") MAXQ指令集架構與RISC競爭對手的基準比較
MAXQ指令集架構與RISC競爭對手的基準比較
本文將MAXQ指令集與競爭微控制器進行比較,包括PIC16CXXX(中端器件)、AVR和MSP430。下表詳細介紹了每個指令集和體系結構的優(yōu)缺點。我們將使用選定的代碼算法和操作來判斷代碼密度和代碼性能。最后一節(jié)介紹并重點介紹了每個代碼示例的MIPS(每秒數(shù)百萬條指令)/mA比率。
MAXQ指令集概述
MAXQ指令集建立在傳遞-觸發(fā)概念之上。指令字僅由源操作數(shù)和目標操作數(shù)組成。雖然這些源和目標操作數(shù)可能表示物理寄存器,但編碼也可以表示數(shù)據(jù)存儲器、堆棧存儲器和工作累加器的間接訪問點,和/或可能隱式觸發(fā)硬件操作。特定MAXQ器件的源和目的編碼在與MAXQ器件相關的MAXQ用戶指南中定義。雖然有些源和目的編碼可能是特定于器件的,例如指定用于外設硬件功能的編碼,但某些固定編碼用于構建MAXQ基本指令集。圖1給出了MAXQ指令字和指令集助記符。

| 記憶 | 描述 | 記憶 | 描述 |
| 位操作 | 邏輯 | ||
| MOVE C, #0/#1 | 清除/設置進位 | AND | 邏輯和 |
| CPL C | 補體進位 | OR | 邏輯或 |
| AND Acc. | 邏輯和帶累加器位的進位 | XOR | 邏輯異或 |
| OR Acc. | 邏輯或帶累加器位的進位 | CPL, NEG | One's, Two's Complement |
| XOR Acc. | 帶累加器位的邏輯異或進位 | SLA, SLA2, SLA4 | 算術左移 1,2,4 |
| MOVE C, Acc. | 移動累加器鉆頭進行攜帶 | SRA, SRA2, SRA4 | 算術右移 1,2,4 |
| MOVE Acc.,C | 將進位移至累加器鉆頭 | SR | 邏輯右移 |
| MOVE C, src. | 移動寄存器位進行攜帶 | RR, RRC | 旋轉右進位(防/進)獨占 |
| MOVE dst., #0/#1 | 清除/設置寄存器位 | RL, RLC | 旋轉左攜帶(防/入)獨占 |
| 數(shù)學 | 數(shù)據(jù)傳輸 | ||
| ADD, ADDC | 添加進位(防/入)獨占 | XCHN | 交換累加器數(shù)據(jù)半字節(jié) |
| DJNZ LC[n], src | 減去進位(前/內)排除 | XCH(MAXQ20) | 交換累加器數(shù)據(jù)字節(jié) |
| 流量控制和分支 | MOVE dst, src | 將源移動到目標 | |
| JUMP {C/NC/Z/NZ/E/NE/S} | 跳躍 - 無條件或有條件,相對或絕對 | PUSH/POP | 推/彈出堆棧 |
| DJNZ LC[n], src | 遞減計數(shù)器,跳躍不為零 | POPI | 彈出堆棧并啟用中斷 (INS<0) |
| CALL | 調用 - 相對或絕對 | 其他 | |
| RET {C/NC/Z/NZ/S} | 返回 - 無條件或有條件 | NOP | 無操作 |
| RETI {C/NC/Z/NZ/S} | 從中斷返回 - 無條件或有條件 | CMP | 與蓄能器比較 |
圖1.MAXQ指令字所示的源到目的地傳輸產(chǎn)生一個小但非常強大的指令集。
| 國際海底管理局 | 強度 | 弱點 |
| AVR |
32個通用工作寄存器(累加器) 數(shù)據(jù)指針是直接可尋址工作寄存器的一部分;允許對高/低指針字節(jié)進行輕松屏蔽和位操作。 從指針讀取 + 位移(0 到 63 字節(jié)位移) 堆棧僅受內部 RAM 限制(沒有 RAM 的 90S1200 除外,則堆棧深度 = 3) 單周期操作 相對跳躍 ±2k(雙周期) 所有AVR都有數(shù)據(jù)EEPROM 設置/清除每個狀態(tài)寄存器標志的明確說明;大量位操作指令 分離的間向量 |
流水線指令提取 超過 32 個注冊,負載 (LD)/存儲 (ST) 開銷成為 LD/ST 的一個因素 @X,Y,Z = 兩個周期,LPM = 3 個周期 減少了對文字操作的支持/范圍(沒有ADDC,EORI;只有CPI,ORI,ANDI,SUBI,SBCI,LDI在R16-R31上的工作) 無旋轉指令,不包括攜帶 條件跳躍范圍僅 +63/-64(雙周期) 呼叫/重新/重新輸入 = 四個周期 |
| 圖16CXXX |
源,編碼為 ALU 操作的目標位 直接數(shù)據(jù)訪問(符號尋址模式)可以產(chǎn)生密集的代碼,有利于數(shù)據(jù)疊加 |
四時鐘內核導致執(zhí)行速度差 流水線指令提取 訪問上層數(shù)據(jù)存儲器組需要分頁 (RP1:0銀行選擇) 需要間接數(shù)據(jù)訪問 INDF、FSR 寄存器 無法直接加載W(累加器) 無 ADDC, SUBB 堆棧深度 = 8 沒有相對跳轉/分支 - 只有絕對跳躍(CALL,GOTO)或條件跳躍(BTFSx) 用于代碼存儲器讀取的 RETLW = 浪費的代碼空間,并且不允許代碼空間的 CRC CALL/GOTO/RET/RETFIE/RETW 都需要八個時鐘周期(兩個指令周期) 單中斷向量 |
MAXQ與其他指令集架構的比較
可以嘗試將MAXQ指令助記符與其他架構的指令助記符進行比較,但這種分析既困難又不合理,因為每個指令集都是圍繞特定的器件資源和尋址模式構建的。因此,指令集和器件架構(指令周期、存儲器模型、寄存器集、尋址模式等)是不可分割的,必須一起考慮。表1總結了所比較的指令集架構的優(yōu)缺點。
代碼示例
比較指令集架構的最佳方法是定義一組任務并編寫代碼來執(zhí)行這些任務。以下各節(jié)描述了要執(zhí)行的某些任務,并總結了每個指令集體系結構的代碼密度和性能結果。第一個例程的示例代碼包含在文檔中,而隨后的例程將僅用圖形和文本進行匯總。Maxim可根據(jù)要求提供與每組統(tǒng)計數(shù)據(jù)對應的代碼例程。
| 國際海底管理局 | 強度 | 弱點 |
| MSP430 |
廣泛的源,目標尋址模式在操作碼中編碼 - 可以產(chǎn)生密集代碼 16 位內部路徑 內部存儲器可作為字或字節(jié)訪問 常量發(fā)電機 (CG) 用于 -1, 0, 1, 2, 4, 8 單周期操作 堆棧僅受內部 RAM 限制 條件/相對跳轉目標范圍 = ±512(雙周期) 單獨的中斷向量,自動清除單源標志 |
馮·諾依曼記憶圖+精心設計的尋址模式=多個周期。唯一的單周期指令是那些專門處理Rn的指令。 外設寄存器訪問 = 三到六個周期 CG不支持的文字需要額外的單詞 目標操作數(shù)不能注冊間接或注冊間接自動增量 寄存器間接不支持自動遞減 符號尋址限制了重用代碼例程的能力 |
| MAXQ |
系統(tǒng)和外設寄存器可作為同一邏輯存儲器空間中的源或目標進行訪問,從而實現(xiàn)最快的數(shù)據(jù)傳輸 單循環(huán)運行,無流水線 單周期條件跳轉(+127/-128)或雙周期絕對跳轉(0-65,535) 單周期呼叫/重新/重新輸入 自動遞減環(huán)路計數(shù)器寄存器消除了維護計數(shù)器時通常浪費的開銷 累加器(工作寄存器)文件的自動遞增/遞減/模控制 每個數(shù)據(jù)指針的可選字或字節(jié)訪問模式 可前綴的操作代碼允許簡單的指令集擴展或增強方法 |
主動累加器始終是 ALU 操作的隱式目標 單端口、同步、SRAM 數(shù)據(jù)存儲器要求在使用前激活(選擇)數(shù)據(jù)指針 默認堆棧深度 = 16,但是,數(shù)據(jù)指針硬件非常適合在數(shù)據(jù)存儲器中實現(xiàn)軟堆棧 |
內存副本 (MemCpy64)
存儲器復制示例演示了微控制器間接操作數(shù)據(jù)存儲器塊的能力。任務是將 64 個字節(jié)從數(shù)據(jù)存儲器源位置復制到不重疊的數(shù)據(jù)存儲器目標。以下頁面提供了每個微控制器的代碼例程,以及匯總復制操作的周期計數(shù)和字節(jié)計數(shù)的圖表。這些例程假定在復制操作之前已經(jīng)定義了指針和字節(jié)計數(shù),并且要復制的字節(jié)在存儲器中是字對齊的,因此可以使用MSP430和MAXQ20的字訪問模式。
;======================================AVR====================================== ; ramsize=r16 ;size of block to be copied ; Z-pointer=r30:r31 ;src pointer ; Y-pointer=r28:r29 ;dst pointer ; USES: ; ramtemp=r1 ;temporary storage register loop: ; cycles ld ramtemp,Z+ ; 2 @src => temp st Y+,ramtemp ; 2 temp => @dst dec ramsize ; 1 brne loop ; 2/1 ret ; 4/5 ;--------- ;(7*bytecount) + return - 1(last brne isn't taken). ; WORD COUNT = 5 ; CYCLE COUNT = 451> ;=====================================MAXQ10==================================== ; DP[0] ; src pointer (default WBS0=0) ; DP[1] ; (dst-1) pointer (default WBS1=0) ; LC[0] ; byte count (Loop Counter) loop: ;words & cycles move DP[0], DP[0] ; 1 implicit DP[0] pointer selection move @++DP[1],@DP[0]++ ; 1 djnz LC[0], loop ; 1 ret ; 1 ;---------- ; 4 / (3*bytecount) +1 ; WORD COUNT = 4 ; CYCLE COUNT = 193 ;====================================MAXQ20===================================== ; Assuming bytes are word aligned (like MSP430 code) for comparison ; DP[0] ; src pointer (default WBS0=1) ; DP[1] ; (dst-1) pointer (default WBS1=1) ; LC[0] ; byte count / 2 (Loop Counter) loop: ;words/cycles move DP[0], DP[0] ; 1 implicit DP[0] pointer selection move @++DP[1],@DP[0]++ ; 1 djnz LC[0], loop ; 1 ret ; 1 ;---------- ; 4 / (3*bytecount/2) +1 ; WORD COUNT = 4 ; CYCLE COUNT = 97 ;====================================MSP430===================================== ; MSP430 has a 16-bit data bus ; assuming bytes are word aligned, only requires (blocksize/2 transfers). ; R4 ;src pointer ; R5 ;dst pointer ; R6 ;size of block to copy loop: ;words/cycles mov @R4+, 0(R5) ;2 / 5 @src++ => dst add #2, R5 ;1 / 1 const generator makes this 1/1 decd.b R6 ;1 / 1 really sub #2, R6 jz loop ;1 / 2 ret ;1 / 3 ;---------- ;6 / (9*(bytecount/2)) + return ; WORD COUNT = 6 ; CYCLE COUNT = 291 ;===================================PIC16CXXX=================================== ; a ; src pointer base ; b ; dst pointer base ; i ; byte count held in reg file ; USES: ; temp ; temp data storage loop: ; cycles decf i, W ; 1 i-- => W addlw a ; 1 (a+i--) => W starting at end movwf FSR ; 1 W => FSR movfw INDF ; 1 W <= @FSR get data movwf temp ; 1 W => temp movlw (b-a) ; 1 diff in dest-src addwf FSR, F ; 1 (b+i--) => W movfw temp ; 1 temp => W movwf INDF ; 1 W => @FSR store data decfsz i, F ; 2/1 i-- goto loop ; 2 return ; 2 ;---------- ;11 / (12*bytecount) +1 (ret instead of goto, +1 on decfsz) ; WORD COUNT = 12 ; CYCLE COUNT = 769 (*4clks/inst cycle = 3076)
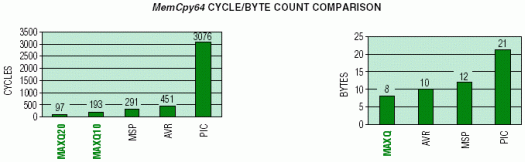
MAXQ器件提供最佳的代碼密度,在執(zhí)行速度方面是明顯的贏家。MAXQ10執(zhí)行復制操作的速度比MAXQ20慢,因為它對數(shù)據(jù)指針使用默認的字節(jié)訪問模式。對于MAXQ10應用,如果認為執(zhí)行速度比代碼密度更重要,并且要復制的數(shù)據(jù)存儲器是字對齊的(MSP430和MAXQ20示例已經(jīng)假設),則可以對源和目標數(shù)據(jù)指針使用字訪問模式。啟用字模式允許將MAXQ10復制環(huán)路切成兩半,但需要額外的指令來啟用/禁用字訪問模式。MAXQ器件相對于競爭產(chǎn)品所表現(xiàn)出的壓倒性性能優(yōu)勢可歸因于以下架構優(yōu)勢:
| 1. | 無流水線 - 分支不會像其他設備那樣產(chǎn)生刷新指令預取的開銷。 |
| 2. | 自動遞減循環(huán)計數(shù)器 - 減輕了手動執(zhí)行此操作的需要。 |
| 3. | 哈佛內存映射 - 程序和數(shù)據(jù)不共享相同的物理空間,允許同時獲取程序和數(shù)據(jù)訪問。 |
| 4. | 預遞增/遞減間接目標指針 - 簡化并加快目標指針的前進速度。這是 MSP430 的一個弱點,它使用 0(R5) 表示@R5,然后必須使用另一條指令推進該目標指針。 |
存儲器復制示例中所示的MAXQ優(yōu)勢轉化為類似的增益,適用于需要在數(shù)據(jù)存儲器中進行頻繁輸入/輸出緩沖的應用。在性能方面,最接近的競爭對手是 MSP430。例如,可能需要數(shù)據(jù)存儲器緩沖,假設我們有一個MSP430器件,該器件配備了具有16位輸出寄存器的ADC外設。將數(shù)據(jù)從外設輸出寄存器傳輸?shù)綌?shù)據(jù)存儲器并遞增指針以準備下一個ADC輸出樣本,可以使用如下代碼進行處理:
; words/cycles
mov.w &ADAT,0(R14) ; 3 / 6 Store output word
incd.w R14 ; 1 / 1 Increment pointer
; 4 / 7
在MAXQ20上,相同的傳遞操作如下所示:
move @++DP[0], ADCOUT ; 1 / 1
氣泡排序(氣泡排序))
冒泡排序例程不僅展示了有效訪問數(shù)據(jù)存儲器的能力,而且還在數(shù)據(jù)字節(jié)之間執(zhí)行算術和/或比較運算,并有條件地對字節(jié)進行重新排序。代碼例程對 32 個數(shù)據(jù)存儲器字節(jié)進行排序,以便它們按升序或降序排列。周期計數(shù)假定字節(jié)重新排序大約有一半時間是相鄰字節(jié)比較的結果。下圖總結了每個微控制器上排序操作的周期計數(shù)和字節(jié)計數(shù)。
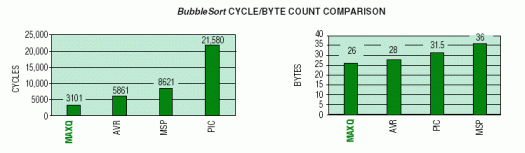
MAXQ器件再次產(chǎn)生最佳的碼密度,是以下領域的明顯贏家。 執(zhí)行速度。MAXQ的優(yōu)勢可以歸因于存儲器復制示例中討論的相同架構優(yōu)勢。
十六進制到 ASCII 轉換 (十六進制2Asc)
此轉換例程測試微控制器的算術和邏輯運算范圍。它還在轉換和擴展單個字節(jié)中包含的數(shù)據(jù)時測試它們對文本字節(jié)數(shù)據(jù)的支持。周期計數(shù)表示一個平均值,假設每個半字節(jié)可以是 16 個十六進制值之一 - 0 到 9,Ato F。下圖總結了每個微控制器上轉換操作的周期計數(shù)和字節(jié)計數(shù)。
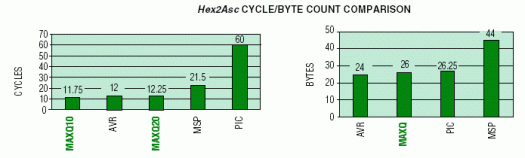
對于這個測試例程,AVR需要的字更少,因為它的工作寄存器可以直接訪問,而MAXQ最有效的方法需要手動更新累加器指針。MSP 代碼密度受到影響,因為它缺少操作半字節(jié)的操作,并且常量生成器不支持的文本 (#nnnnh) 必須用單獨的單詞進行編碼。MAXQ器件和Atmel AVR在性能方面取得了類似的結果,而其他器件則落后。MSP430 的性能受到執(zhí)行操作的額外碼字的影響。
算術右移 2 個位置(向右)
此例程演示了微控制器支持 16 位字數(shù)據(jù)存儲器訪問和 ALU 操作的能力。所需的操作是以算術方式移位(即保留最高有效位)駐留在數(shù)據(jù)存儲器中的 16 位字。假設字駐留在數(shù)據(jù)存儲器的前 256 個字節(jié)中,并在存儲器中對齊,以便由具有該功能的微控制器進行字尋址。下圖總結了每個微控制器上移位操作的周期計數(shù)和字節(jié)計數(shù)。
支持16位ALU操作的微控制器MAXQ20和MSP430提供 代碼密度明顯提高。除PIC外,所有8位計算機都需要至少兩倍的代碼字數(shù)才能完成相同的算術移位。MAXQ20提供最佳性能,MAXQ10雖然僅支持8位ALU操作,但性能接近16位MSP430。
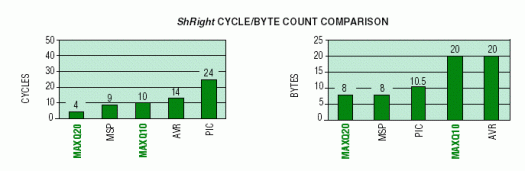
MAXQ20和MSP430表現(xiàn)出更高的ODE密度,因為它們能夠比16位機器更有效地處理8位數(shù)據(jù)。但是,每種方法都以略有不同的方式這樣做。MAXQ20將要移位的16位字傳輸?shù)焦ぷ骷拇嫫鳎ɡ奂悠鳎谀抢锟梢允褂枚辔凰阈g移位。MSP430 使用寄存器間接尋址模式 (RRA @R5) 執(zhí)行單位算術移位運算,并且不會從其存儲器位置顯式傳輸字。在提供更高性能的同時,當20位字的算術移位可以使用多位算術移位操作碼(SRA430、SRA16、SLA2、SLA4)時,MAXQ2可以提供與MSP4相同或更好的碼密度。
位爆炸端口引腳(位爆炸)
此示例測試指令集體系結構通過直接位操作或通過移位/旋轉分解字節(jié)并將各個位發(fā)送到端口引腳(“位敲擊”)的能力。端口引腳輸出分別表示時鐘和數(shù)據(jù),要求數(shù)據(jù)在時鐘的上升沿必須有效。由于代碼直接操作端口引腳,因此此測試還演示了訪問I/O端口寄存器的難易程度。下圖總結了每個微控制器上端口位爆炸操作的周期計數(shù)和字節(jié)計數(shù)。
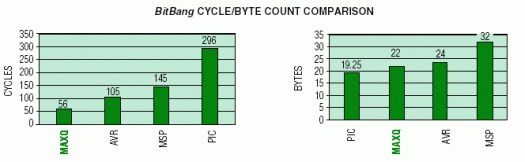
MAXQ器件顯然是性能最好的器件。由于底層 4 周期內核架構,PIC 性能在這里受到限制(與其他示例一樣)。MSP430的性能較差,可歸因于其馮諾依曼存儲器架構和需要使用絕對尋址來訪問端口輸出寄存器。
在碼密度方面,MAXQ和PIC具有相同的字數(shù)。然而,PIC在RISC機器中優(yōu)于MAXQ,因為它的14位程序字與MAXQ的16位程序字相比。MSP430代碼密度受到影響,因為它必須使用至少兩個字來訪問具有絕對尋址模式(即和寄存器)的外設寄存器,或者當使用常量生成器無法減少的文字(例如,#3h)時。
MSP430訪問其外設寄存器的方法值得進一步評論。微控制器的主要職責是以某種方式與外界接口。因此,它必須控制、監(jiān)視和處理 I/O 引腳上發(fā)生的活動。如果微控制器嵌入很少的外設硬件模塊,則此活動的負擔留給軟件。要使軟件執(zhí)行任何有意義的操作,它必須讀取和寫入端口引腳。在 MSP430 上,這些端口引腳寄存器駐留在需要使用絕對訪問模式的外設寄存器空間中。現(xiàn)在考慮一個具有豐富“智能”外設的微控制器。毫無疑問,在使用片上專用硬件執(zhí)行必要功能的過程中,必須配置、控制和訪問更多的外設寄存器。在 MSP430 上,這些寄存器位于需要使用絕對訪問模式的外設寄存器空間中。因此,與 MSP430 絕對尋址模式相關的代碼密度和性能損失是無法逃避的。
“MIPS/mA”指標
功耗通常是選擇處理器或內核架構的重要因素。給定系統(tǒng)的總體功耗取決于許多因素,例如電源電壓和工作頻率,以及盡可能使用低功耗模式的能力。降低電源電壓和/或工作頻率,以及頻繁使用低功耗模式,可以大大降低系統(tǒng)總功耗。雖然給定微控制器的最小電源電壓在很大程度上取決于器件制造工藝技術,但降低工作頻率和使用低功耗模式的能力在很大程度上取決于系統(tǒng)設計人員可以確定的應用要求。MIPS/mA指標提供了一種簡單的方法來評估微控制器的代碼效率,同時考慮有功電流消耗。應選擇通用電源電壓,以便在不同器件之間創(chuàng)建有意義的MIPS/mA比較。對于即將到來的比較,假設為3V電源電壓。為了考慮所比較的指令集架構(即AVR、MSP430、PIC16、MAXQ)的差異和效率,還需要為生成的每個代碼示例生成單獨的MIPS/mA比率。
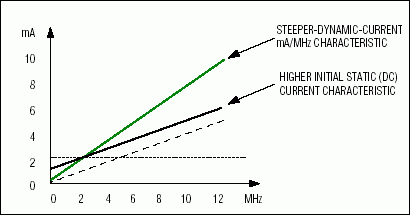
圖2.這個IccActive與MHz的例子說明了靜態(tài)和動態(tài)電流增加的影響。
為了確定MIPS/mA比率的“mA”部分,我們檢查了器件的數(shù)據(jù)手冊。大多數(shù)微控制器供應商都規(guī)定了與器件最大工作頻率相關的典型和最大有功電流。假設靜態(tài)(DC)電流非常小,這些數(shù)據(jù)點允許得出典型和最大mA/MHz近似值,用于在任何時鐘頻率下外推有功電流。如果供應商提供有功電流與溫度/頻率特性數(shù)據(jù),則可以相對于特定系統(tǒng)環(huán)境條件更好地量化和定義mA/MHz比。否則,我們必須簡單地依靠離散數(shù)據(jù)點和我們對非常小的靜態(tài)電流的假設。靜態(tài)(DC)電流的增加會改變mA與MHz特性曲線的起點,從而限制系統(tǒng)設計人員在降低時鐘頻率(降低動態(tài)電流)時看到的總增益。圖2給出了一個IccActive vs. MHz圖示例。表2比較了各種內核的mA/MHz數(shù)字,并引用了信息來源。當以后的計算中需要此術語時,將使用每個架構的突出顯示的 mA/MHz 數(shù)。
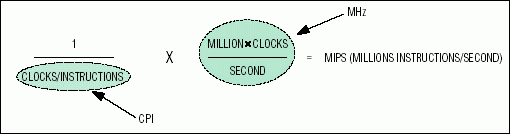
圖3.MAXQ架構通過每條指令在一個時鐘上執(zhí)行幾乎所有指令來實現(xiàn)高MIPS性能比。
MIPS/mA 指標的“MIPS”部分用于量化性能差異。我們將首先給出圖3中MIPS的簡單公式。
在評估給定架構的MIPS時,每條指令的時鐘數(shù)(CPI)非常重要。例如,Microchip PIC等架構要求每個指令周期有多個時鐘。此外,架構通常需要多個指令周期來執(zhí)行某些指令,或者在執(zhí)行跳轉/分支時需要周期來刷新指令管道。在比較架構時,MIPS的平均性能通常遠低于峰值性能(MIPS),并且因指令組合而異。
| 裝置 | 典型毫安/兆赫 | 最大毫安/兆赫 | 源 |
| PIC16C55X | 0.7 | 1.25 | PIC16C55X 數(shù)據(jù)表:DC 表 10.1, D010 (Vcc= 3V, 2兆赫);XT 或 RC |
| PIC16C62X | 0.7 | 1.25 | PIC16C62X 數(shù)據(jù)表:DC 表 12.1, D010 (Vcc= 3V, 2兆赫);XT 或 RC |
| 圖16LC71 | 0.35 | 0.625 | PIC16C71X 數(shù)據(jù)表:DC 表 15.2, D010 (Vcc= 3V, 4兆赫);XT 或 RC |
| PIC16F62X | 0.15 | 0.175 | PIC16F62X 數(shù)據(jù)表:DC 表 17.1, D010 (Vcc= 3V, 4MHz) |
| PIC16LF870/1 | 0.15 | 0.5 | PIC16F870/1 數(shù)據(jù)表:DC 表 14.1, D010 (Vcc= 3V, 4兆赫);XT 或 RC |
| AT90S1200 | 0.33 | 0.75 | AT90S1200 數(shù)據(jù)手冊:EC 表 (3V, 4MHz), 圖 38, 4mA/12MHz (典型值) |
| AT90S2313 | 0.50 | 0.75 | AT90S2313 數(shù)據(jù)手冊:EC 表 (3V, 4MHz), 圖 57, 7.5mA/15MHz (典型值) |
| MSP430F1101 | 0.30 | 0.35 | MSP430x11x1 數(shù)據(jù)表:直流規(guī)格 IccActive (Vcc= 3V, FMCLK = 1MHz) |
| MPS430C11X1 | 0.24 | 0.30 | MSP430x11x1 數(shù)據(jù)表:直流規(guī)格 IccActive (Vcc= 3V, FMCLK = 1MHz) |
| MSP430Fx12x | 0.30 | 0.35 | MSP430x12x 數(shù)據(jù)表:直流規(guī)格 (V抄送= 3V, FMCLK = 1MHz, FACLK = 32kHz) |
| MAXQ10 | 0.30 | 模擬 | |
| MAXQ20 | 0.30 | 模擬 |
為了生成一個更有用的指標并生成一個值來幫助我們達到 MIPS/mA 目標指標,我們將 MIPS 除以 MHz。MIPS/MHz比率可以解釋為在單個時鐘中執(zhí)行的平均指令數(shù)(對于給定的代碼示例)。使用MIPS/MHz數(shù)和之前計算的mA/MHz數(shù),可以生成MIPS/mA比率。下表分別顯示了每個早期代碼例程比較的MIPS/MHz和MIPS/mA數(shù)字。
| 核心 | MIPS/MHz | |||||
| MemCpy64 | BubbleSort | Hex2Asc | ShRight | BitBang | Peak | |
| MAXQ10 | 1.00 | 0.99 | 1.00 | 1.00 | 1.00 | 1 |
| MAXQ20 | 1.00 | 0.99 | 1.00 | 1.00 | 1.00 | 1 |
| PIC | 0.23 | 0.20 | 0.23 | 0.25 | 0.21 | 0.25 |
| MSP | 0.44 | 0.39 | 0.64 | 0.33 | 0.61 | 1 |
| AVR | 0.57 | 0.62 | 0.90 | 0.71 | 0.61 | 1 |
| 核心 | 微弱/毫安 | |||||
| MemCpy64 | BubbleSort | Hex2Asc | ShRight | BitBang | ||
| MAXQ10 | 3.33 | 3.30 | 3.33 | 3.33 | 3.33 | |
| MAXQ20 | 3.33 | 3.30 | 3.33 | 3.33 | 3.33 | |
| PIC | 1.53 | 1.35 | 1.53 | 1.67 | 1.40 | |
| MSP | 1.85 | 1.62 | 2.66 | 1.39 | 1.55 | |
| AVR | 1.71 | 1.86 | 2.69 | 2.14 | 1.83 | |
為了進一步分析,我們必須通過將MIPS/mA比率除以給定代碼樣本實際執(zhí)行的指令數(shù)來考慮核心架構和指令集效率之間的差異。這種額外計算的基本原理是,執(zhí)行三個單周期指令(最高MIPS/MHz比率= 1)實際上并不比一個3周期指令(MIPS/MHz比率= 0.33)好。盡管如此,由此產(chǎn)生的MIPS/mA比率卻大不相同。事實上,如果完成相同的任務,大多數(shù)人更喜歡一條指令而不是三條指令。通過將MIPS/mA比率除以執(zhí)行的指令數(shù),我們正在根據(jù)給定微控制器用于執(zhí)行特定任務的指令組合調整MIPS/mA比率。結果值已規(guī)范化為最高性能值,如下表所示。
| 核心 | 標準化 (MIPS/mA) | ||||
| MemCpy64 | BubbleSort | Hex2Asc | ShRight | BitBang | |
| MAXQ10 | 0.50 | 1.00 | 1.00 | 0.40 | 1.00 |
| MAXQ20 | 1.00 | 1.00 | 0.96 | 1.00 | 1.00 |
| PIC | 0.06 | 0.29 | 0.39 | 0.33 | 0.38 |
| MSP | 0.42 | 0.45 | 0.68 | 0.56 | 0.48 |
| AVR | 0.19 | 0.48 | 0.88 | 0.26 | 0.48 |
結論
歸一化的“MIPS/mA”指標為我們提供了 比較具有不同架構、指令集和電流消耗特性的微控制器。較高的歸一化“MIPS/mA”比通常可以產(chǎn)生以下一個或兩個好處:(1)可以降低系統(tǒng)時鐘頻率,以及(2)可以增加在低功耗或睡眠模式下花費的時間。這兩種可能性都有助于降低系統(tǒng)的整體功耗。或者,可以在保持給定電流/功率預算的同時實現(xiàn)更高的整體系統(tǒng)性能。無論優(yōu)點如何,MAXQ架構產(chǎn)生的高MIPS/mA比都是效率的可靠指標。
審核編輯:郭婷
-
微控制器
+關注
關注
48文章
7487瀏覽量
151044 -
寄存器
+關注
關注
31文章
5317瀏覽量
120003 -
存儲器
+關注
關注
38文章
7452瀏覽量
163598
發(fā)布評論請先 登錄
相關推薦
淺談RISC-V指令集架構的來龍去脈
CISC(復雜指令集)與RISC(精簡指令集)的區(qū)別
RISC-V指令集的特點總結
RISC-V和arm指令集的對比分析
AMD擴展x86并行指令集
RISC-V指令集架構微控制器相關知識
risc指令集是什么_有哪些
指令集架構與開源架構
RISC-V | 關于第五代精簡指令集計算機,你了解多少?
簡單講講RISC-V指令集CPU的參數(shù)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論