年分類任務上KD的發展主要集中在新的損失函數,譬如ICLR’20的CRD和ECCV’20的SSKD將對比學習引入損失函數,可以從teacher模型中提取到更豐富的信息,供student模型學習,實現了當時的SOTA。
本文沒有探索損失函數、蒸餾位置等傳統研究問題上, 我們延用了最原始版本的KD loss (也就是Hinton等人在NIPS’14 workshop上提出KD的時候用的Cross-Entropy + KL divergence )。我們重點關注網絡的輸入端:如何度量不同數據增強方法在KD中的好壞?(相比之下,之前的KD paper大多關注網絡的中間特征,或者輸出端)。系統框圖如下所示,本文的核心目標是要提出一種指標去度量圖中 “Stronger DA” 的強弱程度。
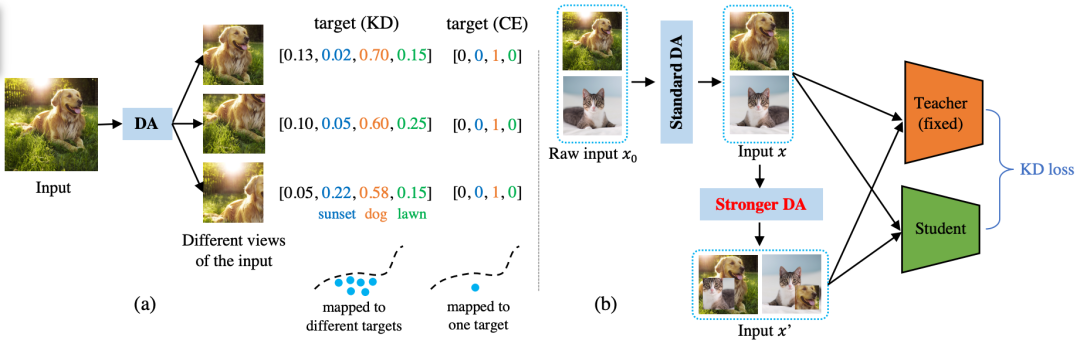
這一切起源于一個偶然的實驗發現:在KD中延長迭代次數,通常可以非常明顯地提升KD的性能。譬如KD實驗中常用的ResNet34/ResNet18 pair, 在ImageNet-1K上,將迭代次數從100 epochs增加到200 epochs,可以將top1/top5準確率從70.66/89.88提升到71.38/90.59, 達到當時的SOTA方法CRD的性能(71.38/90.49)。這顯得很迷,將最baseline的方法訓練久一點就可以SOTA?經過很多實驗分析我們最終發現,是數據增強在背后起作用。
直覺上的解釋是:每次迭代,數據增強是隨機的,得到的樣本都不一樣。那么,迭代次數變多,student見到的不一樣的樣本就越多,這可以從teacher模型中提取到更豐富的信息(跟對比學習loss似乎有著異曲同工之妙),幫助student模型學習。
很自然我們可以進一步推想:不同數據增強方法引入的數據“多樣性”應該是不同的,譬如我們期待基于強化學習搜出來的AutoAugment應該要比簡單的隨機翻轉要更具有多樣性。簡單地說,這篇paper就是在回答:具體怎么度量這種多樣性,以及度量完之后我們怎么在實際中應用。
為什么這個問題重要?(1)理論意義:幫助我們更深地理解KD和DA,(2)實際意義:實驗表明在KD中使用更強的DA總能提高性能,如果我們知道了什么因素在控制這種“強弱”,那么我們就可以締造出更強的DA,從而坐享KD性能的提升。
2. 主要貢獻和內容
文章的主要貢獻是三點:
(1)我們提出了一個定理來嚴格回答什么樣的數據增強是好的,結論是:好的數據增強方法應該降低teacher-student交叉熵的協方差。
定理的核心部分是看不同數據增強方法下訓練樣本之間的相關性,相關性越大意味著樣本越相似,多樣性就越低,student性能應該越差。這個直覺完全符合文中的證明,這是理論上的貢獻。值得一提的是,相關性不是直接算原始樣本之間的相關性,而是算樣本經過了teacher得到的logits之間的相關性,也就是,raw data層面上樣本的相關性不重要,重要的是在teacher看來這些樣本有多么相似,越不相似越好。
(2)基于這個定理,提出了一個具體可用的指標(stddev of teacher’s mean probability, T. stddev),可以對每一種數據增強方法算一個數值出來, 按照這個數值排序,就知道哪種數據增強方法最好。文中測試了7種既有數據增強方法, 發現CutMix最好用。
(3)基于該定理,提出了一種新的基于信息熵篩選的數據增強方法,叫做CutMixPick,它是在CutMix的基礎上挑選出熵最大的樣本(熵大意味著信息量大,多樣性多)進行訓練。實驗表明,即使是使用最普通的KD loss也可以達到SOTA KD方法(例如CRD)的水平。
3. 實驗效果
文中最重要的實驗是,驗證提出的指標(T. Stddev)是否真的能刻畫不同數據增強方法下student性能(S. test loss)的好壞,也就是二者之間的相關性如何。結果表明:相關性顯著!
文章總共測試了9種數據增強方法,我們在CIFAR100,Tiny ImageNet, ImageNet100上均做了驗證,相關性都很強,p-value多數情況下遠小于5%的顯著性界限,如下所示:
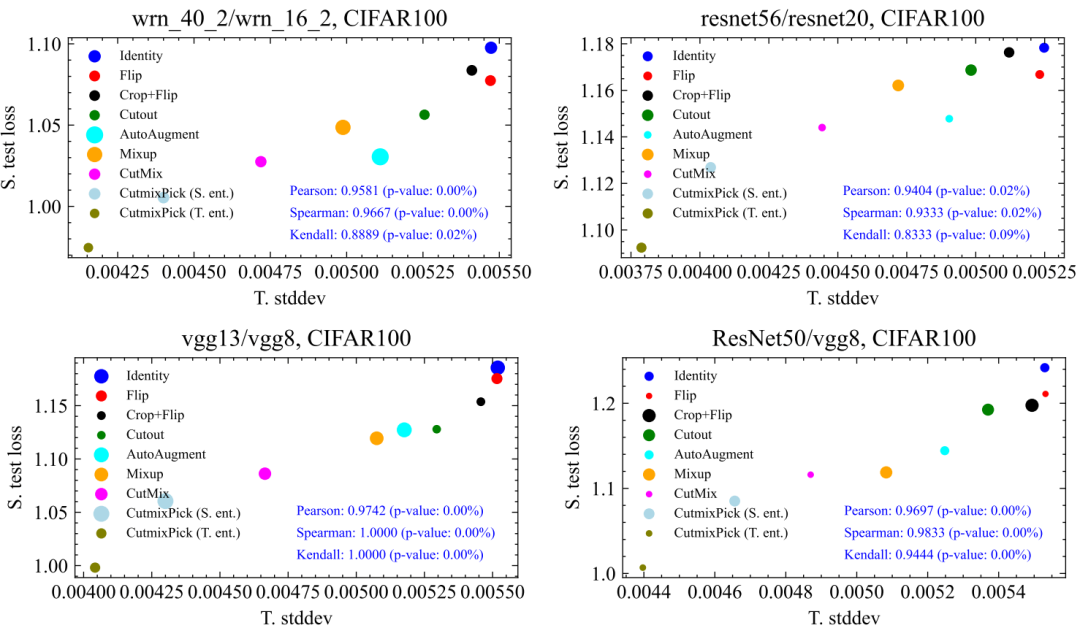
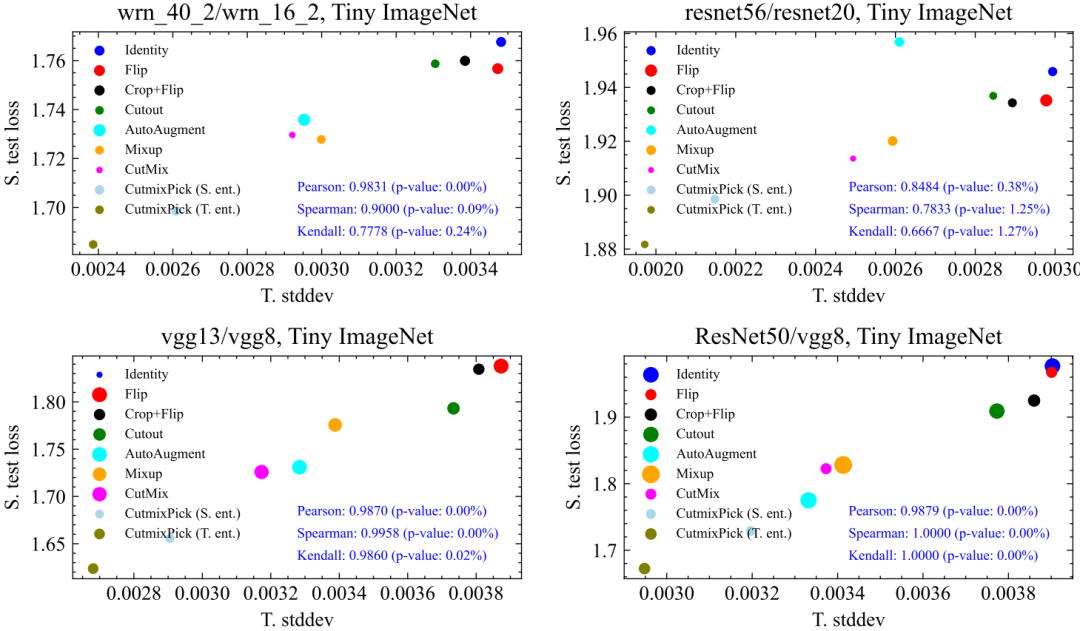
這其中最有意思的一點是,縱軸是student的性能,而橫軸的指標是完全用teacher計算出來的,對于student沒有任何信息,但是somehow,二者呈現出很強的相關性。這說明,KD中對DA好壞的評價很可能獨立于student的。同時,對于不同teacher、數據集,DA之間的相對排序也比較穩定(譬如CutMix穩定地比Cutout要好)。這些都意味著我們在一種網絡、數據集下找到的好的DA有很大概率可以遷移到其他的網絡跟數據集中,大大提升了實際應用價值。
4. 總結和局限性
本文關注數據增強在知識蒸餾中的影響,在理論和實際算法方面均有貢獻,主要有三點:(1) 我們對 “如何度量知識蒸餾中不同數據增強方法的好壞” 這一問題給出了嚴格的理論分析(答:好的數據增強方法應該最小化teacher-student交叉熵的協方差);(2)基于該理論提出了一個實際可計算的度量指標(stddev of teacher’s mean probability);(3)最后提出了一個基于信息熵篩選的新數據增強方法(CutMixPick),可以進一步提升CutMix,在KD中達到新的SOTA性能。
審核編輯:劉清
-
神經網絡
+關注
關注
42文章
4717瀏覽量
100030 -
CRD
+關注
關注
0文章
14瀏覽量
3996
原文標題:NeurIPS 2022 | 如何度量知識蒸餾中不同數據增強方法的好壞?一種統計學視角
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
面向對象軟件度量C&K方法的研究與改進
基于AHP度量模型的安全管理度量方法
基于等級保護的安全管理度量方法研究
構件內聚性度量方法研究
混雜數據的多核幾何平均度量學習
內存取證的內核完整性度量方法
深度學習:知識蒸餾的全過程
基于知識蒸餾的惡意代碼家族檢測方法研究綜述

電池修復技術:做蒸餾水的方法是怎樣的
若干蒸餾方法之間的細節以及差異
關于快速知識蒸餾的視覺框架
用于NAT的選擇性知識蒸餾框架
TPAMI 2023 | 用于視覺識別的相互對比學習在線知識蒸餾

任意模型都能蒸餾!華為諾亞提出異構模型的知識蒸餾方法






 工商網監
工商網監
評論