 什么是針對GPU單指令多數據流的編譯優化算法
什么是針對GPU單指令多數據流的編譯優化算法
1.單指令多數據流
首先來看一段簡單的if-else語句:
if(A)
{
B = 1;//Instruction S1
C = 2;//Instruction S2
}
else
{
B = 3;//Instruction S3
C = 4;//Instruction S4
}
假設代碼中每條語句轉換成指令后分別是S1、S2、S3、S4.
如果在CPU的單指令單數據流中,A=true時會取指令S1和S2執行,A=false時會取指令S3和S4執行,不存在A=true和A=false同時存在的這種情況。
但是在GPU的單指令多數據流(SIMD)中卻存在A=true和A=false同時存在的情況。
如下圖所示是GPU單指令多數據流的執行情況:
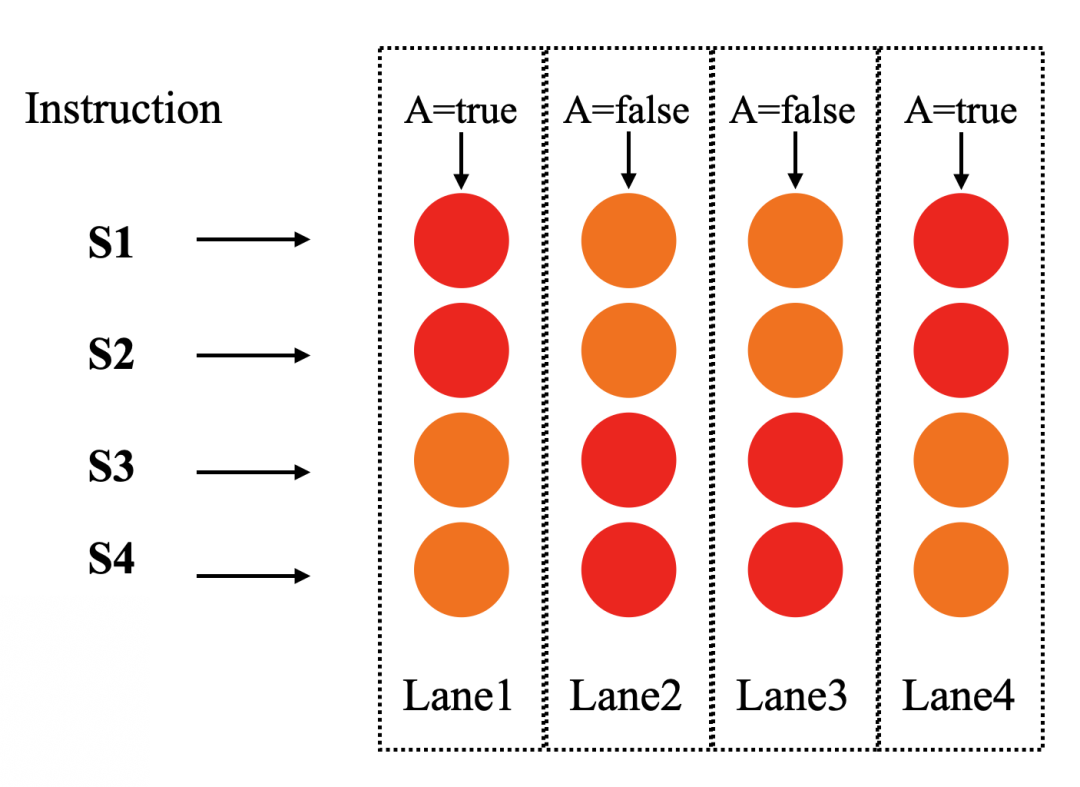
GPU單指令多數據流
從圖中可以看到,GPU共有4個通道lane1、lane2、lane3、lane4,分別對應4筆不同的數據。這四個通道共享同一組指令S1、S2、S3、S4(如圖中左邊所示)。但是在4個不同的lane中,A的值在不同的lane中有時是true,有時是false。紅色表示執行該指令,橙色表示不執行該指令。
如果按照CPU單指令單數據流的方式去編譯,生成的匯編指令是大概這樣的:
goto !A , Labe1;//如果A為false,跳轉
mov B , 1;//指令S1
mov C , 2;//指令S2
Lable1:
mov B , 3;//指令S3
mov C , 4;//指令S4
可以看到goto指令會根據A的值進行跳轉,GPU中A的值在不同的lane中取值不同,不同的lane根據自己的A值進行跳轉是行不通的。因為所有的lane共享同一組指令,不可能有的lane在執行S1、S2語句,有的lane在執行S3、S4語句。
所以GPU的指令應該轉換成順序執行,類似于下面這種。
(p0) mov B , 1;//指令S1
(p0) mov C , 2;//指令S2
(p1) mov B , 3;//指令S3
(p1) mov C , 4;//指令S4
此時不同的lane都會按照順序取值S1,S2,S3,S4,但是具體的lane中會根據前面的p寄存器的取值確定是否執行該指令。例如對于同一條指令S1,根據A的輸入,有的lane是執行的(紅色),有的lane是不執行的(橙色)。
一句話總結就是:GPU是單指令多數據流(SIMD)架構,當多筆數據過來時,不一定同時跳轉,本文介紹的if-conversion算法能夠消除所有的跳轉指令,可以將控制依賴轉換為數據依賴。
2.if-conversion算法
總共分四步:
- 計算直接后繼支配節點
- 計算控制依賴CD
- 計算R&K函數
- Augment K
首先要計算直接后繼支配節點,因為在控制依賴CD的計算中需要用到。
什么是控制依賴CD,一個簡單的例子就是if語句中的block y是受if語句所在的block x所控制的。此時CD(y) = x, 稱為y控制依賴于x。
R&K分別對應寄存器p的use與def,即寄存器p的使用與定義。
R(x):表示分配給block x的謂詞寄存器。block x的執行與否受R(x)中的寄存器控制。也可以說是p的use,即寄存器p用于block x。
K(p):表示謂詞寄存器p需要在K(p)中的block中定義。也就是寄存器的def,即寄存器p在那個block定義。
2.1 直接后繼支配節點
首先要弄清楚兩個概念:后繼支配節點、直接后繼支配節點。
后繼支配節點:如果從節點y到出口節點的每一條路徑都經過節點x,則x為y的后繼支配節點。
記作:x pdom y
直接后繼支配節點:x pdom y,不存在節點z,使得x pdom z 且 z pdom y。則x為y的直接后繼支配節點。
記作:x ipdom y
計算后繼支配節點的迭代算法:
change = true;
//init pdom set
pdom(exit_block) = {exit_block}
pdom(0:eeit_block-1) = {all blocks}
//iterate flow graph
while(change)
{
change = false;
for( each block n) with post order
{
tmp = {all blocks};
//求節點n所有直接后繼節點的共同后繼支配節點
for(each n's successor block p)
{
tmp = tmp & pdom(p);//求交集
}
//n的后繼支配節點包括他本身
tmp = tmp | {n};
if(tmp!=pdom(n))
{
pdom(n) = tmp;
change = true;
}
}
}
求后繼支配節點的算法一句話概括:節點n的后繼支配節點包括他本身,以及他所有直接后繼節點的共同后繼支配節點。
計算直接后繼支配節點的算法:
//remove itself from it's pdom set
for each node n
{
pdom(n)-={n};
}
for each node n with post order
{
for each s in pdom(n){
//移除直接后繼支配節點的后繼支配節點
for each t in set( pdom(n)-s ){
if( t is in pdom(s) )
pdom(n)-={t}
}
}
}
后繼支配節點 = 直接后繼支配節點 + (直接后繼支配節點)的后繼支配節點
前面已經求出了后繼支配節點,因此在后繼支配節點中移除(直接后繼支配節點)的后繼支配節點,即可得到直接后繼支配節點。
下圖是一個計算直接后繼支配節點的例子:
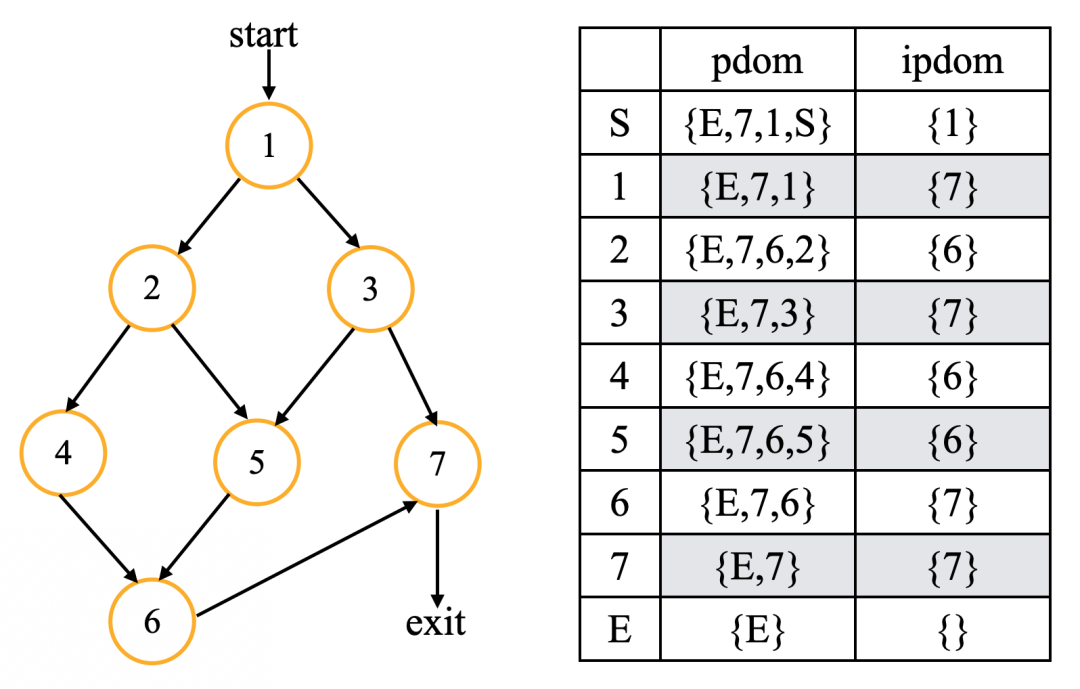
直接后繼支配節點
2.2. CD
CD是Control Dependent的縮寫。直接上英文定義可能更準確一些,詳細證明可參考文章末尾給出的論文,公眾號后臺回復SIMD關鍵字即可下載。
Y is control dependent on X iff
(1) there exists a directed path P from X to Y with any Z in P (excluding X and Y) post-dominated by Y
(2) X is not post-dominated by Y.
計算CD的算法:
pdom(x) = {y in N: y pdom x}
ipdom(x) = {y in N: y ipdom x}
for [x,y,label] in E such that y not in pdom(x)
{
Lub = ipdom(x);
if !label
x = -x
t = y;
while(t!=Lub)
{
CD(t) = CD(t) U {x}//U表示求并集
t = ipdom(t);
}
}
上述偽代碼中的!label表示由block x到block y的執行條件為false。
計算CD的算法用一句話概括:對于[x,y,label],在支配節點樹中,從ipdom(x)到y的路徑上的所有節點都控制依賴于x,不包括ipdom(x)。
以[1,2,true]為例,ipdom(x) = 7,從下面的后繼支配節點樹可知,7到2經過的節點有6,2(不包括7),因此節點6和2都控制依賴于節點1.
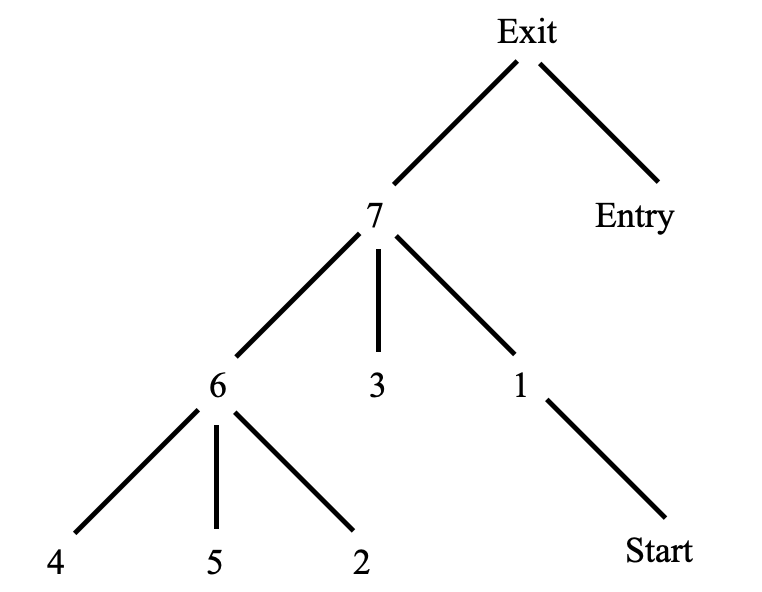
后繼支配節點樹
下圖是CD計算的結果:整篇文章都使用同一個控制流圖作為實例
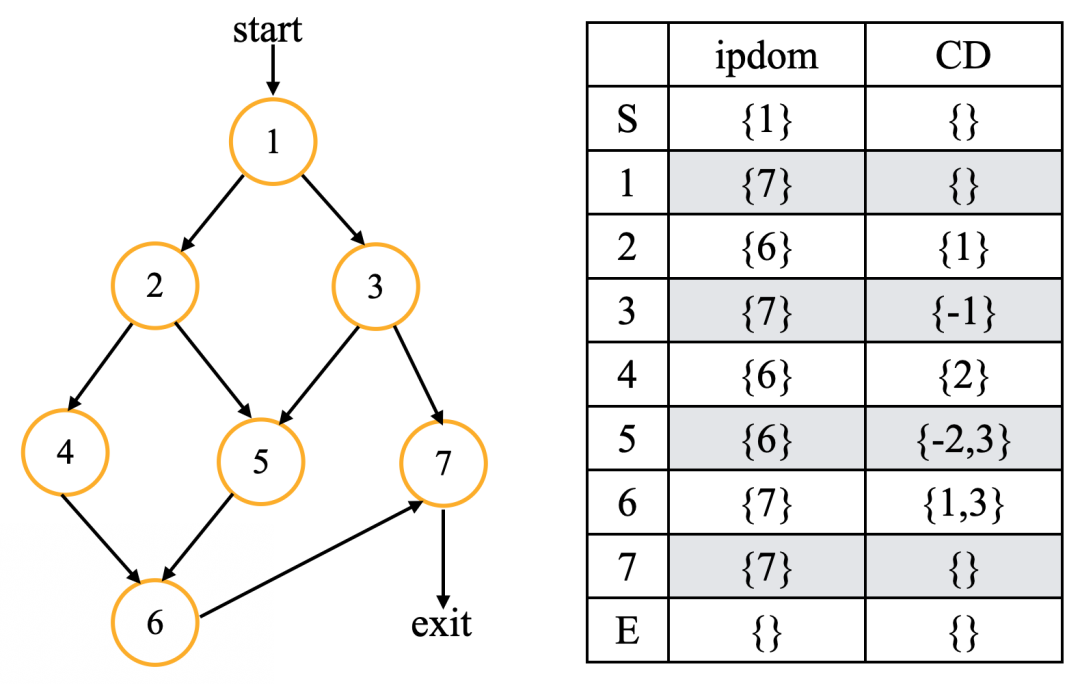
CD計算結果
2.3. 計算R&K
p = 1;
for x in N
t = CD(x);
if t in K
{
//性質2
R(x) = q such that K(q) = t;
}
else
{
K(p) = t;
R(x) = p++;
}
性質1:每一個block x有且僅有一個對應的p = R(x)
性質2:對于兩個不同的block,如果它們的控制依賴都為k(p),則這兩個block對應的寄存器都為p(對應上述算法中的if語句)
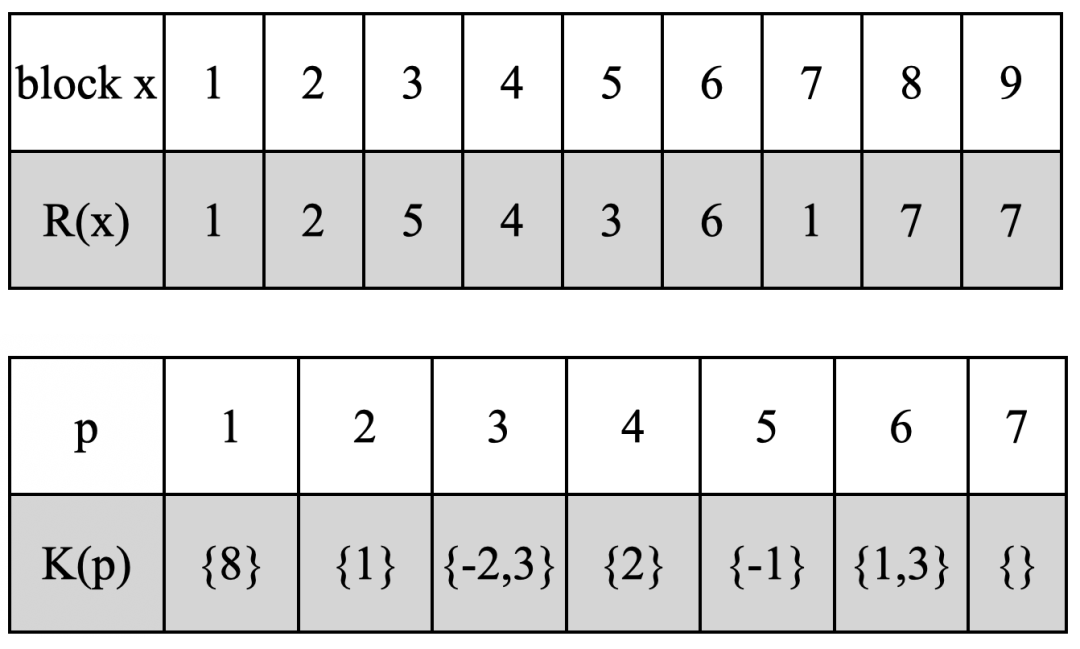
R與K的計算結果
2.4. Augment K
k(p)表明p需要在哪些block初始化,但是存在一條路徑,剛好沒有經過k(p),這個時候p沒有被初始化。因此需要在start節點對p進行初始化。
主要是針對類似的if語句嵌套:
//原始的控制流
if(condition1)
{
block1
if(codition2)
{
block2
}
else
{
block3
}
}
上面的控制流最終會轉化成如下的順序執行,只是每個block會有一個p寄存器去guard。
最終會轉化為這樣:
//轉換后的順序執行,是否執行受p寄存器控制
(p1) block1;//p2與p3都會在block1中初始化
(p2) block2;
(p3) block3;
原始的控制流中p2與p3都會在block1中初始化,如果block1沒有執行,那么p2與p3就沒有被初始化。因此需要在開始節點處將p2與p3初始化為false。
為什么初始化為false而不是true?因為block1沒有執行,說明block2與block3也不應該執行,所以初始化為false。
上述過程是為什么要做Augment K,實際上Augment K要做的只有一件事:找到未初始化的寄存器p,在start節點處將p初始化為false。
在程序中找到為初始化的變量很簡單,從后向前做活躍變量分析,如果變量在入口處還是活躍的,則該變量沒有被初始化。
因為從后向前做活躍變量分析的時候,變量的每次定義都會被Kill掉(公式1),如果在程序的入口處都沒有被Kill掉說明該變量是沒有被初始化過的。
(公式1)
(公式2)
本算法中只需要對p寄存器進行活躍變量分析,use和def分別對應已經求出的R與K。
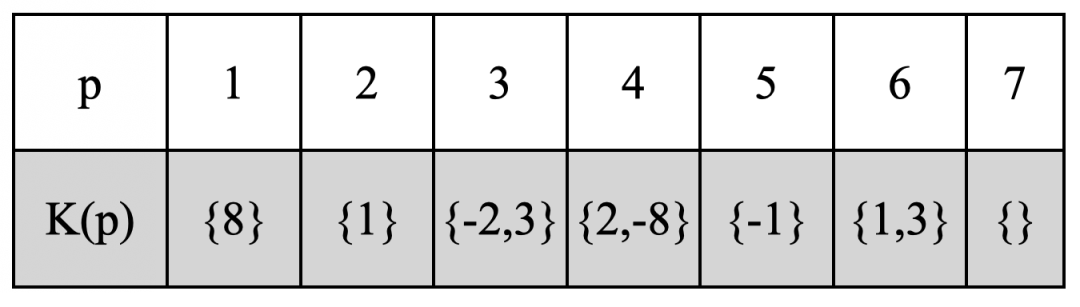
Augment K結果
四個步驟做完后最終的結果如下:
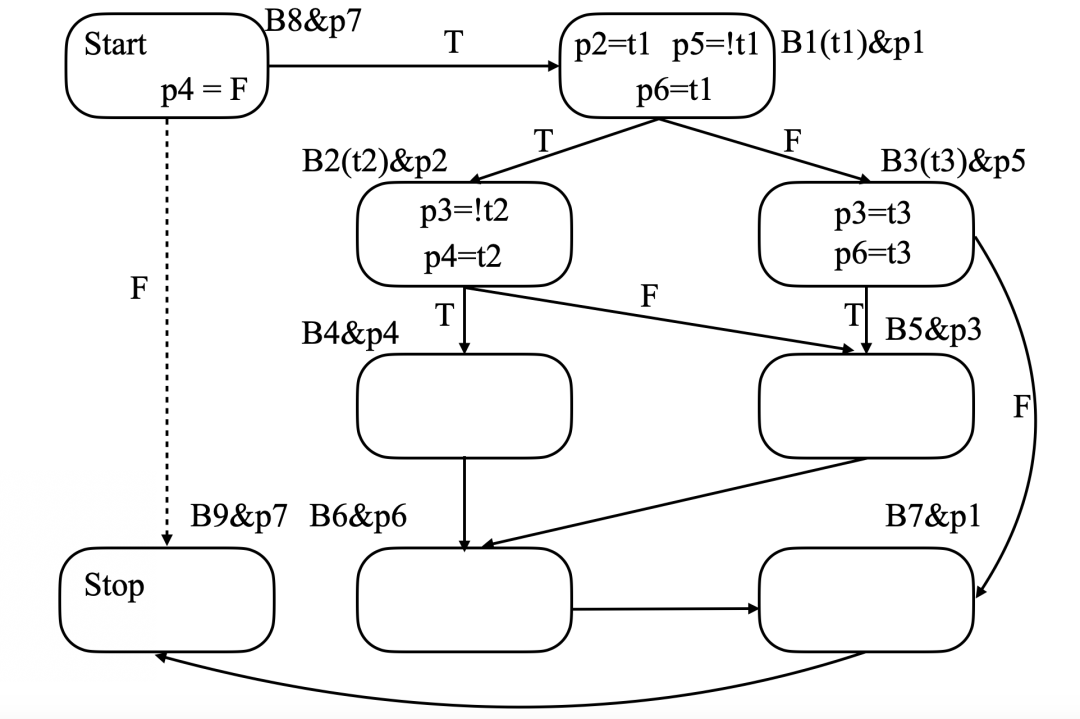
p寄存器分配的最后結果
圖中B2(t2)p2表示寄存器p2控制B2,條件t2與B2相關聯。
3.后記
剛接觸if-conversion算法的時候覺得挺復雜的,在寫文章的過程中對整個算法的理解又有了更深刻的理解,有一種無法言喻的喜悅。
-
cpu
+關注
關注
68文章
10829瀏覽量
211193 -
指令
+關注
關注
1文章
607瀏覽量
35653 -
數據流
+關注
關注
0文章
119瀏覽量
14335
發布評論請先 登錄
相關推薦
有限通信資源下多數據流連接的降載算法
大多數為單指令周期
sse指令集
什么是因特網數據流單指令序列擴展?
網絡數據流存儲算法分析與實現

一種動態調度與靜態優化的數據流編譯系統
數據流編程模型優化
發掘函數級單指令多數據向量化的方法
改進的多數據流協同頻繁項集挖掘算法
一種支持單雙模式選擇的SIMD編譯優化算法
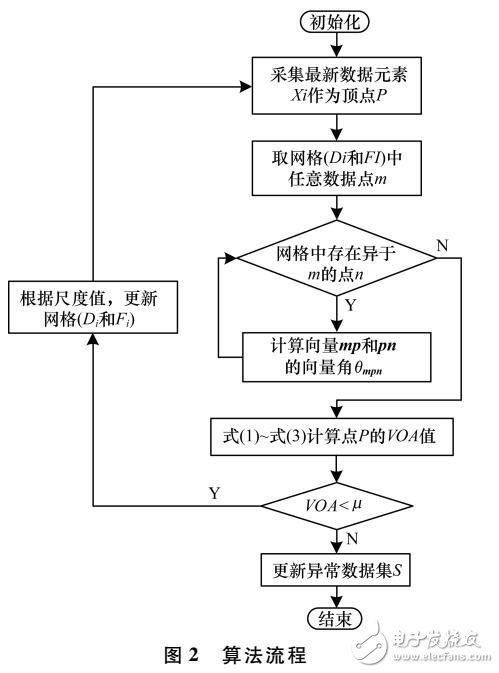
基于角度方差的數據流異常檢測算法
DSP的并行指令分析和冗余優化算法





 工商網監
工商網監
評論