 類ChatGPT訓練需高性能芯片大規模并聯,高速接口IP迎紅利時代
類ChatGPT訓練需高性能芯片大規模并聯,高速接口IP迎紅利時代
電子發燒友網報道(文/吳子鵬)近段時間,ChatGPT的火熱重新掀起人工智能產業熱潮,尤其是AIGC(指利用人工智能技術來生成內容)領域,已經進入到狂飆姿態,頭部科技企業爭分奪秒地尋求搶先發布類ChatGPT應用。
眾所周知,類ChatGPT應用是一個吞金獸,微軟公司為了訓練ChatGPT使用了1萬張英偉達的高端GPU。“從訓練的角度來看,計算性能再好的GPU芯片比如A100如果無法集群在一起去訓練,那么訓練一個類ChatGPT的大模型可能需要上百年。因此,AI大模型的訓練對高速接口IP是一個巨大的挑戰,也是一個巨大的機遇。”奎芯科技市場及戰略副總裁唐睿在接受電子發燒友網采訪時表示。
奎芯科技成立于2021年,該公司的口號是“芯粒高速互聯,海量算力源泉 ”。目前,奎芯科技已經推出的高速接口IP組合包括USB、PCIe、SATA、SerDes、MIPI、DDR、HDMI、DP、HBM等豐富的類型。
類ChatGPT帶動接口IP發展
從半導體產業分布來看,IP是底層技術,接口IP同樣如此,因此關鍵性和重要性是不言而喻的。那么在AIGC產業里,接口IP能夠發揮哪些作用呢?唐睿提到了以下幾點。
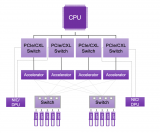
首先是芯片上的互聯接口,也就是Die to Die類型的互聯接口IP,包括UCIe等,用以擴充單芯片的計算能力;其次是Chip to Chip類型的互聯接口IP,包括SerDes/PCIe/CXL等,能夠加快芯片之間的互聯和數據交換,滿足更高帶寬的需求;此外還有內存接口IP,包括SATA、DDR、HBM等,能夠用于打造更高性能的存儲產品,幫助類ChatGPT存儲和交換大規模的數據;再上一層就是數據通訊接口的接口IP。因此,從訓練的角度來看,類ChatGPT應用的爆發,能夠帶來非常大的接口IP需求。
在此前的預測里,有市場調研機構的數據顯示,2022年至2026年高速互聯IP的市場規模有望以75%的年復合增長率快速成長。“接口IP市場的增長一定是跟隨整個高性能計算芯片大趨勢的,包括芯片運算性能、內存和帶寬方面的提升都需要接口IP的幫助,因此芯片用量的提升一定會帶來更大的接口IP用量。”唐睿認為,“同時計算芯片性能的提升已經受限于摩爾定律放緩的影響,單芯片的性能會逐漸遇到瓶頸,那么互聯組成算力集群就是一個有效的手段,這也會加快推動接口IP的發展。”
雖然產業熱潮來臨,不過唐睿并不擔心一下子會涌入很多同行或者友商,造成國內接口IP產業內卷。“市場競爭的激烈程度會增加,但接口IP是高門檻的領域,目前國內做高速混合電路的人才其實并不多,特別是在先進制程上做高速模擬電路設計的人才更少,因此從零組建團隊進入這個領域是非常困難的。”他對此講到。
國產廠商的布局和追趕
從全球產業格局來看,在接口IP方面,目前新思科技和楷登電子等EDA廠商以及其他國際上的接口IP廠商還處于領先位置。相關數據顯示,截止到2021年,國產接口IP的自給率還不足10%。
“目前,從技術上來看,國產接口IP廠商確實還處于追趕的位置,不過這種差距已經越來越小。”唐睿指出,“2023年,奎芯科技將會推出一系列性能達到國際領先水平的接口IP產品,包括HBM3以及其他領先的D2D類型的互聯接口IP。”
同時,他還講到,在服務國內客戶方面,實際上也會存在很多本地化的需求,需要根據這些需求結合晶圓廠的工藝特色,提供IP解決方案。奎芯科技很多IP產品,在研發的過程中或者研發之前,就得到了客戶方的問詢,圍繞客戶的芯片架構,有非常清晰的需求。奎芯科技聯合自己的下游客戶成立了多個產業聯盟,通過這些聯盟將不同類型的計算芯片公司聯合在一起,協同發展,圍繞數據中心應用把國產方案搭建好,彌補國內這一塊的空白。
當前,AI大模型訓練所用到的算力集群基本上都是基于英偉達通用算力芯片來打造,在這方面國產通用算力芯片還存在一定的性能差距。唐睿表示,國產高性能計算芯片還是有機會的,AI大模型并不是一個近期出現的新鮮事物,近些年國內AI產業已經在跟進這一趨勢,只是類ChatGPT類型應用背后的大模型參數規模更大。針對這方面的需求,國內芯片產業也早就啟動了這方面的布局,包括奎芯科技所在的接口IP賽道,都在向這個方向努力。不過,從IP研發到芯片設計,再到應用落地,這中間會有一個時間差。實際上,國外的公司也是在用之前的芯片通過互聯在做這方面的硬件支持。
“還需要特別提出的是,AIGC是一個軟硬件結合的應用。軟件方面,算法模型的體量也是一個值得研究去突破的方向。目前,國外開源的AIGC算法里,也并非只有Open AI的GPT算法,通過介紹信息來看,也有一些參數更小的模型能夠實現類ChatGPT應用。我們實際上可以借鑒這些模型,以減少軟件對硬件的需求壓力。”唐睿最后講到。
小結
IP對半導體產業有巨大的撬動力量,在全球范圍內,約60多億美元的IP銷售額,帶動的是5000億美元的全球半導體市場銷售額。對于***而言,短期內實現單芯片性能暴增的難度非常大,不過通過高速接口IP,用算力集群的方式,也能夠逐步進入類ChatGPT的紅利市場。
-
芯片
+關注
關注
454文章
50439瀏覽量
421915 -
IP
+關注
關注
5文章
1661瀏覽量
149336 -
ChatGPT
+關注
關注
29文章
1548瀏覽量
7505
發布評論請先 登錄
相關推薦
使用EMBark進行大規模推薦系統訓練Embedding加速

什么是協議分析儀和訓練器
端到端InfiniBand網絡解決LLM訓練瓶頸

芯品# 高性能計算芯片
開芯院發布全球首個開源大規模片上互聯網絡IP“溫榆河”

高性能計算集群的能耗優化

進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
構建高性能計算芯片
名單公布!【書籍評測活動NO.30】大規模語言模型:從理論到實踐
Xilinx FPGA NVMe主機控制器IP,高性能版本介紹應用
晶晟微納發布N800超大規模AI算力芯片測試探針卡
NVMe Host Controller IP實現高性能存儲解決方案
【國產FPGA+OMAPL138開發板體驗】(原創)6.FPGA連接ChatGPT 4
對話國產EDA和IP廠商,如何攻克大規模數字電路設計挑戰?

態路小課堂丨InfiniBand與以太網:AI時代的網絡差異






 工商網監
工商網監
評論