 微軟發布Visual ChatGPT:視覺模型加持ChatGPT實現絲滑聊天
微軟發布Visual ChatGPT:視覺模型加持ChatGPT實現絲滑聊天
近來,AI領域迎來各個領域的大突破,ChatGPT展現出強大的語言問答能力和推理能力,然而作為一個自然語言模型,它無法處理視覺信息。
與此同時,視覺基礎模型如Visual Transformer或者Stable Diffusion等,則展現出強大的視覺理解和生成能力。
Visual Transformer將ChatGPT作為邏輯處理中心,集成若干視覺基礎模型,從而達到如下效果:
視覺聊天系統Visual ChatGPT可以接收和發送文本和圖像
提供復雜的視覺問答,或者視覺編輯指令,可以通過多步推理調用工具來解決復雜視覺任務
可以提供反饋,總結答案,主動詢問模糊的指令等
這個工作開啟了ChatGPT借助視覺基礎模型作為工具,進行視覺任務處理的研究方向。
論文鏈接:
https://arxiv.org/abs/2303.04671
開源代碼:
https://github.com/microsoft/visual-chatgpt
論文作者:
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, Nan Duan
機構:微軟亞洲研究院
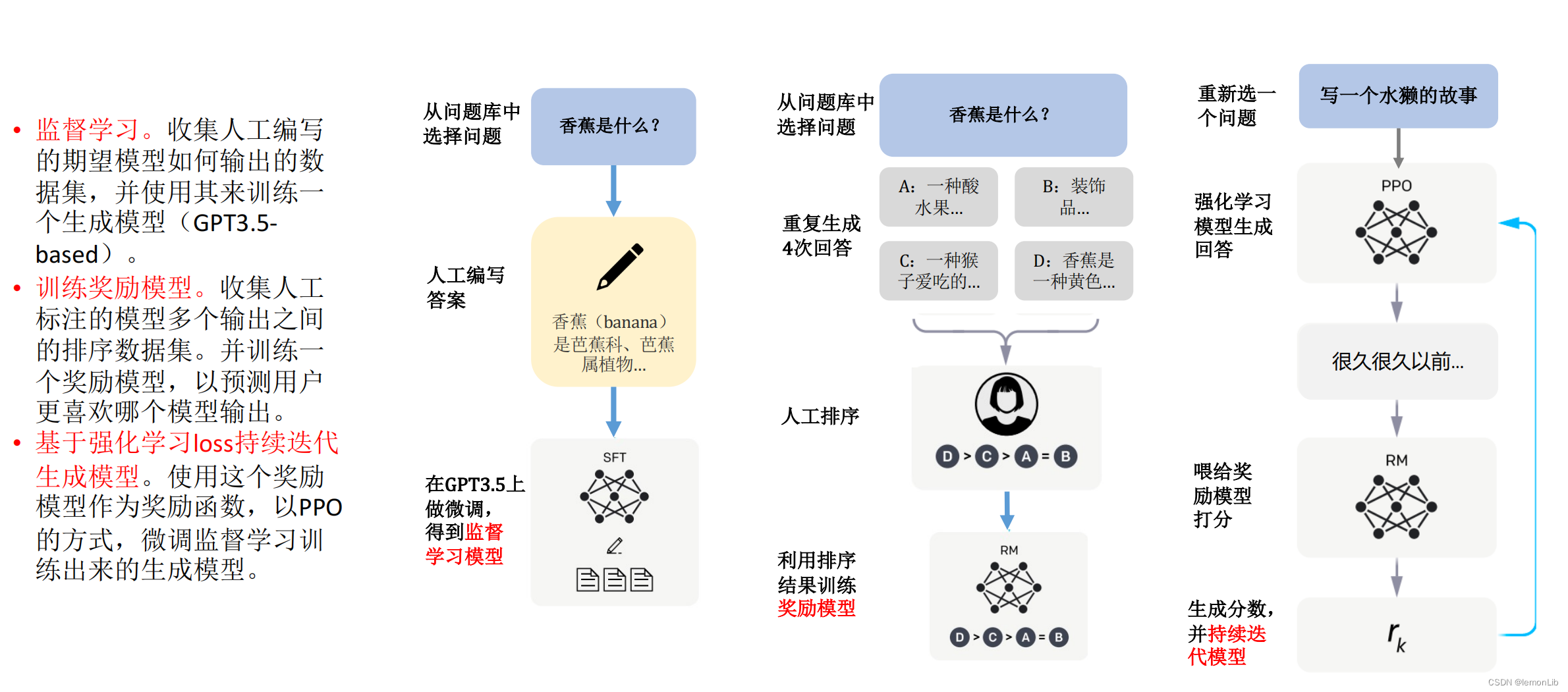
模型效果
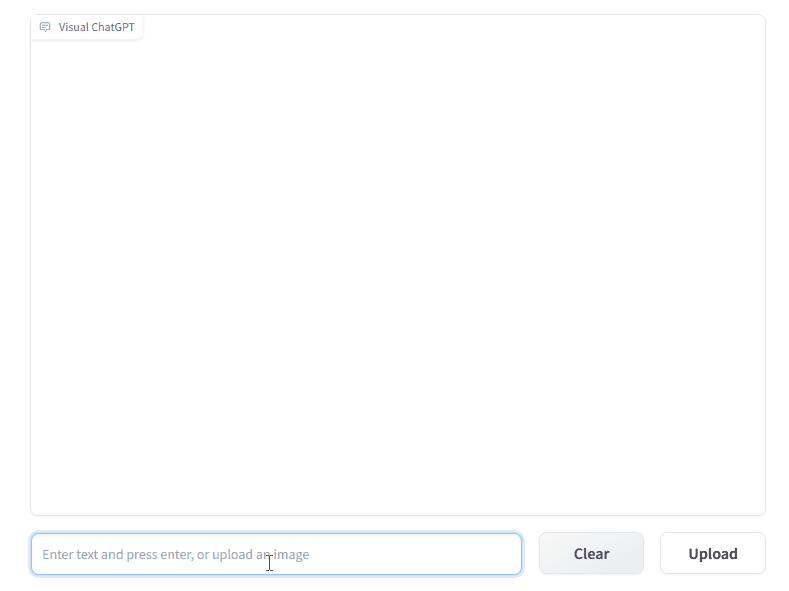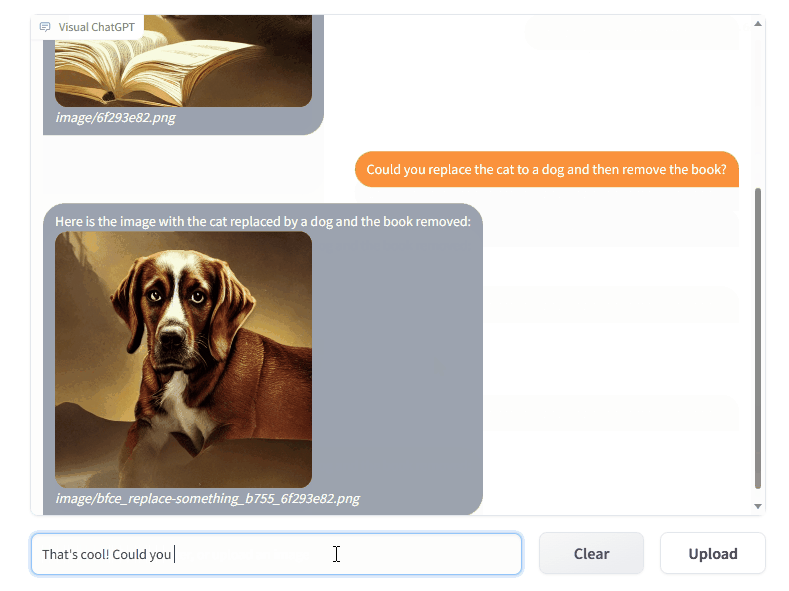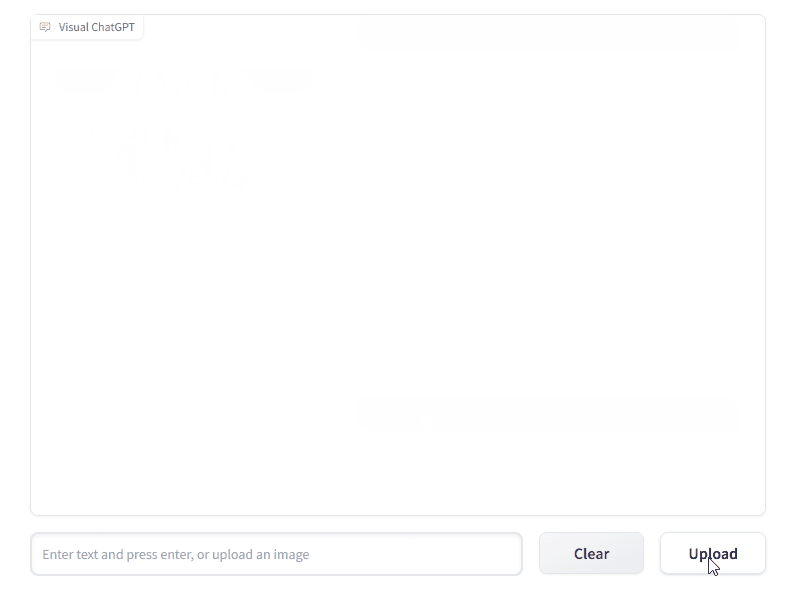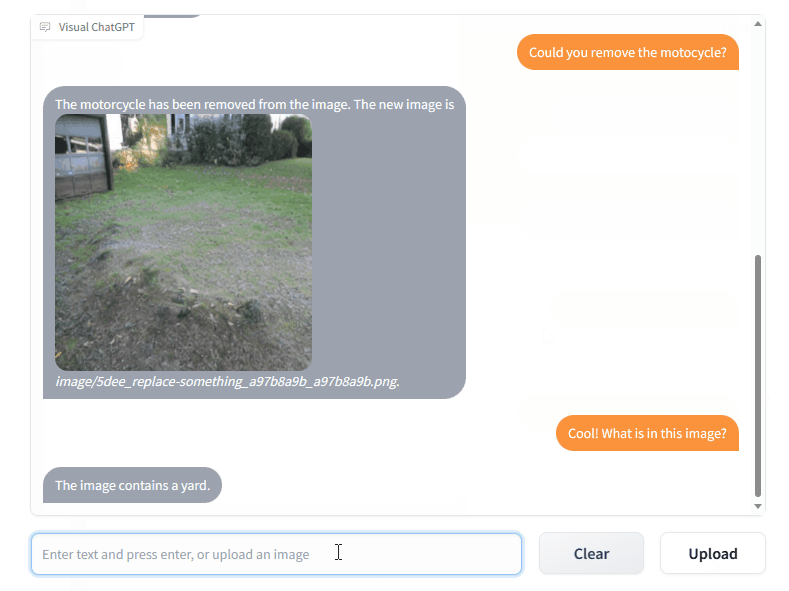
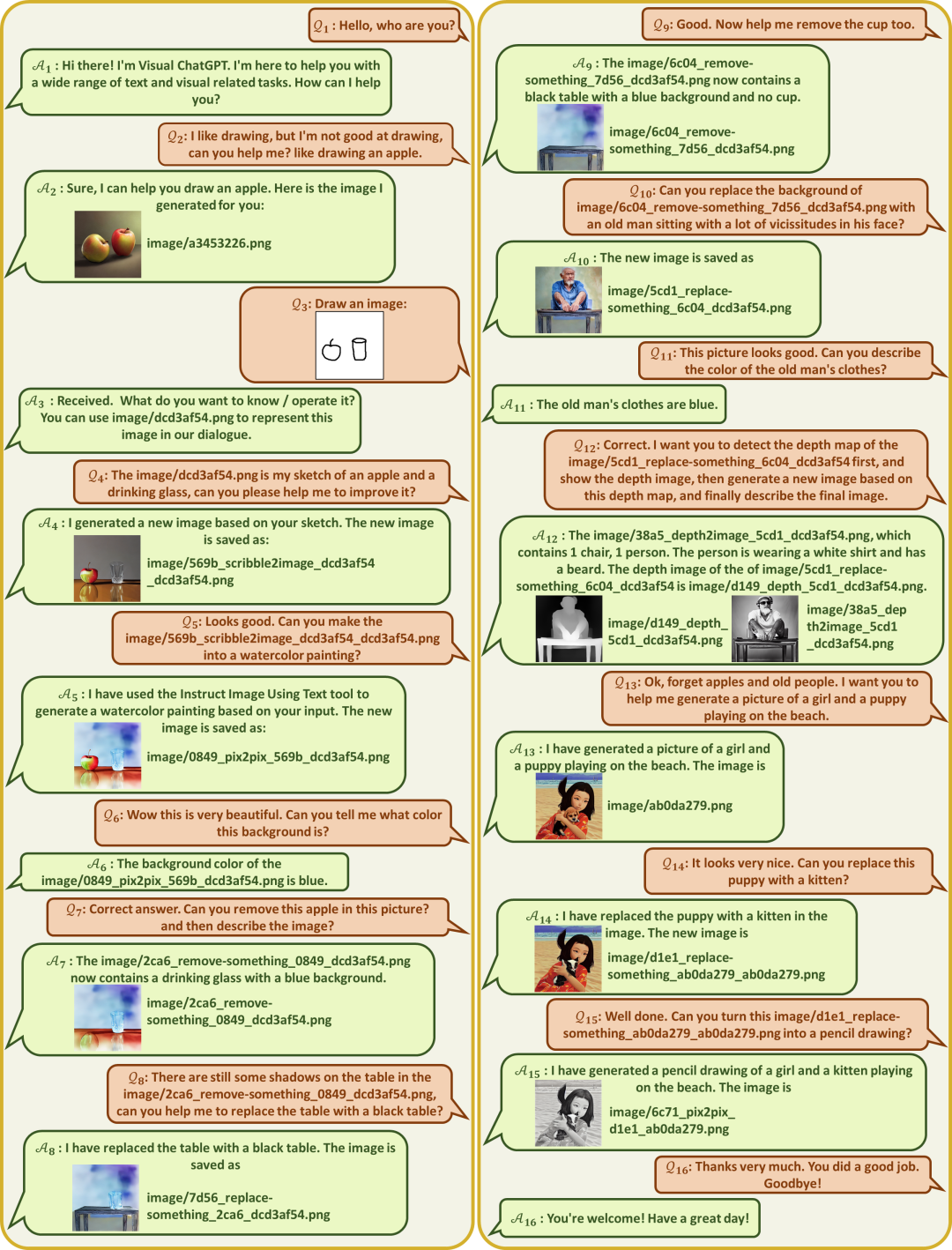
工作流程
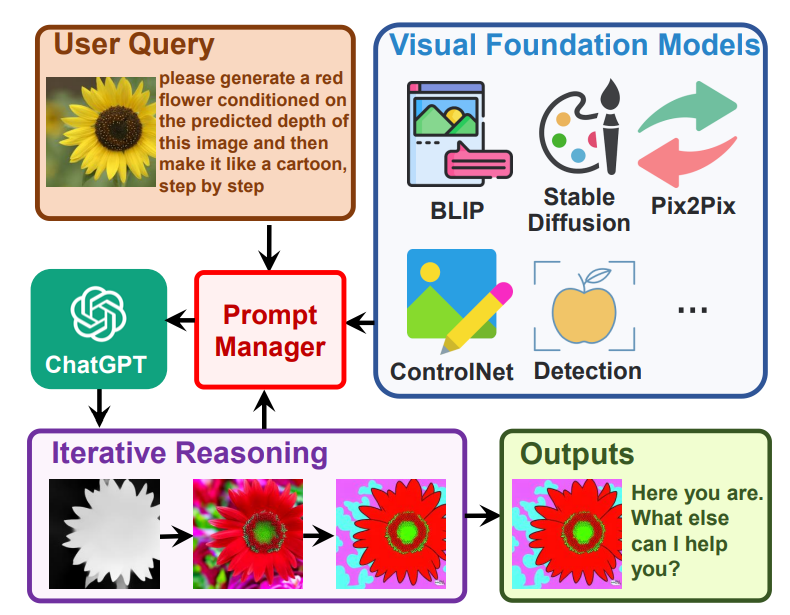
記對話,第i輪的回復,是通過若干次思考調用工具的結果來最終總結出來的。我們記第i輪對話中,第j次的工具調用中間答案記作,那么
其中,是全局原則,是各個視覺基礎模型,是歷史會話記憶,是這一輪的用戶輸入,是這輪對話里思考和的歷史,是中間答案,是prompt manager,用于把上面各個功能轉化成合理的文本prompt,從而可以交給ChatGPT進行處理。以下圖為例進行講解:
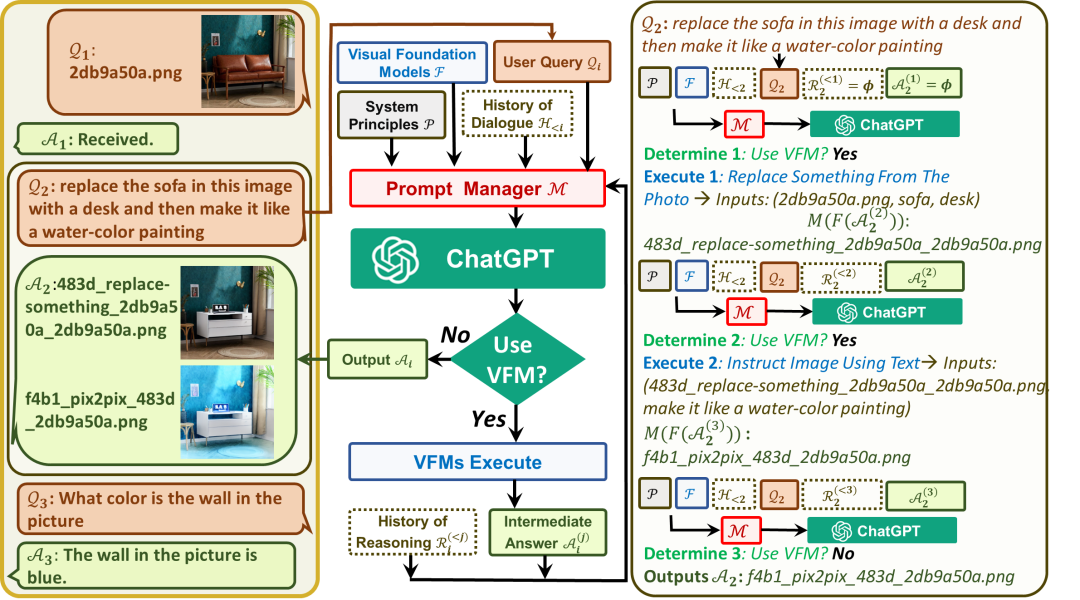
對于用戶輸入,添加于全局原則prompt,工具描述prompt,歷史會話prompt之后,送給ChatGPT進行邏輯推理(Use VFM?)得到推理結果(就是這一次得到的GPT文本輸出)。經過正則匹配進行分析,如果工具調用結束,則直接提取總結輸出作為最終回復,如果是需要繼續調用工具,則將提取到的工具名稱、工作參數,輸入視覺基礎模型,從而得到,置于思考歷史中,進行下一輪推理。或者說喂給GPT的內容為:
第一次問答里,第一個API:
第一次問答里,第二個API:
第一次問答里,第三個API:
第二次問答里,第一個API:
第二次問答里,第二個API:
得到GPT的輸出后,正則匹配進行工具的判斷和解析,最終決定流程。API調用歷史在每次回答后清空,其中只有最后總結性的回復被記錄進入對話歷史
細節描述
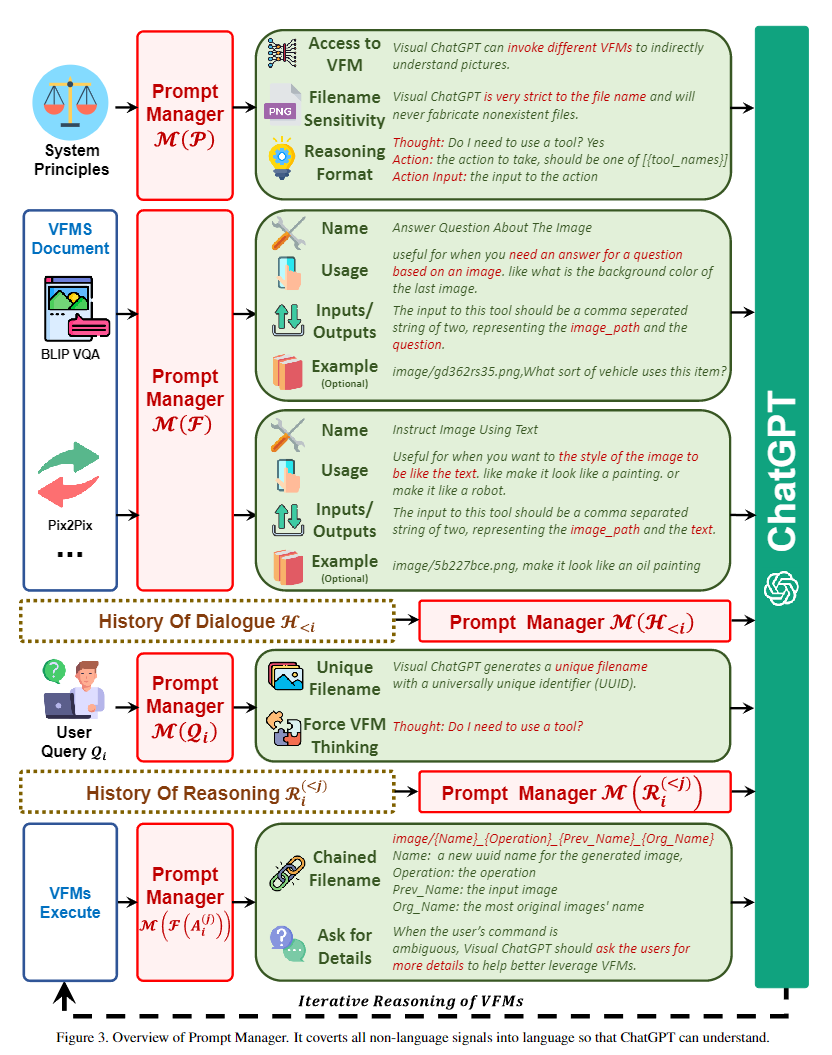
: 系統原則的提示符,“Visual ChatGPT是一個可以處理廣泛語言和視覺任務的助手,xxxxxx”。在這個prompt的部分,以下內容被強調:Visual ChatGPT的角色,可以訪問且需要盡可能使用視覺基礎模型,要對文件名稱非常敏感不可以捏造,可以且必須遵循嚴格的Chain-of-Thought思考鏈的格式進行思考(不然正則匹配不出來是否使用函數和函數名稱參數),可靠性等描述。
: 對每個視覺基礎模型的描述,包含工具名稱,使用方法,輸入輸出格式,實例
: 用戶的輸入會被改寫,用來理解圖片和強制GPT思考
:對輸出的處理,鏈式的文件命名,"imaga/{Name}_{Operation}_{Prev_Name}_{Org_Name}.png",強制修改GPT內容,讓GPT降低思考難度,在指代不清時二次詢問用戶等。
Case Study
論文分析了在各個模塊,如果prompt manager設計不到位,會各自出現什么問題:
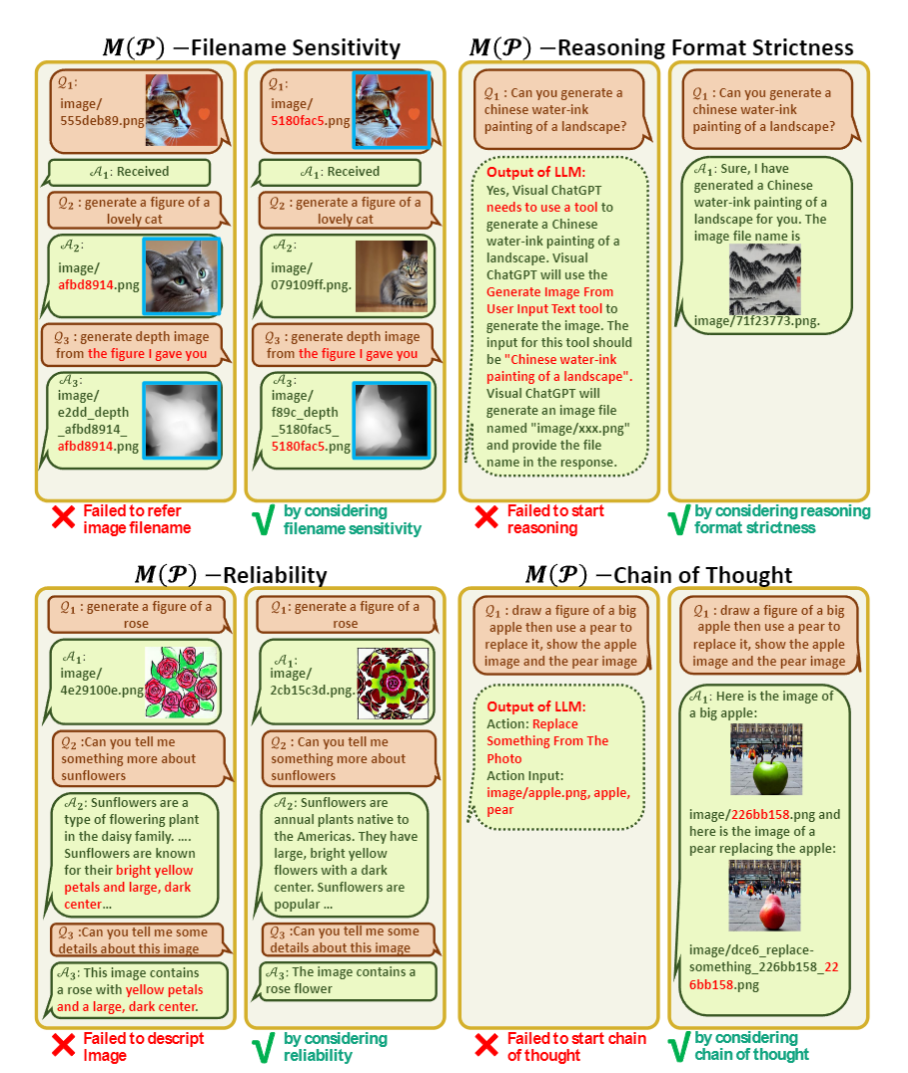
在中,如果不強調對圖片文件名的敏感,可能會發生指代錯誤。如果不強調思考鏈的格式嚴格,可能正則匹配匹不上。如果不強調可靠性,不要基于文本上下文腦補,可能會出現不讀圖片直接回答的情況。如果不強調可以鏈式使用工具,則可能出現一口吃個大胖子而不能一步一步思考的情況。
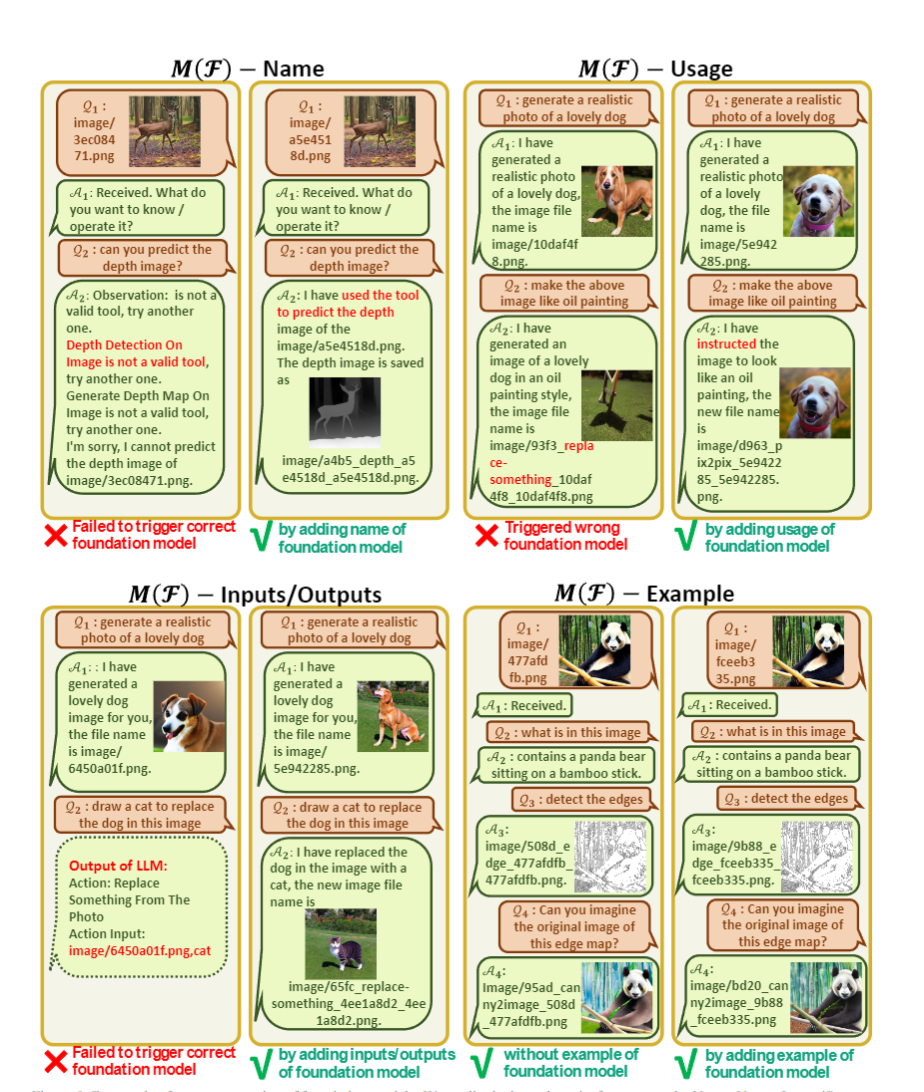
類似的,對于工具包的描述,也應該對名稱、功能、輸入輸出格式進行嚴格的設計。其中,for example進行舉例影響不大,只要前面描述足夠清楚,GPT可以理解,可以刪掉保存token長度。
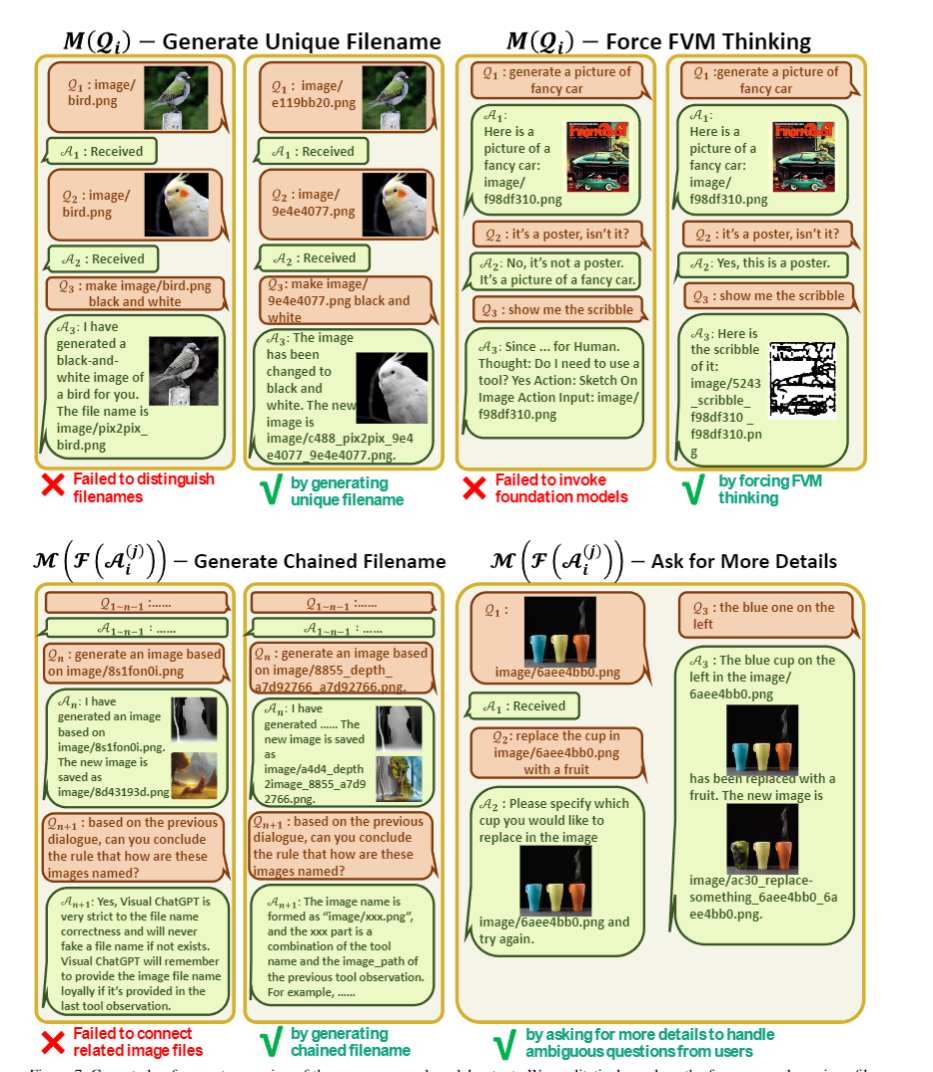
對于用戶輸入和工具包輸出的后處理,如圖。比較神奇的是,右上角的舉例里,用ChatGPT自己的口吻來說一些原則(從而讓ChatGPT以為是它自己說的,然后順著說),以及直接讓ChatGPT說到"Thought: Do I need a tool"繼續生成,能強制進入思考鏈,從而大幅度降低思考難度。左下角的舉例里,對于鏈式的文件命名,問Visual ChatGPT能不能總結出來文件命名原則,基本總結正確,這說明此種命名方法,確實可以幫助Visual ChatGPT理解文件的內容和依賴關系,生成路徑。
有意義的啟發
開啟了ChatGPT處理視覺任務的新大門
NLP --> Natural Language PhotoShop,自然語言文本描述下的圖片創作編輯和問答
可以通過系統設計和工具包設計的Prompt,做到無監督的工具調用,類似于zero-shot的toolformer
ChatGPT本身對仿真場景的能力很強,也讀過圖片路徑和函數關系,從而善于使用基礎視覺模型
Prompt很重要,作為純語言模型,前文說它是啥他就仿照啥,除了細致的要求,一定要多夸一夸他,是能力很強的處理模型,那它順著說,能力才會真的強
Visual ChatGPT本身是一個語言模型,所謂的兩方多輪對話只是一個Human: AI: 的多輪特殊形式前文的繼續生產,所以,完全可以強行給前文AI: 讓ai自己說一些東西出來,是它信了是它自己說的,這能夠極大的降低生成難度。這在本篇論文里對幾個場景的幫助很大。例如,用戶輸入圖片后,改寫為“Human: 上傳了一張圖片,描述為:{}。注意,這里的描述是幫助你理解圖片的,你不能基于它幻想而不調用工具。如果你理解了,就恢復收到。AI:收到。”注意,這里AI回復的收到,并不是真的GPT的生成內容,而是我們強行寫入進dialogue history memory的,而且可以發現,AI真的相信了。另外一個點是,在用戶的輸入后面,挨著的應該是GPT自己的思考內容,如果我們借它的口,自己說“推理信息僅自己可見,需要在最后總結的時候把重要信息復述給讀者”,效果比在最前文的prompt里效果好很多,可能是因為距離的原因,也可能是AI自己說出來的原因。另外,可以直接給到"Thought: do i need a tool?"去讓GPT繼續生成,從而一定進入推理鏈,可以匹配到遠處描述思維鏈格式的prompt內容,極大的降低思考難度。
外網評價



審核編輯 :李倩
-
微軟
+關注
關注
4文章
6572瀏覽量
103963 -
AI
+關注
關注
87文章
30239瀏覽量
268475 -
ChatGPT
+關注
關注
29文章
1549瀏覽量
7507
原文標題:微軟發布Visual ChatGPT:視覺模型加持ChatGPT實現絲滑聊天
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
怎樣搭建基于 ChatGPT 的聊天系統
ChatGPT 適合哪些行業
如何使用 ChatGPT 進行內容創作
華納云:ChatGPT 登陸 Windows
大模型LLM與ChatGPT的技術原理
llm模型和chatGPT的區別
使用espbox lite進行chatgpt_demo的燒錄報錯是什么原因?
OpenAI 深夜拋出王炸 “ChatGPT- 4o”, “她” 來了
【Longan Pi 3H 開發板試用連載體驗】給ChatGPT裝上眼睛,還可以語音對話
在FPGA設計中是否可以應用ChatGPT生成想要的程序呢
微軟和OpenAI面臨關于ChatGPT和Copilot的更多訴訟指控
【國產FPGA+OMAPL138開發板體驗】(原創)6.FPGA連接ChatGPT 4
OpenAI推出Vision Pro版ChatGPT
微軟推出Copilot安卓應用 類似ChatGPT功能
ChatGPT原理 ChatGPT模型訓練 chatgpt注冊流程相關簡介





 工商網監
工商網監
評論