") 如何讓Transformer在征程5上跑得既快又好?以SwinT部署為例的優(yōu)化探索
如何讓Transformer在征程5上跑得既快又好?以SwinT部署為例的優(yōu)化探索
摘要:SwinT是目前視覺transformer模型中的典型代表,在常見視覺任務,如分類、檢測、分割都有非常出色的表現。雖然在相同計算量的模型指標上,SwinT已經可以和傳統CNN為基礎的視覺模型相媲美,但是SwinT面向不同平臺的硬件離線部署仍然存在很多問題。本文以SwinT在地平線征程5平臺上的量化部署為切入點,重點介紹兩個方面,一方面是如何通過調整量化配置訓練得到SwinT最優(yōu)的量化精度,另一方面是如何通過調整模型結構使得SwinT在征程5平臺上能夠得到最優(yōu)的延時性能。最終在地平線征程5平臺上,可以通過低于1%的量化精度損失,得到FPS為133的部署性能。同時該結果與端側最強GPU上SwinT的部署性能相當(FPS為165)。
簡介
Transformer用直接計算sequence間元素的相關性(attension)在NLP方面徹底替換了RNN/LSTM,近年來很多工作都在嘗試把Transformer引入到視覺任務中來,其中ViT,SwinTransformer等都是視覺Transformer的典型代表。
SwinT主要是解決Transformer應用在圖像領域的兩個問題:圖像的分辨率很大、視覺實體的尺寸區(qū)別很大。這都會造成Transformer在圖像領域的計算代價巨大。SwinT通過層級式的transformer和移動窗口,在計算量可控的情況下,利用Transformer得到圖像在不同尺度下的特征表示,從而直接在現有視覺框架下,部分替換CNN。
根據SwinT論文中提供的結論,SwinT在分類、檢測、分割等經典視覺任務上都有很好的表現,但是相對于傳統CNN來說,并沒有絕對的優(yōu)勢。尤其在檢測部署的幀率上,使用SwinT作為backbone的情況下,參數量比較大,同時幀率會出現顯著的下降。其實涉及到Transformer相關的模型,在目前已有的計算平臺上的量化部署都會遇到類似的問題。
SwinT的量化主要有三種問題:第一,算子量化(包括部署)不支持,如roll算子在舊的ONNX框架上沒有支持;第二,算子自身不適合直接量化,如LayerNorm,Softmax,GeLU等,這些算子直接量化一般會造成比較大的精度損失;第三,輔助信息的輸入,如位置編碼,需要注意量化的方式。
SwinT的部署主要有兩種問題:第一,Vector計算占比比較大,如Elementwise、Reduce等;第二,數據不規(guī)則搬運的算子比較多,如Reshape、Transpose等。這些原因導致SwinT對大算力張量計算的平臺來說并不友好。
因此本文主要著重對于上面提到的,SwinT在地平線征程平臺上的量化部署問題,有針對性的提出量化和部署需要改進的地方,得到SwinT在征程5平臺上的最優(yōu)量化部署性能,同時這種建議未來也可以推廣到在征程5平臺上優(yōu)化任何Transformer相關的模型。
優(yōu)化方法
1.基本情況
在優(yōu)化之前,首先明確一下SwinT在征程5平臺上支持的基本情況,這些情況能夠保證SwinT可以在征程5平臺上運行起來,然后才能進一步討論優(yōu)化方向和優(yōu)化思路。
算子支持情況
SwinT公版模型需要的所有算子列表如下:
reshape、permute、transpose、view、roll、LayerNorm、matmul、mean、mul、add、flatten、masked_fill、unsqueeze、AdaptiveAvgPool1d、GeLU、Linear。
目前,在地平線的量化工具和征程5平臺上,以上SwinT需要的所有算子都是可以完全支持的,這是保證SwinT能夠在征程5平臺上正常運行的基礎。
量化精度
在SwinT的量化過程中,使用Calibration+QAT的量化方式得到最終的SwinT的量化精度。由于SwinT中所有算子的量化是完全支持的,那么得到初版的量化精度是非常簡單的。
不過在默認的量化配置下,初步的量化精度只有76.90%(浮點80.58%),相對于浮點下降接近于4個點。這是比較明顯的量化損失。需要說明的是,默認的量化配置是指全局采用int8的量化方式。
部署情況
SwinT模型在地平線征程5平臺的初次部署,性能極低,FPS小于1,幾乎處于不可用的狀態(tài)。通過分析發(fā)現,SwinT相比于傳統CNN的模型,Vector計算占比比較多,如Elementwise、Reduce等;同時數據不規(guī)則搬運的算子較多,如Reshape,Transpose等。這些特性對大算力張量計算的征程5平臺來講極不友好。
這里有一些征程5平臺部署SwinT的情況分析:
SwinT模型張量Tensor與向量Vector的計算比例大約是218:1(將矩陣乘運算歸類為張量運算),而征程5平臺的實際張量運算能力與向量運算的計算比例遠高于此,導致SwinT在征程5平臺的利用率不高。
Reshape / Transpose 等數據搬運算子占比較高。在Transformer之前的CNN模型沒有這方面的需求,因此初次處理SwinT相關的Transformer模型時,這類算子除了本身的實現方式,功能、性能優(yōu)化都不太完善。
2.量化精度優(yōu)化
因為SwinT的量化訓練,主要是采用Calibration+QAT的方式來實現的,因此量化精度的優(yōu)化,主要從兩個方面入手,分別是算子的支持方式、量化訓練的參數配置。
算子的支持方式
算子的支持方式,主要是針對一些量化不友好的算子,在中間結果引入int16的量化方式,這在地平線征程5平臺上是可以有效支持的。常見的量化不友好算子,如LayerNorm,SoftMax等。以LayerNorm為例:其量化方法是使用多個細粒度的算子(如mul,add,mean,sqrt)拼湊起來的。為了保證量化的精度,尤其是mean的操作,因此LayerNorm除了在輸入輸出端使用int8量化之外,中間的結果均采用int16的量化方法。
使用方式:參考目前地平線提供的QAT量化工具,浮點算子到QAT算子的自動映射。用戶只需要定義浮點模型,由QAT工具自動實現浮點和量化算子的映射。因此大部分量化算子的實現方式,用戶是不需要感知的,尤其像LayerNorm和SoftMax這種算子的量化方式,工具本身默認提供int16的量化方式,用戶只需要正常使用社區(qū)的浮點算子即可,而不需要再手動設置QAT相關的配置。
注:需要說明的是,LayerNorm有時候需要使用QAT量化工具提供的浮點算子,但原因在部署優(yōu)化中會提到,和算子量化方式的支持沒有關系。
量化訓練的參數配置
量化訓練的參數配置主要分為量化配置和訓練的超參配置。量化配置除了算子自身的實現方式外,主要是針對輸入輸出的調整,輸入分為兩種類型,如果是圖像輸入,可以采用固定的scale(一般為1/128.0);如果是輔助信息輸入,如位置編碼,需要采用統計的動態(tài)scale,才能使得量化過程保留更多輸入信息。而對于模型輸出默認采用更高精度的方式(如int32)即可。
使用方式:量化訓練過程的超參設置,則比較簡單,常見的調整內容如Lr大小,Epoch長度等,詳細內容參考量化訓練工具提供的Debug文檔。
3.部署優(yōu)化
部署優(yōu)化的前提是不改變模型的結構和計算邏輯,不需要重訓模型,模型參數可以等價復用。基于這樣的原則,從編譯器的角度,結合SwinT模型的計算方式,對SwinT在征程5平臺上的部署進行針對性的優(yōu)化。
上文中分析了SwinT的部署主要有Vector計算占比過高和不規(guī)則數據搬運算子較多這兩個問題,因此,整個編譯器優(yōu)化的方式,其實就是通過軟件優(yōu)化Tile,提高數據復用,減少了數據加載帶寬,算子合并實現優(yōu)化。
接下來重點講一下,從編譯器的思路出發(fā),根據編譯器可以優(yōu)化的內容,要么編譯器內部優(yōu)化,要么模型有針對性的進行調整,最終可以得到SwinT部署的最優(yōu)性能。需要注意的是,如果是模型需要針對性調整的地方,會在具體的使用方式中體現出來。如果不需要調整,屬于編譯器內部優(yōu)化的,則會自動沉淀到編譯器默認使用方式中去,直接使用即可。
算子映射的優(yōu)化
將不同的算子進行靈活的映射,充分利用硬件資源,增加并行計算的機會。如使用Conv運算部件實現Reduce操作;使用MatMul實現Transpose等。
matmul的優(yōu)化使用方式:

LayerNorm的優(yōu)化使用方式,這里是單獨的transpose優(yōu)化,和上文中用戶不需要感知的int16量化(默認使用)區(qū)分開來:

算子優(yōu)化
算子優(yōu)化主要是針對算子實現方式的單獨優(yōu)化,如Reshape/Transpose算子Tile優(yōu)化,Batch MatMul的支持優(yōu)化等。
使用方式:其中Batch MatMul的優(yōu)化,內部batch級別的循環(huán)展開的Tile優(yōu)化,由量化工具和編譯器內部完成,用戶不需要感知。
算子合并
征程5平臺是張量運算處理器,數據排布是多維表示,而Reshape,Transpose的表達語義是基于CPU/GPU的線性排布。連續(xù)的Reshape & Transpose操作,例如window partition、window reverse,征程5平臺可只進行一次數據搬運實現。
編譯器內部,連續(xù)的reshape可合并成一條reshape,連續(xù)的transpose算子可合并成一條permute,征程5平臺可一次搬運完成。
而window partition,window reverse則被封裝成獨立的算子,在模型,量化,部署階段,直接使用即可,這樣可以讓編譯器在部署過程中獲得最佳性能。
使用方式:

其他圖優(yōu)化
對于pixel to pixel計算的算子或者數據搬運的算子(如elementwise,concat/split的部分軸),reshape/transpose算子可穿透這些算子,前后移動reshape/transpose穿透以上算子,移動后可進行算子合并的優(yōu)化。
使用方式:這些優(yōu)化由編譯器內部完成,用戶不需要感知。
4維高效支持
地平線征程5平臺最早針對的是以CNN為基礎的圖像處理,但在實踐過程中,逐漸衍生出支持語音,Transformer等類型的模型。不過以CNN為基礎的模型仍然是效率最高的模型,這一點在編譯器內部的體現就是4d-Tensor仍然是最高效的支持方式。
如果不是4d-Tensor的話,很多算子編譯器內部也會主動轉成4d(某些維度為1)來做,結合編譯器常規(guī)的padding方式(如2H16W8C/2H32W4C對齊),會導致一些計算如Conv,MatMul的效率很低,因為多了很多無效的計算。
這一點在模型上的體現就是,可以使用常規(guī)的4維算子替換原來任意維度的設置,避免不必要的冗余計算。常見的替換方式如下,中間配合任意維度的reshape,view,transpose可以完成等價替換。
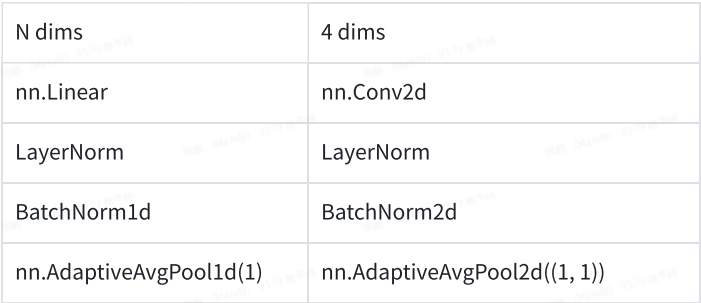
使用方式(以patch merging為例):

實驗結果
1.SwinT在征程5平臺優(yōu)化結論
量化效果

部署效果
通過優(yōu)化,SwinT在征程5平臺上,可以達到的FPS為133。
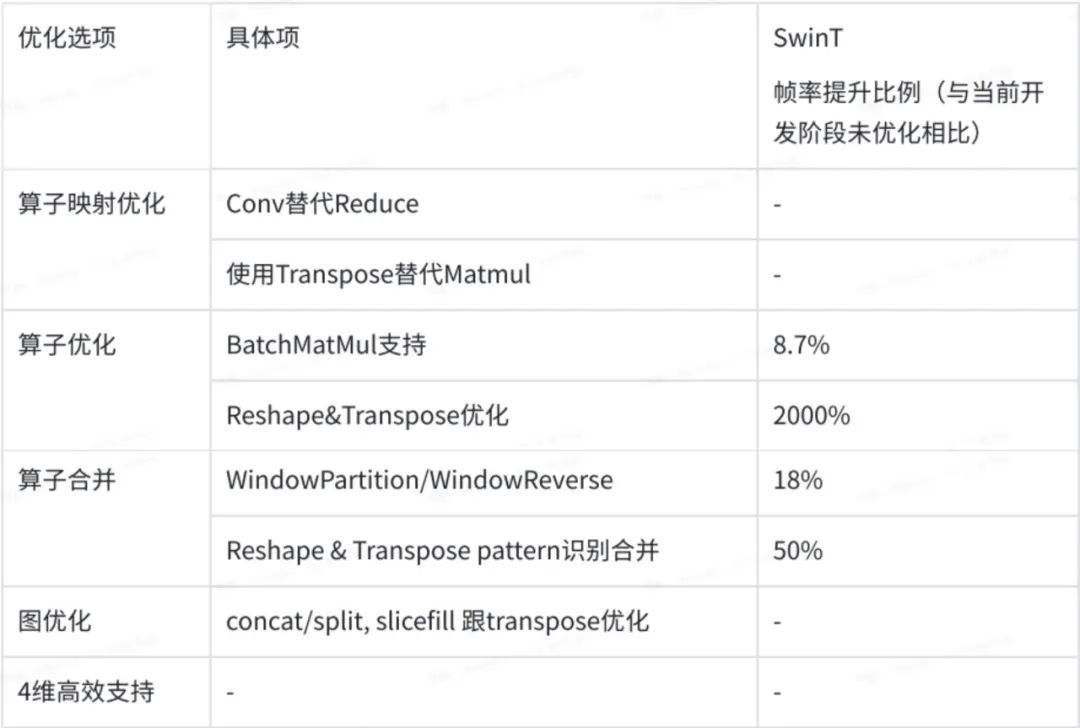
注:-代表缺失實際的統計數據
參考SwinT在端側最強GPU上的部署性能(FPS=165),地平線征程5平臺部署SwinT模型,在有性能保證的情況下,具有一定的精度優(yōu)勢。
2.Transformer在征程5平臺上的優(yōu)化建議
在完成SwinT在征程5平臺上的高效部署之后,其實也可以得出常見的Transformer征程5平臺上的優(yōu)化思路。這里簡單列一些方向供參考。
使用已封裝算子
上面提到的window partition,window reverse,在模型層面封裝成一個算子,編譯器只進行一次數據搬運即可完成高效部署。因此建議在模型搭建階段使用已經封裝好的算子,其他常見的還有LayerNorm,MatMul等。未來地平線也會提供更多定制算子的高效實現,如MultiHeadAttention等。
Tensor的對齊建議
征程5平臺運算的時候有最小的對齊單位,并且不同的算子對齊不一致,以下簡單列出常見的征程5平臺運算部件的計算對齊要求:

2H16W8C,表示計算的時候H方向對齊到2, W方向對齊到16,C方向對齊到8,例如:

以上elementwise add 實際計算為數據對齊后的大小[1,2,3344,2232], 所以盡量讓算子的對齊浪費少些。如果像layernorm中有連續(xù)的如上的elementwise操作,其實可以將Tensor reshape為[1,2,1666, 2227] 再進行連續(xù)的elementwise計算。
按照征程5平臺的計算對齊合理的構建Tensor大小能提高征程5平臺的計算利用率。因此結合SwinT部署優(yōu)化中的4維高效支持的建議:4d-Tensor,結合合理的大小設置,可以穩(wěn)定提供部署的利用率。
減少算子間的Reorder
根據Tensor對齊建議中提到的征程5平臺不同的運算部件有不同的對齊,在不同運算部件切換的時候,除了計算對齊浪費的開銷,還有數據Reorder的開銷,即從2H16W8C 向256C轉換的開銷。所以在此建議構建模型順序的時候盡量避免不同計算對齊的算子連續(xù)橫跳。
在此給一些優(yōu)化的建議,比如Conv->ReduceSum->Conv串接的模型,其實reduce sum也可以替換成用conv實現,比如reduce on C可以構建為input channel = C, output channel = 1的conv, reduce on H/W 可以構建為kernel_h = H or kernel_w = W 的conv。
總結
本文通過對SwinT在地平線征程5平臺上量化部署的優(yōu)化,使得模型在該平臺上用低于1%的量化精度損失,得到FPS為133的部署性能,與主流競品相比效果相當。同時,通過SwinT的部署經驗,推廣到所有的Transformer,給出Transformer在征程5平臺上高效部署的優(yōu)化建議。
審核編輯:湯梓紅
-
gpu
+關注
關注
28文章
4701瀏覽量
128708 -
模型
+關注
關注
1文章
3173瀏覽量
48715 -
Transformer
+關注
關注
0文章
141瀏覽量
5982 -
nlp
+關注
關注
1文章
487瀏覽量
22012 -
征程5
+關注
關注
0文章
14瀏覽量
2672
原文標題:如何讓Transformer在征程5上跑得既快又好?以SwinT部署為例的優(yōu)化探索
文章出處:【微信號:horizonrobotics,微信公眾號:地平線HorizonRobotics】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
為什么transformer性能這么好?Transformer的上下文學習能力是哪來的?
跑在ram里快還是跑在flash里快?
如何更改ABBYY PDF Transformer+界面語言
如何更改ABBYY PDF Transformer+旋轉頁面
以貼片天線設計為例的HFSS在天線設計中的應用介紹
以hello world為例介紹如何讓代碼部署并運行在ARM平臺上
你了解在單GPU上就可以運行的Transformer模型嗎
如何讓WindowsXP跑得更快更穩(wěn)
我們可以使用transformer來干什么?
讓MDK既支持ARM又支持STC單片機.






 工商網監(jiān)
工商網監(jiān)
評論