 語音識別芯片的基本原理和工作流程
語音識別芯片的基本原理和工作流程
語音識別技術的目標是將人們語音中的詞匯內容轉換為計算機可讀輸入,如按鈕、二進制編碼或字符序列。語音識別就像一個“機器的聽覺系統”,它允許設備根據識別和理解將語音信號轉換為相應的文本或指令。語音識別技術正逐漸成為計算機信息處理技術中的關鍵技術。
語音識別芯片的基本原理
語音識別芯片是將語音信號轉換為相應的文本信息。該系統主要包括四個部分:特征提取、聲學模型、語言模型及其詞典和解碼。為了更有效地提取特征,通常需要對收集到的聲音信號進行過濾、幀分析等預處理,從原始信號中提取要分析的信號;之后,特征提取工作將聲音信號從時域轉換為頻域,為聲學模型提供適當的特征向量;聲學模型根據聲學特征計算每個特征向量在聲學特征中的評分;語言模型根據語言學相關理論計算聲音信號對應短語序列的概率;最后,根據現有詞典對短語序列進行解碼,獲得最終可能的文本表示。
語音識別芯片有三個原理:
1、語音信號中的語言信息編碼是根據幅度譜的時間變化進行的;
2、由于語音是可以閱讀的,也就是說聲學信號可以在不考慮說話人說話傳達的信息內容的前提下用多個具有區別性的、離散的符號來表示;
3、語音交互是一個認知過程,因此不能與語法、詞義、術語規范等方面分開。
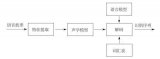
語音識別技術的工作流程
一般來說,一個完整的語音識別系統的工作過程分為七個步驟:
1、分析和處理語音信號,去除冗余信息。
2、獲取影響語音識別的重要信息和表達語言含義的特征信息。
3、圍繞特征信息,用最小單元識別單詞。
4、根據不同語言的各自語法,按順序識別單詞。
5、把前后含義為協助識別鑒定標準,有利于分析識別。
6、根據語義分析,將重要信息劃分為段落,取出被識別的單詞并相互連接,并根據句子的含義調整句子的組成。
7、整合詞義,具體分析前后文的相互依存,適當調整目前正在處理的句子。
英尚微所提供的超低功耗的離線智能語音識別芯片,集成了先進的語音活動監測(VAD)、聲紋識別、自動消噪神經網絡,擁有高效的電源管理模塊、數字和模擬語音信號輸入接口以及ARM Cortex-M0內核,并且搭配了GPIO、UART、SPI、I2C、I2S 等片內外設。在藍牙耳機、智能遙控、智能家居等場景中,能以更小的體積、極低的功耗實現離線語音識別功能。
審核編輯:湯梓紅
-
芯片
+關注
關注
453文章
50406瀏覽量
421825 -
語音識別
+關注
關注
38文章
1721瀏覽量
112547 -
語音識別芯片
+關注
關注
1文章
115瀏覽量
11896
發布評論請先 登錄
相關推薦
RNN的基本原理與實現
淺談無刷電機的工作流程
語音識別機器人的工作原理
物聯網系統智能控制產品的語音識別方案_離線語音識別芯片分析

rnn神經網絡基本原理
Transformer模型在語音識別和語音生成中的應用優勢
卷積神經網絡的基本原理和應用范圍
神經網絡的基本原理
AC/DC電源模塊的基本原理與應用

鴻蒙原生應用元服務-訪問控制(權限)開發工作流程相關
SOLIDWORKS 2024通過自動化和縮短工作流程來實現智能工作
語音識別技術的工作原理 語音識別技術的工作流程





 工商網監
工商網監
評論