 SpringBoot實現MySQL百萬級數據量導出并避免OOM的解決方案
SpringBoot實現MySQL百萬級數據量導出并避免OOM的解決方案
前言
動態數據導出是一般項目都會涉及到的功能。它的基本實現邏輯就是從mysql查詢數據,加載到內存,然后從內存創建excel或者csv,以流的形式響應給前端。
SpringBoot下載excel基本都是這么干。
雖然這是個可行的方案,然而一旦mysql數據量太大,達到十萬級,百萬級,千萬級,大規模數據加載到內存必然會引起OutofMemoryError。
要考慮如何避免OOM,一般有兩個方面的思路。
一方面就是盡量不做唄,先懟產品下面幾個問題啊:
- 我們為什么要導出這么多數據呢?誰傻到去看這么大的數據啊,這個設計是不是合理的呢?
- 怎么做好權限控制?百萬級數據導出你確定不會泄露商業機密?
- 如果要導出百萬級數據,那為什么不直接找大數據或者DBA來干呢?然后以郵件形式傳遞不行嗎?
- 為什么要通過后端的邏輯來實現,不考慮時間成本,流量成本嗎?
- 如果通過分頁導出,每次點擊按鈕只導2萬條,分批導出難道不能滿足業務需求嗎?
如果產品說 “甲方是爸爸,你去和甲方說啊”,“客戶說這個做出來,才考慮付尾款!”,如果客戶的確缺根筋要讓你這樣搞, 那就只能從技術上考慮如何實現了。
從技術上講,為了避免OOM,我們一定要注意一個原則:
不能將全量數據一次性加載到內存之中。
全量加載不可行,那我們的目標就是如何實現數據的分批加載了。實事上,Mysql本身支持Stream查詢,我們可以通過Stream流獲取數據,然后將數據逐條刷入到文件中,每次刷入文件后再從內存中移除這條數據,從而避免OOM。
由于采用了數據逐條刷入文件,而且數據量達到百萬級,所以文件格式就不要采用excel了,excel2007最大才支持104萬行的數據。這里推薦:
以csv代替excel。
考慮到當前SpringBoot持久層框架通常為JPA和mybatis,我們可以分別從這兩個框架實現百萬級數據導出的方案。
基于 Spring Boot + MyBatis Plus + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
- 項目地址:https://github.com/YunaiV/ruoyi-vue-pro
- 視頻教程:https://doc.iocoder.cn/video/
JPA實現百萬級數據導出
實現項目對應:
- https://github.com/knes1/todo
核心注解如下,需要加入到具體的Repository之上。方法的返回類型定義成Stream。Integer.MIN_VALUE告訴jdbc driver逐條返回數據。
@QueryHints(value=@QueryHint(name=HINT_FETCH_SIZE,value=""+Integer.MIN_VALUE))
@Query(value="selecttfromTodot")
StreamstreamAll() ;
此外還需要在Stream處理數據的方法之上添加@Transactional(readOnly = true),保證事物是只讀的。
同時需要注入javax.persistence.EntityManager,通過detach從內存中移除已經使用后的對象。
@RequestMapping(value="/todos.csv",method=RequestMethod.GET)
@Transactional(readOnly=true)
publicvoidexportTodosCSV(HttpServletResponseresponse){
response.addHeader("Content-Type","application/csv");
response.addHeader("Content-Disposition","attachment;filename=todos.csv");
response.setCharacterEncoding("UTF-8");
try(StreamtodoStream=todoRepository.streamAll()){
PrintWriterout=response.getWriter();
todoStream.forEach(rethrowConsumer(todo->{
Stringline=todoToCSV(todo);
out.write(line);
out.write("
");
entityManager.detach(todo);
}));
out.flush();
}catch(IOExceptione){
log.info("Exceptionoccurred"+e.getMessage(),e);
thrownewRuntimeException("Exceptionoccurredwhileexportingresults",e);
}
}
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
MyBatis實現百萬級數據導出
MyBatis實現逐條獲取數據,必須要自定義ResultHandler,然后在mapper.xml文件中,對應的select語句中添加fetchSize="-2147483648"。
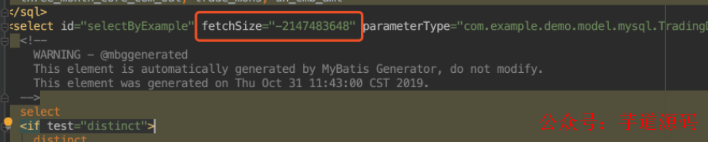
最后將自定義的ResultHandler傳給SqlSession來執行查詢,并將返回的結果進行處理。
MyBatis實現百萬級數據導出的具體實例
以下是基于MyBatis Stream導出的完整的工程樣例,我們將通過對比Stream文件導出和傳統方式導出的內存占用率的差異,來驗證Stream文件導出的有效性。
我們先定義一個工具類DownloadProcessor,它內部封裝一個HttpServletResponse對象,用來將對象寫入到csv。
publicclassDownloadProcessor{
privatefinalHttpServletResponseresponse;
publicDownloadProcessor(HttpServletResponseresponse){
this.response=response;
StringfileName=System.currentTimeMillis()+".csv";
this.response.addHeader("Content-Type","application/csv");
this.response.addHeader("Content-Disposition","attachment;filename="+fileName);
this.response.setCharacterEncoding("UTF-8");
}
publicvoidprocessData(Erecord){
try{
response.getWriter().write(record.toString());//如果是要寫入csv,需要重寫toString,屬性通過","分割
response.getWriter().write("
");
}catch(IOExceptione){
e.printStackTrace();
}
}
}
然后通過實現org.apache.ibatis.session.ResultHandler,自定義我們的ResultHandler,它用于獲取java對象,然后傳遞給上面的DownloadProcessor處理類進行寫文件操作:
publicclassCustomResultHandlerimplementsResultHandler{
privatefinalDownloadProcessordownloadProcessor;
publicCustomResultHandler(
DownloadProcessordownloadProcessor){
super();
this.downloadProcessor=downloadProcessor;
}
@Override
publicvoidhandleResult(ResultContextresultContext){
Authorsauthors=(Authors)resultContext.getResultObject();
downloadProcessor.processData(authors);
}
}
實體類:
publicclassAuthors{
privateIntegerid;
privateStringfirstName;
privateStringlastName;
privateStringemail;
privateDatebirthdate;
privateDateadded;
publicIntegergetId(){
returnid;
}
publicvoidsetId(Integerid){
this.id=id;
}
publicStringgetFirstName(){
returnfirstName;
}
publicvoidsetFirstName(StringfirstName){
this.firstName=firstName==null?null:firstName.trim();
}
publicStringgetLastName(){
returnlastName;
}
publicvoidsetLastName(StringlastName){
this.lastName=lastName==null?null:lastName.trim();
}
publicStringgetEmail(){
returnemail;
}
publicvoidsetEmail(Stringemail){
this.email=email==null?null:email.trim();
}
publicDategetBirthdate(){
returnbirthdate;
}
publicvoidsetBirthdate(Datebirthdate){
this.birthdate=birthdate;
}
publicDategetAdded(){
returnadded;
}
publicvoidsetAdded(Dateadded){
this.added=added;
}
@Override
publicStringtoString(){
returnthis.id+","+this.firstName+","+this.lastName+","+this.email+","+this.birthdate+","+this.added;
}
}
Mapper接口:
publicinterfaceAuthorsMapper{
ListselectByExample(AuthorsExampleexample) ;
ListstreamByExample(AuthorsExampleexample) ;//以stream形式從mysql獲取數據
}
Mapper xml文件核心片段,以下兩條select的唯一差異就是在stream獲取數據的方式中多了一條屬性: fetchSize="-2147483648"
<selectid="selectByExample"parameterType="com.alphathur.mysqlstreamingexport.domain.AuthorsExample"resultMap="BaseResultMap">
select
<iftest="distinct">
distinct
if>
'false'asQUERYID,
<includerefid="Base_Column_List"/>
fromauthors
<iftest="_parameter!=null">
<includerefid="Example_Where_Clause"/>
if>
<iftest="orderByClause!=null">
orderby${orderByClause}
if>
select>
<selectid="streamByExample"fetchSize="-2147483648"parameterType="com.alphathur.mysqlstreamingexport.domain.AuthorsExample"resultMap="BaseResultMap">
select
<iftest="distinct">
distinct
if>
'false'asQUERYID,
<includerefid="Base_Column_List"/>
fromauthors
<iftest="_parameter!=null">
<includerefid="Example_Where_Clause"/>
if>
<iftest="orderByClause!=null">
orderby${orderByClause}
if>
select>
獲取數據的核心service如下,由于只做個簡單演示,就懶得寫成接口了。其中 streamDownload 方法即為stream取數據寫文件的實現,它將以很低的內存占用從MySQL獲取數據;此外還提供traditionDownload方法,它是一種傳統的下載方式,批量獲取全部數據,然后將每個對象寫入文件。
@Service
publicclassAuthorsService{
privatefinalSqlSessionTemplatesqlSessionTemplate;
privatefinalAuthorsMapperauthorsMapper;
publicAuthorsService(SqlSessionTemplatesqlSessionTemplate,AuthorsMapperauthorsMapper){
this.sqlSessionTemplate=sqlSessionTemplate;
this.authorsMapper=authorsMapper;
}
/**
*stream讀數據寫文件方式
*@paramhttpServletResponse
*@throwsIOException
*/
publicvoidstreamDownload(HttpServletResponsehttpServletResponse)
throwsIOException{
AuthorsExampleauthorsExample=newAuthorsExample();
authorsExample.createCriteria();
HashMapparam=newHashMap<>();
param.put("oredCriteria",authorsExample.getOredCriteria());
param.put("orderByClause",authorsExample.getOrderByClause());
CustomResultHandlercustomResultHandler=newCustomResultHandler(newDownloadProcessor(httpServletResponse));
sqlSessionTemplate.select(
"com.alphathur.mysqlstreamingexport.mapper.AuthorsMapper.streamByExample",param,customResultHandler);
httpServletResponse.getWriter().flush();
httpServletResponse.getWriter().close();
}
/**
*傳統下載方式
*@paramhttpServletResponse
*@throwsIOException
*/
publicvoidtraditionDownload(HttpServletResponsehttpServletResponse)
throwsIOException{
AuthorsExampleauthorsExample=newAuthorsExample();
authorsExample.createCriteria();
Listauthors=authorsMapper.selectByExample(authorsExample);
DownloadProcessordownloadProcessor=newDownloadProcessor(httpServletResponse);
authors.forEach(downloadProcessor::processData);
httpServletResponse.getWriter().flush();
httpServletResponse.getWriter().close();
}
}
下載的入口controller:
@RestController
@RequestMapping("download")
publicclassHelloController{
privatefinalAuthorsServiceauthorsService;
publicHelloController(AuthorsServiceauthorsService){
this.authorsService=authorsService;
}
@GetMapping("streamDownload")
publicvoidstreamDownload(HttpServletResponseresponse)
throwsIOException{
authorsService.streamDownload(response);
}
@GetMapping("traditionDownload")
publicvoidtraditionDownload(HttpServletResponseresponse)
throwsIOException{
authorsService.traditionDownload(response);
}
}
實體類對應的表結構創建語句:
CREATETABLE`authors`(
`id`int(11)NOTNULLAUTO_INCREMENT,
`first_name`varchar(50)CHARACTERSETutf8COLLATEutf8_unicode_ciNOTNULL,
`last_name`varchar(50)CHARACTERSETutf8COLLATEutf8_unicode_ciNOTNULL,
`email`varchar(100)CHARACTERSETutf8COLLATEutf8_unicode_ciNOTNULL,
`birthdate`dateNOTNULL,
`added`timestampNOTNULLDEFAULTCURRENT_TIMESTAMP,
PRIMARYKEY(`id`)
)ENGINE=InnoDBAUTO_INCREMENT=10095DEFAULTCHARSET=utf8COLLATE=utf8_unicode_ci;
這里有個問題:如何短時間內創建大批量測試數據到MySQL呢?一種方式是使用存儲過程 + 大殺器 select insert 語句!不太懂?
沒關系,且看我另一篇文章 MySQL如何生成大批量測試數據 你就會明白了。如果你懶得看,我這里已經將生成的270多萬條測試數據上傳到網盤,你直接下載然后通過navicat導入就好了。
- 鏈接:https://pan.baidu.com/s/1hqnWU2JKlL4Tb9nWtJl4sw
- 提取碼:nrp0
有了測試數據,我們就可以直接測試了。先啟動項目,然后打開jdk bin目錄下的 jconsole.exe
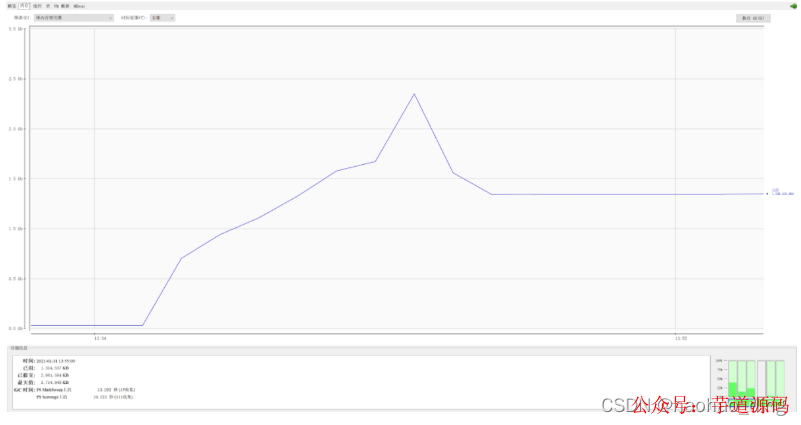
首先我們測試傳統方式下載文件的內存占用,直接瀏覽器訪問:http://localhost:8080/download/traditionDownload。
可以看出,下載開始前內存占用大概為幾十M,下載開始后內存占用急速上升,峰值達到接近2.5G,即使是下載完成,堆內存也維持一個較高的占用,這實在是太可怕了,如果生產環境敢這么搞,不出意外肯定內存溢出。
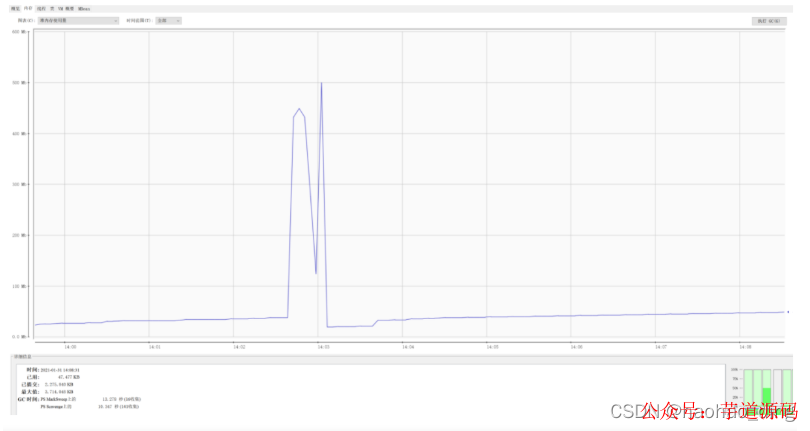
接著我們測試stream方式文件下載的內存占用,瀏覽器訪問:http://localhost:8080/download/streamDownload,當下載開始后,內存占用也會有一個明顯的上升,但是峰值才到500M。對比于上面的方式,內存占用率足足降低了80%!怎么樣,興奮了嗎!
我們再通過記事本打開下載后的兩個文件,發現內容沒有缺斤少兩,都是2727127行,完美!
審核編輯 :李倩
-
框架
+關注
關注
0文章
399瀏覽量
17435 -
spring
+關注
關注
0文章
338瀏覽量
14311 -
MySQL
+關注
關注
1文章
802瀏覽量
26445 -
SpringBoot
+關注
關注
0文章
173瀏覽量
169
原文標題:SpringBoot 實現 MySQL 百萬級數據量導出并避免 OOM 的解決方案
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
百萬級別excel導出功能如何實現
無人機系統發展趨勢與解決方案最新集錦
mysql數據導出golang實現
數據量大也不卡的bi軟件有哪些?
B+樹索引如何對Mysql單表數據量造成影響

如何優化MySQL百萬數據的深分頁問題
百萬數據的導入導出解決方案
SpringBoot實現Excel導入導出,百萬數據量,性能爆表!
實現MySQL與elasticsearch數據同步的方法
excel導出功能如何實現?





 工商網監
工商網監
評論