 特斯拉的下一代AI芯片:存算一體
特斯拉的下一代AI芯片:存算一體
ChatGPT的火爆預示了自動駕駛的方向:大模型(至少超過100億個參數)和高算力(至少1000TOPS@FP16)。ChatGPT完美展示了大模型的優勢,也讓英偉達欣喜若狂,英偉達、AMD和英特爾是最大受益者(英偉達最頂級的DGX-H100中的CPU是英特爾的W3495X,國內售價高達每片8萬人民幣),還有幾乎壟斷高端服務器市場的中國臺灣企業廣達和英業達,科技巨頭每年需要花費數百億乃至上千億美元購買新的服務器來處理越來越大的AI模型,并且會持續數十年。
高算力讓存儲墻愈加明顯,存儲系統的成本也持續攀升,AI芯片價格越來越高,未來10萬美元甚至百萬美元級AI芯片也極有可能。要完美解決存儲墻問題是不可能的,折中的辦法是存算一體。這雖然無法解決芯片成本趨高的問題,但是可以解決1000TOPS算力的問題。
根據存儲與計算的距離遠近,將廣義存算一體的技術方案分為三大類,分別是近存計算 (Processing Near Memory,PNM)、存內處理(Processingln Memory,PIM) 和存內計算(Computing in Memory, CIM)。其中,存內計算即狹義的存算一體。
存內計算面臨的最大挑戰是內存和高性能計算都是高度集中的行業,巨頭們出于利潤的考量,不會允許革命性的存內計算顛覆其所屬的壟斷行業。內存行業,美光、三星和SK Hynix在高性能存儲領域市占率達100%。高性能計算領域,英特爾、AMD和英偉達的市場占有率也接近100%。臺積電和三星聯合壟斷了高性能芯片代工領域。7納米以下晶圓廠產能是最具話語權的武器,沒有這個,高性能計算便是空中樓閣。
PNM已經非常常見,即HBM與CPU一體,所有高性能計算芯片都是如此,采用HBM堆疊,2.5D封裝,硅中介層(Interposer)內聯在基板上。也可以反推,沒有采用HBM就不是高性能計算芯片。特斯拉二代FSD已經用上了GDDR6,下一代基本可以肯定是HBM3了。

PIM則是再下一階段熱點
圖片來源:Planet
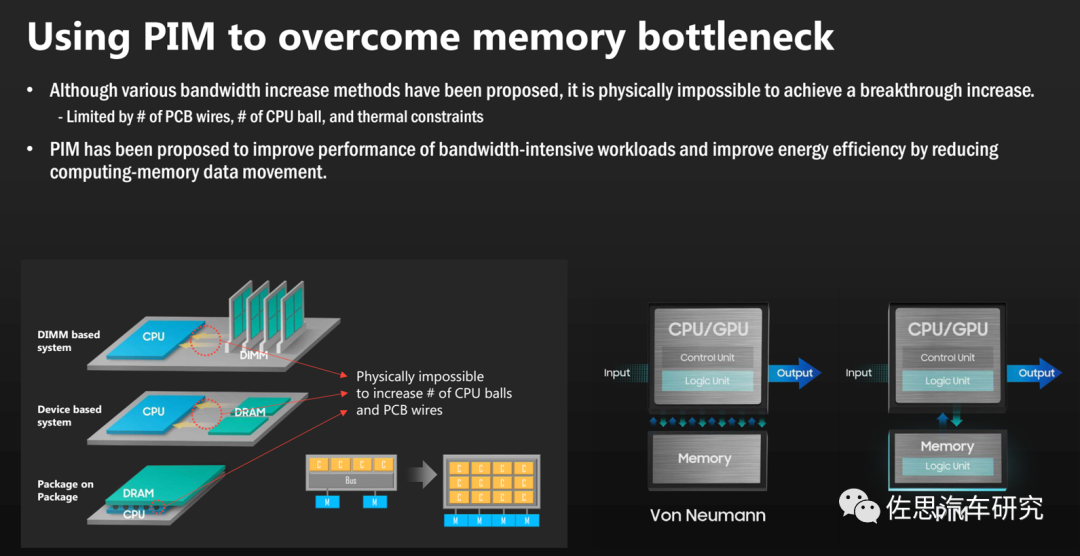
PIM已經有商業化的實例,最早的實例是Xilinx的Alveo U280
圖片來源:Planet
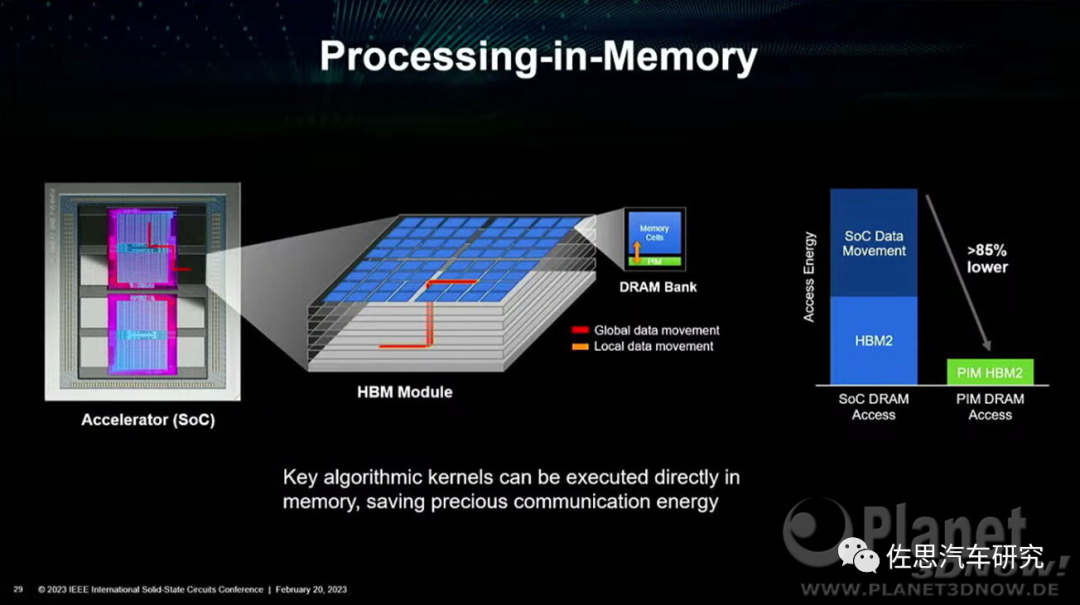
PIM可以大幅度降低存取功耗
圖片來源:Planet

圖片來源:三星
AMD收購Xilinx,其中最看中的就是PIM堆疊技術,AMD后來將其用在InstinctMI100/MI250/MI150/MI210系列GPU上,這也是美國商務部禁止向中國出售的芯片。MI100的性能能夠超越英偉達的上一代旗艦A100,功耗較A100降低約25%,價格也低于A100約30%。MI250與英偉達新旗艦H100持平,在FP32和FP64上,MI250更強;在FP16上,H100遠超MI250。
PIM的主角還是三星,配角是AMD,三星Aquabolt-XLHBM2-PIM是目前唯一PIM內存。
Aquabolt-XL HBM2-PIM架構

圖片來源:三星
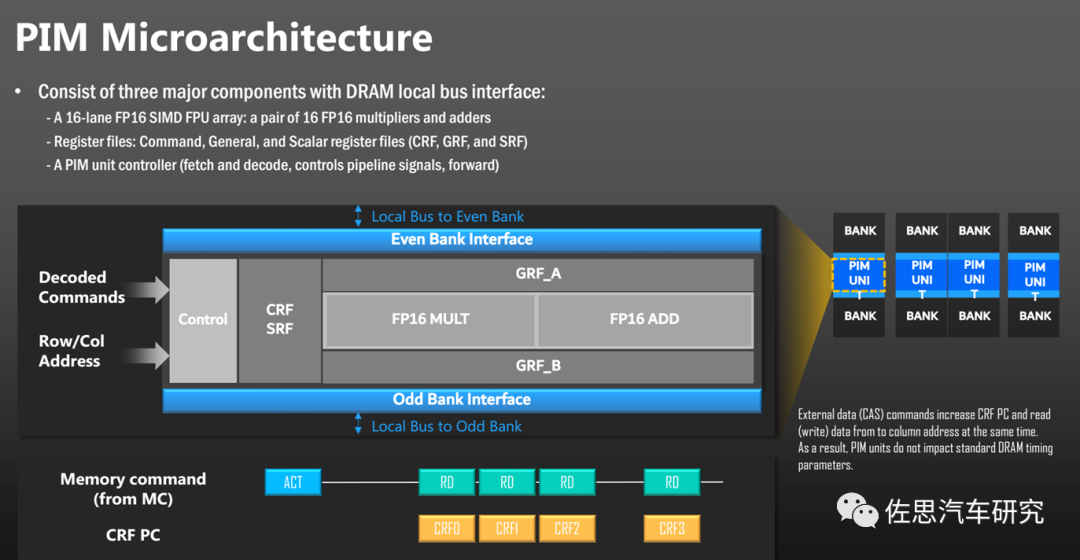
PIM非常簡單,就是用硅通孔(Through Silicon Via, TSV)技術將計算單元塞進內存上下BANK之間。TSV技術人類2010年就掌握了,只不過迄今還不算特別成熟,價格還是有點高。
圖片來源:三星
計算單元很簡單,一個FP16矩陣乘法,一個FP16矩陣加法。輸入命令解碼和行列地址即可。
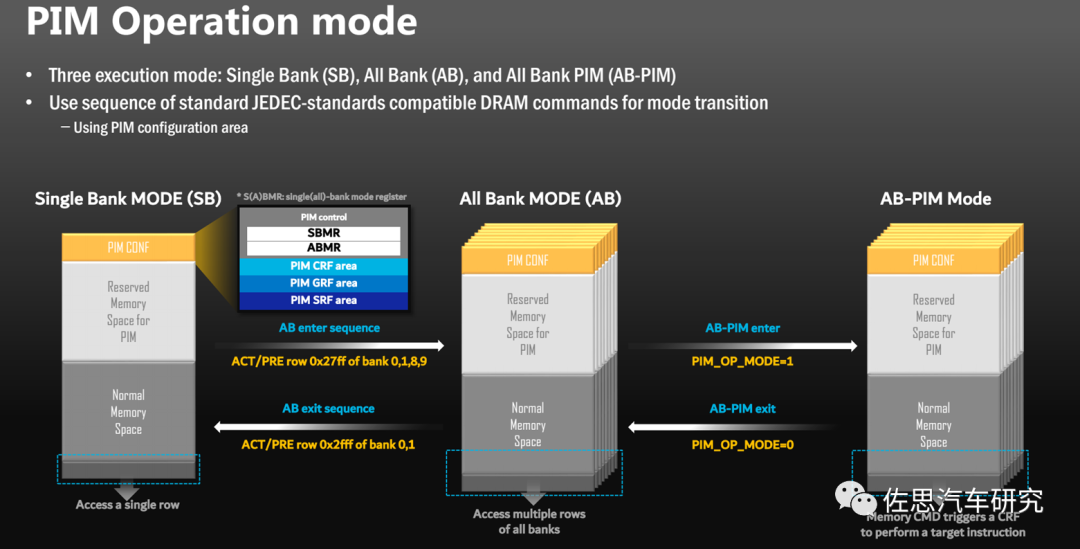
PIM運作模式
圖片來源:三星
PIM的軟件棧

圖片來源:三星
在2023CES消費電子展上,AMD推出了MI300,PIM似乎升級到了HBM3。

圖片來源:AMD
國人一心打破美國的科技壟斷,由于缺乏先進2.5D和3D封裝產能和技術,中國企業對PNM和PIM完全不感興趣,聚焦的是真正的存算一體,即存內計算。
其本質是利用不同存儲介質的物理特性,對存儲電路進行重新設計使其同時具備計算和存儲能力,直接消除“存〞“算〞界限,使計算能效達到數量級提升的目標。在存儲原位上實現計算,是真正的存算一體。存算一體理論上完美,但目前離實用至少還有10年距離。
存內計算主要包含數字和模擬兩種實現方式,二者適用于不同應用場景。模擬存內計算能效高,但誤差較大,適用于低精度、低功耗計算場景,如端側可穿戴設備等。模擬存內計算還涉及復雜的模數轉換器(ADC)、數模轉換器(DAC)、跨阻放大器(TIA) 等模塊。ADC和DAC領域需要幾十年經驗長期摸索,全球精通ADC和DAC的僅有ADI、德州儀器和NXP三家,其中ADI最強,正是牽涉大量模擬部分,存內計算無法使用EDA工具,導致芯片開發成本高、周期長、規模小、算力低。
一直以來,主流的存內計算大多采用模擬計算實現,近兩年數字存內計算的研究熱度也有所提升。模擬存內計算主要基于物理定律(歐姆定律和基爾霍夫定律),在存算陣列上實現乘加運算。數字存內計算通過在存儲陣列內部加入邏輯計算電路,如與門和加法器等,使數字存內計算陣列具備存儲及計算能力。數字存內計算精度高,但是其存儲單元只能存儲單比特數據,而目前主流人工智能訓練是32或64比特數據,這嚴重限制了其應用范圍,并且數字存內計算需增加加法樹邏輯電路,很大程度上限制了面積及能效優勢。也就是目前存內計算在高算力領域沒有容身之地的原因。
存內計算最重要的部分就是存儲器件本身,算法之類的軟件部分幾乎可以忽略。目前存儲器主要有易失性存儲器和非易失存儲器件。易失性存儲器在設備掉電之后數據丟失,如SRAM等。非易失性存儲器在設備掉電后數據可保持不變,如NOR Flash、可變電阻隨機存儲器 (Resistive Random Access Memory, RRAM或ReRAM)、磁性隨機存儲器(Magnetoresistive Random Access Memory, MRAM)、相變存儲器 (Phase ChangeMemory, PCM)等。中國企業或機構主要研究的是鐵電晶體管FeFET。傳統的SRAM、DRAM、NAND被三星、美光和SK Hynix壟斷,因此基于傳統存儲的存內計算無論如何都無法對抗這三大巨頭,大部分機構或企業都選擇另辟蹊徑。
幾種新興存儲器的技術對比
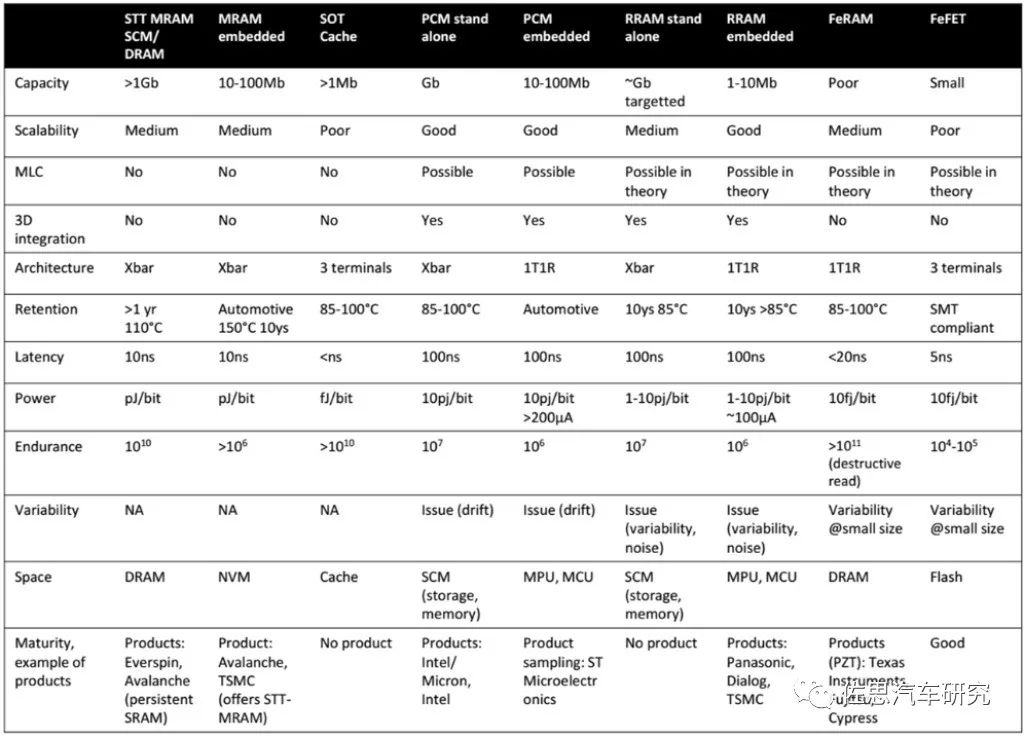
需要指出,目前存儲器制造也需要EUV***了,而EUV***被ASML壟斷,又聽命于美國政府。通常認為,DRAM的天花板是10nm。其原因是在傳統1T1C架構下,單位元件面積不斷減小,如何保證電容能夠存儲足夠的電荷、防止相鄰存儲單元之間的耦合,是DRAM推進到10nm以下的無解難題,而EUV是用來做7nm以下的,DRAM目前主流是14納米。14納米理論上完全可以用DUV來完成,不需要EUV。
但實際情況并非如此,三星電子的1Znm節點DRAM量產結果表明,相比于DUV浸沒式光學***,EUV***極大簡化了制造流程,不僅可以大幅度提高光刻分辨率和DRAM性能,而且可以減少所使用的掩模數量,從而減少流程步驟的數量,減少缺陷、提高存儲密度,并大幅降低DRAM生產成本,縮短生產周期。也就是說,即使EUV掩模費用(達數百萬美元)遠高于DUV掩模費用,使用EUV***量產DRAM也具有更高的性價比。三星電子和SK海力士公司將EUV***引入1Znm節點DRAM的量產進展順利,并一路高歌到第五代1β節點,令DRAM三巨頭中最為保守的美光公司很無奈。美光一度宣稱自己用DUV也做到了11納米,然而進入2023年后的DDR5時代,韓國雙雄再一次依靠EUV***碾壓了美光。美光在DDR5方面嚴重落后韓國雙雄。
全球智能汽車領域,特斯拉是第一個用上GDDR6的企業,特斯拉也很可能第一個用上HBM2或HBM3,當然代價是芯片成本超過1000美元以上,不過以特斯拉的溢價能力,消費者愿意為高價買單。要想超越特斯拉,不如一步到位,直接上HBM3。當然了,對中國企業來說最困難的不是技術,而是供應鏈,晶圓級2.5D封裝HBM的產能95%都在臺積電手中,5%在三星手中。
審核編輯 :李倩
-
存儲器
+關注
關注
38文章
7455瀏覽量
163623 -
存儲
+關注
關注
13文章
4266瀏覽量
85686 -
AI芯片
+關注
關注
17文章
1860瀏覽量
34919
原文標題:特斯拉的下一代AI芯片:存算一體
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
直播預約 |開源芯片系列講座第24期:SRAM存算一體:賦能高能效RISC-V計算

存算一體化與邊緣計算:重新定義智能計算的未來

存算一體架構創新助力國產大算力AI芯片騰飛
科技新突破:首款支持多模態存算一體AI芯片成功問世

蘋芯科技引領存算一體技術革新 PIMCHIP系列芯片重塑AI計算新格局

后摩智能推出邊端大模型AI芯片M30,展現出存算一體架構優勢
豐田、日產和本田將合作開發下一代汽車的AI和芯片
知存科技助力AI應用落地:WTMDK2101-ZT1評估板實地評測與性能揭秘
探索存內計算—基于 SRAM 的存內計算與基于 MRAM 的存算一體的探究

知存科技攜手北大共建存算一體化技術實驗室,推動AI創新
DPU技術賦能下一代AI算力基礎設施
什么是通感算一體化?通感算一體化的應用場景







 工商網監
工商網監
評論