 LeCun新作:全面綜述下一代「增強語言模型」
LeCun新作:全面綜述下一代「增強語言模型」
【導讀】語言模型該怎么增強?
ChatGPT算是點燃了語言模型的一把火,NLP的從業者都在反思與總結未來的研究方向。

最近圖靈獎得主Yann LeCun參與撰寫了一篇關于「增強語言模型」的綜述,回顧了語言模型與推理技能和使用工具的能力相結合的工作,并得出結論,這個新的研究方向有可能解決傳統語言模型的局限性,如可解釋性、一致性和可擴展性問題。

論文鏈接:https://arxiv.org/abs/2302.07842
增強語言模型中,推理意為將復雜的任務分解為更簡單的子任務,工具包括調用外部模塊(如代碼解釋器、計算器等),LM可以通過啟發式方法單獨使用或組合利用這些增強措施,或者通過演示學習實現。
在遵循標準的missing token預測目標的同時,增強的LM可以使用各種可能是非參數化的外部模塊來擴展上下文處理能力,不局限于純語言建模范式,可以稱之為增強語言模型(ALMs, Augmented Language Models)。
missing token的預測目標可以讓ALM學習推理、使用工具甚至行動(act),同時仍然能夠執行標準的自然語言任務,甚至在幾個基準數據集上性能超過大多數常規LM。
增強語言模型
大型語言模型(LLMs)推動了自然語言處理的巨大進步,并且已經逐步成為數百萬用戶所用產品的技術核心,包括寫代碼助手Copilot、谷歌搜索引擎以及最近發布的ChatGPT。
Memorization 與Compositionality 能力相結合,使得LLM能夠以前所未有的性能水平執行各種任務,如語言理解或有條件和無條件的文本生成,從而為更廣泛的人機互動開辟了一條實用的道路。
然而,目前LLM的發展仍然受到諸多限制,阻礙了其向更廣泛應用場景的部署。比如LLMs經常提供非事實但看似合理的預測,也被稱為幻覺(hallucinations),很多錯誤其實完全是可以避免的,包括算術問題和在推理鏈中出現的小錯誤。

此外,許多LLM的突破性能力似乎是隨著規模的擴大而出現的,以可訓練參數的數量來衡量的話,之前的研究人員已經證明,一旦模型達到一定的規模,LLM就能夠通過few-shot prompting來完成一些BIG-bench任務。
盡管最近也有工作訓練出了一些較小的LMs,同時還能保留一些大模型的能力,但當下LLMs的規模和對數據的需求對于訓練和維護都是不切實際的:大型模型的持續學習仍然是一個開放的研究問題。
Meta的研究人員們認為這些問題源于LLMs的一個基本缺陷:其訓練過程就是給定一個參數模型和有限的上下文(通常是n個前后的詞),然后進行統計語言建模。
雖然近年來,由于軟件和硬件的發展,上下文尺寸n一直在增長,但大多數模型仍然使用相對較小的上下文尺寸,所以模型的巨大規模是儲存沒有出現在上下文知識的一個必要條件,對于執行下游任務來說也很關鍵。
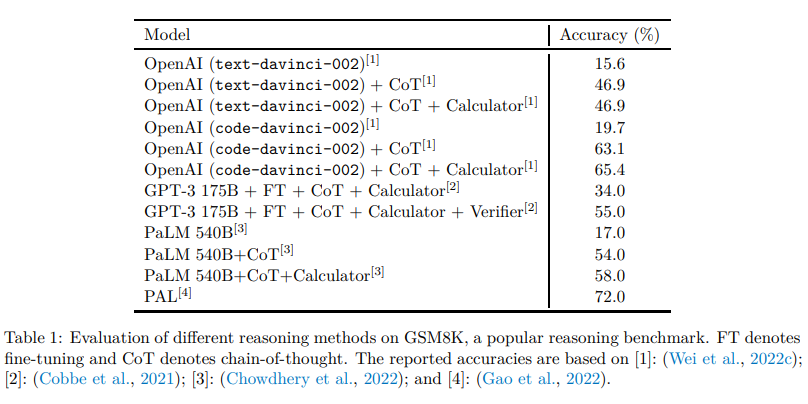
因此,一個不斷增長的研究趨勢就是用稍微偏離上述的純統計語言建模范式的方式來解決這些問題。
例如,有一項工作是通過增加從「相關外部文件中提取的信息」計算相關度來規避LLM的有限語境尺寸的問題。通過為LMs配備一個檢索模塊,從數據庫中檢索出給定語境下的此類文檔,從而實現與更大規模LM的某些能力相匹配,同時擁有更少的參數。
需要注意的是,現在產生的模型是非參數化的,因為它可以查詢外部數據源。更一般的,LM還可以通過推理策略改善其上下文,以便在生成答案之前生成更相關的上下文,通過更多的計算來提升性能。
另一個策略是允許LM利用外部工具,用LM的權重中不包含的重要缺失信息來增強當前語境。盡管這些工作大多旨在緩解上述LM的缺點,但可以直接想到,更系統地用推理和工具來增強LM,可能會導致明顯更強大的智能體。
研究人員將這些模型統稱為增強語言模型(ALMs)。
隨著這一趨勢的加速,跟蹤和理解眾多模型變得十分困難,需要對ALMs的工作進行分類,并對有時出于不同目的而使用的技術術語進行定義。
推理Reasoning
在ALM的背景下,推理是將一個潛在的復雜任務分解成更簡單的子任務,LM可以自己或使用工具更容易地解決。
目前有各種分解子任務的方法,例如遞歸或迭代,在某種意義上來說,推理類似于LeCun于2022年發表論文「通往自主機器智能的路線」中定義的計劃。

論文鏈接:
https://openreview.net/pdf?id=BZ5a1r-kVsf
在這篇survey中,推理指的是提高LM中推理能力的各種策略,比如利用少量的幾個例子進行step-by-step推理。雖然目前還沒有完全理解LM是否真的在推理,或者僅僅是產生了一個更大的背景,增加了正確預測missing tokens的可能性。
鑒于目前的技術水平,推理可能是一個被濫用的說法,但這個術語已經在社區內廣泛使用了。在ALM的語境中,推理的一個更務實的定義是在得出prompt的答案之前給模型更多的計算步驟。
工具Tool
對于ALM來說,工具是一個外部模塊,通常使用一個規則或一個特殊的token來調用,其輸出包含在ALM的上下文中。
工具可以用來收集外部信息,或者對虛擬或物理世界產生影響(一般由ALM感知):比如說文件檢索器可以用來作為獲取外部信息的工具,或者用機器臂對外部影響進行感知。
工具可以在訓練時或推理時被調用,更一般地說,模型需要學習與工具的互動,包括學習調用其API。
行為Act
對于ALM來說,調用一個對虛擬或物理世界有影響的工具并觀察其結果,通常是將其納入ALM的當前上下文。
這篇survey中介紹的一些工作討論了在網絡中搜索(seraching the web),或者通過LMs進行機械臂操縱。在略微濫用術語的情況下,有時會把ALM對一個工具的調用表示為一個行動(action),即使沒有對外部世界產生影響。
為什么要同時討論推理和工具?
LM中推理和工具的結合應該允許在沒有啟發式的情況下解決廣泛的復雜任務,即具有更好的泛化能力。
通常情況下,推理會促進LM將一個給定的問題分解成可能更簡單的子任務,而工具則有助于正確地完成每個步驟,例如從數學運算中獲得結果。
換句話說,推理是LM結合不同工具以解決復雜任務的一種方式,而工具則是避免推理失敗和有效分解的一種方式。
兩者都應該受益于對方,并且推理和工具可以放在同一個模塊里,因為二者都是通過增強LM的上下文來更好地預測missing tokens,盡管是以不同的方式。
為什么要同時討論工具和行動?
收集額外信息的工具和對虛擬或物理世界產生影響的工具可以被LM以同樣的方式調用。
例如,輸出python代碼解決數學運算的LM和輸出python代碼操縱機械臂的LM之間似乎沒有什么區別。
這篇綜述中討論的一些工作已經在使用對虛擬或物理世界產生影響的LM,在這種觀點下,我們可以說LM有行動的潛力,并期望在LM作為自主智能體的方向上取得重要進展。
分類方法
研究人員將綜述中介紹的工作分解上述三個維度,并分別介紹,最后還討論了其他維度的相關工作。
對讀者來說,應該記得,其中很多技術最初是在LM之外的背景下引入的,如果需要的話,盡可能查看提到的論文的介紹和相關工作。
最后,盡管綜述專注于LLM,但并非所有的相關工作都采用了大模型,而是以LM的正確性為宗旨。
審核編輯 :李倩
-
語言模型
+關注
關注
0文章
506瀏覽量
10245 -
nlp
+關注
關注
1文章
487瀏覽量
22011 -
ChatGPT
+關注
關注
29文章
1548瀏覽量
7488
原文標題:ChatGPT之后何去何從?LeCun新作:全面綜述下一代「增強語言模型」
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

24芯M16插頭在下一代技術中的潛力







 工商網監
工商網監
評論