 何利用PMC來發現JVM原生代碼的瓶頸?
何利用PMC來發現JVM原生代碼的瓶頸?
本文通過對CPU層面的代碼挖掘,發現JVM存在的問題,并通過對JVM打補丁的方式解決了大實例下性能不足的問題。
在前面的文章中,我們概述了可觀測性的三大領域:整體范圍,微服務和實例。我們描述了洞察每個領域所使用的工具和技術。然而,還有一類問題需要深入到CPU微體系架構中。本文我們將描述一個此類問題,并使用工具來解決該問題。
問題概述
問題起始于一個常規遷移。在Netflix,我們會定期對負載進行重新評估來優化可用容量的利用率。我們計劃將一個Java微服務(暫且稱之為GS2)遷移到一個更大的AWS實例上,規格從m5.4xl(16 vCPU)變為m5.12xl(48 vCPU)。GS2是計算密集型的,因此CPU就成為了受限資源。雖然我們知道,隨著vCPU數量的增長,吞吐量幾乎不可能實現線性增長,但可以近線性增長。
在大型實例上進行整合可以分攤后臺任務產生的開銷,為請求留出更多的資源,并可以抵消亞線性縮放。由于12xl實例的vCPU數是4xl實例的3倍,因此我們預期每個實例的吞吐量能夠提升3倍。在快速進行了一次金絲雀測試后發現沒有發現錯誤,并展示了更低的延遲,該結果符合預期,在我們的標準金絲雀配置中,會將流量平均路由到運行在4xl上的基準以及運行在12xl上的金絲雀上。
由于GS2依賴 AWS EC2 Auto Scaling來達到目標CPU利用率,一開始我們認為只要將服務重新部署到大型實例上,然后等待 ASG (Auto Scaling Group)達到目標CPU即可,但不幸的是,一開始的結果與我們的預期相差甚遠:
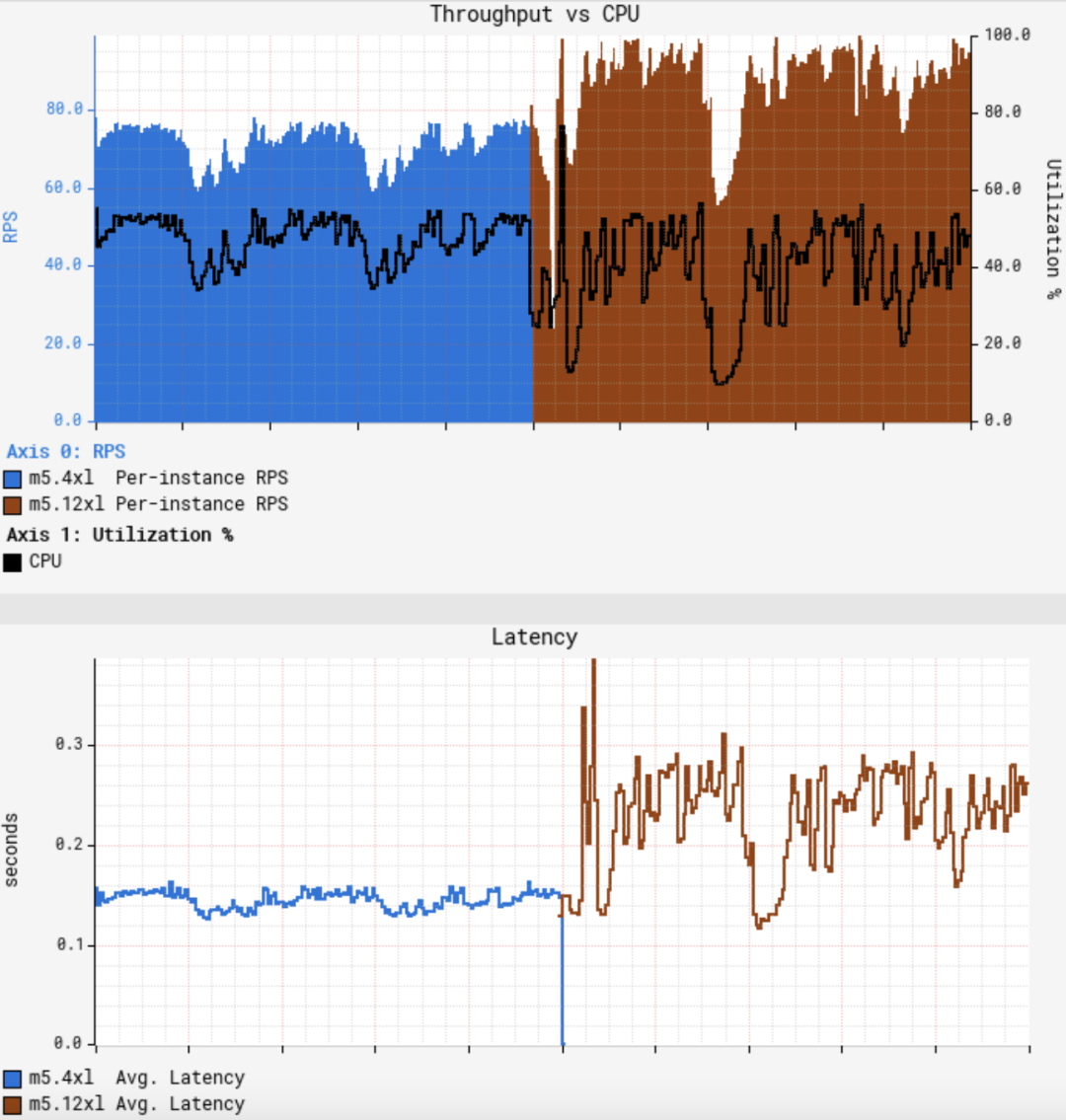
第一張圖展示了單節點吞吐量和CPU利用率之間的關系,第二張圖展示了平均請求延遲。可以看到當CPU大致達到50%時,平均吞吐量僅僅增加了約25%,大大低于預期。更糟糕的是,平均延遲則增加了50%,CPU和延遲的波動也更大。GS2是一個無狀態服務,它使用輪詢方式的負載均衡器來接收流量,因此所有節點應該接收到幾乎等量的流量。RPS(Requests Per Second)也顯示了,不同節點的吞吐量變化很少:
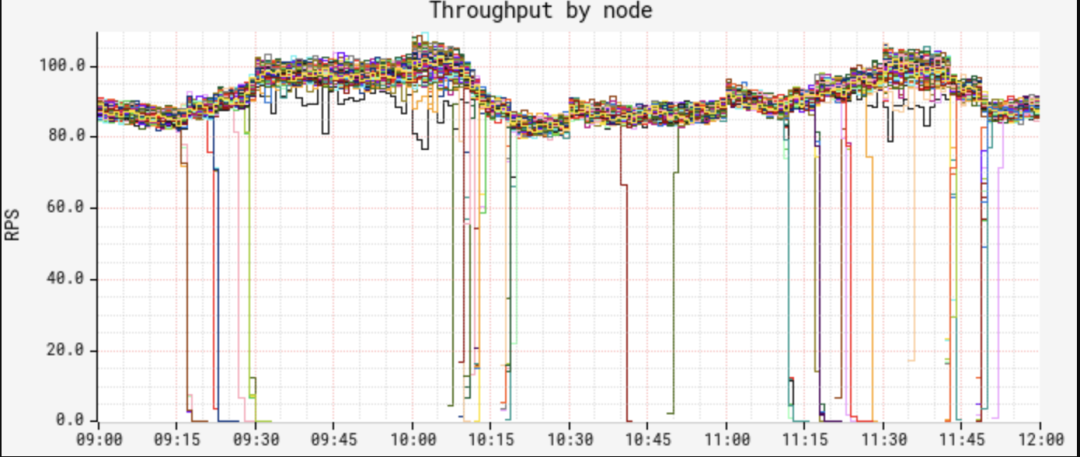
但當我們查看節點的CPU和延遲時,發現了一個奇怪的模式:
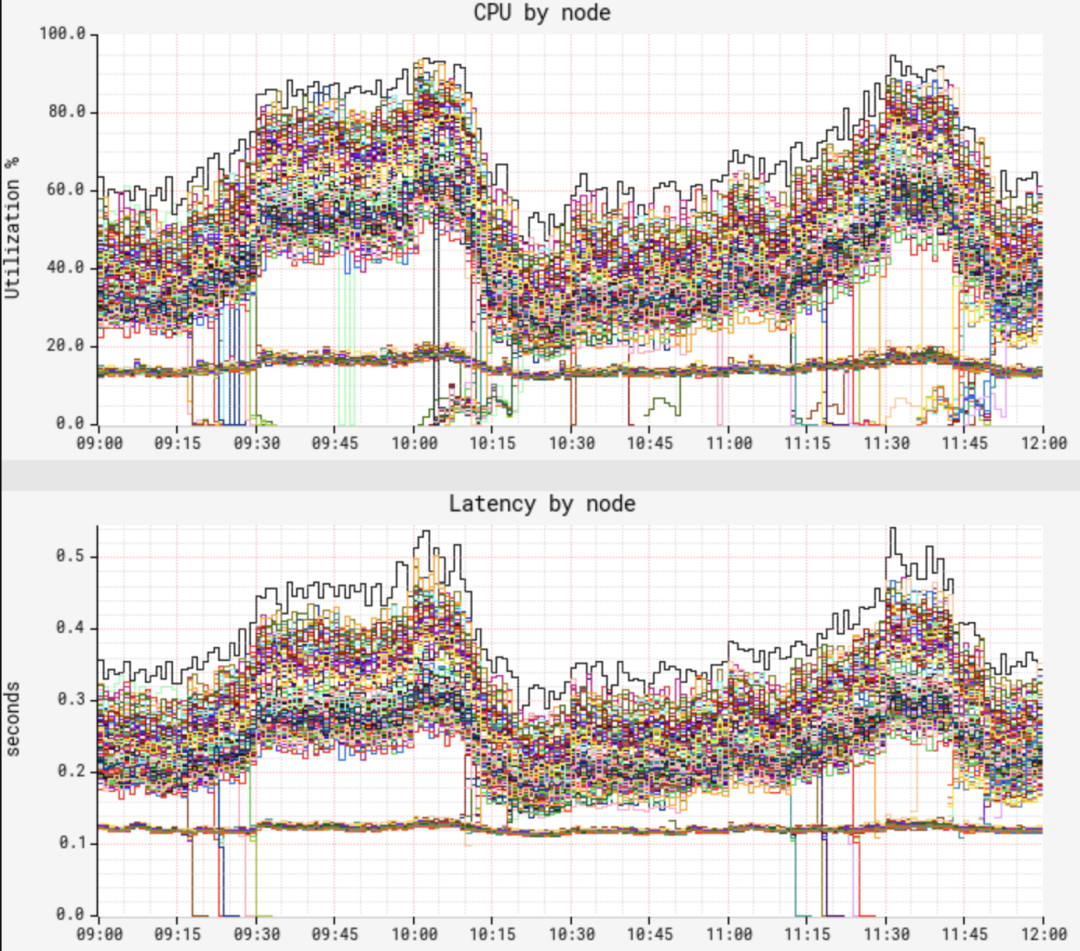
盡管我們確認了節點之間的流量分布相當,但CPU和延遲度量卻展示了一種非常不同的雙峰分布模式。"低波段"的節點展示了很低的CPU和延遲,且幾乎沒有波動,而"高波段"的節點則具有相當高的CPU和延遲,以及更大的波動。我們發現大約12%的節點處于低波段中,隨著時間的推移,這一圖形讓人產生懷疑。兩種波段中,在(節點上的)JVM的整個運行時間內,其性能特點保持一致,即節點不會跳出其所在的波段。我們就此開始進行問題定位。
首次嘗試解決
一開始我們嘗試對比快慢兩種節點的火焰圖。雖然火焰圖清晰地給出了采樣到的CPU利用率之間的差異,但堆棧之間的分布保持不變,因此并沒有獲得有價值的結論。我們轉而使用JVM專用的性能采樣,從基本的hotspot 統計到更詳細的 JFR (Java Flight Recorder)來比較事件分布,然而還是一無所獲,快慢兩種節點的事件數量和分布都沒有出現值得關注的差異。我們仍然懷疑JIT行為可能有問題,通過對perf-map-agent 采集的符號映射進行了一些基本統計,結果發現了另一個死角。
False Sharing
在確定沒有在app-,OS-和JVM層面有所遺漏之后,我們感覺答案可能隱藏在更低的層次。幸運的是,m5.12xl實例類型暴露了一組PMCs (Performance Monitoring Counters, 即PMU 計數器),因此我們可以使用PerfSpect采集一組基線計數器數據:
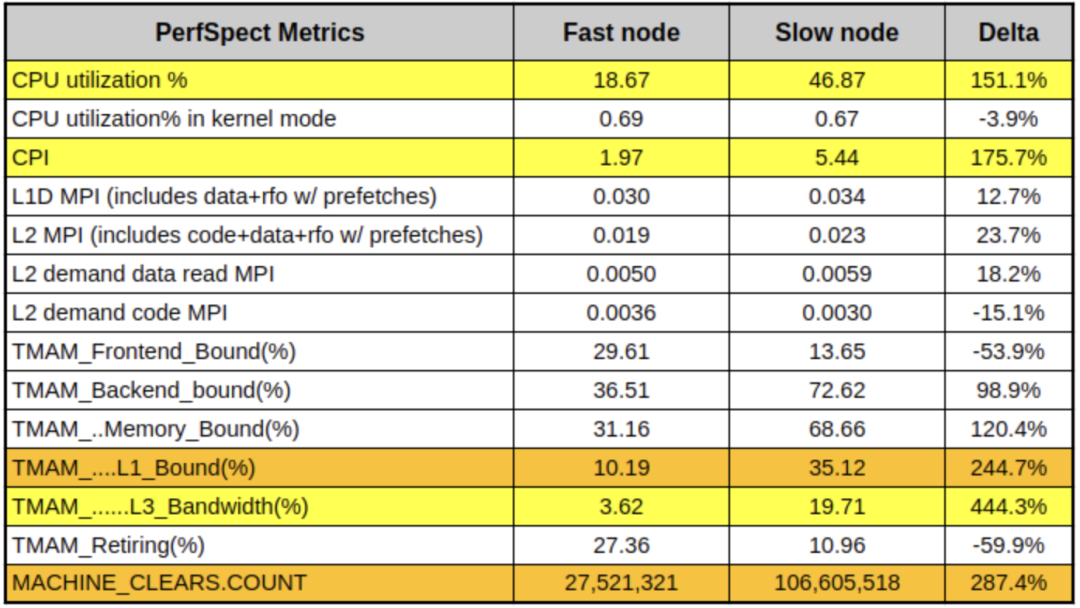
在上表中,低CPU/延遲的節點代表"快節點",而高CPU/延遲的節點代表"慢節點"。除了CPU上的明顯差異外,還看到慢節點的CPI幾乎是快節點的3倍。此外,我們還看到了更高的L1緩存活動以及4倍的MACHINE_CLEARS計數。一種常見的導致這種現象的原因稱為false sharing,即當2個core讀/寫恰好共享同一L1 cache line的不相關的變量的模式。Cache line是一個類似內存頁的概念,數據塊(x86系統通常為64字節)會進出該緩存,過程如下:
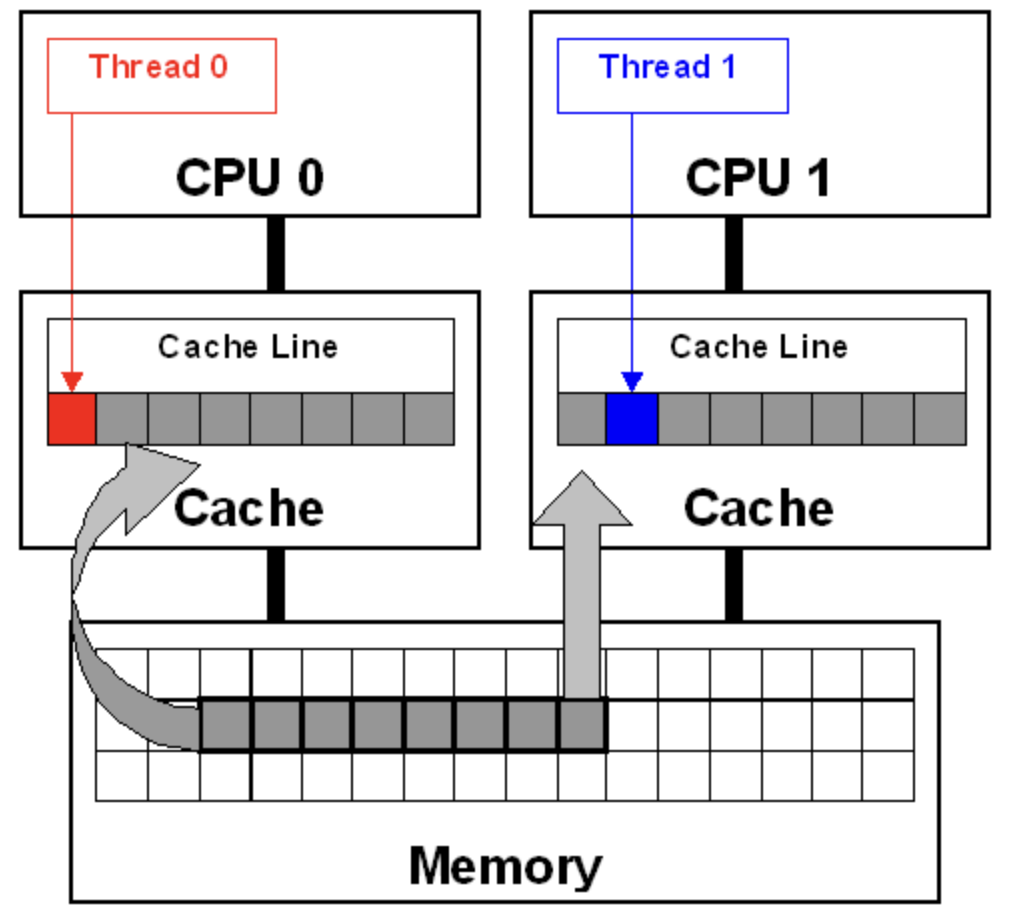
圖中的每個core都有自己的私有緩存,由于兩個cores會訪問相同的內存空間,因此必須保證緩存一致。這種一致性稱為緩存一致協議。Thread 0會寫入紅色變量,一致性協議會將Thread 0中的整個cache line標記為"已修改",并將Thread 1的緩存標記為"無效"。
而后,當Thread 1讀取藍色變量時,即使藍色變量不是"已修改"的,一致性協議也會強制從緩存中重載上次修改的內容(本例中為Thread 0的緩存)到cache line中。解決私有緩存之間的一致性需要花費一定時間并導致CPU暫停。此外,還需要通過最后一級共享緩存的控制器來監控來回的一致性流量,進而導致更多的暫停。我們認為CPU緩存一致性是理所當然的,但這種false sharing模式表明,如果只讀取與無關數據相鄰的變量時,就會造成巨大的性能損耗。
根據已掌握的知識,我們使用 Intel vTune 來進行微體系架構的性能采樣。通過研究熱點方法以及匯編代碼,我們找出了超過100CPI的指令(執行非常慢的指標),如下:
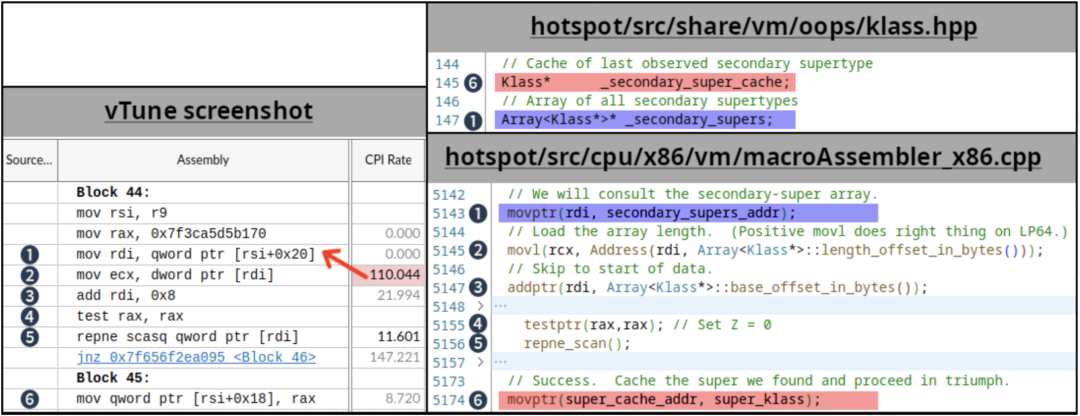
1到6的編號表示源代碼和vTune匯編視圖中對應的相同代碼/變量。紅色箭頭表示的CPI值可能屬于上一條指令,這是由于在沒有PEBS(基于處理器事件的采樣)的情況下進行了性能采樣,并且通常是被單條指令關閉的。(5)中的repne scan是一個相對少見的定義在JVM代碼庫中的操作,我們將這個代碼片段鏈接到用于子類檢查的例程(在撰寫本文時,JDK主線中存在相同的代碼)中。關于HotSpot中的子類型檢查的細節超出了本文的范疇,有興趣的可以參見2002年出版的Fast Subtype Checking in the HotSpot JVM。
基于該工作負載中使用的類層次結構的特點,我們不斷更新(6)_secondary_super_cache字段的代碼路徑,它是最后找到的二級父類的單元素緩存,注意該字段與_secondary_supers相鄰。_secondary_supers是所有父類的列表,會在掃描開始時讀取(1)。多線程會對這些字段進行讀寫操作,且如果字段(1)和(6)處于相同的cache line,那么就會出現false sharing的情況。在上圖中,我們使用紅色和藍色高亮了這些導致false sharing的字段。
由于cache line的長度為64字節,而指針長度為8字節,因此這些字段有1/8的機會讓處于不同的cache line中,有7/8的機會共享相同的cache line。1/8的即12.5%,這與前面觀測到的快節點的比例相同。
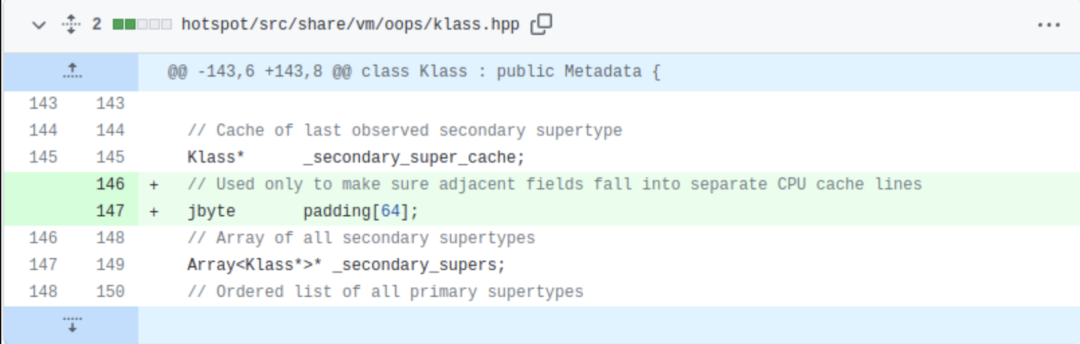
問題的修復需要設涉及對JDK的補丁操作,我們在_secondary_super_cache和_secondary_supers字段中間插入padding來保證它們不會使用相同的cache line。注意我們并沒有修改JDK的功能,只是變更了數據布局:
部署補丁之后的效果立竿見影。下圖中節點上的CPU出現了斷崖式下降。在這里,我們可以看到中午進行了一次紅黑部署,而新的ASG和修補后的JDK在12:15時生效:
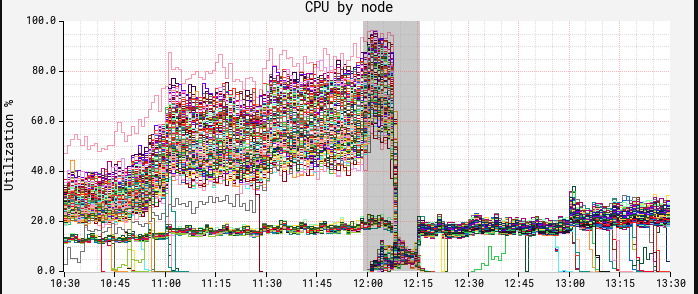
此時CPU和延遲展示了相似的曲線,慢波段節點消失不見。
True Sharing
隨著自動擴容達到CPU目標,但我們注意到單個節點仍然無法處理超過150RPS,而我們的目標是250RPS。針對補丁版本的JDK進行的又一輪vTune性能采樣,發現圍繞二級父類的緩存查找出現了瓶頸。在經過補丁之后又出現了相同的問題,一開始讓人感到困惑,但在仔細研究后發現,現在我們使用的是true sharing,與false sharing不同,兩個獨立的變量共享了一個cache line,true sharing指相同的變量會被多線程/core讀寫。這種情況下,CPU強制內存排序是導致速度減慢的原因。
我們推斷,消除false sharing并提高了總吞吐量會導致增加相同JVM父類緩存代碼路徑的執行次數。本質上,我們有更高的執行并發性,但由于CPU強制內存排序協議,導致父類緩存壓力過大。通常的解決方式是避免一起寫入相同的共享變量,這樣就可以有效地繞過JVM的輔助父類緩存。由于此變更改變了JDK的行為,因此我們使用了命令行標志,完整的補丁如下:
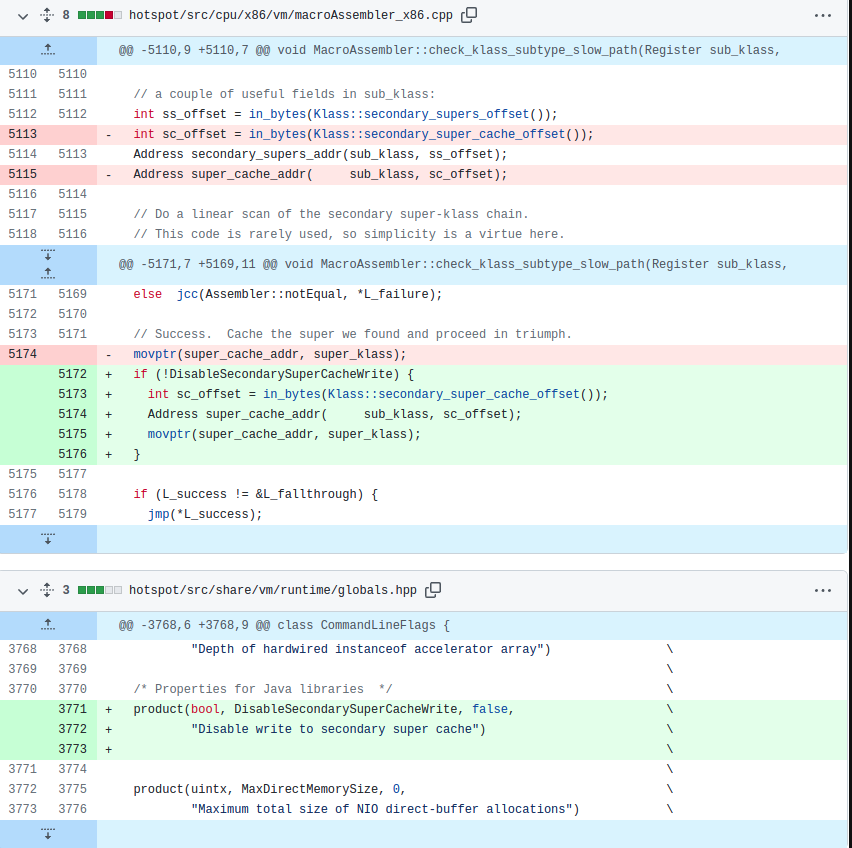
在禁用父類緩存寫操作之后的結果如下:
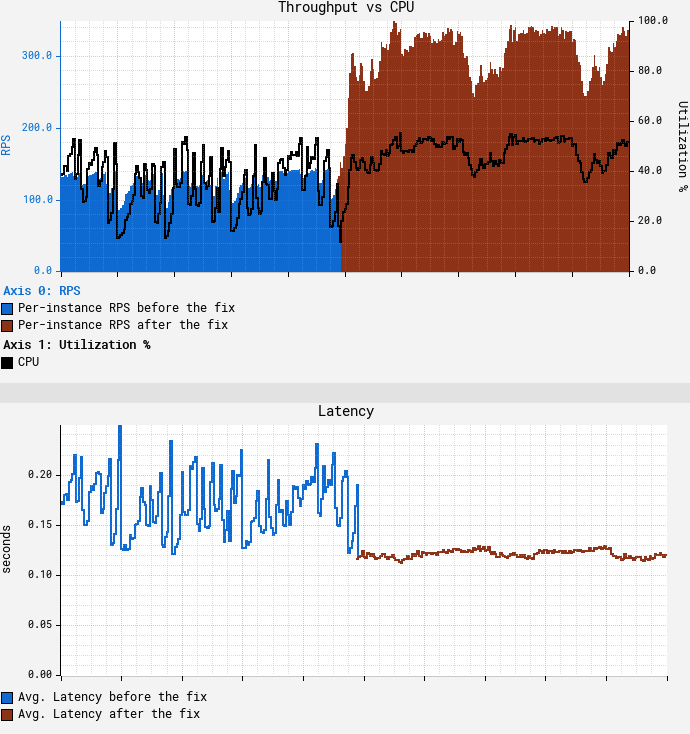
可以看到在CPU達到目標55%的情況下,吞吐量達到了350 RPS,是我們一開始使用m5.12xl的吞吐量的3.5倍,同時降低了平均和尾部延遲。
后續工作
在我們的場景下,禁用寫入二級父類緩存工作良好,雖然這并不一定適用于所有場景,但過程中使用到的方法,工具集可能會對遇到類似現象的人有所幫助。在處理該問題時,我們碰到了 JDK-8180450,這是一個5年前的bug,它所描述的問題和我們遇到的一模一樣。諷刺的是,在真正找到答案之前,我們并不能確定是這個bug。
總結
我們傾向于認為現在的JVM是一個高度優化的環境,在很多場景中展示出了類似C+++的性能。雖然對于大多數負載來說是正確的,但需要提醒的是,JVM中運行的特定負載可能不僅僅受應用代碼的設計和實現的影響,還會受到JVM自身的影響,本文中我們描述了如何利用PMC來發現JVM原生代碼的瓶頸,對其打補丁,并且隨后使負載的吞吐量提升了3倍以上。當遇到這類性能問題時,唯一的解決方案是在CPU微體系結構層面進行挖掘。intel vTune使用PMC提供了有價值的信息(如通過m5.12xl實例類型暴露出來的信息)。在云環境中跨所有實例類型和大小公開一組更全面的PMC和PEBS可以為更深入的性能分析鋪平道路,并可能獲得更大的性能收益。
審核編輯:劉清
-
PMC
+關注
關注
0文章
89瀏覽量
14886 -
JVM
+關注
關注
0文章
157瀏覽量
12209 -
RPSMA
+關注
關注
0文章
2瀏覽量
6168 -
AWS
+關注
關注
0文章
427瀏覽量
24315
原文標題:通過硬件計數器,將性能提升3倍之旅
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
jvm的類加載器的整體結構及過程解析
進擊的 Java ,云原生時代的蛻變
Jvm的整體結構和特點
為什么低代碼平臺都不采用原生代碼的方式
Java:JVM虛擬機的入門知識
如何解決JVM中一個極小概率發生的bug
JVM內存布局的多方面了解
JVM內存布局詳解
Spring干掉原生JVM?

jvm的dump太大了怎么分析
jvm內存分析命令和工具
jvm參數的設置和jvm調優
jvm運行時內存區域劃分
jvm和jmm的區別
聊聊JVM如何優化





 工商網監
工商網監
評論