 探討GAN背后的數學原理(下)
探討GAN背后的數學原理(下)
2.2 判別器:有問題?GAN來了!
GAN由生成器G和判別器D組成。
其實上面我們已經基本介紹了生成器G的由來了,并且我們遇到了一個問題: 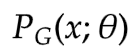 極其復雜的計算方式導致使用極大似然估計根本無從下手啊!!!
極其復雜的計算方式導致使用極大似然估計根本無從下手啊!!!
為了解決這個問題,我們引入了判別器D!
現在GAN的結構就完備了!!
對于生成器G:
-
G 是一個函數,輸入
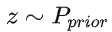 ,輸出(上面已經介紹了)
,輸出(上面已經介紹了)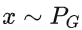
-
先驗分布
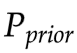 , 和G共同決定的分布
, 和G共同決定的分布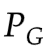
對于判別器D:
- D是一個函數,輸入,輸出一個scalar
- D用于評估和
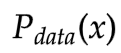 之間的差異(解決上一小節提出的問題)
之間的差異(解決上一小節提出的問題)
那么,GAN的最終目標-->用符號化語言表示就是:

我們的目標是得到使得式子 最小的生成器
最小的生成器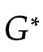 .
.
關于V:
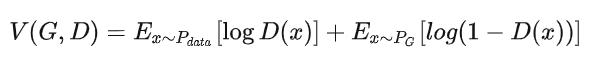
給定G,
衡量的就是分布
的差異。
因此,
也就是我們需要的使得差異最小的 G .
詳細解釋 V(G,D) :
對于:
固定G ,最優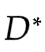 最大化:
最大化:

假設D(x) 可以表達任何函數
此時再固定 x ,則對于 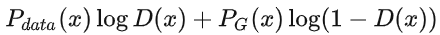 ,我們可將其看成是關于D的函數:
,我們可將其看成是關于D的函數: 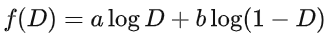

解得

即:

則此時對于原式 V(G,D) (將代入):
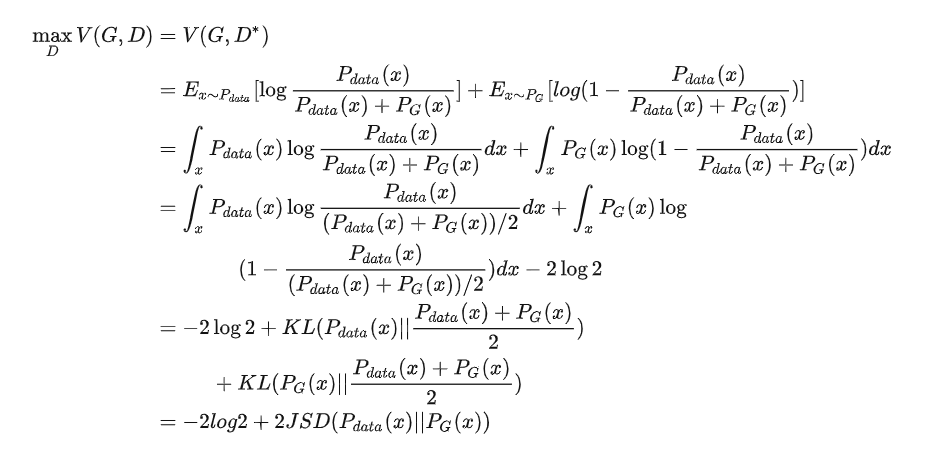
JSD表示JS散度,它是KL散度的一種變形,也表示兩個分布之間的差異:
與KL散度不同,JS散度是對稱的。
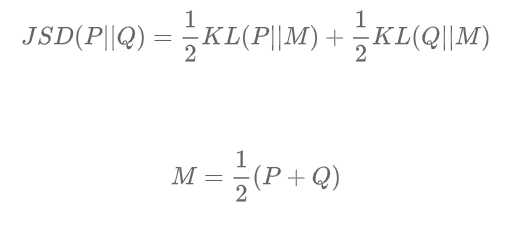
以上的公式推導,證明了確實是衡量了 和 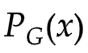 之間的差異。
之間的差異。
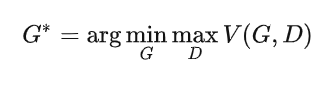
此時,最優的G:
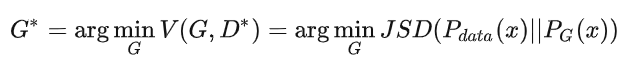
也就是使得 最小的G
最小的G
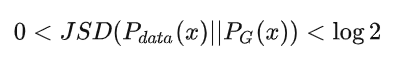
當 時,表示兩個分布完全相同。
時,表示兩個分布完全相同。
對于 ,令
,令 
我們該如何優化從而獲得呢???
我們希望通過最小化損失函數L(G) ,找到最優的G。
這一步可以通過梯度下降實現:

具體算法參考:
第一代:
- 給定
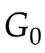 (隨機初始化)
(隨機初始化)
-
確定
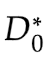 使得 V(,D) 最大。此時 V(,) 表示和
使得 V(,D) 最大。此時 V(,) 表示和 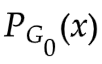 的JS散度
的JS散度 -
梯度下降:
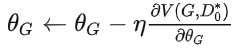 .得到
.得到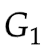
第二代:
- 給定
-
確定
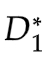 使得V(,D) 最大。此時V(,)表示和
使得V(,D) 最大。此時V(,)表示和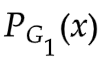 的JS散度
的JS散度 -
梯度下降:
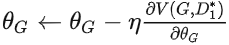 .得到
.得到
。。。
后面的依此類推
以上算法有一個問題: 如何確定使得 V (D ,G**)**** 最大???**
也就是:給定 G,如何計算 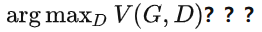
回答:
從采樣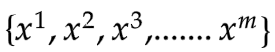
從采樣
因此我們可以將 從期望值計算改寫為對樣本計算(近似估計):
從期望值計算改寫為對樣本計算(近似估計):

這很自然地讓我們想到二分類問題中常使用的交叉熵loss
因此,我們不妨聯想:
D是一個二分類器,參數是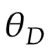
來自的采樣作為正樣本
來自的采樣作為負樣本
那么此時,我們就將問題轉化成了一個二分類問題:
交叉熵loss大 -->和 JS散度小
交叉熵loss小 -->和 JS散度大
此時,D就是可以使用一個神經網絡作為二分類器,那么確定D,也就是可以使用梯度下降來優化獲得D的最終參數。
GAN的最終算法流程:
初始化參數(for D)和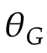 (for G)
(for G)
對于訓練的每一輪:
第一部分 學習優化判別器D:
-
從
采樣 -
從
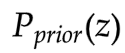 采樣
采樣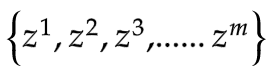
-
通過生成器
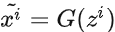 獲得生成樣本
獲得生成樣本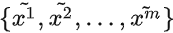
-
梯度下降更新
來最大化 :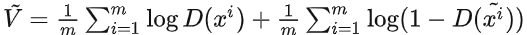 :
: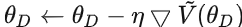
注:以上第一部分可以重復多次:此過程本質上是在測量兩分布之間的JS散度
第二部分 學習優化生成器G:
- 再從采樣另一組
- 梯度下降更新來最小化 :
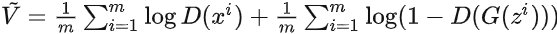 :
: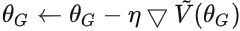 .實際上
.實際上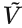 第一項與G無關,梯度下降只需最小化
第一項與G無關,梯度下降只需最小化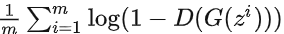 即可。
即可。
注:以上過程僅一次
最后的話:
其實在GAN之前,就已經有Auto-Encoder,VAE這樣的方法來使用神經網絡做生成式任務了。
GAN的最大的創新就是在于非常精妙地引入了判別器,從樣本的維度解決了衡量兩個分布差異的問題。
這種生成器和判別器對抗學習的模式,也必將在各種生成式任務中發揮其巨大的威力。
-
GaN
+關注
關注
19文章
1918瀏覽量
72979 -
生成器
+關注
關注
7文章
313瀏覽量
20976 -
深度學習
+關注
關注
73文章
5492瀏覽量
120975
發布評論請先 登錄
相關推薦
你知道XGBoost背后的數學原理是什么嗎?
基于GaN的開關器件
如何精確高效的完成GaN PA中的I-V曲線設計?
如何使用LL庫給MCU頻率F每T秒使用定時器更新事件生成一個中斷?
計算機代數系統數學原理
圖解:卷積神經網絡數學原理解析
詳解圖神經網絡的數學原理3
探討GAN背后的數學原理(上)
背后的數學原理在應用中得到驗證





 工商網監
工商網監
評論