 Jack Dongarra:高性能計算及其未來需求
Jack Dongarra:高性能計算及其未來需求
當前超級計算機主要通過LINPACK測試性能并形成TOP500排行榜,隨著人工智能等應用的流行,新的基準測試正顯得愈發重要。未來,數據移動將成為越來越重要的因素。
超級計算機的主要特點
傳統的科學和工程通常是通過理論和實驗完成的。一方面,我們通過觀察周圍的事物,使用紙和筆推導計算形成理論;另一方面,我們通過大量實驗驗證理論。當然,實驗有時會改進甚至改變理論。然而,這兩種科研范式都有其局限性:要么太困難(例如建造大型風洞),要么太昂貴(例如進行引擎鳥擊實驗),要么太緩慢(例如分析氣候變化、星系碰撞),要么太危險(例如設計武器和藥物)。計算機為科學研究提供了第三種范式,即基于物理規律和數值計算的方法,利用模擬仿真研究這些困難的問題。為此,我們需要運算速度快的超級計算機來實現高精度和高保真的模擬仿真。
如今,超級計算機普遍是由商用而非專用零部件制造而成的。我們把多個處理器核心封裝在一起做成通用的CPU,這些CPU組成了超級計算機的節點。當我們希望提高計算能力和計算速度時,可以把GPU放在CPU旁邊,利用GPU提高超級計算機的性能。多個這樣的節點裝在一個機柜里,然后在大房間(目前最快的超級計算機占地約為2個網球場大)里裝滿這樣的機柜,再通過網絡把這些節點連起來,就組成了一臺超級計算機。
當今的超級計算機主要具備以下四個特點:
1.高度并行化。超級計算機是高度并行化的系統,內存也是分布式的。在這樣的系統上,我們通常基于消息傳遞接口(Message Passing Interface,MPI)和OpenMP的編程模型做開發。
2.異構性。超算排行榜上速度最快的計算機的算力由CPU和GPU共同提供,這就是我們所說的異構性。3.數據傳輸代價高。在超級計算機上,與數值計算相比,數據在各處傳輸的代價十分高昂。4.多樣的浮點數支持。主流的計算機大都支持64位(雙精度)、32位(單精度)和16位(半精度)浮點運算,目前一些計算機也支持8位浮點數。這些支持較低精度浮點數的計算機主要用于機器學習。 當我們評價世界上最快的超級計算機時,會使用ExaFLOP來衡量。ExaFLOP是什么呢?一個FLOP指的是完成一次浮點數(通常為64位)加法或乘法運算,因此一個ExaFLOP,或者簡稱為EFLOP,就是指完成一百億億(1018)次浮點數運算。假設我們讓地球上所有人每秒鐘做一次計算,那么完成一個ExaFLOP需要4年時間,而如果讓目前最好的超級計算機做,只需要一秒鐘,我們把這樣的計算機叫做E級計算機。
LINPACK與TOP500
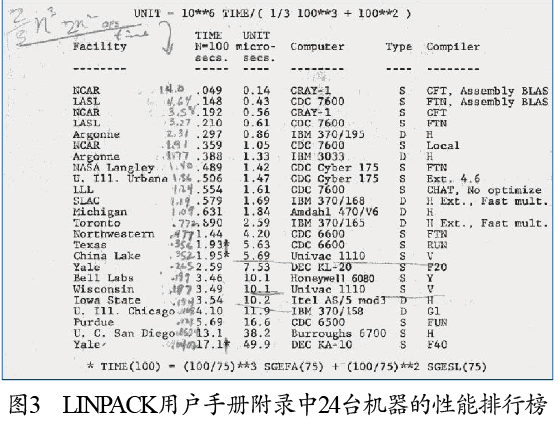
LINPACK是我在1979年開始做的項目,用于求解線性方程組。圖1是當時項目組的合影,從右到左分別是吉姆邦奇(Jim Bunch)、彼得斯圖爾特(Pete Stewart)、克里夫莫勒爾(Cleve Moler)和我,中間是我的汽車,車牌正好也是LINPACK。這個項目是我在新墨西哥大學發起的,當時我還是一名研究生。LINPACK用戶手冊(見圖2)的附錄中列出了24臺機器求解規模為100的線性方程組的性能排行榜(見圖3)。排行榜中最快的計算機是美國國家大氣研究中心(National Center for Atmospheric Research)的克雷1號(Cray-1),當時它的運算速度是14 MFLOPS(1400萬次浮點運算/秒)。

TOP500項目始于1993年,由我、漢斯梅烏爾(Hans Meuer)、埃里希斯特羅邁爾(Erich Strohmaier)和霍斯特西蒙(Horst Simon)等人共同發起。TOP500排行榜每年發布兩次,其中一次是6月在德國的國際超算大會(ISC)上發布,另一次是11月在美國的超算大會(SC)上發布。在TOP500的評測中,我們測量求解線性方程組Ax=b的時間,然后把它換算為運行速度。當增大線性方程組的規模時,運算速度會上升,直到達到穩定點(asymptotic point)。這一穩定的速率被作為TOP500評測的結果。 圖4是超級計算機的性能隨時間變化的曲線:紅線表示運算速度最快(即第一名)的計算機的性能,橙線表示剛進入名單(即第500名)的計算機的性能,藍線是TOP500榜單中算力的總和。1993年的冠軍是美國洛斯阿拉莫斯國家實驗室(Los Alamos National Lab,LANL)的CM5計算機,它有1024個處理器,峰值性能為59.7 GFLOPS(597億次浮點運算/秒),主要用于設計核武器。這種算力在今天是不值一提的。以我作報告使用的Apple M2芯片為例,它的算力約為426 GFLOPS,比1993年的冠軍高了一個數量級,而我卻只用它收發電子郵件。實際上,這個芯片的性能與1997年的冠軍——位于日本筑波大學的日立CP-PAC的性能相當,而這臺機器竟然有2048個處理器。
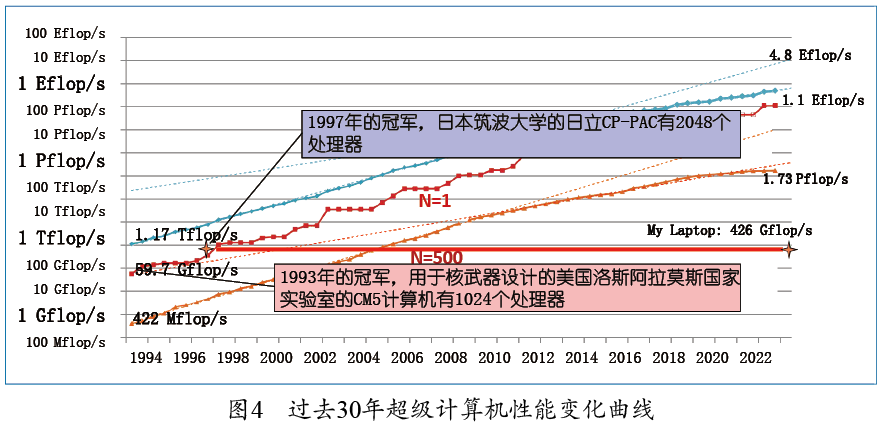
表1列出了最近剛發布的TOP500中排名前十的機器。美國有5臺超級計算機位居前十,其中4臺部署在美國能源部下屬的實驗室,另一臺在英偉達公司。日本、芬蘭、意大利各有一臺,中國有兩臺。
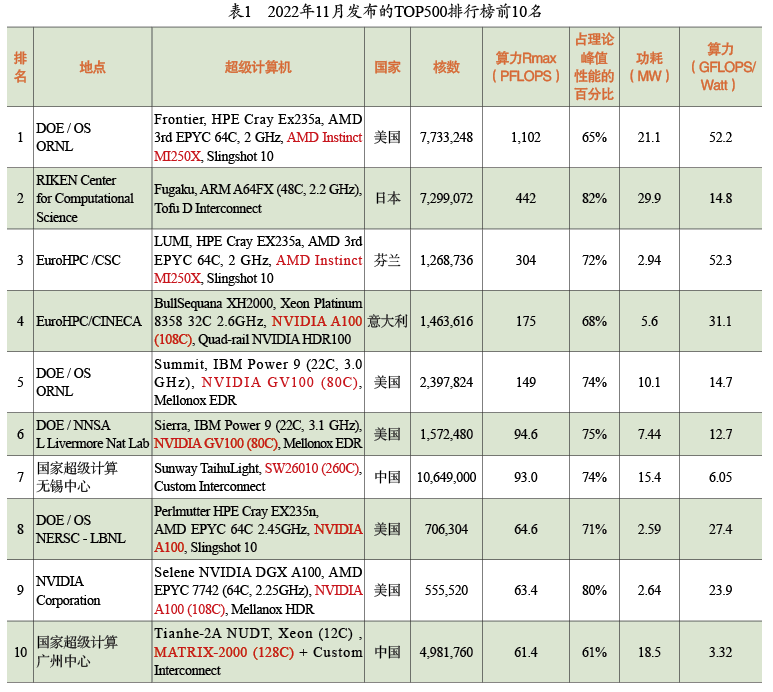
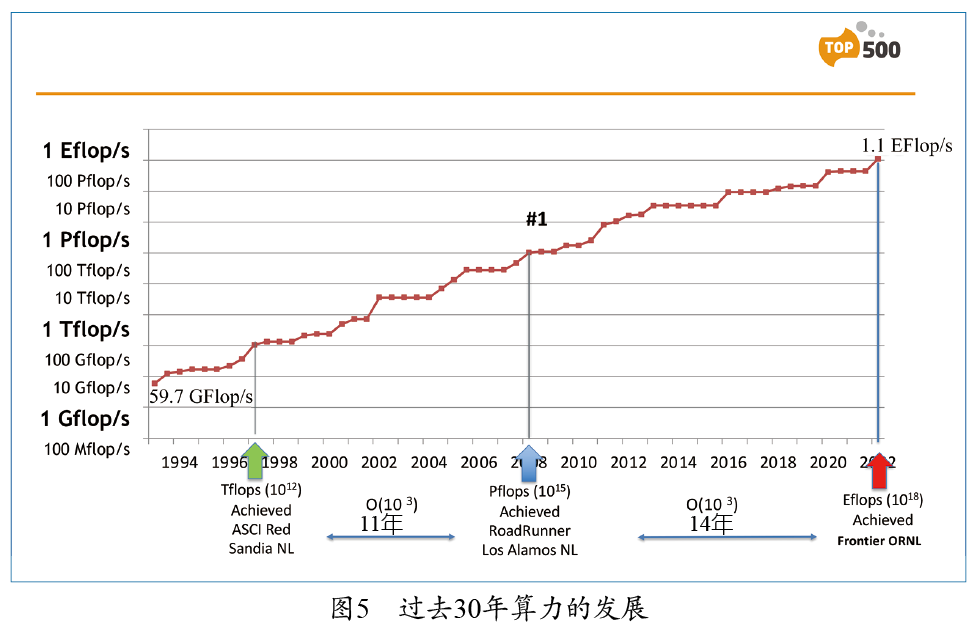
排行榜的第一名是位于美國橡樹嶺國家實驗室(Oak Ridge National Lab,ORNL)的超級計算機Frontier。它是由系統集成商HPE使用超威(AMD)的CPU和GPU制造的,由9408個節點,共計約800萬個核心組成。這臺機器的算力測試結果為1.1 EFLOPS,達到了理論峰值性能的65%,功耗高達21兆瓦,以美國的電價計算,這臺計算機一年的電費約為2100萬美元。這臺機器非常高效,每瓦的能耗可以提供52.2 GFLOPS的算力。 中國上榜的兩臺機器中,位于無錫的“神威太湖之光”非常引人注目,它使用了中國自己生產的申威處理器。另一臺是由國防科技大學研制的“天河二號A”,它使用英特爾處理器,并配備了國防科技大學自研的加速器。 最新的TOP500排行榜中,中國擁有162臺 超級計算機,數量位居第一;美國有125臺,排名第二;然后是德國(34臺)、日本(32臺)和法國(24臺)等。中國不僅擁有數量最多的超級計算機,還擁有數量最多的超級計算機研發機構,包括聯想、中科曙光、浪潮、華為和國防科技大學等。據悉,中國目前有兩臺E級計算機,速度比目前排名第一的Frontier還快。其中一臺是位于青島的新一代神威超級計算機,基于這臺計算機的研究成果獲得了2021年的“戈登貝爾”獎(高性能計算領域的最高獎項);另一臺是位于天津的天河三號。目前,這兩臺超級計算機尚未提交LINPACK的測試結果,因此還未列入TOP500排行榜。 回顧超級計算機的發展(見圖5),我們發現1997年時算力達到了T級,即每秒1012次浮點數操作。11年后的2008年,算力提高了3個數量級,達到了P級,即每秒1015次浮點數操作。又過了14年,到今年(2022年),算力再次提高了3個數量級,達到了E級。那么什么時候能達到Z級(ZettaFLOPS,每秒1021次浮點數操作)呢?我認為時間要比14年長得多。
新的計算模式與基準測試
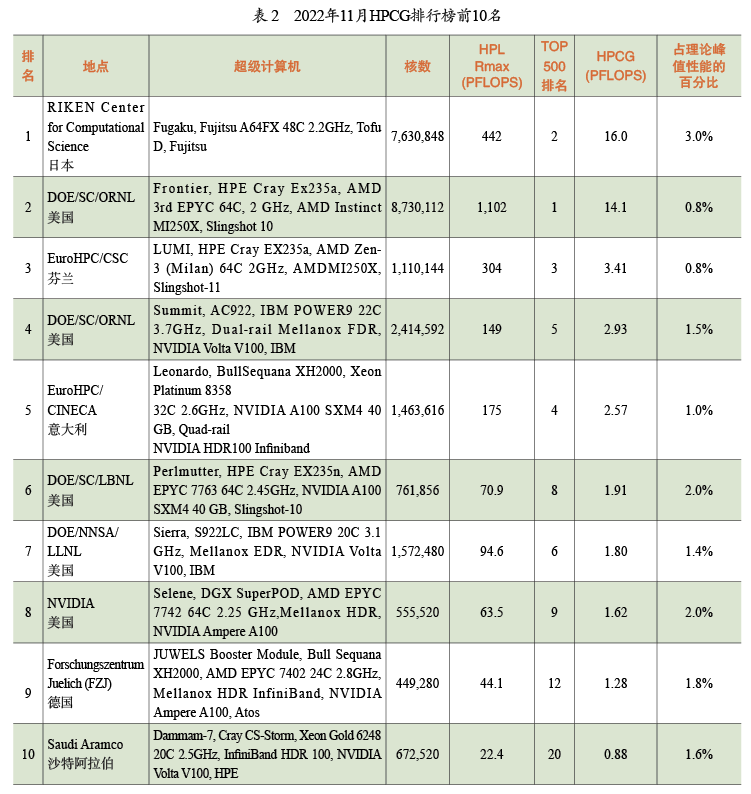
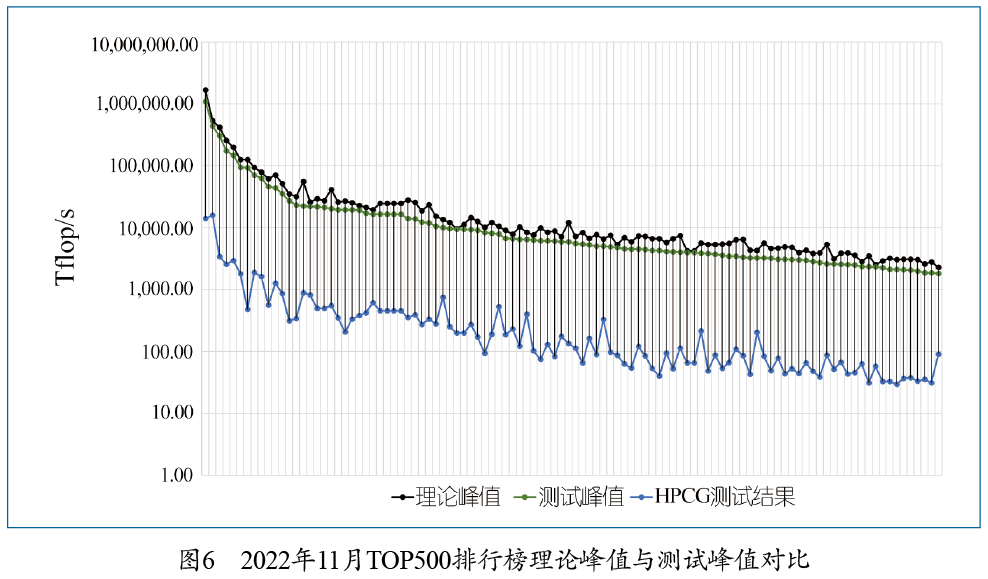
我們設計LINPACK的時候,通過矩陣乘法評價浮點數的計算性能。這在過去是個很重要的指標,但現在不是了。今天,我們需要用新的基準測試來關注數據傳輸的性能。有一個比較新的基準測試叫作HPCG(High Performance Conjugate Gradients),它使用共軛梯度算法解決稀疏矩陣上的問題,這個問題在當前各類應用中普遍出現。表2是基于新基準HPCG的計算機排名,表中列出的HPL(High Performance LINPACK)是舊基準下的算力數值,HPCG是新基準下的算力數值。如果我們只比較這些數字,會發現舊基準給出了比新基準更高的算力結果,但實際上新基準更能反映在這些機器上運行應用程序的實際性能。 表2中的占理論峰值性能的百分比表示HPCG基準下,測試所得算力與理論峰值算力的比值。其中排名第一的日本超級計算機富岳(Fugaku)達到了理論峰值算力的3%,而TOP500中排名第一的Frontier僅達到了理論峰值的0.8%。算力與理論峰值存在差異的主要原因是通信的帶寬和延遲。圖6展示了TOP500排行榜上機器的算力情況,其中黑色圓點表示根據硬件配置計算得到的理論峰值算力;綠色圓點表示LINPACK基準測試得到的峰值算力,非常接近理論峰值;藍色圓點表示HPCG測試結果,相比之下低得多,但它更能反映大多數應用的實際效果。
近年來,人工智能和機器學習十分火熱。它們已經存在很長時間了,為什么現在才火起來呢?原因之一是,近年來互聯網產生了大量數據,可以用于訓練和構建機器學習算法。原因之二是,計算能力的不斷發展(主要是GPU的出現)提高了機器學習的可行性。此外,近年來我們也更深入地理解了算法和理論背后的原理。這些因素都讓我們更有效地利用計算機實現人工智能。今天的人工智能涵蓋很多方面,包括機器學習、自然語言處理、專家系統、計算機視覺、語音、機器人等。不僅如此,人工智能在科學發現方面也起到了很重要的作用,提高了我們解決問題的能力,包括氣候、生物、制藥、材料、高能物理在內的各個領域都在使用人工智能。 盡管線性代數在機器學習中仍然十分重要,但對于精度的要求卻不高。很多時候16位浮點數足以滿足要求,因此很多公司都在設計新硬件和新架構來滿足這樣的場景。今天的超級計算機大多基于CPU和GPU構建,也許在未來,我們會使用更多的其他加速器,例如神經形態計算(neuromorphic computing),甚至是光學計算(optical computing)加速器。在未來,用戶或許可以像接入互聯網那樣輕松地使用超算服務。 展望未來,數據的移動將會是計算機體系架構發展中重要的考量因素,我希望未來的計算機可以在數據移動性能和浮點數計算性能之間取得更好的平衡。雖然在短期內,我們不會看到量子計算機取代現有的計算機,它不能解偏微分方程,也不能解決我們今天使用超級計算機時遇到的各種問題,但量子計算(quantum computing)有望發揮加速器的作用,與現有的計算模式協作解決某些問題。此外,今天的超級計算機仍然被英特爾和超微的處理器主導,TOP500中僅有5臺計算機使用ARM處理器,還沒有任何機器使用RISC-V處理器。RISC-V目前對高性能計算的影響很小,未來或許會有所改變。
結論
從標量到向量,到分布式內存,到加速器,再到混合精度,高性能計算的變遷從未停止過。我認為這里有三場計算的變革。第一個是高性能計算,利用高性能計算推動科學的新發現是當今科學研究的重要組成部分,擁有最好的超級計算機就能做最好的科學研究;第二個是深度學習,它對提高我們利用超級計算機解決問題的能力至關重要;第三個是邊緣計算與人工智能。我認為,算法和軟件通常會隨著硬件的進步而發展,硬件發展在先,軟件發展在后。幾年前,《科學》雜志上發表了一篇非常有趣的論文,是查爾斯雷瑟爾森(Charles Leiserson)等人所寫的《我們仍有向上的空間:摩爾定律之后什么將推動計算機性能》(There’s plenty of room at the Top: What will drive computer performance after Moore's law?)。這篇文章討論的正是這個問題:我們需要設計更好的軟件、更好的算法來匹配已有的硬件,以更有效地利用硬件。我想,這或許可以與理查德費曼(Richard Feynman)1959年在加州理工學院作的經典演講相呼應,費曼講的是在物理世界的底層還有很多研究空間,例如量子效應、量子計算,以及我們如何利用它們。
審核編輯 :李倩
-
cpu
+關注
關注
68文章
10825瀏覽量
211150 -
加速器
+關注
關注
2文章
795瀏覽量
37759 -
超級計算機
+關注
關注
2文章
460瀏覽量
41923
原文標題:Jack Dongarra:高性能計算及其未來需求
文章出處:【微信號:信息與電子工程前沿FITEE,微信公眾號:信息與電子工程前沿FITEE】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論