 CPU緩存一致性原理
CPU緩存一致性原理
cpu速度和內存速度比值,目前比值是100:1的關系,一個做計算的,一個做存儲,相互之間怎么比速度?
這個速度是指:cpu內部的ALU計算單元訪問內部的寄存器,如果耗時是1個納秒,計算單元通過數據總線去訪問內存需要100納秒,這個速度是指訪問某個寄存器的速度并不是計算的速度,ALU訪問寄存器的速度比訪問內存的速度快100倍。
為什么ALU訪問寄存器的速度快,因為ALU和寄存器離的近。
內存中有一個數組,訪問數組中第一個元素數據需要100納秒,訪問第二個數據100納秒,所以cpu至少有99個時間單元都得等著從內存中返回數據給ALU使用。
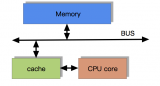
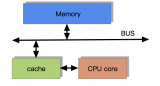
為了充分利用cpu的速度,一般往往在中間設計緩存的存在,cpu訪問緩存的速度比訪問內存的速度要快。
訪問數組中第一個數據的時候,把整個數組放到緩存中來,下次cpu訪問的時候從緩存中訪問。
不要內存完全可以,但工業上需要考慮一個性價比,數據都放在寄存器中太貴了,8個G的內存400塊錢,8個G的寄存器40萬,寄存器稍微貴一點點的、容量稍微小一點的還可以承受,比如8個G的內存,1個G的寄存器。
不是所有的數據都放在寄存器中,在這里有專門的算法LRU(Least Recently Used 淘汰最近未使用的)或LFU(least frequently used淘汰不經常使用的),這個算法決定著什么樣的數據挪過來,什么樣的數據挪出去。
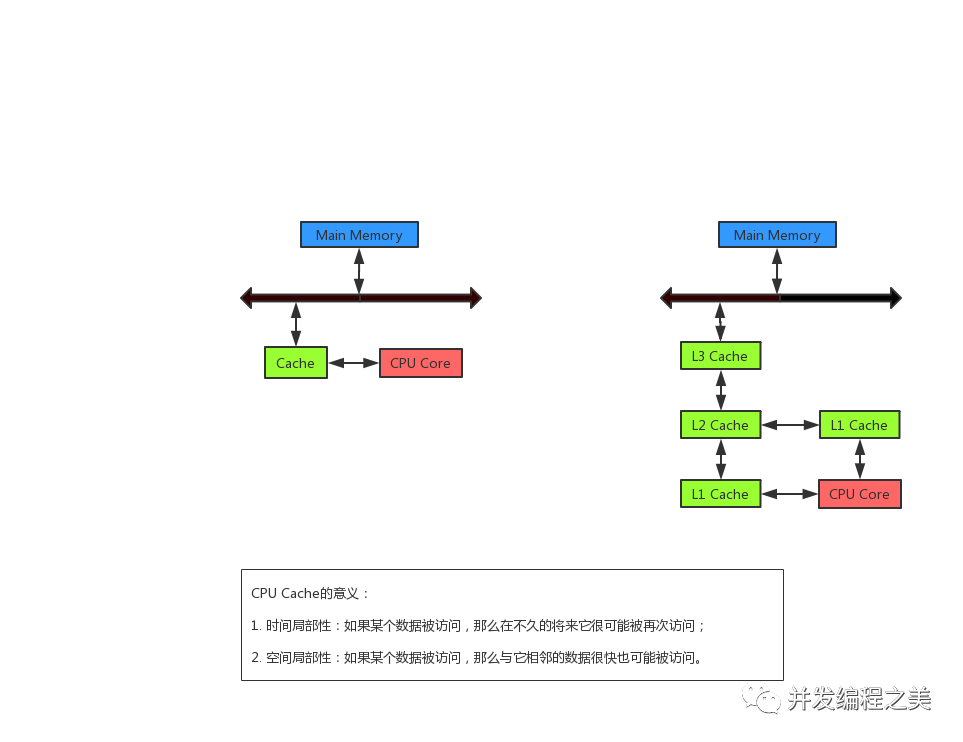
緩存是均衡的設計,在省錢和讀取、寫入的效率之間均衡。加了一層緩存之后,發現cpu到這個緩存之間的速度還是慢很多,再加一層,
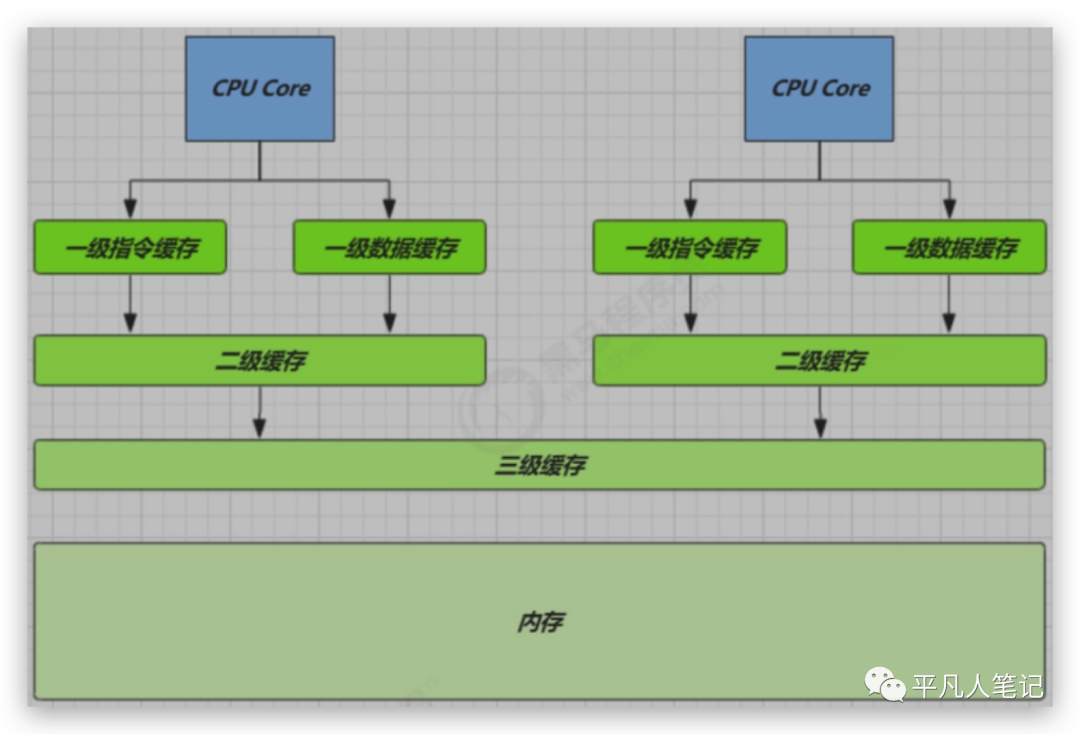
三級緩存是工業實現中的一個妥協,也許不久的將來,cpu的速度超級快,可能需要四層緩存或內存的速度快很多,也許就一層緩存,目前的工業實踐,多采用三級緩存的結構。
線程和cpu之間的關系密不可分,一顆cpu在同一個時間只能執行一個線程,cpu的計算也代表著線程的計算。
多核CPU
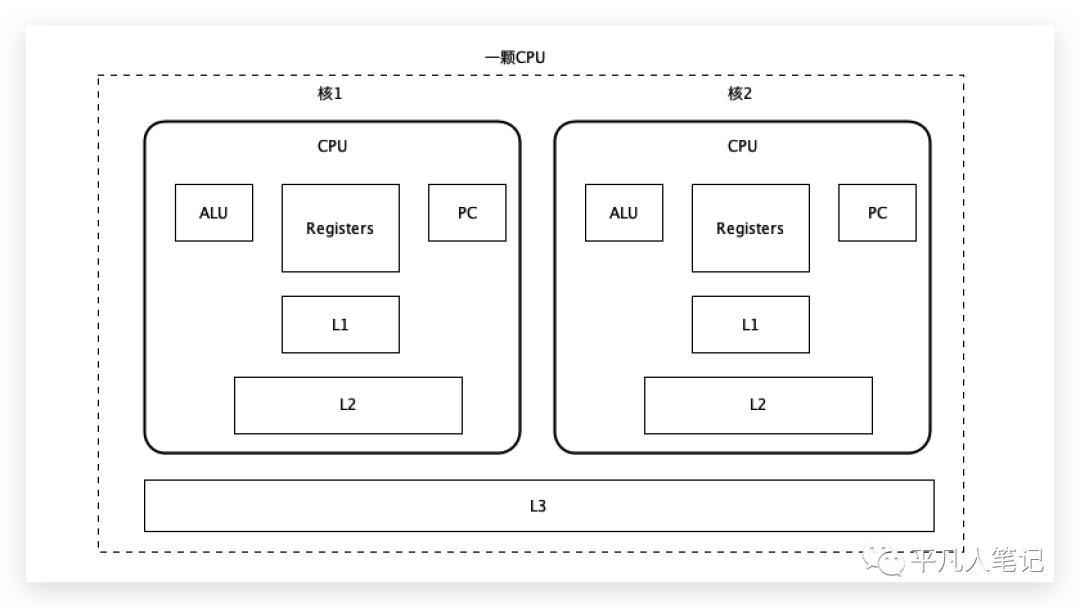
這是一顆cpu,在cpu內部往往有多個核存在,每一個核都有自己的ALU、寄存器、程序計數器,一級緩存和二級緩存都在這個核里,三級緩存是多個核共享。
ALU的計算單元需要把讀到的數據放到寄存器,寄存器會去尋找想要的數據,首先去一級緩存找,沒有的話,再去二級緩存找,還沒有的話,再去三級緩存找,三級緩存把數據傳給二級緩存,二級緩存把數據傳給一級緩存,一級緩存把數據傳給寄存器,下一次再訪問數據的時候直接去一級緩存中拿。
超線程
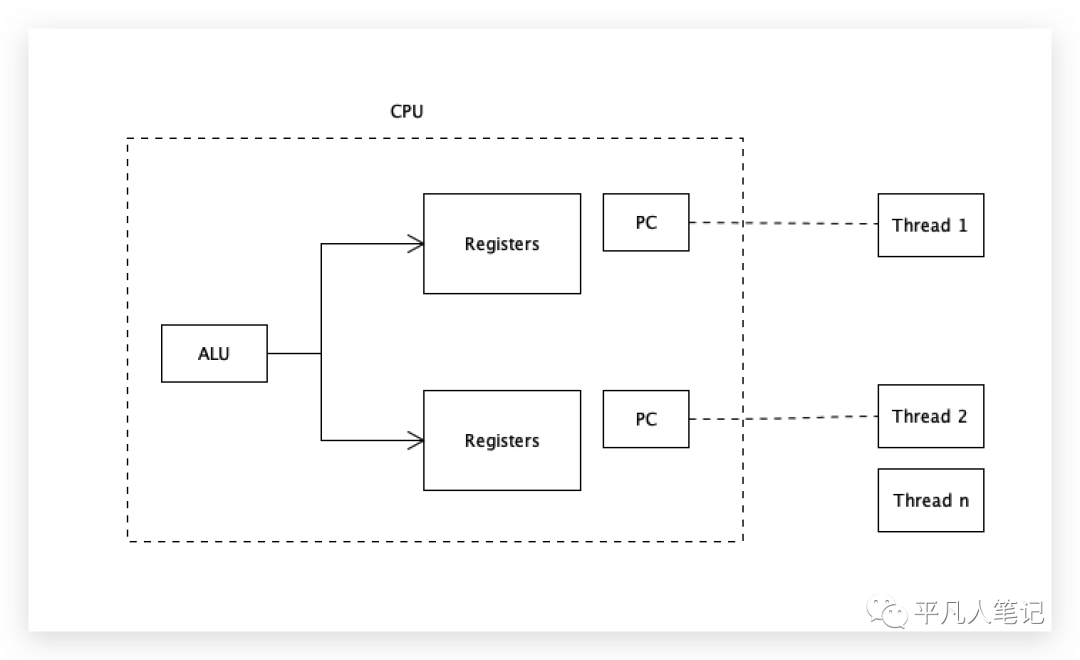
雖然只有一個計算單元ALU,但是有2套存儲單元、2套寄存器、2套程序計數器,一個核可以裝2個線程的數據進來,計算單元輪著計算,2個線程就不需要來回切換了,即一個核2個線程,2個核4個線程,4個核8個線程。
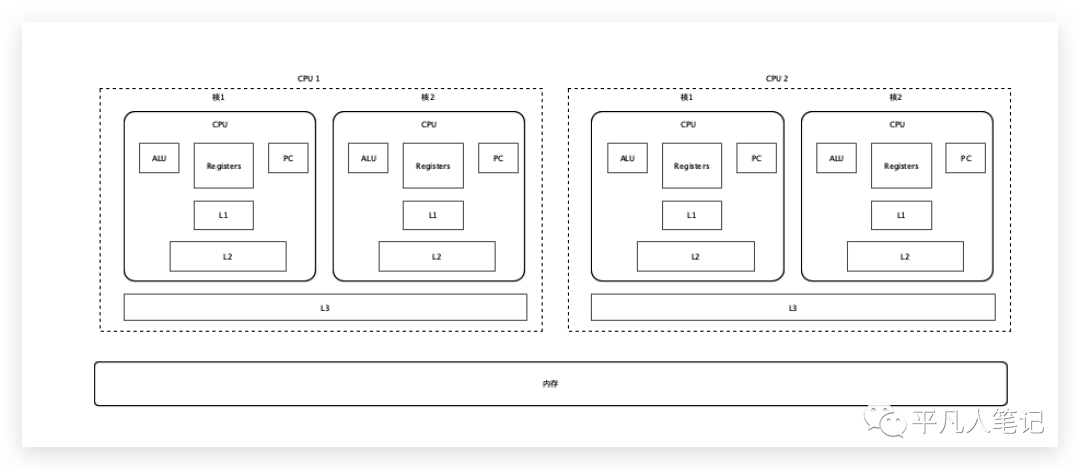
需要訪問內存中某個數組中的第一個元素數據,先在一級緩存找,再找二級、三級,都沒有的話,去內存中找,內存中找到之后,返回給三級緩存、二級緩存、一級緩存,最后再給到寄存器, ALU做計算的時候就可以直接訪問寄存器獲取數據了。
站在計算單元的角度,訪問數組中第一個元素數據很可能會訪問第二個元素數據,如果第二個元素數據也沒有,同樣的方式又得來一遍,那這樣的話還不如直接從內存讀呢!
緩存行
當要訪問一個數據的時候,干脆每一次緩存一小塊的數據,這一小塊數據里面包含了整個數組的數據,當訪問數組中的任意元素數據的時候,就可以直接從緩存中讀取到了,這一塊的數據被稱為緩存行。
這個理論被稱為程序的局部性原理,而局部性原理分為空間局部性和時間局部性。
根據大多數工業證明,在訪問局部數據的時候,會很快的訪問相鄰的數據,這就是空間局部性。
時間局部性是執行完這條指令之后,很可能執行和它挨著的下一條指令,如果指令也看做是一份二進制0101數據的話,也可以一次性的把很多指令讀取過來。
緩存行數據是大了好還是小了好?
如果這一行數據特別大,一次性可以放好多數據過來,好處就是訪問的時候命中率會更高,但是每讀一塊數據過來效率會很低;數據小的話,讀起來速度會很快但命中率會較低。
目前計算機多采用64個字節(64*8bit)為一緩存行數據。
緩存行對齊,偽共享
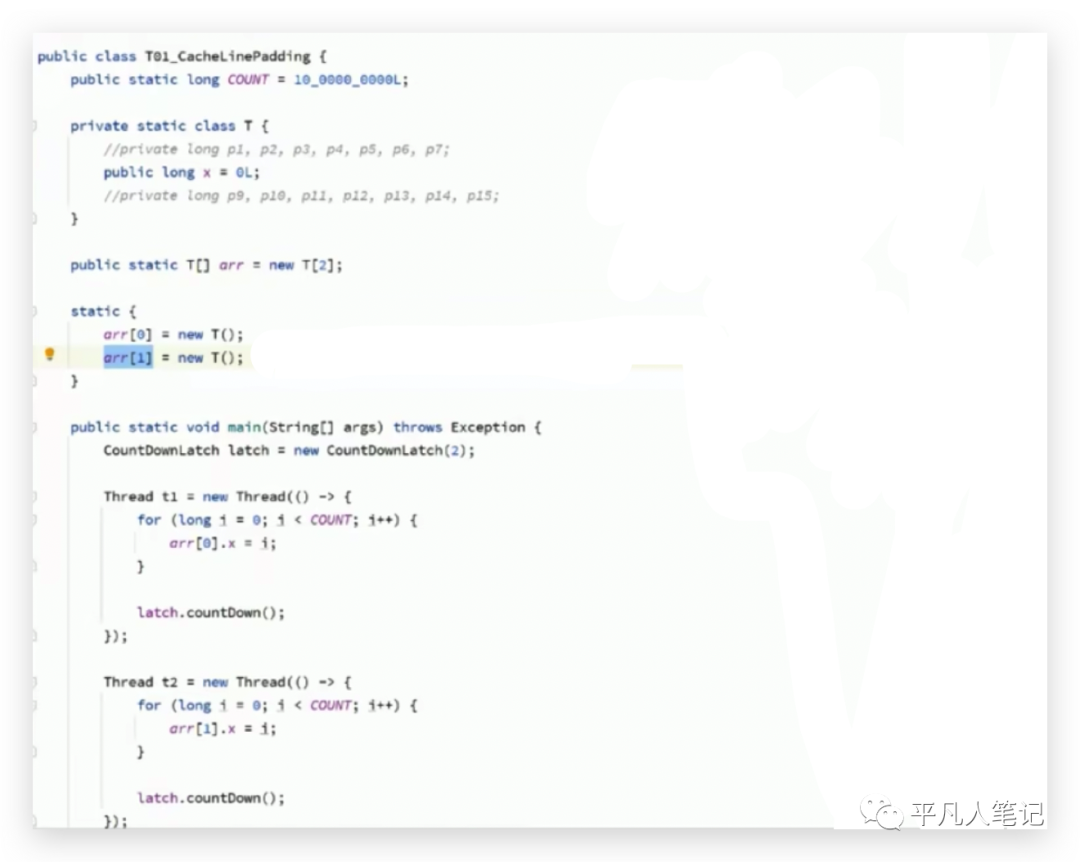
創建一個數組,里面存放了2個T類對象元素,T類中有一個long類型的x字段,long類型長度是8個bytes。
2個線程,意味著有2顆cpu在同時運行,第一個線程玩命的修改數組中的第一個元素t1,改了10億次,第二個線程玩命的修改數組中的第二個元素t2,也改了10億次,總共耗時700多毫秒。
對T類做了修改,
因為一個緩存行大小為64字節,所以在屬性x前面加了7個屬性(7*8字節=56個字節),加上x共64個字節,x后面也加了56個字節,正好將一個x值,放在一個緩存行里,計算結果耗時240多毫秒,數據越多執行效率反而越高了。在介紹原理之前,先介紹下緩存一致性協議,
緩存一致性協議
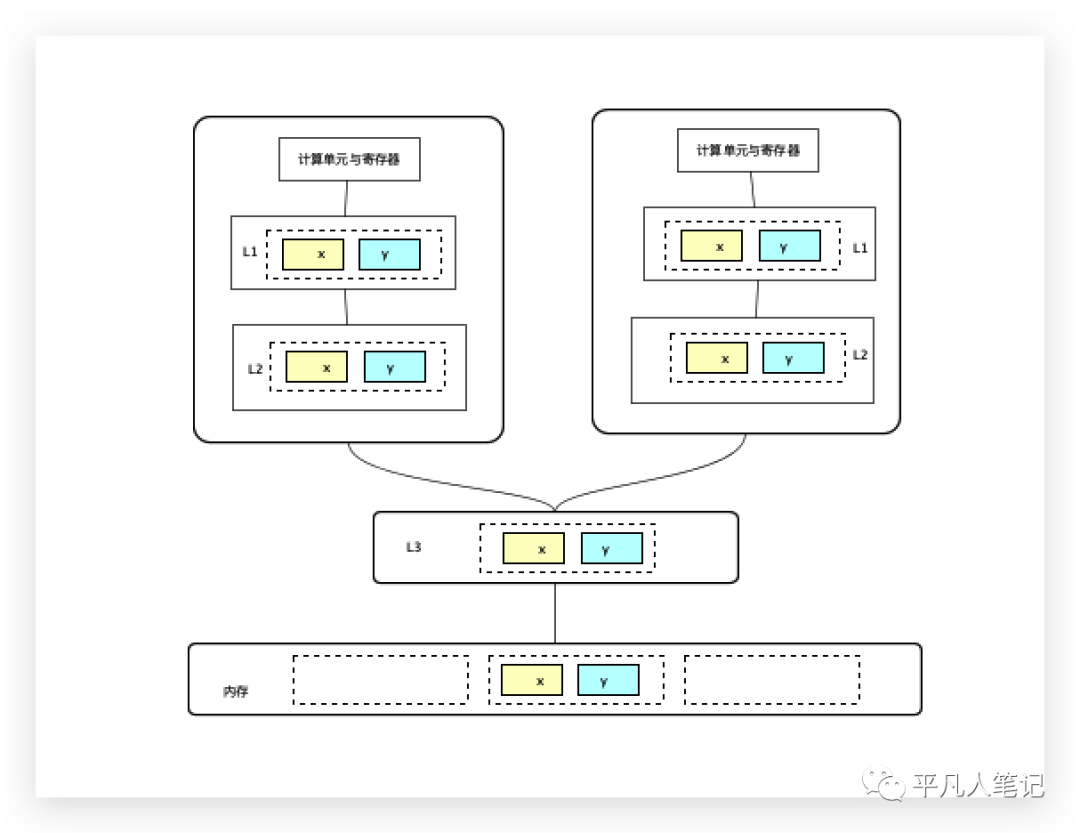
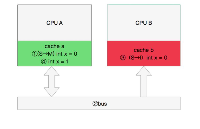
假設有2個數據x、y位于同一緩存行,在第一個計算單元(cpu或線程)里面只使用了x,第二個線程里面只使用了y,雖然在內存中是同一份數據,但是到緩存之后,是2份拷貝數據,每一個用到它的cpu都會有它的一份拷貝存在,一個cpu對這份數據做了修改之后,另外cpu也需要同步到最新的數據。
有了緩存的概念,必須要保證緩存的數據一致性即緩存一致性協議,每種cpu廠商都有自己完全不同的緩存一致性協議,常見的是MESI(因特爾的緩存一致性協議),這是緩存一致性協議的一種實現。
cpu每個緩存行標記有4種狀態:Modified(被修改),Exclusive(獨占)、Shared(共享)、Invalid(無效)。
一個cpu將一個緩存行中的數據修改了,需要一種機制:通知使用該緩存行的其他cpu數據已失效,需要重新再讀取一遍,獲取最新修改的數據。
有些無法被緩存的數據,比如一份的數據超過了64個字節,則需要使用總線鎖。
再回到上面的那個問題,為什么數據越多執行效率反而越高了?
一個long類型的x是8個字節,這2個x位于同一個緩存行的概率極大(尤其這2個x位于同一個數組,在內存中是挨著的),2個cpu分別修改一個x,2個x在一方cpu都有緩存,修改了其中一個需要通知另外一個,每改一次通知一下,總之在修改的時候需要觸發一種機制需要另外的cpu跟我保持一致,如果這樣的話,耗時當然會比較長。
在x前后加56個字節,無論怎么刷新緩存,這個x都不會和另外一個x位于同一緩存行,這意味著這個cpu修改了第一個x的時候,是不需要通知任何其他cpu的,第二個cpu修改第二個x的時候,也是不需要通知第一個cpu的,速度一定會很快。
jdk 7寫的LinkedBlockQueue也是這種寫法或者獲得杜克獎的開源軟件Disruptor中的環形隊列也是這種寫法,
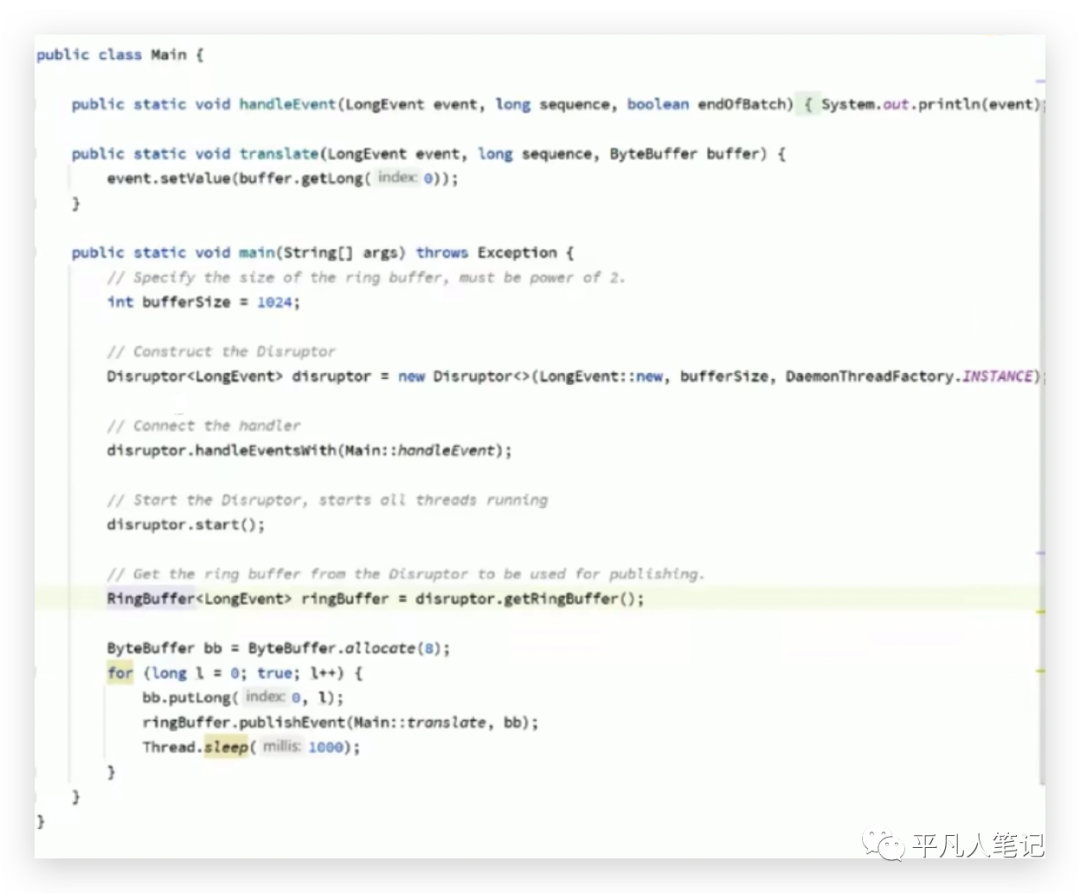
Disruptor(環形隊列)號稱是最快的單機mq;實現鏈表一般需要2個指針,一個是頭指針,一個是尾指針,而這個環形隊列,只要有一個指針就可以了,
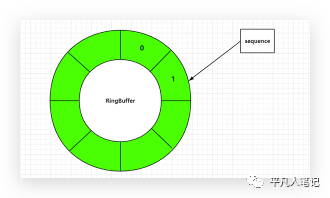
指針指向這個位置就往這存,指向下個位置就往下一個位置存,什么時候存滿了,就等著最開始存的那個被消費走,消費走了繼續往這里存,一個指針來回轉,速度非常快。
由于有多個生產者和多個消費者,在多線程的情況下這個環形的指針就會被多個線程讀到自己的緩存里,
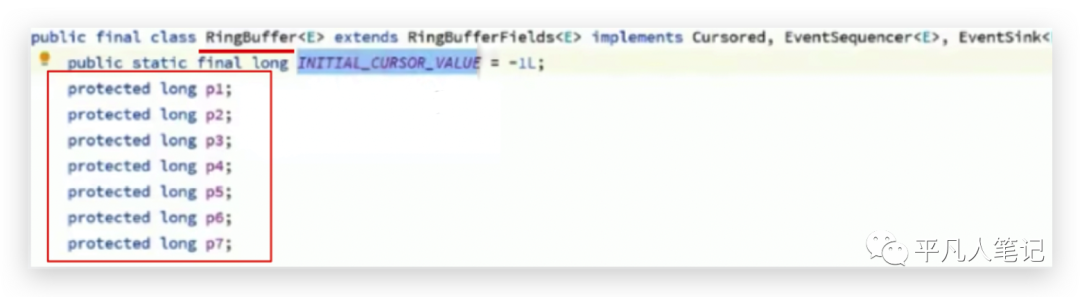
第一個屬性是起始值,后面是7個無業務含義的數據,其存在的目的是可以保證p1屬性往后組合的時候不會和別的p1屬性位于同一個緩存行。
但是說不準會往前面組合呢即為什么沒有前面的7個呢?也是有的,在父類的父類中定義的,
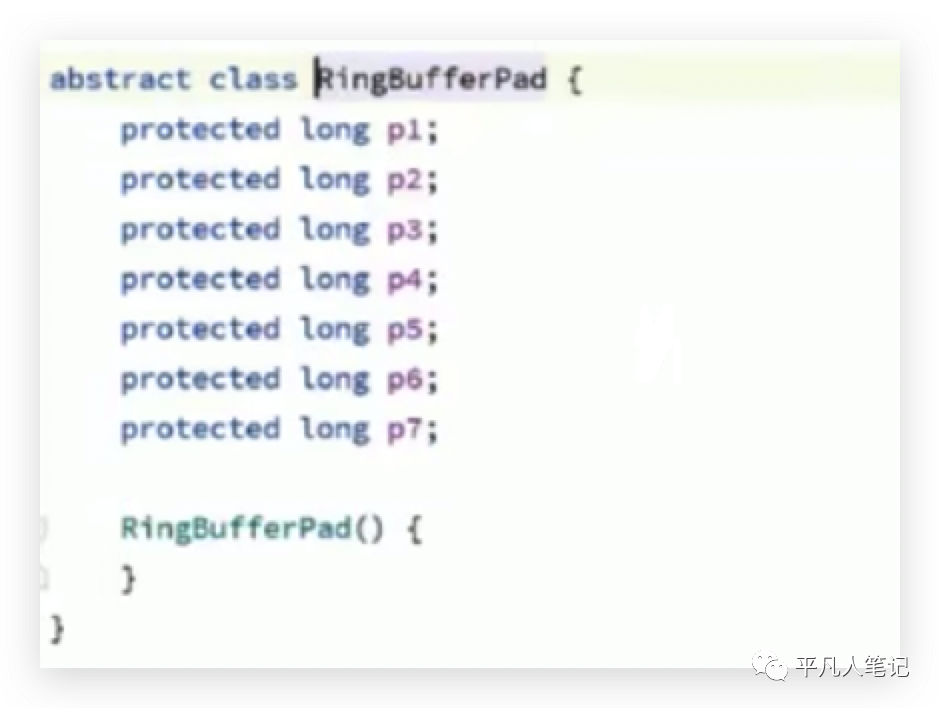

數組中前連續的2個元素是2個RingBuffer對象,一個對象所占用的字節57+8+56,所以可以確保一個緩存行中只有一個元素,那么在多線程的情況下對不同元素的修改不會互相通知,互相影響。
以上便是cpu級別的并發控制之緩存一致性的描述。
審核編輯:湯梓紅
-
寄存器
+關注
關注
31文章
5317瀏覽量
120010 -
cpu
+關注
關注
68文章
10825瀏覽量
211155 -
存儲
+關注
關注
13文章
4263瀏覽量
85675 -
緩存
+關注
關注
1文章
233瀏覽量
26649 -
線程
+關注
關注
0文章
504瀏覽量
19651
原文標題:CPU緩存一致性原理
文章出處:【微信號:IC學習,微信公眾號:IC學習】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何解決數據庫與緩存一致性


加速器一致性接口
Cache一致性協議優化研究
自主駕駛系統將使用緩存一致性互連IP和非一致性互連IP

CPU緩存一致性協議MESI詳解
CPU緩存一致性協議MESI介紹
介紹下cpu緩存一致性(MESI協議)


Redis緩存與Mysql如何保證一致性?

異構計算下緩存一致性的重要性





 工商網監
工商網監
評論