") 結(jié)合卷積層來(lái)創(chuàng)建一個(gè)完整的推理函數(shù)
結(jié)合卷積層來(lái)創(chuàng)建一個(gè)完整的推理函數(shù)
到上一篇為止,我們已經(jīng)完成了卷積層、全連接層、池化層、激活函數(shù)ReLU的所有C的編程實(shí)現(xiàn)。在本文中,我們將結(jié)合這些層來(lái)創(chuàng)建一個(gè)完整的推理函數(shù)。
模型實(shí)現(xiàn)
下面是在第 2 篇文章中創(chuàng)建的推理模型的圖表。

首先輸入一張1x28x28的圖片,然后兩次通過Conv2d -> ReLU -> MaxPool2d提取特征,最后轉(zhuǎn)為linear,> ReLU -> Linear為10階向量值。
用C寫的時(shí)候,只需按如下依次逐層處理即可。
voidconv2d(constfloat*x,constfloat*weight,constfloat*bias,int32_twidth,int32_theight, int32_tin_channels,int32_tout_channels,int32_tksize,float*y){ for(int32_toch=0;och=height||pw=width){ continue; } int64_tpix_idx=(ich*height+ph)*width+pw; int64_tweight_idx=((och*in_channels+ich)*ksize+kh)*ksize+kw; sum+=x[pix_idx]*weight[weight_idx]; } } } //addbias sum+=bias[och]; y[(och*height+h)*width+w]=sum; } } } }
函數(shù)內(nèi)部的緩沖區(qū) (x1-x8) 用于連接各層之間的特征數(shù)據(jù)。
在HLS中,在哪里定義這個(gè)buffer很重要,如果像這次一樣把它放在函數(shù)中,就可以指定使用FPGA中的RAM(或寄存器)。
另一方面,如果將此緩沖區(qū)作為函數(shù)的參數(shù)提供,則可以將數(shù)據(jù)連接到外部 DRAM。這個(gè)區(qū)域需要根據(jù)應(yīng)用來(lái)設(shè)計(jì),但是這次內(nèi)部SRAM已經(jīng)夠用了,所以定義在函數(shù)內(nèi)部。
如果像以前一樣編寫接口規(guī)范,將如下所示:
輸入
x: 輸入圖像。shape=(1, 28, 28)
weight0:第一個(gè)卷積層的權(quán)重。shape=(4, 1, 3, 3)
bias0:第一個(gè)卷積層的偏差。shape=(4)
weight1:第二個(gè)卷積層的權(quán)重。shape=(8, 4, 3, 3)
bias1:第二個(gè)卷積層的偏差。shape=(8)
weight2:第一個(gè)全連接層的權(quán)重。shape=(32, 8 * 7 * 7)
bias2:第一個(gè)全連接層的偏差。shape=(32)
weight3:第二個(gè)全連接層的權(quán)重。shape=(10, 32)
bias3:第二個(gè)全連接層的偏差。shape=(10)
輸出
y:輸出向量。shape=(10)
界面設(shè)置
在目前創(chuàng)建的函數(shù)中,我們還沒有具體定義創(chuàng)建電路的接口。未指定接口時(shí),HLS 會(huì)為簡(jiǎn)單 SRAM 生成一個(gè)接口。
該接口不能用于訪問DRAM等訪問時(shí)間不確定的接口,不方便在真機(jī)上操作。為此,我們告訴HLS使用一種稱為AMBA AXI4接口協(xié)議(以下簡(jiǎn)稱AXI)的協(xié)議,該協(xié)議主要用于Xilinx FPGA上IP之間的接口。
簡(jiǎn)單介紹一下AXI,AXI是ARM公司提供的一種接口標(biāo)準(zhǔn)。
Xilinx IP主要使用以下三種協(xié)議。
AXI4:高速內(nèi)存訪問協(xié)議(主要用途:訪問DRAM、PCIe等)
AXI4-Lite:AXI4的一個(gè)子集,一種用于低速內(nèi)存訪問的協(xié)議(主要用途:IP寄存器控制)
AXI4-Stream:僅用于單向數(shù)據(jù)傳輸?shù)膮f(xié)議,無(wú)地址(主要用途:流數(shù)據(jù)處理)
這次我們將使用 AXI4 訪問輸入/輸出數(shù)據(jù),使用 AXI4-Lite 控制 IP。
具有接口定義的推理函數(shù)如下所示:
voidinference_top(constfloatx[kMaxSize],
constfloatweight0[kMaxSize],constfloatbias0[kMaxSize],
constfloatweight1[kMaxSize],constfloatbias1[kMaxSize],
constfloatweight2[kMaxSize],constfloatbias2[kMaxSize],
constfloatweight3[kMaxSize],constfloatbias3[kMaxSize],
floaty[kMaxSize]){
#pragmaHLSinterfacem_axiport=xoffset=slavebundle=gmem0
#pragmaHLSinterfacem_axiport=weight0offset=slavebundle=gmem1
#pragmaHLSinterfacem_axiport=weight1offset=slavebundle=gmem2
#pragmaHLSinterfacem_axiport=weight2offset=slavebundle=gmem3
#pragmaHLSinterfacem_axiport=weight3offset=slavebundle=gmem4
#pragmaHLSinterfacem_axiport=bias0offset=slavebundle=gmem5
#pragmaHLSinterfacem_axiport=bias1offset=slavebundle=gmem6
#pragmaHLSinterfacem_axiport=bias2offset=slavebundle=gmem7
#pragmaHLSinterfacem_axiport=bias3offset=slavebundle=gmem8
#pragmaHLSinterfacem_axiport=yoffset=slavebundle=gmem9
#pragmaHLSinterfaces_axiliteport=xbundle=control
#pragmaHLSinterfaces_axiliteport=weight0bundle=control
#pragmaHLSinterfaces_axiliteport=weight1bundle=control
#pragmaHLSinterfaces_axiliteport=weight2bundle=control
#pragmaHLSinterfaces_axiliteport=weight3bundle=control
#pragmaHLSinterfaces_axiliteport=bias0bundle=control
#pragmaHLSinterfaces_axiliteport=bias1bundle=control
#pragmaHLSinterfaces_axiliteport=bias2bundle=control
#pragmaHLSinterfaces_axiliteport=bias3bundle=control
#pragmaHLSinterfaces_axiliteport=ybundle=control
#pragmaHLSinterfaces_axiliteport=returnbundle=control
dnnk::inference(x,
weight0,bias0,
weight1,bias1,
weight2,bias2,
weight3,bias3,
y);
}
dnnk::inference函數(shù)就是前面提到的推理函數(shù),這個(gè)函數(shù)將dnnk::inference“包起來(lái)”了。
和上一篇文章一樣,top函數(shù)的接口是一個(gè)數(shù)組,而不是一個(gè)指針。在仿真 HLS 時(shí),此符號(hào)對(duì)于指定仿真器保留的內(nèi)存緩沖區(qū)的大小是必需的,但它并不是很重要。
第 30-50 行 #pragma HLS interfaceport=<參數(shù)名稱>bundle=<要分配的接口名稱> 使用語(yǔ)法為每個(gè)函數(shù)參數(shù)指定接口協(xié)議,使用的協(xié)議有兩個(gè),m_axi和s_axilite,其中m_/s_部分表示請(qǐng)求是發(fā)送還是接收(AXI術(shù)語(yǔ)中的master/slave),后面的部分就是前面提到的協(xié)議部分增加。
在此函數(shù)中,每個(gè)數(shù)據(jù)端口都成為 AXI4 主端口并主動(dòng)從 DRAM (L30-39) 中獲取數(shù)據(jù)。此時(shí)主機(jī)CPU等訪問的存儲(chǔ)器地址可以通過AXI4-Lite從端口(L40-49)進(jìn)行設(shè)置。
最后,用于開始處理的控制寄存器和用于檢查處理完成的狀態(tài)寄存器port=return鏈接到 AXI4-Lite 從端口 (L50)。
綜合/結(jié)果確認(rèn)
界面
將這個(gè)電路作為IP輸出,放到Vivado的IP Integrator中,如下圖。每個(gè)端口的名稱對(duì)應(yīng)于上面的interface pragma bundle位置。
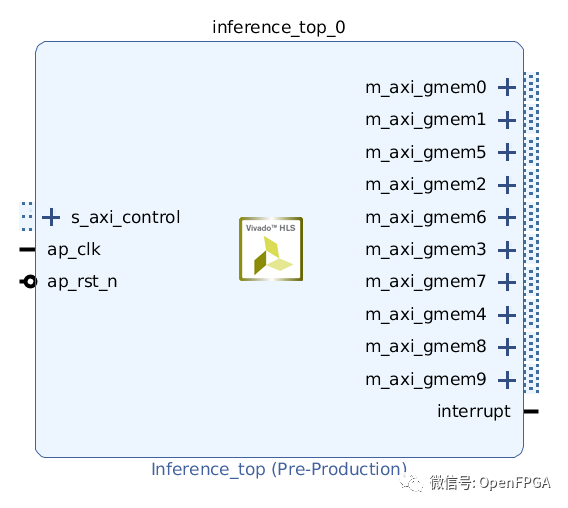
熟悉 Vivado 開發(fā)的都知道,剩下要做的就是適當(dāng)?shù)剡B接端口,將能夠創(chuàng)建能夠進(jìn)行推理處理的 FPGA 圖像。
綜合
綜合時(shí)的表現(xiàn)如下:執(zhí)行時(shí)間最短 1.775 ms,最長(zhǎng) 7.132 ms。
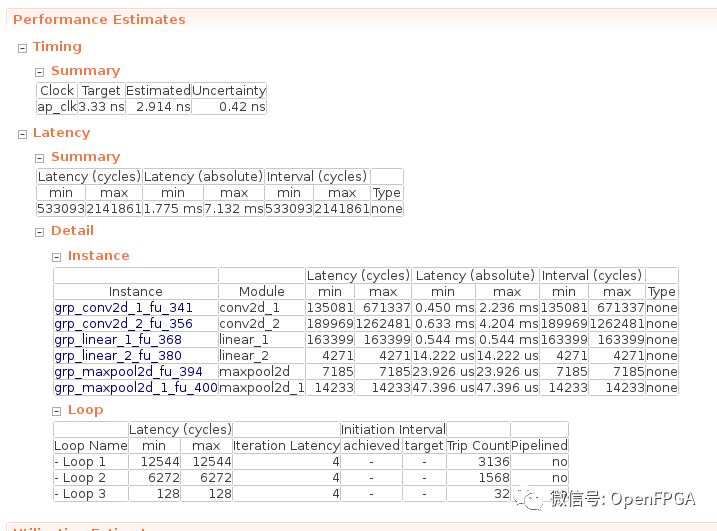
在這里,我想知道為什么輸入圖像大小是固定的,但執(zhí)行時(shí)間不固定,這是因?yàn)榈谌恼轮袆?chuàng)建的卷積函數(shù)continue包括補(bǔ)零處理。
由于這個(gè)補(bǔ)零過程只在屏幕邊緣進(jìn)行,實(shí)際執(zhí)行時(shí)間幾乎是最大時(shí)間7.132 ms。
for(int32_tkw=0;kw=height||pw=width){
continue;
}
int64_tpix_idx=(ich*height+ph)*width+pw;
int64_tweight_idx=((och*in_channels+ich)*ksize+kh)*ksize+kw;
sum+=x[pix_idx]*weight[weight_idx];
}
在這里為了可讀性,用continue中止,但是在FPGA上,與在這里中斷循環(huán)的處理相比,使用已經(jīng)安裝的乘法加法器進(jìn)行0加法運(yùn)算的成本更少。
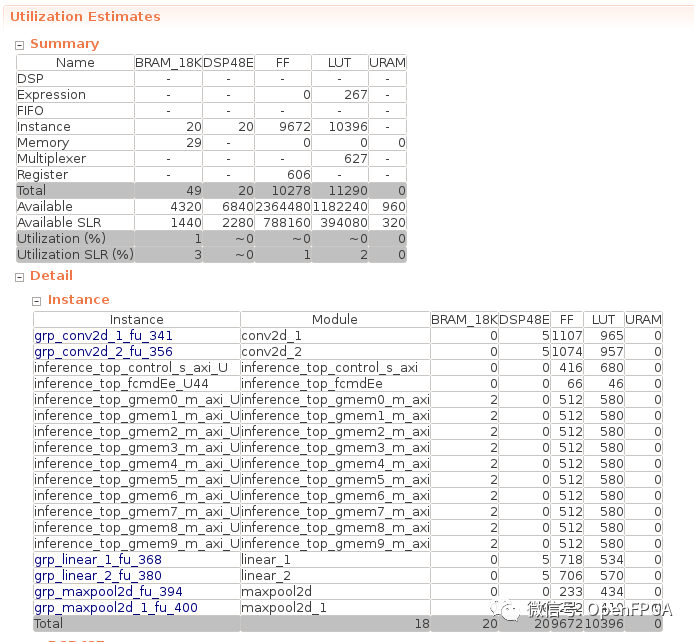
資源使用
FPGA的資源利用率如下所示:總體使用量是微不足道的,因?yàn)闆]有增加并行化和流水線等資源的加速。
審核編輯:劉清
-
DRAM
+關(guān)注
關(guān)注
40文章
2303瀏覽量
183319 -
寄存器
+關(guān)注
關(guān)注
31文章
5322瀏覽量
120022 -
SRAM芯片
+關(guān)注
關(guān)注
0文章
65瀏覽量
12051 -
HLS
+關(guān)注
關(guān)注
1文章
128瀏覽量
24038
原文標(biāo)題:總結(jié)
文章出處:【微信號(hào):Open_FPGA,微信公眾號(hào):OpenFPGA】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
求函數(shù)計(jì)算序列線性卷積結(jié)果
CNN之卷積層
卷積神經(jīng)網(wǎng)絡(luò)一維卷積的處理過程
【飛凌RK3568開發(fā)板試用體驗(yàn)】RKNN模型推理測(cè)試
如何在PyTorch上學(xué)習(xí)和創(chuàng)建網(wǎng)絡(luò)模型呢?
對(duì)卷積層的C++實(shí)現(xiàn)詳細(xì)介紹
結(jié)合卷積層與全連接層創(chuàng)建一個(gè)完整的推理函數(shù)
C語(yǔ)言入門教程-創(chuàng)建一個(gè)函數(shù)庫(kù)
一種改進(jìn)的殘差網(wǎng)絡(luò)結(jié)構(gòu)以減少卷積層參數(shù)

如何去理解CNN卷積層與池化層計(jì)算?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論