 vivo AI計算平臺的K8s分級配額管理實踐
vivo AI計算平臺的K8s分級配額管理實踐
2018 年底,vivo AI 研究院為了解決統一高性能訓練環境、大規模分布式訓練、計算資源的高效利用調度等痛點,著手建設 AI 計算平臺。經過四年多的持續迭代,平臺建設和落地取得了很大進展,成為 vivo AI 領域的核心基礎平臺。平臺從當初服務深度學習訓練為主,到現在演進成包含 VTraining、VServing、VContainer 三大模塊,對外提供模型訓練、模型推理和容器化能力的基礎設施。平臺的容器集群有數千個節點,擁有超過數百 PFLOPS 的 GPU 算力。集群里同時運行著數千個訓練任務和數百個在線服務。本文是 vivo AI 計算平臺實戰 系列文章之一,主要分享了平臺在資源配額管理方面的實踐。
背 景
K8s 提供了原生的 ResourceQuota 資源配額管理功能,基于命名空間進行配額管理,簡單易用。但是隨著平臺資源使用場景變得越來越復雜,例如多層級業務組織配額、針對具體 CPU 核和 GPU 卡的型號配額、資源使用時長配額等,ResourceQuota 變得難以應對,平臺面臨業務資源爭搶、配額管理成本增加、定位問題效率變低等問題。
本文主要介紹平臺在 K8s 集群資源配額管理過程中遇到的問題,以及如何實現符合需求的配額管理組件:BizGroupResourceQuota —— 業務組資源配額(簡稱 bizrq),用于支撐平臺對復雜資源使用場景的配額管控。
ResourceQuota 資源配額管理遇到的問題
在使用 ResourceQuota 做資源配額管理時,有以下 4 個問題比較突出:
1、無法滿足有層級的業務組織架構的資源配額管理
ResourceQuota 不能很好地應用于樹狀的業務組織架構場景,因為命名空間是扁平的,在實際場景中,我們希望將資源配額由父業務組到子業務組進行逐級下發分配。
2、以 pod 對象的粒度限額可能導致只有部分 pod 創建成功
ResourceQuota 是以 pod 對象的粒度來進行資源限額的,正常情況下在線服務或離線任務的部署,例如 deployment、argo rollout、tfjob 等,都需要批量創建 pod,可能會造成一部分 pod 由于額度不足而創建失敗的情形,導致部署無法完成甚至失敗,我們希望要么全部 pod 都創建成功,要么直接拒絕部署并提示資源額度不足,提升部署體驗。
3、無法針對具體 CPU 核和 GPU 卡的型號進行配額管理
ResourceQuota 管理配額的資源粒度太粗,無法針對具體 CPU 核和 GPU 卡的型號進行配額管理,在實際場景中,不同的 CPU、GPU 型號的性能、成本差異很大,需要分開進行限額。例如我們會將 CPU 機器劃分為 A1、A2、A3、A4 等機型,GPU 機器也有 T4、V100、A30、A100 等機型,他們的性能和成本都是有差異的。
4、無法限制資源使用時長
ResourceQuota 僅能限制當前時刻資源的已使用額度不能超過配額,但是并不能限制對資源的使用時長。在某些離線的深度模型訓練場景,業務對 CPU、GPU 資源爭搶比較激烈,某些業務組希望能按 CPU 核時或 GPU 卡時的方式,給團隊成員發放資源配額,比如每人每周發放 1000 GPU 卡時,表示可以用 10 張卡跑 100 小時,也可用 20 張卡跑 50 小時,以此類推。
BizGroupResourceQuota 分級配額管理方案
針對 ResourceQuota 配額管理所面臨的 4 個問題,我們設計了 BizGroupResourceQuota 配額管理 —— 業務組資源配額管理方案,后文簡稱為 bizrq。接下來,我們介紹一下 bizrq 方案。
我們通過 K8s crd(Custom Resource Define)來自定義 bizrq 資源對象(如下圖 bizrq 配額示例),從而定義 bizrq 的實現方案:
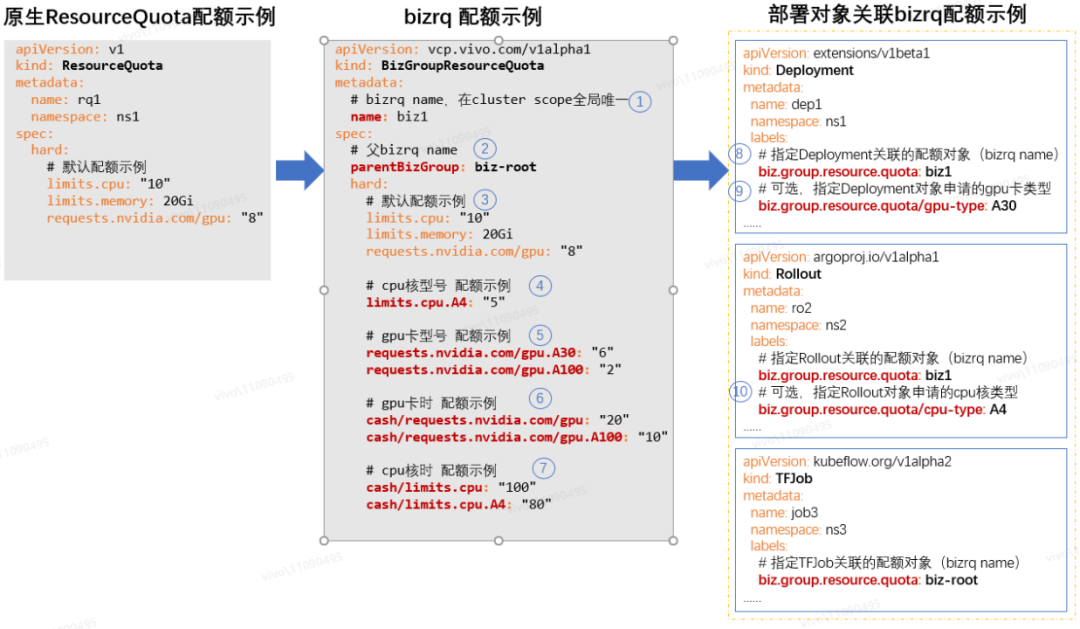
如上圖配額示例所示,下面分別解釋一下 bizrq 配額方案的特點:
① bizrq name
bizrq name 在 cluster scope 全局唯一,bizrq 配額對象是集群范圍的,不跟命名空間相關聯。在實際業務場景中,bizrq name 可以跟業務組 ID 對應起來,便于實現基于樹狀的業務組織架構的配額管理。
②父 bizrq name
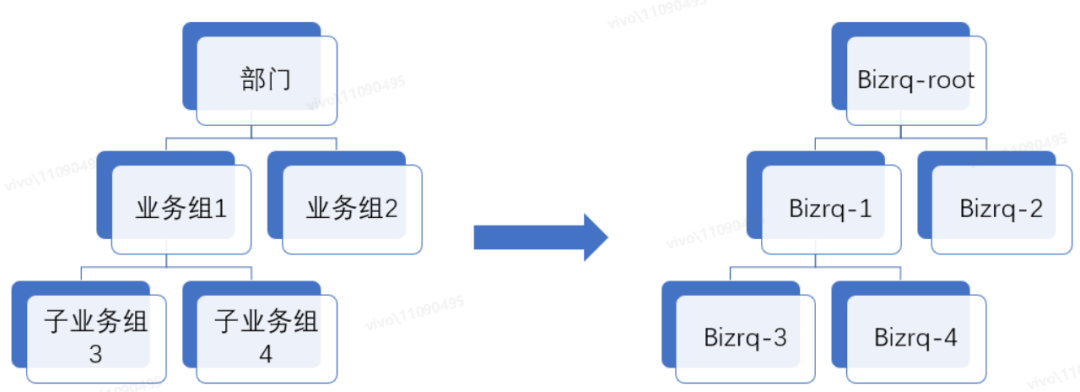
父 bizrq name 表示當前 bizrq 的父級業務組的 bizrq 配額對象名稱,假如父 bizrq name 值設置了空字符串"",則表示當前 bizrq 是 root 節點。當創建非 root 的 bizrq 配額對象時,子 bizrq 的資源配額要從父 bizrq 的剩余額度中申請,并需要滿足相關約束條件才能創建成功,后面也會介紹實現原理。這樣就可以按常見的業務組織架構來管理配額,構成一顆“bizrq 樹”:
③默認配額示例
默認配額示例跟 ResourceQuota 的資源額度配置和限額效果是一致的,bizrq 借鑒了 ResourceQuota 的實現,保持了一致的配置風格和使用體驗。
④ CPU核型號配額示例
bizrq 支持將 CPU 核配額限制到具體型號,具體型號資源的已使用額度,也會累加到前綴相同的通用資源配額的已使用額度里,它們是可以結合使用的,如果都配置了則限額會同時生效。這樣即保留了原生 ResourceQuota 的限額功能,又新增了不同型號資源的限額。
舉例說明,比如將 limits.cpu 配額設置為 10 核,limits.cpu.A4 配額設置為 4 核,它們一開始已使用額度都是 0 核,當我們的部署對象申請了 4 核的 A4 后,那么 limits.cpu 和 limits.cpu.A4 的已使用額度都會累加上這 4 核,因為 bizrq 會判斷 limits.cpu 是 limits.cpu.A4 的前綴資源,屬于通用資源類型,所以要一并計算。另外,此時業務組不能再申請 A4 型號的 cpu 資源了,因為 limits.cpu.A4 的剩余額度為 0,不過 limits.cpu 剩余額度還有 6 核,所以還可以申請非 A4 型號的 CPU 資源。
那么我們能否將 limits.cpu 配額設置為 10 核,將 limits.cpu.A4 配額設置為 100 核呢(limits.cpu < limits.cpu.A4)?是可以這樣配置的,但是將 limits.cpu.A4 配置為 100 核沒有意義,因為申請 A4 型號的 CPU 資源時,bizrq 也會分析前綴相同的 limits.cpu 的剩余額度是否足夠,如果額度不足那么任何型號的 CPU 資源都不能申請成功。
⑤GPU 卡型號配額示例
bizrq 支持將 GPU 卡配額限制到具體型號,具體型號資源的已使用額度,也會累加到前綴相同的通用資源的已使用額度里,它們是可以結合使用的,跟上面介紹的 CPU 核型號的限額行為也是一致的。
⑥GPU 卡時配額示例,⑦CPU 核時配額示例
bizrq 支持虛擬 cash 機制,可以給業務組分配 CPU 核時、GPU 卡時等“虛擬的貨幣”,比如給某個業務組分配 100CPU 核時:“cash/limits.cpu: 100”,(注意前綴 “cash/” 的表示)表示這個業務組的業務可以用 1 個 CPU 核跑 100 小時,也可以用 2 個 CPU 核跑 50 小時,還可以用 100 個 CPU 核跑 1 小時,GPU 卡時的定義可以類比。
⑧指定 Deployment 關聯的配額對象(bizrq name)
bizrq 限額不以 pod 對象為粒度進行限額,而是以 deployment、argo rollout、tfjob 等上層部署對象的粒度來限額,需要通過部署對象 label “biz.group.resource.quota”來關聯 bizrq 配額對象(注意不是通過命名空間進行關聯,因為 bizrq 是 cluster scope 的)。
通過攔截上層部署對象的創建、更新操作進行資源額度的校驗(通過 validating webhook 攔截,后文會介紹實現原理),當關聯 bizrq 的剩余資源額度充足時,允許上層對象的創建;當剩余資源額度不足時,拒絕上層對象的創建,從而防止只有部分 pod 創建成功的情形。
⑨⑩指定部署對象關聯的配額對象(bizrq name)
為了達到具體的 CPU 核型號或 GPU 卡型號的限額目的,也要給部署對象打上聲明具體的資源型號的 label,例如:biz.group.resource.quota/cpu-type: "A4",表示部署對象申請的是 A4 型號的 CPU 核;或 GPU 卡型號的 label,例如:biz.group.resource.quota/gpu-type: "A30",表示部署對象申請的是 A30 型號的 GPU 卡。
備注:bizrq 同樣支持具體的內存類型的限額,使用方式與 CPU 核、GPU 卡類型的限額類似,比如可以設置 limits.memory.A4 的額度,然后給部署對象打上聲明具體的資源型號的 label:biz.group.resource.quota/memory-type: "A4" 即可。
配額機制實現原理
bizrq 方案在 ResourceQuota 所支持的基礎資源配額的基礎上,增加了(1)父子關系的表示,(2)CPU 核和 GPU 卡型號的限額,(3)核時、卡時的限額,(4)針對上層的部署資源對象進行額度校驗,而不是針對單個 pod;同時 bizrq 對象的配置風格和 ResourceQuota 對象的配置風格是一樣的,易于配置和理解。所以 bizrq 分級配額的實現思路應該也是可以借鑒 ResourceQuota 的,在分析 bizrq 實現前,我們先分析下 ResourceQuota 的實現原理,以便借鑒官方優秀的實現思路。
原生 ResourceQuota 實現 整體架構
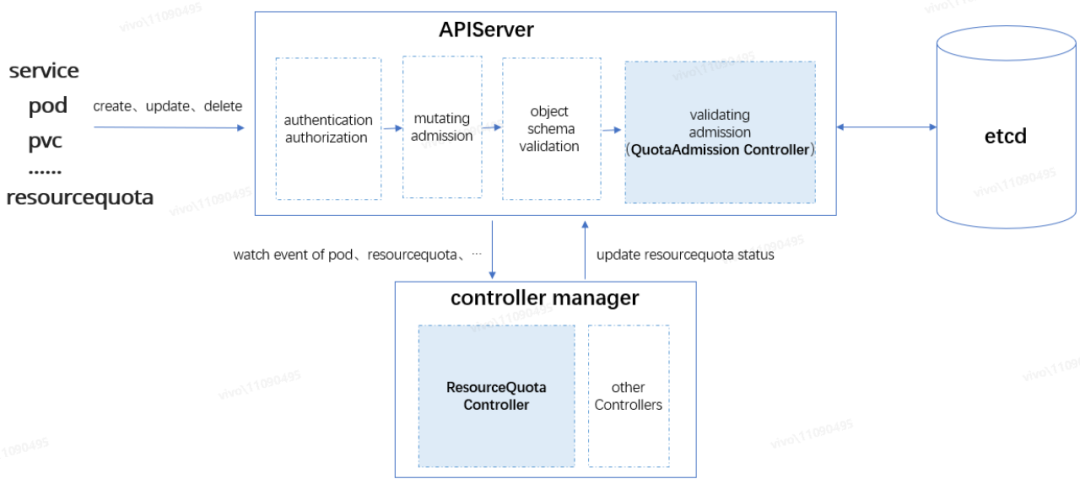
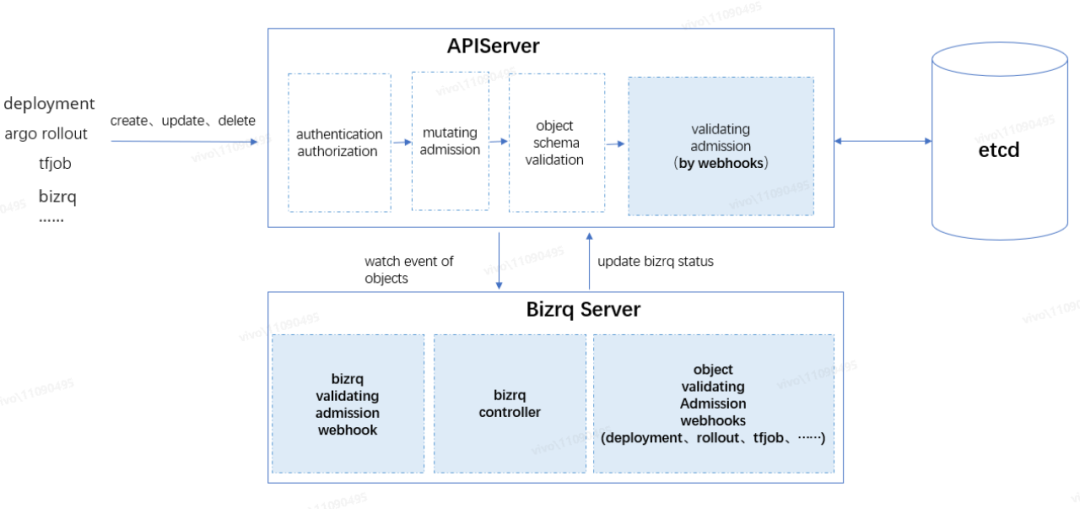
如上圖所示,APIServer 接收到資源對象請求后,由訪問控制鏈路中的處理器按順序進行處理,請求順利通過訪問控制鏈路的處理后,資源對象的變更才允許被持久化到 etcd,它們依次是認證(authentication)→鑒權(authorization)→變更準入控制(mutating admission)→對象 Schema 校驗(object schema validation)→驗證準入控制(validating admission)→etcd 持久化,我們需要重點關注“準入控制”環節:
? 變更準入控制(mutating admission):對請求的資源對象進行變更。例如內置的 ServiceAccount admission controller,會將 pod 的默認 ServiceAccount 設為 default,并為每個容器添加 volumeMounts,掛載至 /var/run/secrets/kubernetes.io/serviceaccount,以便在 pod 內部可以讀取到身份信息來訪問當前集群的 apiserver。變更準入控制是可擴展的,我們可以通過配置 mutating admission webhooks 將自定義的邏輯加入到變更準入控制鏈路中;
? 驗證準入控制(validating admission):對請求的資源對象進行各種驗證。此環節不會去變更資源對象,而是做一些邏輯校驗,例如接下來要分析的 QuotaAdmission Controller,會攔截 pod 的創建請求,計算 pod 里容器申請的資源增量是否會導致超額。驗證準入控制也是可擴展的,我們可以通過配置 validating admission webhooks 將自定義的邏輯加入到驗證準入控制鏈路中。
如上圖所示,ResourceQuota 限額機制主要由兩個組件組成:
? ResourceQuota Controller:ResourceQuota Controller 是內置在 controller manager 眾多 Controllers 中的一個,主要負責監聽資源對象,如 pod、service 等變更事件,也包括 ResourceQuota 對象的變更事件,以便及時刷新關聯的 ResourceQuota 的 status 狀態;
? QuotaAdmission Controller:QuotaAdmission 是內置在 apiserver 請求訪問控制鏈路驗證準入控制環節的控制器,QuotaAdmission 主要負責攔截資源對象的創建、更新請求,對關聯 ResourceQuota 的額度進行校驗。
下面以 Pod 對象的限額為例,分析 ResourceQuota 限額機制原理。其他資源,比如 service、pvc 等對象限額的實現思路基本一致,只不過不同對象有不同的資源計算邏輯實現(Evaluator)。
ResourceQuota Controller
當集群的 controller manager 進程啟動后,選主成功的那個 controller manager leader 就會將包括 ResourceQuota Controller 在內的所有內置的 Controller 跑起來,ResourceQuota Controller 會以生產者 - 消費者的模式,不斷刷新集群命名空間的 ResourceQuota 對象的資源使用狀態:

作為任務生產者,為了及時把需要刷新狀態的 ResourceQuota 放到任務隊列,ResourceQuota Controller 主要做了以下 3 件事情:
· 監聽 pod 對象的事件,當監聽到 pod 由占用資源狀態變更為不占資源狀態時,比如 status 由 terminating 變為 Failed、Succeeded 狀態,或者 pod 被刪除時,會將 pod 所在命名空間下關聯的所有 ResourceQuota 放入任務隊列;
·監聽 ResourceQuota 對象的創建、spec.Hard 更新(注意會忽略 status 更新事件,主要是為了將 spec.Hard 刷新到 status.Hard)、delete 等事件,將對應的 ResourceQuota 放入任務隊列;
·定時(默認 5m,可配置)把集群所有的 ResourceQuota 放入任務隊列,確保 ResourceQuota 的狀態最終是跟命名空間實際資源使用情況一致的,不會因為各種異常情況而出現長期不一致的狀態。
作為任務消費者,ResourceQuota Controller 會為任務隊列啟動若干 worker 協程(默認 5 個,可配置),不斷從任務隊列取出 ResourceQuota,計算 ResourceQuota 所在命名空間所有 pod 的容器配置的資源量來刷新 ResourceQuota 的狀態信息。
QuotaAdmission Controller
對于 pod 的限額,QuotaAdmission 只會攔截 Pod create 操作,不會攔截 update 操作,因為當部署對象的 pod 容器資源申請被變更后,原 pod 是會被刪除并且創建新 pod 的,pod 的刪除操作也不用攔截,因為刪除操作肯定不會導致超額。
當 QuotaAdmission 攔截到 Pod 的創建操作后,會找出對應命名空間所有相關聯的 ResourceQuota,并分析創建 pod 會不會造成資源使用超額,只要有一個 ResourceQuota 會超額,那么就拒絕創建操作。如果所有的 ResourceQuota 都不會超額,那么先嘗試更新 ResourceQuota 狀態,即是將此個 pod 的容器配置的資源量累加到 ResourceQuota status.Used 里,更新成功后,放行此次 pod 操作。
問題分析
總的來說,ResourceQuota Controller 負責監聽各類對象的變更事件,以便能及時刷新對應的 ResourceQuota status 狀態,而 QuotaAdmission 則負責攔截對象操作,做資源額度的校驗。有幾個比較關鍵的問題我們需要分析一下,這幾個問題也是 bizrq 實現的關鍵點:
1、ResourceQuota status 的并發安全問題
ResourceQuota Controller 會不斷刷新 ResourceQuota status 里各類資源使用量,所有 apiserver 進程的 QuotaAdmission 也會根據 ResourceQuota status 校驗是否超額,并將校驗通過的 pod 資源增量累加到 ResourceQuota status.Used,所以 status 的更新是非常頻繁的,這就會導致并發安全問題:
假設某個業務組 CPU 配額有 10 核,已使用量為 1 核,業務 A 和業務 B 同時請求申請 5 核,此時對剩余額度的校驗都是足夠的(剩余 CPU 核數為 10-1=9),兩個請求都會將 CPU 已使用量更新為 1+5=6 核,并且都申請成功,這將導致限額失效,因為實際的資源申請已經超額了(1+5+5=11 核)。
解決辦法通常有以下 3 種方式:
·方式 1:將所有對 status 的訪問邏輯打包成任務放入隊列,并通過單點保證全局按順序進行處理;
·方式 2:將所有對 status 的訪問邏輯加鎖,獲取到鎖才可以進行處理,保證任何時刻都不會有并發的訪問;
·方式 3:通過樂觀鎖來確保對 status 的訪問是安全的。
ResourceQuota 采用的是第三種方式,方式 1、2 都要引入額外的輔助手段,比如分布式隊列、分布式鎖,并且同一時刻只能處理一個請求,效率比較低下,容易造成處理延時,此外還要考慮 ResourceQuota Controller 跟 QuotaAdmission Controller 的協同(都會更新 ResourceQuota status.Used),在限額場景實現起來不是那么簡潔高效,而方式 3 可以直接基于 K8s 的樂觀鎖來達到目的,是最簡潔高效的方式。
K8s 樂觀鎖實現原理
K8s 樂觀鎖的實現,有兩個前提:
·一是 K8s 資源對象的 resourceVersion 是基于 etcd 的 revision,revision 的值是全局單調遞增的,對任何 key 的修改都會使其自增;
·二是 apiserver 需要通過 etcd 的事務 API,即 clientv3.KV.Txn(ctx).If(cmp1, cmp2, ......).Then(op1, op2, ......).Else(op1, op2, ......),來實現事務性的比較更新操作。
具體流程示例如下:

·第 1 步:client 端從 apiserver 查詢出對象 obj 的值 d0,對應的 resourceVersion 為 v0;
·第 2 步:client 端本地處理業務邏輯后,調用 apiserver 更新接口,嘗試將對象 obj 的值 d0 更新為 dx;
·第 3 步:apiserver 接受到 client 端請求后,通過 etcd 的 if...then...else 事務接口,判斷在 etcd 里對象 obj 的 resourceVersion 值是否還是 v0,如果還是 v0,表示對象 obj 沒被修改過,則將對象 obj 的值更新為 dx,并為對象 obj 生成最新的 resourceVersion 值 v1;如果 etcd 發現對象 obj 的 resourceVersion 值已經不是 v0,那么表示對象 obj 已經被修改過,此時 apiserver 將返回更新失敗;
·第 4 步:對于 client 端,apiserver 返回更新成功時,對象 obj 已經被成功更新,可以繼續處理別的業務邏輯;如果 apiserver 返回更新失敗,那么可以選擇重試,即重復 1~4 步的操作,直到對象 obj 被成功。
apiserver 的更新操作實現函數:
https://github.com/kubernetes/kubernetes/blob/v1.20.5/staging/src/k8s.io/apiserver/pkg/storage/etcd3/store.go

相對于方式 2 的鎖(悲觀鎖),樂觀鎖不用去鎖整個請求操作,所有請求可以并行處理,更新數據的操作可以同時進行,但是只有一個請求能更新成功,所以一般會對失敗的操作進行重試,比如 QuotaAdmission 攔截的用戶請求,加了重試機制,重試多次不成功才返回失敗,在并發量不是非常大,或者讀多寫少的場景都可以大大提升并發處理效率。
QuotaAdmission 中樂觀鎖重試機制實現函數是 checkQuotas,感興趣可自行閱讀源碼:
https://github.com/kubernetes/kubernetes/blob/v1.20.5/staging/src/k8s.io/apiserver/pkg/admission/plugin/resourcequota/controller.go

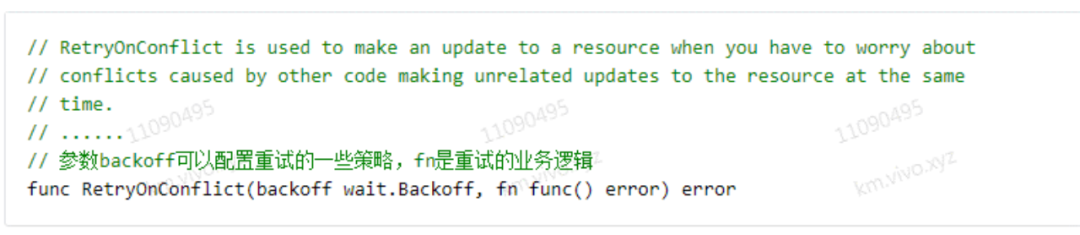
另外,更新沖突在所難免,客戶端可以借助 client-go 的 util 函數 RetryOnConflict 來實現失敗重試:
https://github.com/kubernetes/client-go/blob/kubernetes-1.20.5/util/retry/util.go
2、超額問題
問題:QuotaAdmission 校驗 pod 創建是否超額時,查詢出來的 ResourceQuota 的 status.Used 狀態能否反映命名空間下資源最新實際使用量,會不會造成超額情形?
問題分析:
由于 ResourceQuota Controller 和 QuotaAdmission 都會不斷刷新 ResourceQuota 的 status.Used 狀態,并且 QuotaAdmission 基本是通過 informer cache 來獲取 ResourceQuota 的,informer 監聽會有延遲,所以校驗額度時查詢的 ResourceQuota status 狀態可能并不是準確反映命名空間下資源最新實際使用量,概括起來有以下 3 種不一致的情況:
·(1) informer 事件監聽延遲,查詢到的可能不是 etcd 最新的 ResourceQuota;
·(2)即使查詢到的是 etcd 最新的 ResourceQuota,在額度校驗過程中,ResourceQuota 也有可能先被別的請求或被 ResourceQuota controller 修改掉,那么 ResourceQuota 數據也是“過期”的;
·(3)即使查詢到的是 etcd 最新的 ResourceQuota,并且在額度校驗過程中,ResourceQuota 數據沒有被修改,這個查詢出來的 etcd 最新的 ResourceQuota,也有可能不是最新的數據,因為 ResourceQuota controller 刷新 ResourceQuota 可能不是那么及時。
對于(1)、(2)這兩種情形,由于 QuotaAdmission 基于 K8s 樂觀鎖做 ResourceQuota 資源額度的校驗及狀態更新,如果 ResourceQuota 不是 etcd 最新的,那么更新 ResourceQuota 狀態時會失敗,QuotaAdmission 將進行重試,這樣就能保證只有用最新的 ResourceQuota 來做額度校驗,資源申請請求才能被通過;
對于(3)情形,ResourceQuota controller 刷新 ResourceQuota 可能不及時,但也不會造成超額,因為資源使用量的增加(例如 pod 創建操作)都是要通過 QuotaAdmission 攔截校驗并通過樂觀鎖機制將資源增量更新到 ResourceQuota,ResourceQuota controller 刷新 ResourceQuota 不及時,只會導致當前 etcd 最新 ResourceQuota 的剩余額度比實際“偏小”(例如 pod 由 terminating 變為 Failed、Succeeded 狀態,或者 pod 被刪除等情形),所以符合我們限額的目的。
當然,如果手動把配額調小,那可能會人為造成超額現象,比如原先 CPU 配額 10 核,已使用 9 核,此時手動把配額改成 8 核,那么 QuotaAdmission 對于之后的 pod 創建的額度校驗肯定因為已經超額,不會通過操作了,不過這個是預期可理解的,在實際業務場景也有用處。
3、全局刷新問題
問題:為什么要定時全量刷新集群所有的 ResourceQuota 狀態?
問題分析:
·定時全量刷新可以防止某些異常導致的 ResourceQuota status 跟實際的資源使用狀態不一致的情形,保證狀態回歸一致性。例如 QuotaAdmission 更新了 ResourceQuota 后(額度校驗通過后),實際的資源操作由于遇到異常而沒有成功的情形(如 pod 創建操作在后續環節失敗的場景);
·不過由于 ResourceQuota Controller 會不斷更新 ResourceQuota,在額度校驗通過后到實際資源操作被持久化前這段時間內(這段時間很短),ResourceQuota 可能會被 ResourceQuota Controller 更新回舊值,如果后續有新的資源申請操作,就可能造成超額情形,不過出現這個問題的幾率應該很小,通過業務層補償處理(比如超額告警、回收資源)即可。
關于 ResourceQuota Controller 和 QuotaAdmission 的代碼細節,感興趣可以自行閱讀:
https://github.com/kubernetes/kubernetes/blob/v1.20.5/cmd/kube-controller-manager/app/core.go

https://github.com/kubernetes/kubernetes/blob/v1.20.5/staging/src/k8s.io/apiserver/pkg/admission/plugin/resourcequota/admission.go

bizrq 實現
在分析了 ResourceQuota 的實現原理后,我們再看看如何實現 bizrq 的限額方案。
整體架構
參考 ResourceQuota 的實現,我們可以將 bizrq 按功能職責劃分成 3 個模塊:
bizrq controller
負責監聽相關事件,及時刷新 bizrq 狀態以及定時(默認 5m)刷新整個集群的 bizrq 狀態。
·監聽 bizrq 的創建、更新(Spec.Hard 變更),及時刷新 bizrq status;
·監聽部署對象,例如 deployment、argo rollout、tfjob 等對象的更新(這里僅監聽 biz.group.resource.quota label 配置的更新)、刪除事件,及時刷新關聯的 bizrq status。
bizrq validating admission webhook(server)
基于 apiserver 的驗證準入控制 webhook,負責攔截 bizrq 的增刪改事件,做 bizrq 本身以及 bizrq parent 相關的約束性校驗,從而實現分級配額。
·攔截創建事件:對 bizrq name 做重名校驗,確保 cluster scope 全局唯一;然后進行父 bizrq 校驗;
·攔截更新事件:確保父 parentBizGroup 字段不能變更,不能更改父 bizrq;然后進行父 bizrq 校驗;
·攔截刪除事件:確保只能刪除葉子節點的 bizrq,防止不小心將一棵樹上所有的 bizrq 刪除;然后進行父 bizrq 校驗;
·父 bizrq 校驗:校驗非 root bizrq(Spec.ParentBizGroup 字段不為 "")的父 bizrq 的相關約束條件是否滿足:
父 bizrq 必須已存在;
子 bizrq 必須包含父 bizrq 配額配置的所有資源類型名稱 key(Spec.Hard 的 key 集合),父 bizrq 的配額配置是子 bizrq 配額配置的子集,例如父 bizrq 包含 limits.cpu.A4,則創建子 bizrq 時也必須包含 limits.cpu.A4;
父 bizrq 的剩余額度必須足夠,子 bizrq 申請的額度是從父 bizrq 里扣取的額度。如果父 bizrq 不會超額,則先更新父 bizrq 的 status,更新成功才表示從父 bizrq 申請到了額度。
object validating admission webhooks(server)
基于 apiserver 的驗證準入控制 webhook,負責攔截需要限額的資源對象的創建和更新事件,例如 deployment、argo rollout、tfjob 等對象的攔截,做額度校驗,從而實現部署對象的限額校驗,而不是 pod 對象粒度的校驗。
攔截到部署對象的請求時,從部署對象提取出以下信息,就能計算各類資源的增量:
·資源型號(如果有指定具體型號的話),從 label biz.group.resource.quota/cpu-type 或 biz.group.resource.quota/gpu-type 提取;
·部署對象的副本數(obj.Spec.Replicas);
·PodTemplateSpec,用來計算容器配置的資源量。
然后再判斷部署對象的請求是否會導致關聯的 bizrq 超額(從 label biz.group.resource.quota 提取關聯的 bizrq name),如果 bizrq 不會超額,那么先嘗試更新 bizrq 資源使用狀態,更新成功后,放行此次請求操作。
關于核時、卡時的限額實現
controller 會不斷刷新 bizrq 的 status,bizrq 的 status 跟 ResourceQuota 的 status 有點不一樣,bizrq 的 status 添加了一些輔助信息,用來計算核時、卡時的使用狀態(cash 額度使用狀態):
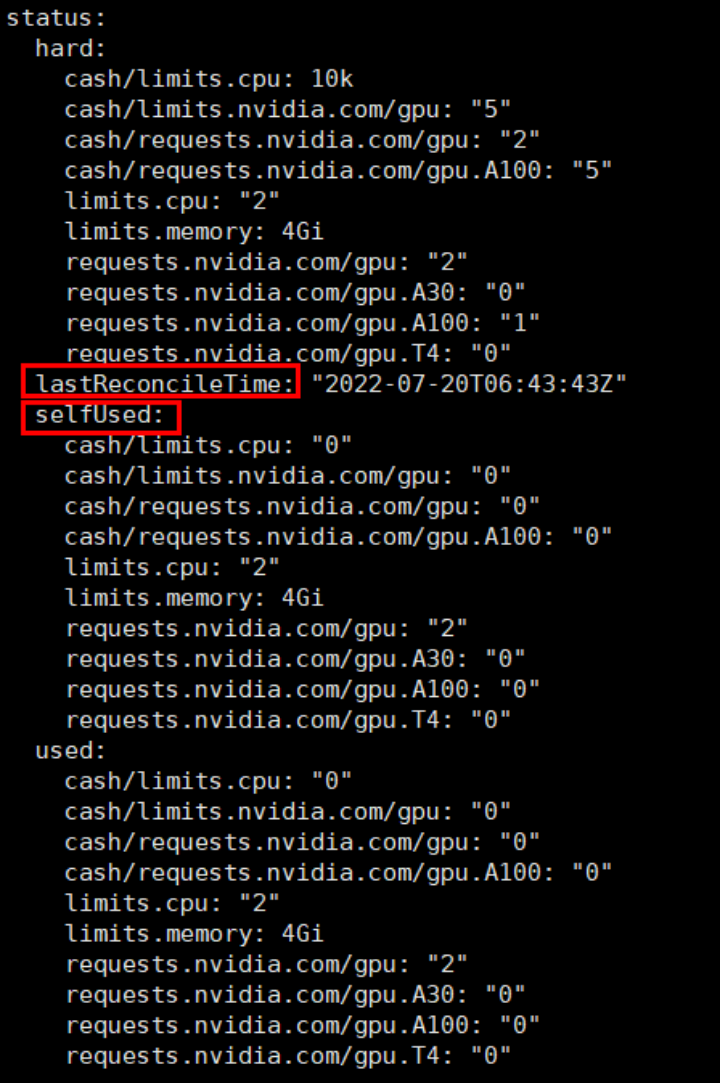
對比 ResourceQuota 的 status:
·bizrq status 包含了 ResourceQuota 也有的 hard、used 字段;
·增加 selfUsed 字段來記錄 bizrq 本身(業務組本身)已使用資源量,selfUsed 不包含子 bizrq 所申請的配額,并滿足關系:selfUsed + 子 bizrq 申請的配額 = used;
·增加 lastReconcileTime 字段來記錄 controller 最后一次刷新 bizrq status 的時間,因為計算核時、卡時是要基于資源量乘于使用時間來計算的,而且是要基于 selfUsed 累加的。計算 cash 時,controller 會將部署對象包含的所有 pod 查詢出來,然后結合 lastReconcileTime、pod 開始占用資源的時間點(成功調度到節點上)、pod 釋放資源的時間點(比如 Succeeded、Failed),再結合 pod 容器配置的資源量,從而計算出整個 bizrq 業務組較準確的 cash 使用量。注意 cash 的計算不是百分百精確的,有些情形,例如 pod 被刪除了,那么下個計算周期這個 pod 的 cash 就不會累加到 status 了,不過由于 controller 更新 status 的頻率很高(最遲每 5m 更新一次),所以少量誤差并不會影響大部分業務場景下的 cash 限額的需求;
·object validating admission webhooks 攔截到請求后進行核時、卡時的額度校驗時,判斷 bizrq.status.used 里相關資源類型的 cash(如 cash/limits.cpu)是否已經大于等于 bizrq.status.hard 里配置的配額,是則表示 cash 已經超額,直接拒絕攔截的請求即可;
·另外,當 cash 已經超額時,并不能強制把相應業務組正在運行的業務停掉,而是可以通過監控告警的等手段通知到業務方,由業務方自行決定如何處置。
開發工具簡介
kubebuilder
Kubebuilder 是一個基于 CRD 搭建 controller、admission webhook server 腳手架的工具,可以按 K8s 社區推薦的方式來擴展實現業務組件,讓用戶聚焦業務層邏輯,底層通用的邏輯已經直接集成到腳手架里。
bizrq 主要用到了 kubebuilder 的以下核心組件 / 功能:
· manager:負責管理 controller、webhook server 的生命周期,初始化 clients、caches,當我們要集成不同資源對象的 client、cache 時,只需寫一行代碼將資源對象的 schema 注冊一下就可以了;
· caches:根據注冊的 scheme(schema 維護了 GVK 與對應 Go types 的映射) 同步 apiserver 中所有關心的 GVK(對象類型)的 GVR(對象實例),維護 GVK -> Informer 的映射;
· clients:封裝了對象的增刪改查操作接口,執行查詢操作時,底層會通過 cache 查詢,執行變更類操作時,底層會訪問 apiserver;
· indexer:可以通過 indexer 給 cache 加索引提升本地查詢效率,例如實現 bizrq 功能時,可以通過建立父子關系索引,方便通過父查找所有子 bizrq;
· controller:controller 的腳手架,提供腳手架讓業務層只需要關注感興趣的事件(任務生產),及實現 Reconcile 方法(任務消費),以便對 crd 定義的對象進行狀態調和;
· webhook server:webhook server 的腳手架,業務層只需要實現 Handler 接口,以便對攔截的請求做處理。
code-generator
實現了 bizrq 組件之后,可以通過 code-generator 工具生成 bizrq 的 informer、lister、clientset 等客戶端代碼,以便其他應用進行集成:
· client-gen:生成 crd 對象的標準操作方法:get、list、create、update、patch、delete、deleteCollection、watch 等;
· informer-gen: 生成監聽 crd 對象相關事件的 informer;
· lister-gen: 生成緩存層只讀的 get、list 方法。
落地情況及后續規劃
目前 bizrq 分級配額管理方案已經在平臺的在線業務場景全面落地,我們基于 bizrq 組件,對在線業務的 argo rollout 部署對象進行攔截和額度校驗,結合在線業務場景中的“項目 - 服務 - 流水線”等層級的配額管理需求,實現了分級配額管理界面,讓用戶可以自行管理各層級的資源配額,從而解決業務資源爭搶、減輕了平臺資源管理壓力、提高了相關問題的定位和解決效率。
后續我們將持續完善 bizrq 組件的功能,例如:
·以插件式的方式支持更多種類對象的攔截和額度校驗(例如離線訓練任務 tfjob、有狀態部署對象 statefulset 等),從而使 bizrq 分級配額管理組件能落地到更多的離在線業務場景中;
·完善自動擴縮容(HPA)場景下的額度校驗。目前我們是通過分析用戶 HPA 配置的最大副本數是否會導致超額,來判斷用戶配置的值是否合理,后續可以給 bizrq 增加一個 validating admission webhook,通過攔截 scale 對象的方式來進行額度校驗,從而讓校驗邏輯更加健壯、完整。
另外,我們也會結合實際的業務場景,完善上層功能的使用體驗。例如優化資源額度的遷入遷出、借用流程;完善資源碎片分析、給業務推薦更加合理的部署資源套餐等能力,提升用戶資源配額管理的體驗和效率。
審核編輯 :李倩
-
cpu
+關注
關注
68文章
10825瀏覽量
211142 -
AI
+關注
關注
87文章
30122瀏覽量
268408 -
計算平臺
+關注
關注
0文章
51瀏覽量
9612 -
vivo
+關注
關注
12文章
3292瀏覽量
63145 -
深度學習
+關注
關注
73文章
5492瀏覽量
120975
原文標題:vivo AI 計算平臺的 K8s 分級配額管理實踐
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
OpenStack與K8s結合的兩種方案的詳細介紹和比較
如何使用kubernetes client-go實踐一個簡單的與K8s交互過程
Docker不香嗎為什么還要用K8s
簡單說明k8s和Docker之間的關系
K8S集群服務訪問失敗怎么辦 K8S故障處理集錦

mysql部署在k8s上的實現方案
k8s是什么意思?kubeadm部署k8s集群(k8s部署)|PetaExpres
什么是K3s和K8s?K3s和K8s有什么區別?
k8s生態鏈包含哪些技術
跑大模型AI的K8s與普通K8s的區別分析
K8s多集群管理:為什么需要多集群、多集群的優勢是什么

k8s云原生開發要求






 工商網監
工商網監
評論