 ChatGPT,人類認知力延伸的競賽
ChatGPT,人類認知力延伸的競賽
2022年11月30日,OpenAI發布了ChatGPT,在全球范圍內引發了人工智能熱潮。ChatGPT(Chat Generative Pre-trained Transformer),即聊天生成式預訓練轉換器。它通過與人類做文字對話的方式,“與人進行實時對話,即時回答問題;可以做到理解上下文,實現連續對話;可以撰寫和修改計算機代碼;編寫文案、腳本、大綱、策劃;快速生成新聞報道、創作詩歌”等,提供相應的文字回答,且回答的內容“形式上合理”。
創新困境者的突圍
人類從誕生開始,就一直不斷地認識自然,改造自然。但當人類感到自己本體機能受限時,技術就應運而生。技術加強了人類的本體技能,其本質是人類的延伸。體力(手腳、軀干)的延伸促進了機械化的產生,感知力(眼耳鼻舌身)的延伸促進了信息化的產生,從工具到汽車,從PC機到AlphaGo,再到ChatGPT,認知力(意即大腦)的延伸促進了智能化的發展。
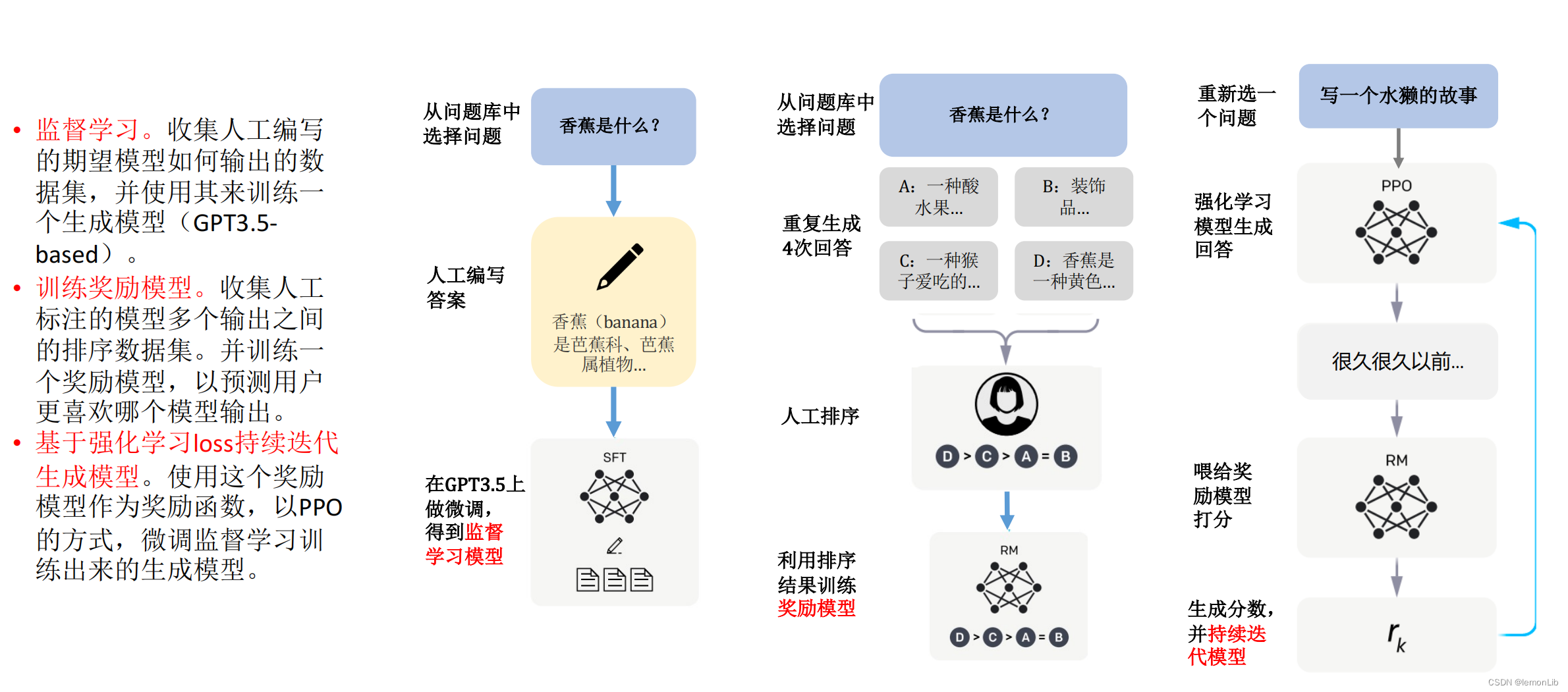
從AI技術層面來看,ChatGPT所能實現的人類意圖,來自于機器學習、深度學習、轉換器和多層感知機模型的多種技術架構及模型積累,最終形成針對人類反饋信息學習的大規模自然語言處理模型。截至2023年1月,ChatGPT的用戶超過1億,成為迄今為止增長最快的消費者應用程序。這是因為人們主觀的認知和表達,以及自然科學和社會科學都要以具有實質性的內容作為基礎和前提,沒有內容就沒有人類文明。ChatGPT的500多位開發科學家突破的就是“內容”這個困境!
突破困境,就會形成質的突變。數據表明,ChatGPT用了5天漲粉到100萬,而蘋果用了74天,推特用了2年,奈飛用了3年半。
理想主義者的堅持
ChatGPT是由OpenAI團隊研發創造,OpenAI是由SpaceX創業者埃隆·馬斯克、美國創業孵化器Y Combinator總裁阿爾特曼、全球在線支付平臺PayPal聯合創始人彼得·蒂爾等人于2015年在舊金山創立。OpenAI的創立目標是與其他機構合作進行AI的相關研究,并開放研究成果以促進AI技術的發展。
ChatGPT經歷多類技術路線演化,逐步成熟與完善。其GPT(Generative Pre-trained Transformer,生成式預訓練轉換器)模型是一種自然語言處理模型,使用轉換器來預測下一個單詞的概率分布,通過訓練在大型文本語料庫上學習到的語言模式來生成自然語言文本。
從1950年AI始祖圖靈提出基于規則的少量數據處理,給出判斷機器是否具有“智能”的方法——圖靈測試開始,AI技術開始了漫長的探索。直到30年后,機器學習出現,才以可根據一定范圍的數據進行參數分類,但受限于技術水平,AI僅限于小范圍實驗。到了20世紀90年代,基于機器學習延伸出來的一個新的領域——深度學習出現了,它是以受人大腦結構為啟發的神經網絡算法為起源加之模型結構深度的增加發展,并伴隨大數據和計算能力的提高而產生的一系列新的算法。進入21世紀,獲得突破的卷積神經網絡(CNN)、循環神經網絡(RNN)及其后來發展的生成式對抗網絡(GAN)開始模仿人腦進行大量數據的標記和訓練,分別在計算機視覺和自然語言處理領域得到廣泛使用,帶動了人工智能領域的蓬勃發展。
深度學習的發展讓我們第一次看到并接近人工智能的終極目標,AI從實驗性向實用性轉變,但缺陷是受限于算法瓶頸,無法直接進行內容生成。
2017年,Ashish Vaswani et.al的論文《Attention Is All You Need》中,提出了一種新的簡單架構——轉換器(Transformer),徹底顛覆了過去的理念,沒用到卷積神經網絡和循環神經網絡,它完全基于注意力機制,不用重復和卷積,因而這些模型在質量上更優,同時更易于并行化,并且需要的訓練時間明顯更少。該論文被評為自然語言處理領域的年度最佳論文。
Transformer出現以后,迅速躋身主流模型架構基礎,使深度學習模型參數達到了上億的規模。AI技術的發展也呈現出模型之爭,重大研究方向就是自然語言處理任務。隨之,自然語言處理任務就轉入了兩大流派的競賽,按轉換器架構可分OpenAI的自回歸系列(例如GPT-3,偏好生成性任務);谷歌的雙向Transformer+Mask的自編碼系列(例如BERT,偏好自然語言理解)。
從2018年開始,谷歌率先提出了3億參數模型BERT,陸續又推出了ELNet、RoBERTa、T5等,到了2021年則推出高達1.6萬億的參數量的Switch Transformer模型。2023年2月4日,谷歌注資3億美元投資Anthropic,Anthropic 開發了一款名為Claude的智能聊天機器人,據稱可與ChatGPT相媲美(仍未發布)。
而OpenAI也在兩年左右的時間,先后推出了GPT- 1到GPT- 3,再到ChatGPT,參數實現了從億級到上千億級的突破,并能夠實現作詩、聊天、生成代碼等功能。作為OpenAI最大投資方的微軟,開始利用ChatGPT提高產品競爭力,將ChatGPT整合進Bing搜索引擎、Office全家桶、Azure云服務、Teams程序等產品中。
此外包括微軟、Meta、英偉達、華為、百度、阿里等巨頭在內的全球領先企業紛紛參與其中,預訓練大模型已經成為整個AI領域的競爭焦點。
混沌和近臨界邊緣者的沖浪
2022年,在ChatGPT溫和聚變式的科技革命中,人工智能生成內容后來居上,以超出人們預期的速度成為科技歷史上的重大事件,迅速催生了全新的科技生態。
在國內,2021年成為中國AI大模型的爆發年。眾多公司和研究機構正在積極開展對大模型的研發。代表性的有華為云聯合循環智能發布的基于昇思MindSpore打造的1000億參數盤古NLP模型、聯合北京大學發布2000億參數的盤古α模型;百度推出基于PaddlePaddle 開發的2600億參數ERNIE3.0 Titan模型;而阿里達摩院聯合清華大學發布的中文多模態模型M6參數達到10萬億,將大模型參數直接提升了一個量級。
2022年,基于清華大學、阿里達摩院等研究成果以及超算基礎實現的“腦級人工智能模型”——八卦爐(BAGUALU)完成建立,其模型參數模型突破了174萬億個,完全可以與人腦中的突觸數量相媲美。
目前,大模型參數規模最高可達百萬億級別,數據集達到TB量級,且面向多模態場景(同時支持文字、圖像、聲音、視頻、觸覺等兩種及以上形態)的大模型已成為趨勢。大模型生態已初具規模。
值得期待的是,百度宣布將在2023年3月的某個時候推出一項中文名為“文心一言”或英文名為“ERNIE Bot”的ChatGPT式服務。
新一輪認知力延伸的競賽是否又開始了呢?
《Attention Is All You Need》幾位作者的選擇或許有一定的代表性:時隔5年,8位作者僅有一位還留在谷歌。其中6人選擇創業或加入創業公司,還有一位去了OpenAI。
2022年4月26日,一家名為Adept的公司官宣成立,以Ashish Vaswani為首的共同創始人有9位,Ashish Vaswani在南加州大學拿到博士學位,師從華人學者蔣偉和黃亮,主要研究現代深度學習在語言建模中的早期應用。2016年,他加入了谷歌大腦并領導了Transformer的研究。
Adept是一家致力于用AI來增強人類能力并最終實現通用智能的公司。在闡述公司創立初衷時,Ashish Vaswani寫道:“在Google,我們訓練出了越來越大的Transformer,夢想著有朝一日構建一個通用模型來支持所有ML用例。但是,這其中有一個明顯的局限:用文本訓練出的模型可以寫出很棒的文章,但它們無法在數字世界中采取行動。你不能要求GPT-3給你訂機票,給供應商開支票,或者進行科學實驗”。
因此,他們打算創建一個通用系統,“你可以把它想象成你電腦里的一個overlay,它和你一起工作,使用和你一樣的工具。使用Adept,你能專注于你真正喜歡的工作,并要求模型承擔其他任務”。
也許,對于國內大多數在混沌和近臨界邊緣上沖浪的人來說,都應該好好思索一個問題:“是沿著Transformer和ChatGPT競賽,還是換一個類似Adept的新賽道呢?”
審核編輯 :李倩
-
人工智能
+關注
關注
1791文章
46868瀏覽量
237592 -
ChatGPT
+關注
關注
29文章
1548瀏覽量
7495
原文標題:ChatGPT,人類認知力延伸的競賽
文章出處:【微信號:AI智勝未來,微信公眾號:AI智勝未來】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
具身智能與人類認知能力的關系
ChatGPT 與人工智能的未來發展
怎樣搭建基于 ChatGPT 的聊天系統
ChatGPT 適合哪些行業
數據智能系列講座第3期—交流式學習:神經網絡的精細與或邏輯與人類認知的對齊

偉創力蘇州斬獲客戶施耐德電氣最佳實踐競賽雙金獎
大模型LLM與ChatGPT的技術原理
用launch pad燒錄chatgpt_demo項目會有api key報錯的原因?
使用espbox lite進行chatgpt_demo的燒錄報錯是什么原因?
OpenAI 深夜拋出王炸 “ChatGPT- 4o”, “她” 來了
在FPGA設計中是否可以應用ChatGPT生成想要的程序呢
亞馬遜加碼投資Anthropic,AI競賽再掀波瀾
【國產FPGA+OMAPL138開發板體驗】(原創)6.FPGA連接ChatGPT 4
芯科技,解密ChatGPT暢聊之算力芯片
ChatGPT原理 ChatGPT模型訓練 chatgpt注冊流程相關簡介





 工商網監
工商網監
評論