 R-sq越高代表模型擬合越好?
R-sq越高代表模型擬合越好?
在統計建模中,究竟R-sq應該取多大? 我們經常聽到這個疑問。以前,我們分享過如何解釋R-Sq,我們還糾正了一個統計上的誤區,即較低的R-sq不一定差,較高的R-sq不一定好。顯然,“R-sq應該多高”的答案就是:視情況而定。
盲目追求高R-sq的模型很容易掉入過度擬合的陷阱,這一點在大數據建模中經常發現。
什么是好的模型?
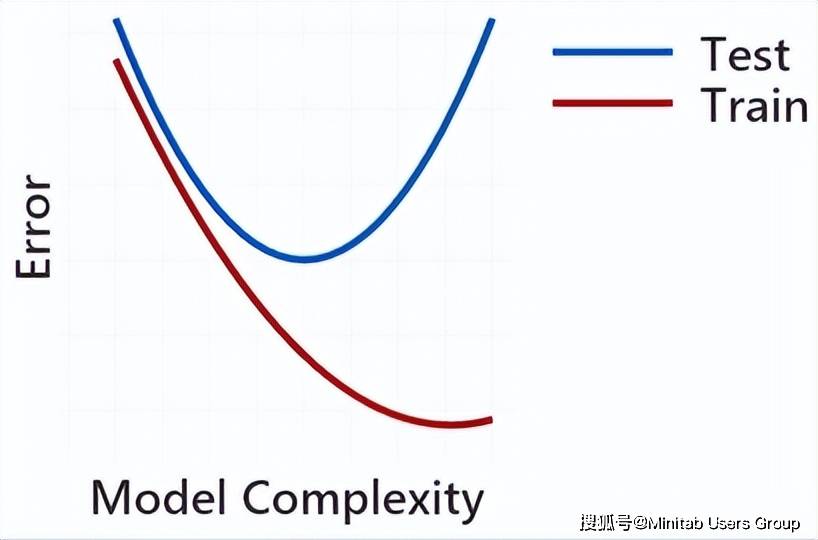
我們在建模的時候最不愿意看到兩種情況:過度擬合和欠擬合。使用與擬合模型相同的數據來評估模型,經常會導致過度擬合,如下圖:
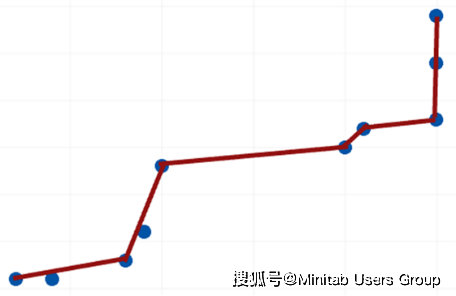
而這種過度擬合的模型如果用來預測的話,效果往往不好。
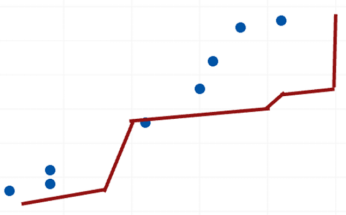
那么什么才算一個好的模型呢?一個好的模型需要在高方差(過度擬合)和高偏差(欠擬合)之間找到一種權衡。
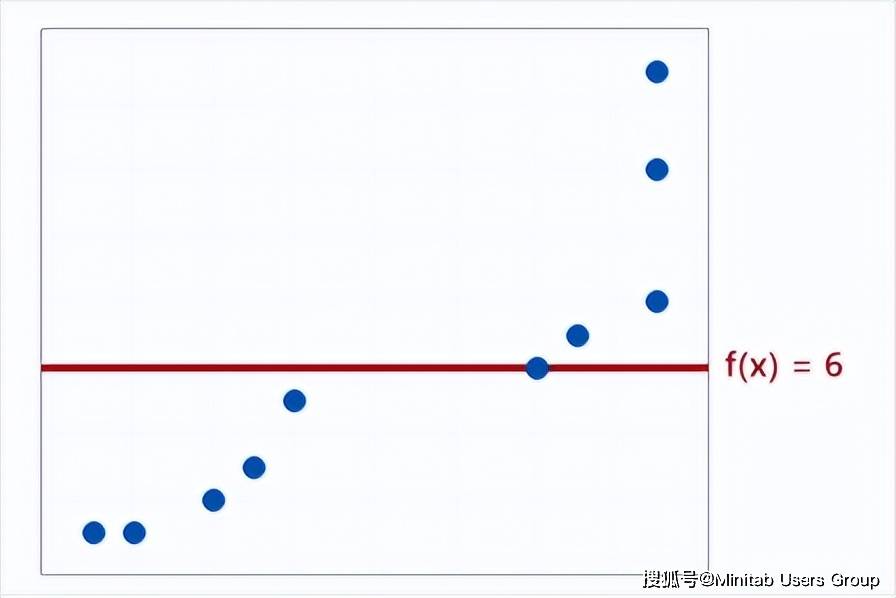
上圖就是由于模型太簡單導致存在高的偏差。
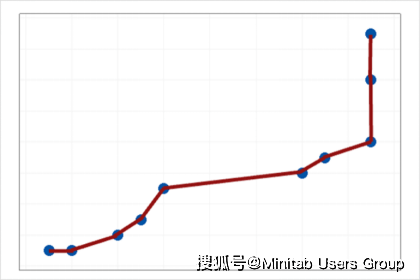
上圖就是由于模型過度擬合導致存在高的方差。
過度擬合與欠擬合之間的權衡
那么如何去找到“高偏差”與“高方差”之間的權衡呢?這就需要用到“驗證”法了。
大數據建模把數據分為兩大類:訓練集和測試集。訓練集用來創建模型,而測試集來評估模型的性能,這樣我們就可以來權衡過度擬合和欠擬合的模型。
舉個例子,對于同一組數據我們可以下面三個不同的模型,看起來立方模型是最好的。
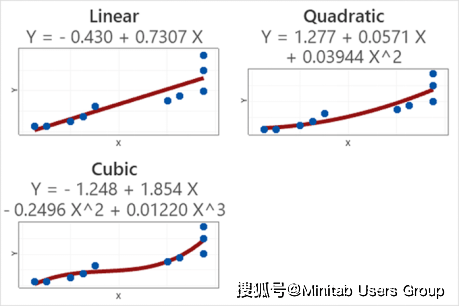
但當我們常用驗證法,從下圖中我們可知,用訓練集來建模時,模型越復雜模型誤差確實越小,但再來看看測試集你會發現當模型復雜到一定程度,它的誤差會隨著模型復雜度的增加而增大。也就是說,太簡單和太復雜的模型都不能很好的用來預測。看來找到這個權衡點很重要,這是如何做到的呢?這就要來說說所謂的“驗證”法了。
三種驗證方法
在Minitab 21版本的回歸(擬合回歸模型、擬合二值Logistic模型、擬合Poisson模型)和預測分析模塊中包含三種用于驗證的方法:

對這三種驗證方法做一個簡單介紹:
1. 留一驗證法
這種方法正如其名,留一留一,就是留下一行yi,再用其他所有數據來建模,得到模型后再把留下來這一行代入得到的模型就會得到對應的擬合者,其過程如下所示:
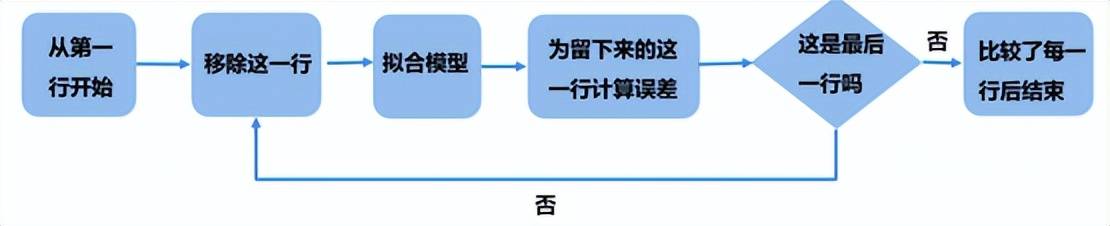
接下來,我們計算預測的殘差平方和(Predicted Residual Sum of Squares)
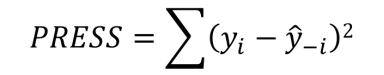
有了PRESS就可以來計算R-sq(預測)了,到這里是不是很熟悉了。
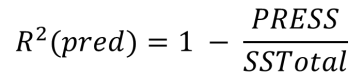

2. 測試集驗證法
隨機保留一定比例(Minitab 21默認保留30%)的數據(測試集),用剩余的數據來擬合模型(訓練集)。
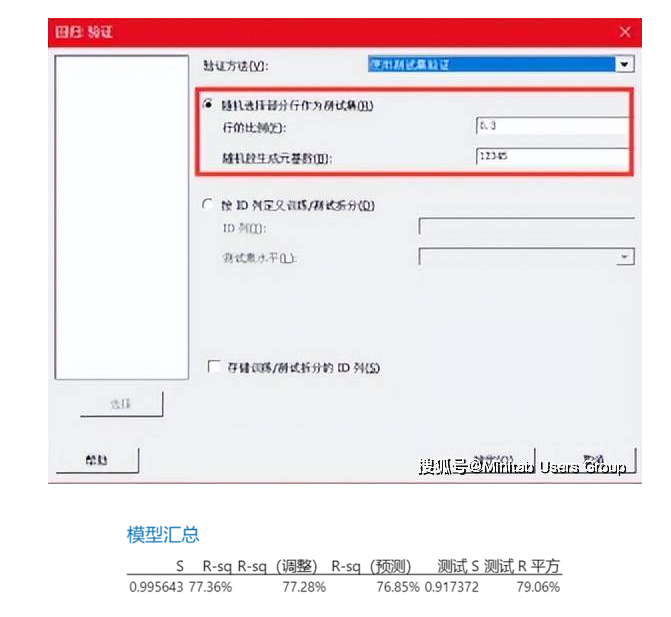
3. K折交叉驗證法
將數據拆分個K個子集,以其中一份為測試數據,其它K-1份用于訓練數據來擬合模型。使用測試數據計算誤差,重復k次,每次忽略一份,基于測試數據誤差統計匯總信息選擇模型。
小結
當你詢問R-sq應該取多大時,可能是因為你想確定當前模型是否能夠滿足要求。我希望你有更好的方法來解決這這個問題而不是只通過R-sq,尤其當你的數據量和數據維度比較大的時候。
審核編輯黃宇
-
Minitab
+關注
關注
0文章
163瀏覽量
11661 -
統計建模
+關注
關注
0文章
3瀏覽量
5703
發布評論請先 登錄
相關推薦
電池容量越高越好嗎?
電池的容量越高越好嗎 ?
為什么AD位數越高越好AD位數是如何影響信號幅值的






 工商網監
工商網監
評論