") cache背后的軟思考
cache背后的軟思考
1.前言
Cache在體系架構(gòu)中占據(jù)半邊山,讀者又多為軟件從業(yè)者、學(xué)者,個人在碰到項目瓶頸時,研讀一些ARM手冊,以及業(yè)內(nèi)技術(shù)論文,發(fā)現(xiàn)cache在架構(gòu)中發(fā)揮著被軟件工程師低估的能力,本文從其設(shè)計角度和軟件角度闡述一二;
2.Cache的設(shè)計思考
Cache的基礎(chǔ)資料很多,多是圍繞如下展開說明:cache line,組/全相連,VIVT/VIPT/PIPT等概念,一般初學(xué)者閱讀后也會云里霧里,cache技術(shù)也很少被直接關(guān)注到;
所以在linux初級開發(fā)者接觸cache時,腦海里會不自覺的思考:硬件行為,都是被ICer設(shè)計好的;所以他們也并沒有深究cache的層次結(jié)構(gòu),也沒有繼續(xù)挖掘cache和驅(qū)動軟件的千絲萬縷的關(guān)系,腦海里想象的拓?fù)鋱D,大致是這樣:
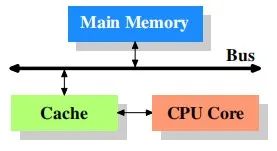
認(rèn)為cache的設(shè)計就是cpu和memory之間單一的存在,從而忽略了那些ICer對cache的研究和優(yōu)化,直接影響就是軟件層面的優(yōu)化,以及軟件層面的疑難bug;這也是初學(xué)者進(jìn)階時的第一道阻礙;
那么在原廠工程師的腦海里,cache最基礎(chǔ)的樣子是這樣的:
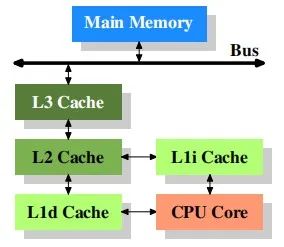
它是現(xiàn)在處理器基本的形態(tài),也是最簡單的形態(tài),在ICer們的設(shè)計上,其內(nèi)在協(xié)議直接影響著指令的流轉(zhuǎn):load,store等;其內(nèi)在存在的load buffer和store buffer影響著你的數(shù)據(jù)一致性,你的讀寫指令運(yùn)行速度,數(shù)據(jù)的共享屬性等等,極其簡單的實例:
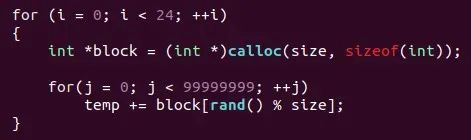
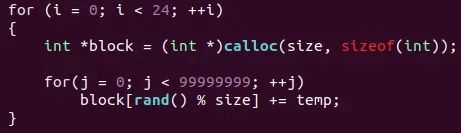
一個load執(zhí)行,一個store執(zhí)行,哪個快?顯然prefetch最快,再深一層次思考:如果工程中,在多cpu和多thread都有數(shù)據(jù)訪問需求,但是CPU和memory直接又有cache這一層大buffer,硬件和軟件都做了什么,能夠保證實時或訪存速度?
硬件上,制定cache的各種參數(shù)時,在保證滿足設(shè)計需求時,ICer們也會做這種動作:即對cache的benchmark;比如cache size和直接映射、組相連帶來的收益:
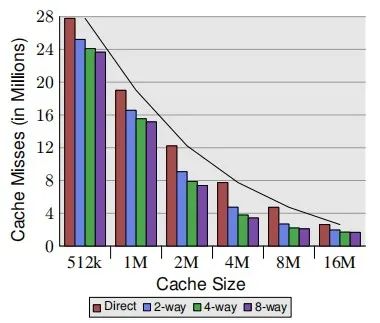
L2 cache的benchmark:
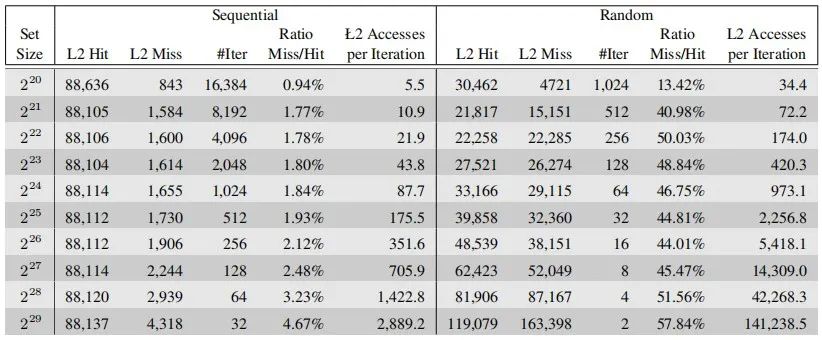
各種參數(shù)的測試結(jié)果呈現(xiàn)就是市面上大家可以查到的某種處理器L1 cache,L2 cache,L3 cache,以及system cache的大小,所以在大家認(rèn)為很小size的cache,ICer以及架構(gòu)師們,甚至是學(xué)者,都在為其能夠發(fā)揮出更佳性能,更低功耗的能力,夜以繼日的做研究,做實驗;
進(jìn)一步思考:現(xiàn)在處理器設(shè)計越來越復(fù)雜,越來越強(qiáng),比如NUMA,大小核等等,其呈現(xiàn)效果又如下簡單示例:
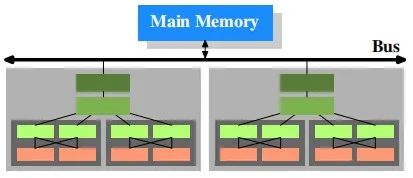
硬件層面帶來了考驗和升級,直接的影響給軟件層面也帶了考驗,比如:你的數(shù)據(jù)一致性問題,IP驅(qū)動設(shè)計等等,ARM的內(nèi)存模型又是弱一致性的,那么你設(shè)計的驅(qū)動,可能被動存在著潛在bug,所以進(jìn)一步帶來的是我們在工程問題上的思考。
1.Cache的工程思考
本人工作于ARM體系架構(gòu)之上,所以日常在查閱arm官方公開的文檔時,知道的愈多,疑問也愈多,思考的也愈多,但是借助linux這個開源社區(qū),眾多疑惑也慢慢得到解答,特此在工作之余將一小部分所得分享于大家,比如:cache的多個讀寫策略在影響著指令行為,直接導(dǎo)致數(shù)據(jù)的行為不一,如何在工程中認(rèn)識它們?解決它們?
Cache的策略有如下:write-allocate,no write-allocate,read-allocate,read-through;
上述策略在驅(qū)動設(shè)計時,也是幾乎被忽略的存在,其發(fā)揮的作用就是data是否被緩存在cache中,還是 pass到內(nèi)存中,若兩者皆存在,那么你的DMA在搬運(yùn)數(shù)據(jù)前,有個動作就是sync,即刷新cache,保持?jǐn)?shù)據(jù)在cache與內(nèi)存中的一致性;
當(dāng)然在內(nèi)核驅(qū)動設(shè)計時,并不會指定使用哪個cache策略,因為kernel已經(jīng)在某些接口中,潛在的做了相關(guān)操作,譬如大家用的ioremap_xxx這類接口就是和cache聯(lián)系緊密;
可以思考:如果我不需要使用ioremap_xxx這類接口,還需要關(guān)注什么cache策略嗎?
思考后的結(jié)果:dirty數(shù)據(jù)帶來的不同步就是你解決不了問題的噩夢;
Dirty數(shù)據(jù)怎么處理?借助linux的驅(qū)動設(shè)計,可以給各位呈現(xiàn)出如下一個接口:
POC(Pointof Coherency):全局緩存一致性,即系統(tǒng)中所有可以發(fā)起內(nèi)存訪問的硬件單元的視角:CPU,DMA等;
所以雖然cache分為:L1 cache,L2 cache,L3cache,以及system cache,但是需要軟件設(shè)計者必須知道的是:你想干什么?是刷新部分master所感測到的數(shù)據(jù),還是所有master都要關(guān)注到的數(shù)據(jù)變化,這就是cache帶來的可操作性;
即在不同cache層級的設(shè)計中,data的可觀測性是不一樣的,這也是為什么在我的腦海里,cache一直是多層級,多策略的,所以在驅(qū)動設(shè)計時,保證IP的視角看到的數(shù)據(jù)就是我設(shè)計的結(jié)果;
思考:如果只是CPU之間的data是可觀測的,有沒有什么指令作用域比POC更小的?
思考后的結(jié)果:POC視角太寬泛了,比POC作用域小的,即 POU:Pointof Unification;即處理器看到的視角,比如虛擬內(nèi)存和物理內(nèi)存映射的頁表數(shù)據(jù):TLB,MMU;
進(jìn)一步思考:POC和POU又太大了,有沒有只操作我dword數(shù)據(jù)的?
因為ARM的內(nèi)存模型是弱一致性的,所以其在指令排序上有所行為,直接影響就是控制數(shù)據(jù)的亂序,內(nèi)存屏障指令運(yùn)勢而生:dmb,dsb,isb;(PS:宋寶華老師的分享文章有詳解);
該內(nèi)存屏障指令宋老師有過介紹,不再贅述,需要關(guān)注的是:在使用上述指令時,也有作用域的區(qū)別;
Cache帶給處理器的是極致性能,帶給開發(fā)者是一個又一個的隱藏問題,所以剖析cache很有必要;
2.總結(jié)
本文因為篇幅問題,分享的是cache的冰山一角。cache又是體系架構(gòu)中的一角,體系架構(gòu)又是內(nèi)核技術(shù)的一角,我又是眾多讀者的一角。
文獻(xiàn)參考:論文《WhatEvery Programmer Should Know About Memory》。
審核編輯 :李倩
-
ARM
+關(guān)注
關(guān)注
134文章
9046瀏覽量
366816 -
cpu
+關(guān)注
關(guān)注
68文章
10825瀏覽量
211148 -
Cache
+關(guān)注
關(guān)注
0文章
129瀏覽量
28298
原文標(biāo)題:cache背后的軟思考
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
(分享設(shè)計)顯示器上的思考者
為什么需要cache?cache是如何影響code的呢
Cache中Tag電路的設(shè)計
什么是Cache/SIMD?
什么是Instructions Cache/IMM/ID
高速緩存(Cache),高速緩存(Cache)原理是什么?
cache基本知識培訓(xùn)教程[2]
什么是 Cache? Cache讀寫原理
CPU Cache偽共享問題
深入理解Cache工作原理
Cache的原理和地址映射
Cache分類與替換算法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論