") 未來的高性能FPGA是否會優(yōu)于GPU?
未來的高性能FPGA是否會優(yōu)于GPU?
英特爾加速器架構(gòu)實驗室的Eriko Nurvitadhi 博士以最新的GPU為參照,對兩代IntelFPGA上新興的DNN算法進(jìn)行了評估,認(rèn)為新興的低精度和稀疏DNN算法效率較之傳統(tǒng)的密集FP32 DNN有巨大改進(jìn),但是它們引入了GPU難以處理的不規(guī)則并行度和定制數(shù)據(jù)類型。相比之下,F(xiàn)PGA正是設(shè)計用于在運(yùn)行不規(guī)則并行度和自定義數(shù)據(jù)類型時實現(xiàn)極端的可定制性的。這樣的趨勢使未來FPGA成為運(yùn)行DNN、AI和ML應(yīng)用的可行平臺。
來自社交媒體和互聯(lián)網(wǎng)的圖像、視頻和語音數(shù)字?jǐn)?shù)據(jù)的持續(xù)指數(shù)增長推動了分析的需要,以使得數(shù)據(jù)可以理解和處理。
數(shù)據(jù)分析通常依賴于機(jī)器學(xué)習(xí)(ML)算法。在ML算法中,深度卷積神經(jīng)網(wǎng)絡(luò)(DNN)為重要的圖像分類任務(wù)提供了最先進(jìn)的精度,并被廣泛采用。
在最近的 International Symposium onField Programmable Gate Arrays (ISFPGA) 上,Intel Accelerator Architecture Lab (AAL) 的 Eriko Nurvitadhi 博士提出了一篇名為CanFPGAs beat GPUs in AcceleratingNext-Generation Deep Neural Networks 的論文。他們的研究以最新的高性能的 NVIDIA Titan X Pascal * Graphics Processing Unit (GPU) 為參照,對兩代 Intel FPGA(Intel Arria10 和Intel Stratix 10)的新興DNN算法進(jìn)行了評估。
Intel Programmable SolutionsGroup 的 FPGA 架構(gòu)師 Randy Huang 博士,論文的合著者之一,說:“深度學(xué)習(xí)是AI中最令人興奮的領(lǐng)域,因為我們已經(jīng)看到了深入學(xué)習(xí)帶來的巨大進(jìn)步和大量應(yīng)用。雖然AI 和DNN 研究傾向于使用 GPU,但我們發(fā)現(xiàn)應(yīng)用領(lǐng)域和英特爾下一代FPGA 架構(gòu)之間是完美契合的。我們考察了接下來FPGA 的技術(shù)進(jìn)展,以及DNN 創(chuàng)新算法的快速增長,并思考了對于下一代 DNN 來說,未來的高性能 FPGA 是否會優(yōu)于GPU。我們的研究發(fā)現(xiàn),F(xiàn)PGA 在DNN 研究中表現(xiàn)非常出色,可用于需要分析大量數(shù)據(jù)的AI、大數(shù)據(jù)或機(jī)器學(xué)習(xí)等研究領(lǐng)域。使用經(jīng)修剪或壓縮的數(shù)據(jù)(相對于全32位浮點(diǎn)數(shù)據(jù)(FP32)),被測試的 Intel Stratix10 FPGA 的性能優(yōu)于GPU。除了性能外,F(xiàn)PGA 的強(qiáng)大還源于它們具有適應(yīng)性,通過重用現(xiàn)有的芯片可以輕松實現(xiàn)更改,從而讓團(tuán)隊在六個月內(nèi)從想法進(jìn)展到原型(和用18個月構(gòu)建一個ASIC相比)。”
測試中使用的神經(jīng)網(wǎng)絡(luò)機(jī)器學(xué)習(xí)
神經(jīng)網(wǎng)絡(luò)可以被表現(xiàn)為通過加權(quán)邊互連的神經(jīng)元的圖形。每個神經(jīng)元和邊分別與激活值和權(quán)重相關(guān)聯(lián)。該圖形被構(gòu)造為神經(jīng)元層。如圖1所示。

圖1 深度神經(jīng)網(wǎng)絡(luò)概述
神經(jīng)網(wǎng)絡(luò)計算會通過網(wǎng)絡(luò)中的每個層。對于給定層,每個神經(jīng)元的值通過相乘和累加上一層的神經(jīng)元值和邊權(quán)重來計算。計算非常依賴于多重累積運(yùn)算。DNN計算包括正向和反向傳遞。正向傳遞在輸入層采樣,遍歷所有隱藏層,并在輸出層產(chǎn)生預(yù)測。對于推理,只需要正向傳遞以獲得給定樣本的預(yù)測。對于訓(xùn)練,來自正向傳遞的預(yù)測錯誤在反向傳遞中被反饋以更新網(wǎng)絡(luò)權(quán)重。這被稱為反向傳播算法。訓(xùn)練迭代地進(jìn)行向前和向后傳遞以調(diào)整網(wǎng)絡(luò)權(quán)重,直到達(dá)到期望的精度。
FPGA成為可行的替代方案
硬件:與高端GPU 相比,F(xiàn)PGA 具有卓越的能效(性能/瓦特),但它們不具有高峰值浮點(diǎn)性能。FPGA技術(shù)正在迅速發(fā)展,即將推出的Intel Stratix10 FPGA提供超過5,000個硬件浮點(diǎn)單元(DSP),超過28MB的芯片上RAM(M20Ks),與高帶寬內(nèi)存(up to 4x250GB/s/stack or 1TB/s)的集成,并來自新HyperFlex技術(shù)的改進(jìn)頻率。英特爾FPGA 提供了一個全面的軟件生態(tài)系統(tǒng),從低級HardwareDescription 語言到具有OpenCL、C和C ++的更高級別的軟件開發(fā)環(huán)境。英特爾將進(jìn)一步利用MKL-DNN庫,針對Intel的機(jī)器學(xué)習(xí)生態(tài)系統(tǒng)和傳統(tǒng)框架(如今天提供的Caffe)以及其他不久后會出現(xiàn)的框架對 FPGA進(jìn)行調(diào)整。基于14nm工藝的英特爾Stratix 10在FP32吞吐量方面達(dá)到峰值9.2TFLOP/s。相比之下,最新的Titan X Pascal GPU的FP32吞吐量為11TFLOP/s。
新興的DNN算法:更深入的網(wǎng)絡(luò)提高了精度,但是大大增加了參數(shù)和模型大小。這增加了對計算、帶寬和存儲的要求。因此,使用更為有效的DNN已成趨勢。新興趨勢是采用遠(yuǎn)低于32位的緊湊型低精度數(shù)據(jù)類型, 16位和8位數(shù)據(jù)類型正在成為新的標(biāo)準(zhǔn),因為它們得到了DNN軟件框架(例如TensorFlow)支持。此外,研究人員已經(jīng)對極低精度的2位三進(jìn)制和1位二進(jìn)制 DNN 進(jìn)行了持續(xù)的精度改進(jìn),其中值分別約束為(0,+ 1,-1)或(+ 1,-1)。Nurvitadhi 博士最近合著的另一篇論文首次證明了,ternary DNN可以在最著名的ImageNet數(shù)據(jù)集上實現(xiàn)目前最高的準(zhǔn)確性。另一個新興趨勢是通過諸如修剪、ReLU 和ternarization 等技術(shù)在DNN神經(jīng)元和權(quán)重中引入稀疏性(零存在),這可以導(dǎo)致DNN帶有?50%至?90%的零存在。由于不需要在這樣的零值上進(jìn)行計算,因此如果執(zhí)行這種稀疏DNN 的硬件可以有效地跳過零計算,性能提升就可以實現(xiàn)。新興的低精度和稀疏DNN算法效率較之傳統(tǒng)的密集FP32 DNN有巨大改進(jìn),但是它們引入了GPU難以處理的不規(guī)則并行度和定制數(shù)據(jù)類型。相比之下,F(xiàn)PGA正是設(shè)計用于在運(yùn)行不規(guī)則并行度和自定義數(shù)據(jù)類型時實現(xiàn)極端的可定制性的。這樣的趨勢使未來FPGA成為運(yùn)行DNN、AI和ML應(yīng)用的可行平臺。黃先生說:“FPGA專用機(jī)器學(xué)習(xí)算法有更多的余量。圖2說明了FPGA的極端可定制性(2A),可以有效實施新興的DNN(2B)。
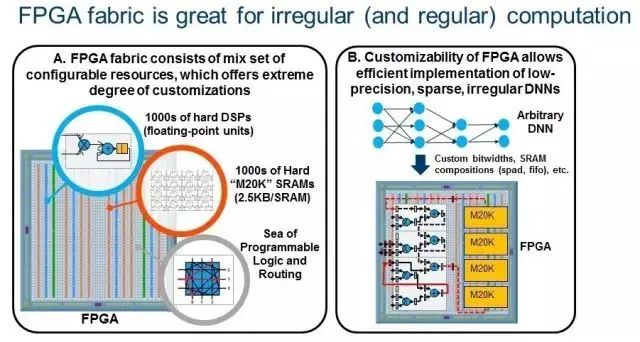
圖2
研究所用的硬件和方法
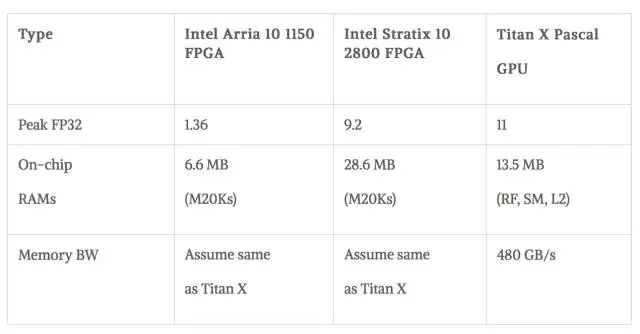
GPU:使用已知的庫(cuBLAS)或框架(Torch with cuDNN)FPGA:使用QuartusEarly Beta版本和PowerPlay
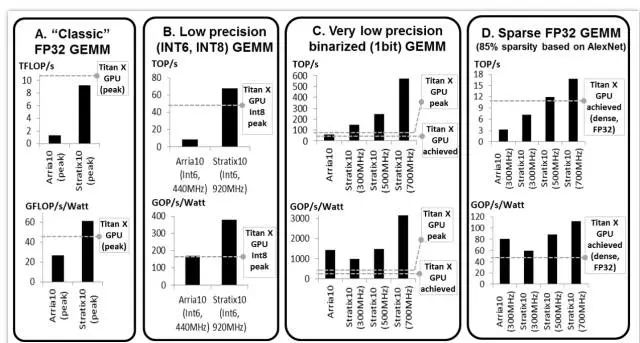
圖3 GEMM測試結(jié)果、GEMM是DNN中的關(guān)鍵操作
在低精度和稀疏DNN中,Stratix 10 FPGA 比 Titan X GPU的性能更好,甚至性能功耗比要更好。未來這類DNN可能會成為趨勢。
研究1:GEMM測試
DNN 嚴(yán)重依賴GEMM。常規(guī)DNN依靠FP32密集GEMM。然而,較低的精度和稀疏的新興DNN 依賴于低精度和/或稀疏的GEMM 。Intel 團(tuán)隊對這些GEMM進(jìn)行了評估。
FP32 密集GEMM:由于FP32密集GEMM得到了很好的研究,該團(tuán)隊比較了FPGA和GPU數(shù)據(jù)表上的峰值。Titan X Pascal 的最高理論性能是Stratix 10 的11 TFLOP和9.2 TFLOP。圖3A顯示,帶有多得多的DSP 數(shù)量的Intle Stratix 10 將提供比Intel Arria 10 更強(qiáng)大的FP32性能,和Titan X 的性能表現(xiàn)接近。
低精度INT6 GEMM:為了顯示FPGA的可定制性優(yōu)勢,該團(tuán)隊通過將四個int6打包到一個DSP模塊中,研究了FPGA的Int6 GEMM。對于本來不支持Int6 的GPU,他們使用了Int8 GPU 的峰值性能進(jìn)行了比較。圖3B顯示,Intel Stratix 10 的性能優(yōu)于GPU。FPGA比GPU提供了更引人注目的性能/功耗比。
非常低精度的1位二進(jìn)制GEMM :最近的二進(jìn)制DNN 提出了非常緊湊的1bit數(shù)據(jù)類型,允許用xnor 和位計數(shù)操作替換乘法,非常適合FPGA。圖3C顯示了團(tuán)隊的二進(jìn)制GEMM 測試結(jié)果,其中FPGA 基本上執(zhí)行得比GPU 好(即,根據(jù)頻率目標(biāo)的不同,為~2x 到 ~10x)。
稀疏GEMM:新出現(xiàn)的稀疏DNN包含許多零值。該團(tuán)隊在帶有85%零值的矩陣上測試了一個稀疏的GEMM(基于已修剪的AlexNet)。該團(tuán)隊測試了使用FPGA的靈活性以細(xì)粒度的方式來跳過零計算的 GEMM 設(shè)計。該團(tuán)隊還在 GPU 上測試了稀疏的 GEMM,但發(fā)現(xiàn)性能比在GPU 上執(zhí)行密集的 GEMM 更差(相同的矩陣大小)。該團(tuán)隊的稀疏 GEMM 測試(圖3D)顯示,F(xiàn)PGA 可以比 GPU 表現(xiàn)更好,具體取決于目標(biāo) FPGA 的頻率。

圖4 DNN精度的趨勢,以及FPGA和GPU在Ternary ResNet DNN上的測試結(jié)果
研究2:使用三進(jìn)制 ResNet DNN 測試
三進(jìn)制DNN最近提出神經(jīng)網(wǎng)絡(luò)權(quán)重約束值為+1,0或-1。這允許稀疏的2位權(quán)重,并用符號位操作代替乘法。在本次測試中,該團(tuán)隊使用了為零跳躍、2位權(quán)重定制的FPGA設(shè)計,同時沒有乘法器來優(yōu)化運(yùn)行Ternary-ResNet DNN 。
與許多其他低精度和稀疏的DNN 不同,三進(jìn)制DNN可以為最先進(jìn)的DNN(即ResNet)提供可供比較的精度,如圖4A所示。“許多現(xiàn)有的GPU和FPGA研究僅針對基于AlexNet(2012年提出)的ImageNet的”足夠好“的準(zhǔn)確性。最先進(jìn)的Resnet(在2015年提出)提供比AlexNet高出10%以上的準(zhǔn)確性。在2016年底,在另一篇論文中,我們首先指出,Resnet上的低精度和稀疏三進(jìn)制DNN 算法可以在全精度ResNet 的±1%的精度范圍內(nèi)實現(xiàn)。這個三進(jìn)制ResNet 是我們在FPGA研究中的目標(biāo)。因此,我們首先論證,F(xiàn)PGA可以提供一流的(ResNet)ImageNet精度,并且可以比GPU更好地實現(xiàn)。““Nurvitadhi說。
圖4B顯示了 Intel Stratix 10 FPGA 和 Titan X GPU 在 ResNet-50上的性能和性能/功耗比。即使保守估計,Intel Stratix 10 FPGA 也比 Titan X GPU 性能提高了約60%。中度和激進(jìn)的估計會更好(2.1x和3.5x的加速)。有趣的是,Intel Stratix 10 750MHz的激進(jìn)預(yù)估可以比 Titan X 的理論峰值性能還高35%。在性能/功耗比方面,從保守估計到激進(jìn)估計,Intel Stratix 10 比 Titan X 要好2.3倍到4.3倍, FPGA如何在研究測試中堆疊
結(jié)果表明,Intel Stratix 10 FPGA的性能(TOP /秒)比稀疏的、Int6 和二進(jìn)制DNN的GEMM上的 Titan X Pascal GPU分別提高了10%、50%和5.4倍。在三進(jìn)制 ResNet 上,Stratix 10 FPGA 的性能比Titan X Pascal GPU 提高了60%,而性能/功耗比好2.3倍。結(jié)果表明,F(xiàn)PGA 可能成為下一代DNN 加速的首選平臺。深層神經(jīng)網(wǎng)絡(luò)中FPGA的未來
FPGA 能否在下一代 DNN 的性能上擊敗 GPU ?Intel 對兩代 FPGA(Intel Arria 10和 Intel Stratix 10)以及最新的 Titan X GPU 的各種新興DNN的評估顯示,目前DNN算法的趨勢可能有利于FPGA,而且FPGA甚至可以提供卓越的性能。雖然這些結(jié)論源于2016年完成的工作,Intel 團(tuán)隊在繼續(xù)測試 Intel FPGA 的現(xiàn)代 DNN 算法和優(yōu)化(例如,F(xiàn)FT / winograd 數(shù)學(xué)變換,量化,壓縮)。
該團(tuán)隊還指出,除了DNN之外,F(xiàn)PGA在其他不規(guī)則應(yīng)用以及延遲敏感(如ADAS和工業(yè)用途)等領(lǐng)域也有機(jī)會。
“目前使用32位密集矩陣乘法的機(jī)器學(xué)習(xí)是GPU體現(xiàn)優(yōu)勢的領(lǐng)域”,黃表示:“我們鼓勵其他開發(fā)人員和研究人員與我們一起重新表述機(jī)器學(xué)習(xí)問題,以充分發(fā)揮 FPGA 更小位數(shù)處理能力的優(yōu)勢,因為 FPGA 可以很好地適應(yīng)向低精度的轉(zhuǎn)變。”



歡迎加入至芯科技FPGA微信學(xué)習(xí)交流群,這里有一群優(yōu)秀的FPGA工程師、學(xué)生、老師、這里FPGA技術(shù)交流學(xué)習(xí)氛圍濃厚、相互分享、相互幫助、叫上小伙伴一起加入吧!
點(diǎn)個在看你最好看
原文標(biāo)題:未來的高性能FPGA是否會優(yōu)于GPU?
文章出處:【微信公眾號:FPGA設(shè)計論壇】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
FPGA
+關(guān)注
關(guān)注
1626文章
21667瀏覽量
601864
原文標(biāo)題:未來的高性能FPGA是否會優(yōu)于GPU?
文章出處:【微信號:gh_9d70b445f494,微信公眾號:FPGA設(shè)計論壇】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
精彩回顧 : 向新而行 云啟未來——2024高云FPGA線上技術(shù)研討會
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析」閱讀體驗】--了解算力芯片GPU
GPU市場趨勢與未來發(fā)展
如何提高GPU性能
GPU高性能服務(wù)器配置
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析」閱讀體驗】--全書概覽
FPGA做深度學(xué)習(xí)能走多遠(yuǎn)?
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析
IaaS+on+DPU(IoD)+下一代高性能算力底座技術(shù)白皮書
技術(shù)巔峰!探秘國內(nèi)高性能模擬芯片的未來發(fā)展

FPGA在深度學(xué)習(xí)應(yīng)用中或?qū)⑷〈?b class='flag-5'>GPU
如何通過DLP FPGA實現(xiàn)低延時高性能的深度學(xué)習(xí)處理器設(shè)計呢?
FPGA與GPU的區(qū)別
揭秘GPU:GPU的未來發(fā)展趨勢






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論