 Python序列的字典類型介紹
Python序列的字典類型介紹
字典
介紹
字典是“鍵值對”的無序可變序列,字典中的每個元素都是一個“鍵值對”,包含:“鍵對象”和“值對象”。
可以通過“鍵對象”實現快速獲取、刪除、更新對應的“值對象”
字典特點:
無序, 可變, 大括號 {} + 鍵值對 k,v
字典是 Python 項目中最常用的序列類型之一, 對應Java 中常用的 Json 數據類型
操作
字典的創建
通過 {} + kv
來創建
通過dict()來創建字典對象(兩種方式)
過zip()創建字典對象
通過fromkeys創建值為空的字典
字典(類比Json)
“鍵”是任意的不可變數據,比如:整數、浮點數、字符串、元組. 但是:列表、字典、集合這些可變對象,不能作為“鍵”.
并且“鍵”不可重復。
#“值”可以是任意的數據,并且可重復
1. 通過{} 創建字典
a = {'name': 'TimePause',
'age': 18, 'sex': 'man'}
print(a)
2. 通過dict()來創建字典對象(兩種方式)
b =
dict(name='TimePause', age=18, sex='man')
a = dict([("name", "TimePause"),
("age", 18)])
print(b)
print(a)
c = {} # 空的字典對象
d = dict() #
空的字典對象
print(c)
print(d)
3. 通過zip()創建字典對象
k = ["name", "age",
"sex"]
v = ["TimePause", 18, "man"]
d = dict(zip(k, v))
print(d) #
{'name': 'TimePause', 'age': 18, 'sex': 'man'}
4. 通過fromkeys創建值為空的字典
f =
dict.fromkeys(["name", "age", "sex"])
print(f) # {'name': None, 'age': None,
'sex': None}
元素的訪問:
字典元素的訪問
a = {'name': 'TimePause', 'age': 18, 'sex': 'man'}
1. 通過
[鍵] 獲得“值”。若鍵不存在,則拋出異常。
b = a["name"]
print(b)
#c = a["birthday"]
KeyError: 'birthday'
#print(c)
2. 通過get()方法獲得“值”. 推薦使用.
優點是:指定鍵不存在,返回None;也可以設定指定鍵不存在時默認返回的對象. 推薦使用get()獲取“值對象”
b =
a.get("name")
c = a.get("birthday")
d = a.get("birthday",
"值不存在")
print(b)
print(c)
print(d)
3. 列出所有的鍵值對
b =
a.items()
print(b) # dict_items([('name', 'TimePause'), ('age', 18), ('sex',
'man')])
4. 列出所有的鍵,列出所有的值
k = a.keys()
v = a.values()
print(k, v)
dict_keys(['name', 'age', 'sex']) dict_values(['TimePause', 18, 'man'])
-
len() 鍵值對的個數
b = len(a)
print(b)
6. 檢測一個“鍵”是否在字典中
print("name"
in a) # True
字典元素添加、修改、刪除
- 給字典新增“鍵值對”。如果“鍵”已經存在,則覆蓋舊的鍵值對;如果“鍵”不存在,則新增“鍵值對
a =
{'name': 'TimePause', 'age': 18, 'sex': 'man'}
a['name'] =
"時間靜止"
a['phone'] = 18322222222
print(a)
- 使用 update()
將新字典中所有鍵值對全部添加到舊字典對象上。如果 key 有重復,則直接覆蓋
a = {'name': 'TimePause', 'age': 18,
'sex': 'man'}
b = {'name': '時間靜止', 'age': 18, 'phone':
18322222222}
a.update(b) # 舊字典.update(新字典)
print(a)
- 字典中元素的刪除,可以使用
del() 方法;或者 clear() 刪除所有鍵值對; pop() 刪除指定鍵值對,并返回對應的“值對象
a = {'name':
'TimePause', 'age': 18, 'sex': 'man'}
del (a["name"])
print(a) # {'age':
18, 'sex': 'man'}
a.pop("age")
print(a) # {'sex': 'man'}
popitem() :以后入先出的方式刪除和返回該鍵值對
#刪除并返回一個(鍵,值)對作為 2 元組。對以 LIFO(后進先出)順序返回。如果 dict
為空,則引發 KeyError。
a = {'name': 'TimePause', 'age': 18, 'sex':
'man'}
a.popitem()
print("第一次調用popitem",
a)
a.popitem()
print("第二次調用popitem",
a)
a.popitem()
print("第三次調用popitem", a)
#a.popitem() # KeyError:
'popitem(): dictionary is empty'
#print("第四次調用popitem", a)
序列解包
序列解包可以用于元組、列表、字典。序列解包可以讓我們方便的對多個變量賦值
#序列解包
#序列解包可以用于元組、列表、字典。序列解包可以讓我們方便的對多個變量賦值
x, y, z = (20, 30, 10) #
變量
(a, b, c) = (9, 8, 10) # 元組
[m, n, p] = [10, 20, 30] # 列表
序列解包用于字典時,默認是對“鍵”進行操作;
a = {'name': 'TimePause', 'age': 18, 'sex':
'man'}
name, age, sex = a
print(name)
如果需要對鍵值對操作,則需要使用items()
name, age, sex = a.items()
print(name)
如果需要對“鍵”進行操作,則需要使用keys()
name, age, sex = a.keys()
print(name)
如果需要對“值”進行操作,則需要使用values()
name, age, sex = a.values()
print(name)
18
表格數據使用字典和列表存儲訪問
#表格數據使用字典和列表存儲訪問
#定義字典對象
a1 = {"name": "才子隊", "season": 1, "winner":
"比爾"}
a2 = {"name": "九頭蛇隊", "season": 2, "winner": "皮爾斯"}
a3 = {"name":
"巨亨隊", "season": 3, "winner": "卡羅爾"}
#定義列表對象tl
tl = [a1, a2,
a3]
print(tl)
print(tl[1].get("name"))
#輸出所有獲勝人員名稱
for x in
range(3):
print(tl[x].get("winner"))
#打印表的所有數據
for i in
range(len(tl)):
print(tl[i].get("name"), tl[i].get("season"),
tl[i].get("winner"))
字典核心底層原理(重要)
一
: 將一個鍵值對放進字典的底層過程
字典對象的核心是散列表. 散列表是一個稀疏數組(總是有空白元素的數組)
數組的每個單元叫做 bucket. 每個 bucket
有兩部分:一個是鍵對象的引用,一個是值對象的引用
由于所有 bucket 結構和大小一致,我們可以通過偏移量來讀取指定bucket
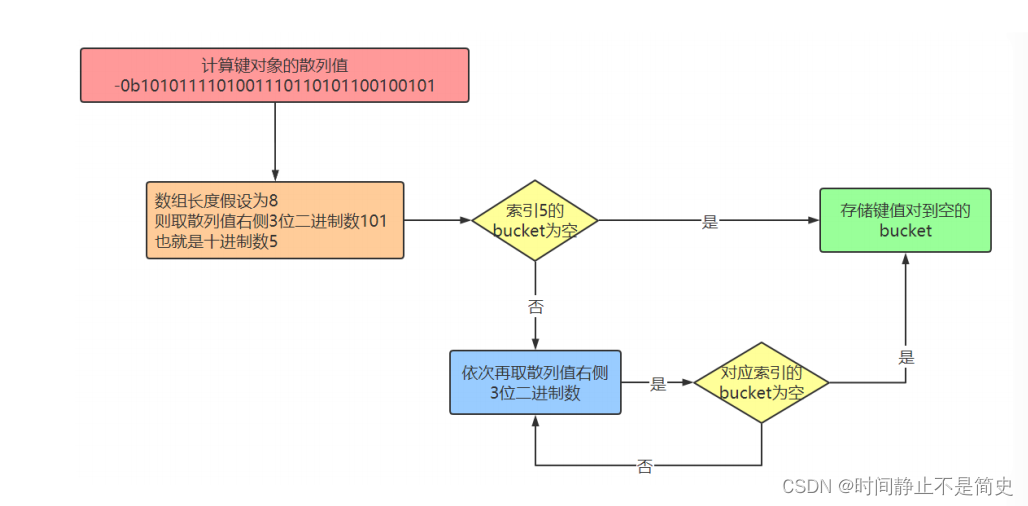
下面操作將一個鍵值對放入字典
假設字典a對象創建完后,數組長度為8
a =
{}
a["name"]="比爾"
我們要把”name”=”比爾”這個鍵值對放到字典對象a中,
首先第一步需要計算鍵”name”的散列值。Python中可以通過hash()來計算。
下面我們通過
Python Console 來查看 name 的hash值
bin(hash("name"))
'-0b1010111101001110110101100100101'
由于數組長度為8,我們可以拿計算出的散列值的最右邊3位數字作為偏移量,即“101”,十進制是數字5。
我們查看偏移量6對應的bucket是否為空
如果為空,則將鍵值對放進去。如果不為空,則依次取右邊3位作為偏移量,即“100”,十進制是數字4
再查看偏移量為7的bucket是否為空。直到找到為空的bucket將鍵值對放進去.
流程圖如下:
字典擴容
python會根據散列表的擁擠程度擴容。“擴容”指的是:創造更大的數組,將原有內容拷貝到新數組中。
接近2/3時,數組就會擴容
二. 根據鍵查找“鍵值對”的底層過程
通過 Python console() 查看字典元素值如下
a.get("name")
'比爾'
1
2
當調用a.get(“name”),就是根據鍵“name”查找到“鍵值對”,從而找到值對象“比爾”。
我們仍然要首先計算“name”對象的散列值:
bin(hash("name"))
'-0b1010111101001110110101100100101'
1
2
和存儲的底層流程算法一致,也是依次取散列值的不同位置的數字。
假設數組長度為8,我們可以拿計算出的散列值的最右邊3位數字作為偏移量,即
101 ,十進制是數字5。
我們查看偏移量5,對應的 bucket 是否為空。如果為空,則返回 None 。
如果不為空,則將這個 bucket
的鍵對象計算對應散列值,和我們的散列值進行比較,
如果相等。則將對應“值對象”返回。
如果不相等,則再依次取其他幾位數字,重新計算偏移量。依次取完后,仍然沒有找到。則返回None
。
流程圖如下:

用法總結:
字典在內存中開銷巨大 (空間換時間)
鍵查詢速度很快
(通過位運算+Hash運算)
往字典里面添加新鍵值對可能導致擴容,導致散列表中鍵的次序變化。
因此,不要在遍歷字典的同時進行字典的修改
鍵必須可散列
數字、字符串、元組,都是可散列的
如果是自定義對象,
需要支持下面三點:
(1) 支持 hash() 函數 (2) 支持通過 eq () 方法檢測相等性 (3) 若 a==b 為真,則
hash(a)==hash(b) 也為真
-
編程
+關注
關注
88文章
3595瀏覽量
93602 -
字符串
+關注
關注
1文章
577瀏覽量
20486 -
元素
+關注
關注
0文章
47瀏覽量
8421 -
python
+關注
關注
56文章
4782瀏覽量
84463
發布評論請先 登錄
相關推薦
Python中常用的數據類型
請問python如何返回元組,列表或字典的?
python字典
python字典高階用法
python字典類型的使用和注意事項







 工商網監
工商網監
評論