") FPGA、ASIC等AI芯片特性及對(duì)比
FPGA、ASIC等AI芯片特性及對(duì)比
01.前言
目前,智能駕駛領(lǐng)域在處理深度學(xué)習(xí)AI算法方面, 主要采用GPU、FPGA 等適合并行計(jì)算的通用芯片來(lái)實(shí)現(xiàn)加速 。同時(shí)有部分芯片企業(yè)開始設(shè)計(jì)專門用于AI算法的ASIC專用芯片,比如谷歌TPU、地平線BPU等。在智能駕駛產(chǎn)業(yè)應(yīng)用沒有大規(guī)模興起和批量投放之前,使用GPU、FPGA等已有的通用芯片可以避免專門研發(fā)定制芯片(ASIC)的高投入和高風(fēng)險(xiǎn),但是,由于這類通用芯片設(shè)計(jì)初衷并非專門針對(duì)深度學(xué)習(xí),因而存在性能不足、功耗過(guò)高等方面的問(wèn)題。這些問(wèn)題隨著自動(dòng)駕駛行業(yè)應(yīng)用規(guī)模的擴(kuò)大將會(huì)日益突出。
本文從芯片種類、性能、應(yīng)用和供應(yīng)商等多角度介紹AI芯片,用于給行業(yè)內(nèi)入門新人掃盲。
02.什么是人工智能(AI)芯片?
從廣義上講,能運(yùn)行AI算法的芯片都叫AI芯片。
目前通用的CPU、GPU、FPGA等都能執(zhí)行AI算法,只是執(zhí)行效率差異較大。但狹義上講一般將AI芯片定義為“專門針對(duì)AI算法做了特殊加速設(shè)計(jì)的芯片”。
目前AI芯片的主要用于語(yǔ)音識(shí)別、自然語(yǔ)言處理、圖像處理等大量使用AI算法的領(lǐng)域,通過(guò)芯片加速提高算法效率。 AI芯片的主要任務(wù)是矩陣或向量的乘法、加法,然后配合一些除法、指數(shù)等算法。 AI算法在圖像識(shí)別等領(lǐng)域,常用的是CNN卷積網(wǎng)絡(luò),一個(gè)成熟的AI算法,就是大量的卷積、殘差網(wǎng)絡(luò)、全連接等類型的計(jì)算,本質(zhì)是乘法和加法。
對(duì)汽車行業(yè)而言,AI芯片的主要用于就是處理智能駕駛中環(huán)境感知、傳感器融合和路徑規(guī)劃等算法帶來(lái)的大量并行計(jì)算需求。
AI芯片可以理解為一個(gè)快速計(jì)算乘法和加法的計(jì)算器,而CPU要處理和運(yùn)行非常復(fù)雜的指令集,難度比AI芯片大很多。GPU雖然為圖形處理而設(shè)計(jì),但是CPU與GPU并不是專用AI芯片,其內(nèi)部有大量其他邏輯來(lái)實(shí)現(xiàn)其他功能,這些邏輯對(duì)于目前的AI算法來(lái)說(shuō)完全無(wú)用。目前經(jīng)過(guò)專門針對(duì)AI算法做過(guò)開發(fā)的GPU應(yīng)用較多,也有部分企業(yè)用FPGA做開發(fā),但是行業(yè)內(nèi)對(duì)于AI算法必然出現(xiàn)專用AI芯片。
03.為什么要用AI芯片?
人工智能從功能上來(lái)看包括推理和訓(xùn)練兩個(gè)環(huán)節(jié),智能駕駛行業(yè)亦然。在訓(xùn)練環(huán)節(jié), 通過(guò)大數(shù)據(jù)訓(xùn)練出一個(gè)復(fù)雜的神經(jīng)網(wǎng)絡(luò)模型,目前大部分企業(yè)在訓(xùn)練環(huán)節(jié)主要使用英偉達(dá)的GPU集群完成 。推理環(huán)節(jié)是指利用訓(xùn)練好的模型,使用大量數(shù)據(jù)推理出各種結(jié)論。因此,訓(xùn)練環(huán)節(jié)對(duì)芯片的算力性能要求比較高,推理環(huán)節(jié)對(duì)簡(jiǎn)單指定的重復(fù)計(jì)算和低延遲的要求很高。
從應(yīng)用場(chǎng)景來(lái)看,人工智能芯片應(yīng)用于云端和設(shè)備端,在智能駕駛領(lǐng)域同樣具備云服務(wù)器和車載的各種計(jì)算平臺(tái)或域控制器, 在智能駕駛深度學(xué)習(xí)的訓(xùn)練階段需要極大的數(shù)據(jù)量和大量運(yùn)算,單一處理器無(wú)法獨(dú)立完成,因此訓(xùn)練環(huán)節(jié)只能在云服務(wù)器實(shí)現(xiàn)。相對(duì)的在設(shè)備端即車上,各種ECU、DCU等終端數(shù)量龐大,而且需求差異較大。因此,推理環(huán)節(jié)無(wú)法在云端完成,這就要求車上的各種電子單元、硬件計(jì)算平臺(tái)或域控制器有獨(dú)立的推理計(jì)算能力,因此必須要有專用的AI芯片來(lái)應(yīng)對(duì)這些推理計(jì)算需求。
傳統(tǒng)的CPU、GPU都可以拿來(lái)執(zhí)行AI算法,但是速度慢,性能低,尤其是CPU,在智能駕駛領(lǐng)域無(wú)法實(shí)際投入商用。
比如,自動(dòng)駕駛需要識(shí)別道路、行人、紅綠燈等路況和交通狀況,這在自動(dòng)駕駛算法里面都是屬于并行計(jì)算,如果是CPU去執(zhí)行計(jì)算,那么估計(jì)車撞到人了也沒算出來(lái)個(gè)結(jié)果,CPU并行計(jì)算速度慢屬于先天不足。如果用GPU速度要快得多,畢竟GPU專為圖像處理并行計(jì)算設(shè)計(jì),但是GPU功耗過(guò)大,汽車的電池?zé)o法長(zhǎng)時(shí)間支撐正常使用,而且GPU價(jià)格相對(duì)較高,用于自動(dòng)駕駛量產(chǎn)的話普通消費(fèi)者也用不起。另外,GPU因?yàn)椴皇菍iT針對(duì)AI算法開發(fā)的ASIC,執(zhí)行AI計(jì)算的速度優(yōu)勢(shì)還沒到極限,還有提升空間。
在智能駕駛這樣的領(lǐng)域,環(huán)境感知、物體識(shí)別等深度學(xué)習(xí)應(yīng)用要求計(jì)算響應(yīng)方面必須快! 時(shí)間就是生命,慢一步就有可能造成無(wú)法挽回的情況,但是保證性能快效率高的同時(shí),功耗不能過(guò)高,不能對(duì)智能汽車的續(xù)航里程造成較大影響,也就是AI芯片必須功耗低,所以GPU不是適合智能駕駛的最佳AI芯片選擇。因此開發(fā)ASIC就成了必然。
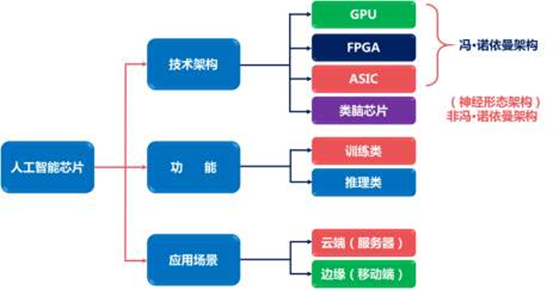
04.AI芯片的種類
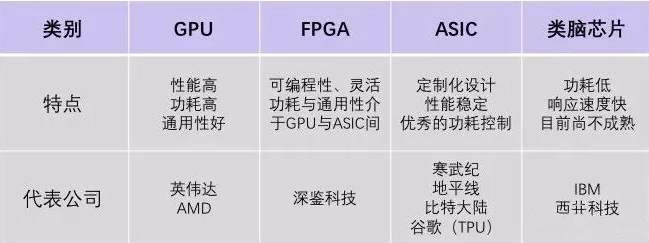
當(dāng)前主流的AI芯片主要分為三類,GPU、FPGA、ASIC。GPU、FPGA均是前期較為成熟的芯片架構(gòu),屬于通用型芯片。ASIC屬于為AI特定場(chǎng)景定制的芯片。行業(yè)內(nèi)已經(jīng)確認(rèn)CPU不適用于AI計(jì)算,但是在AI應(yīng)用領(lǐng)域也是必不可少,另外一種說(shuō)法是還有一種類腦芯片,算是ASIC的一種。
FPGA(Field Programmable Gate Array,現(xiàn)場(chǎng)可編程門陣列)具有足夠的計(jì)算能力和足夠的靈活性。FPGA的計(jì)算速度快是源于它本質(zhì)上是無(wú)指令、無(wú)需共享內(nèi)存的體系結(jié)構(gòu)。對(duì)于保存狀態(tài)的需求,F(xiàn)PGA中的寄存器和片上內(nèi)存(BRAM)是屬于各自的控制邏輯的,無(wú)需不必要的仲裁和緩存,因此FPGA在運(yùn)算速度足夠快,優(yōu)于GPU。同時(shí)FPGA也是一種半定制的硬件,通過(guò)編程可定義其中的單元配置和鏈接架構(gòu)進(jìn)行計(jì)算,因此具有較強(qiáng)的靈活性。相對(duì)于GPU,F(xiàn)PGA能管理能運(yùn)算,但是相對(duì)開發(fā)周期長(zhǎng),復(fù)雜算法開發(fā)難度大。
ASIC(Application Specific Integrated Circuit特定用途集成電路)根據(jù)產(chǎn)品的需求進(jìn)行特定設(shè)計(jì)和制造的集成電路,能夠在特定功能上進(jìn)行強(qiáng)化,具有更高的處理速度和更低的能耗。缺點(diǎn)是研發(fā)成本高,前期研發(fā)投入周期長(zhǎng),且由于是定制化,可復(fù)制性一般,因此只有用量足夠大時(shí)才能夠分?jǐn)偳捌谕度耄档统杀尽?/p>
4.1 CPU (CentralProcessing Unit)
中央處理器作為計(jì)算機(jī)系統(tǒng)的運(yùn)算和控制核心,是信息處理、程序運(yùn)行的最終執(zhí)行單元,CPU 是對(duì)計(jì)算機(jī)的所有硬件資源(如存儲(chǔ)器、輸入輸出單元) 進(jìn)行控制調(diào)配、執(zhí)行通用運(yùn)算的核心硬件單元。
優(yōu)點(diǎn): CPU有大量的緩存和復(fù)雜的邏輯控制單元,非常擅長(zhǎng)邏輯控制、串行的運(yùn)算
缺點(diǎn): 不擅長(zhǎng)復(fù)雜算法運(yùn)算和處理并行重復(fù)的操作。
對(duì)于AI芯片來(lái)說(shuō),算力最弱的是cpu。雖然cpu主頻最高,但是單顆也就8核,16核的樣子,一個(gè)核3.5g,16核也就56g,再考慮指令周期,每秒最多也就30g次乘法。還是定點(diǎn)的。
4.2 GPU (GraphicsProcessing Unit)
圖形處理器,又稱顯示核心、視覺處理器、顯示芯片,是一種專門在個(gè)人電腦、工作站、游戲機(jī)和一些移動(dòng)設(shè)備(如平板電腦、智能手機(jī)等)上做圖像和圖形相關(guān)運(yùn)算工作的微處理器。
優(yōu)點(diǎn): 提供了多核并行計(jì)算的基礎(chǔ)結(jié)構(gòu),且核心數(shù)非常多,可以支撐大量數(shù)據(jù)的并行計(jì)算,擁有更高的浮點(diǎn)運(yùn)算能力。
缺點(diǎn): 管理控制能力(最弱),功耗(最高)。
生產(chǎn)廠商: AMD、NVIDIA
4.3 FPGA(Field Programmable Gate Array)
FPGA是在PAL、GAL等可編程器件的基礎(chǔ)上進(jìn)一步發(fā)展的產(chǎn)物。它是作為專用集成電路(ASIC)領(lǐng)域中的一種半定制電路而出現(xiàn)的,既解決了定制電路的不足,又克服了原有可編程器件門電路數(shù)有限的缺點(diǎn)。
優(yōu)點(diǎn): 可以無(wú)限次編程,延時(shí)性比較低,同時(shí)擁有流水線并行和數(shù)據(jù)并行(GPU只有數(shù)據(jù)并行)、實(shí)時(shí)性最強(qiáng)、靈活性最高。
缺點(diǎn): 開發(fā)難度大、只適合定點(diǎn)運(yùn)算、價(jià)格比較昂貴
生產(chǎn)廠商: Altera(Intel收購(gòu))、Xilinx
4.4 ASIC(Application Specific IntegratedCircuit)
ASIC,即專用集成電路,指應(yīng)特定用戶要求和特定電子系統(tǒng)的需要而設(shè)計(jì)、制造的集成電路。目前用CPLD(復(fù)雜可編程邏輯器件)和 FPGA(現(xiàn)場(chǎng)可編程邏輯陣列)來(lái)進(jìn)行ASIC設(shè)計(jì)是最為流行的方式之一。
優(yōu)點(diǎn): 它作為集成電路技術(shù)與特定用戶的整機(jī)或系統(tǒng)技術(shù)緊密結(jié)合的產(chǎn)物,與通用集成電路相比具有體積更小、重量更輕、 功耗更低、可靠性提高、性能提高、保密性增強(qiáng)、成本降低等優(yōu)點(diǎn)。
缺點(diǎn): 靈活性不夠,成本比FPGA貴
主要性能指標(biāo): 功耗、速度、成本
生產(chǎn)廠商: 谷歌、地平線、寒武紀(jì)等
4.5 四種芯片的特性總結(jié)
CPU是一個(gè)有多種功能的優(yōu)秀領(lǐng)導(dǎo)者。它的優(yōu)點(diǎn)在于調(diào)度、管理、協(xié)調(diào)能力強(qiáng),計(jì)算能力則位于其次。而GPU相當(dāng)于一個(gè)接受CPU調(diào)度的“擁有大量計(jì)算能力”的員工。
GPU 作為圖像處理器,設(shè)計(jì)初衷是為了應(yīng)對(duì)圖像處理中需要大規(guī)模并行計(jì)算。
因此,其在應(yīng)用于深度學(xué)習(xí)算法時(shí),有三個(gè)方面的局限性:
第一, 應(yīng)用過(guò)程中無(wú)法充分發(fā)揮并行計(jì)算優(yōu)勢(shì)。深度學(xué)習(xí)包含訓(xùn)練和應(yīng)用兩個(gè)計(jì)算環(huán)節(jié),GPU 在深度學(xué)習(xí)算法訓(xùn)練上非常高效,但在應(yīng)用時(shí)一次性只能對(duì)于一張輸入圖像進(jìn)行處理,并行度的優(yōu)勢(shì)不能完全發(fā)揮。
第二, 硬件結(jié)構(gòu)固定不具備可編程性。深度學(xué)習(xí)算法還未完全穩(wěn)定,若深度學(xué)習(xí)算法發(fā)生大的變化,GPU 無(wú)法像FPGA 一樣可以靈活的配置硬件結(jié)構(gòu)。
第三, 運(yùn)行深度學(xué)習(xí)算法能效遠(yuǎn)低于FPGA。學(xué)術(shù)界和產(chǎn)業(yè)界研究已經(jīng)證明,運(yùn)行深度學(xué)習(xí)算法中實(shí)現(xiàn)同樣的性能,GPU 所需功耗遠(yuǎn)大于FPGA,例如國(guó)內(nèi)初創(chuàng)企業(yè)深鑒科技基于FPGA 平臺(tái)的人工智能芯片在同樣開發(fā)周期內(nèi)相對(duì)GPU 能效有一個(gè)數(shù)量級(jí)的提升。
FPGA,其設(shè)計(jì)初衷是為了實(shí)現(xiàn)半定制芯片的功能,即硬件結(jié)構(gòu)可根據(jù)需要實(shí)時(shí)配置靈活改變。
研究報(bào)告顯示,目前的FPGA市場(chǎng)由Xilinx 和Altera 主導(dǎo),兩者共同占有85%的市場(chǎng)份額,其中Altera 在2015 年被intel以167 億美元收購(gòu), Xilinx則選擇與IBM進(jìn)行深度合作,背后都體現(xiàn)了 FPGA 在人工智能時(shí)代的重要地位。
盡管 FPGA 倍受看好,甚至百度大腦、地平線AI芯片也是基于FPGA 平臺(tái)研發(fā),但其畢竟不是專門為了適用深度學(xué)習(xí)算法而研發(fā),實(shí)際仍然存在不少局限:
第一, 基本單元的計(jì)算能力有限。為了實(shí)現(xiàn)可重構(gòu)特性,F(xiàn)PGA 內(nèi)部有大量極細(xì)粒度的基本單元,但是每個(gè)單元的計(jì)算能力(主要依靠LUT 查找表)都遠(yuǎn)遠(yuǎn)低于CPU 和GPU中的ALU模塊。
第二, 速度和功耗相對(duì)專用定制芯片(ASIC)仍然存在不小差距。
第三, FPGA 價(jià)格較為昂貴,在規(guī)模放量的情況下單塊FPGA 的成本要遠(yuǎn)高于專用定制芯片。
人工智能定制芯片是大趨勢(shì),從發(fā)展趨勢(shì)上看,人工智能定制芯片將是計(jì)算芯片發(fā)展的大方向。
05.AI芯片算力對(duì)比
5.1 通用芯片—GPU
GPU(Graphics Processing Unit)即為圖形處理器。 NVIDIA公司在1999年發(fā)布GeForce256圖形處理芯片時(shí)首先提出GPU的概念。從此NVIDIA顯卡的芯就用這個(gè)新名字GPU來(lái)稱呼。GPU使顯卡削減了對(duì)CPU的依賴,部分替代原本CPU的工作,特別是在3D圖形處理方面。由于在浮點(diǎn)運(yùn)算、并行計(jì)算等方面,GPU可以提供數(shù)十倍乃至于上百倍于CPU的性能。
GPU相比CPU更適合人工智能計(jì)算。 GPU和CPU分別針對(duì)的是兩種不同的應(yīng)用場(chǎng)景,他們的設(shè)計(jì)目標(biāo)不同,CPU需要很強(qiáng)的通用性來(lái)處理各種不同的數(shù)據(jù)類型,同時(shí)邏輯判斷又會(huì)引入大量的分支跳轉(zhuǎn)和中斷的處理。這些都使得CPU的內(nèi)部結(jié)構(gòu)異常復(fù)雜。而GPU擅長(zhǎng)的則是在不需要被打斷的純凈的計(jì)算環(huán)境中進(jìn)行類型高度統(tǒng)一的、相互無(wú)依賴的大規(guī)模數(shù)據(jù)處理,人工智能的計(jì)算恰巧主要是后者,這使得原本為圖像處理而生的GPU在人工智能時(shí)代煥發(fā)第二春。
CPU的邏輯運(yùn)算單元(ALU)較少,控制器(control)占比較大; GPU的邏輯運(yùn)算單元(ALU)小而多,控制器功能簡(jiǎn)單,緩存(cache)也較少。架構(gòu)的不同使得CPU擅長(zhǎng)進(jìn)行邏輯控制、串行計(jì)算,而GPU擅長(zhǎng)高強(qiáng)度的并行計(jì)算。GPU單個(gè)運(yùn)算單元處理能力弱于CPU的ALU,但是數(shù)量眾多的運(yùn)算單元可以同時(shí)工作,當(dāng)面對(duì)高強(qiáng)度并行計(jì)算時(shí),其性能要優(yōu)于CPU。現(xiàn)如今GPU除了圖像處理外,也越來(lái)越多的運(yùn)用到別的計(jì)算中。
CPU根據(jù)功能劃分,將需要大量并行計(jì)算的任務(wù)分配給GPU。 GPU從CPU獲得指令后,把大規(guī)模、無(wú)結(jié)構(gòu)化的數(shù)據(jù)分解成許多獨(dú)立部分,分配給各個(gè)流處理集群(SMM)。每個(gè)流處理集群再次把數(shù)據(jù)分解,分配給調(diào)度器,調(diào)度器將任務(wù)放入自身所控制的計(jì)算核心core中完成最終的數(shù)據(jù)處理任務(wù)。
GPU性能較強(qiáng)但功耗較高。以NVIDIA開發(fā)的GPU為例,Xavier最高算力為30Tops,功耗為30W,NVIDIA最新發(fā)布的GPUA100相比Volta架構(gòu)的640個(gè)Tensor Core,A100核心的TensorCore減少到了432個(gè),但是性能大幅增強(qiáng),支持全新的TF32運(yùn)算,浮點(diǎn)性能156TFLOPS,同時(shí)INT8浮點(diǎn)性能624TOPS,F(xiàn)P16性能312TFLOPS,同時(shí)功耗也達(dá)到了400W。
5.2 半定制化芯片—FPGA
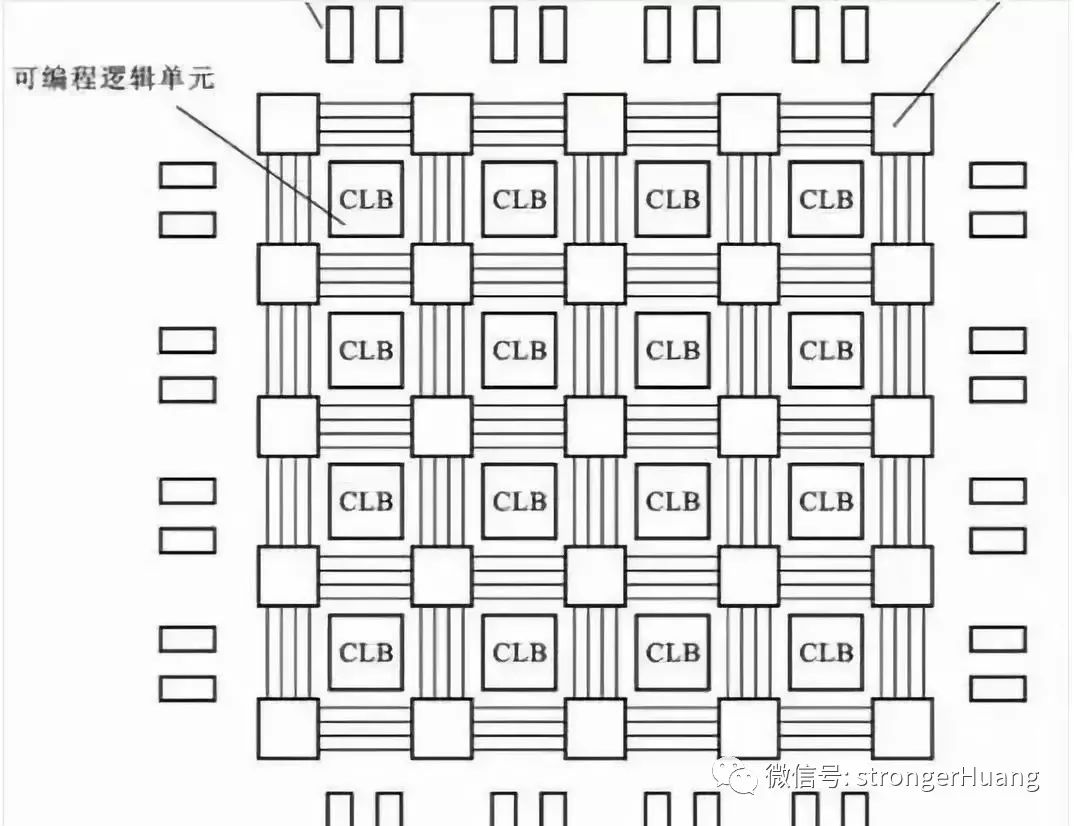
FPGA(Field-ProgrammableGate Array),即現(xiàn)場(chǎng)可編程門陣列。它是在PAL、GAL、CPLD等可編程器件的基礎(chǔ)上進(jìn)一步發(fā)展的產(chǎn)物。它是作為專用集成電路(ASIC)領(lǐng)域中的一種半定制電路而出現(xiàn)的,既解決了定制電路的不足,又克服了原有可編程器件門電路數(shù)有限的缺點(diǎn)。
FPGA內(nèi)部有很多可配置邏輯模塊(CLB),這些模塊是現(xiàn)實(shí)邏輯功能的基本單元,F(xiàn)PGA可通過(guò)靈活地配置CLB來(lái)令其實(shí)現(xiàn)工程師想要實(shí)現(xiàn)的邏輯功能。
FPGA的并行處理能力也很強(qiáng)大,其可編程性也適用于不斷優(yōu)化的深度學(xué)習(xí)算法的運(yùn)算。目前很多公司基于FPGA開發(fā)人工智能處理器。于2016年成立的深鑒科技,就在研發(fā)深度學(xué)習(xí)通用解決方案。2016年初,深鑒科技就設(shè)計(jì)了基于FPGA、針對(duì)深度學(xué)習(xí)的DPU硬件架構(gòu)。該產(chǎn)品實(shí)現(xiàn)了高性能功耗比,并且成本也比GPU產(chǎn)品低很多。今年8月加州的Hot Chips大會(huì)上,百度也發(fā)布了其基于FPGA芯片的A.I加速芯片—XPU。該芯片有256核,旨在尋求性能和效率的平衡,處理多樣化計(jì)算任務(wù)。
基于FPGA開發(fā)的人工智能處理器具有高性能、低能耗、可硬件編程的特點(diǎn)。
1)高性能
除了GPU,F(xiàn)PGA也擅長(zhǎng)并行計(jì)算,基于FPGA開發(fā)的處理器可以實(shí)現(xiàn)更高的并行計(jì)算。而且FPGA帶有豐富的片上存儲(chǔ)資源,可以大大減少訪問(wèn)片外存儲(chǔ)的延遲,提高計(jì)算性能,訪問(wèn)DRAM儲(chǔ)存大約是訪問(wèn)寄存器存儲(chǔ)延遲的幾百倍以上。
2)低能耗
相比于CPU和GPU,F(xiàn)PGA的能耗優(yōu)勢(shì)主要有兩個(gè)原因:1)相比于CPU、GPU,F(xiàn)PGA架構(gòu)有一定的優(yōu)化,CPU、GPU需要頻繁的訪問(wèn)DRAM,而這個(gè)能量消耗較大,F(xiàn)PGA可以減少這方面的能耗。2)FPGA的主頻低,CPU和GPU的主頻一般在1-3GHz之間,而FPGA的主頻一般在500MHz一下。因此,F(xiàn)PGA的能耗要低于CPU、GPU。
3)可硬件編程
FPGA可硬件編程,并且可以進(jìn)行靜態(tài)重復(fù)編程和動(dòng)態(tài)系統(tǒng)重配置。用戶可像編程修改軟件一樣修改系統(tǒng)的硬件功能,大大增強(qiáng)了系統(tǒng)設(shè)計(jì)的靈活性和通用性。使得FPGA可以靈活地部署在需要修改硬件設(shè)置場(chǎng)景中。
FPGA+CPU異構(gòu)架構(gòu)被越來(lái)越多地研究和認(rèn)可。相比于CPU+GPU,因?yàn)镕PGA的高性能低功耗等優(yōu)勢(shì)使FPGA+CPU可以提供更好的單位功耗性能,且更易于修改和編程。因此FPGA適合做可并行計(jì)算的任務(wù),如矩陣運(yùn)算。如果是一些判斷類的問(wèn)題,F(xiàn)PGA算得并沒有CPU快。所以已經(jīng)有研究人員探討FPGA+CPU的架構(gòu)模式。
5.3 全定制芯片—ASIC
ASIC(Application Specific IntegratedCircuit)在集成電路界被認(rèn)為是一種為專門目的而設(shè)計(jì)的集成電路。是指應(yīng)特定用戶要求和特定電子系統(tǒng)的需要而設(shè)計(jì)、制造的集成電路。ASIC的特點(diǎn)是面向特定用戶的需求,ASIC在批量生產(chǎn)時(shí)與通用集成電路相比具有體積更小、功耗更低、可靠性提高、性能提高、保密性增強(qiáng)、成本降低等優(yōu)點(diǎn)。簡(jiǎn)單地講,ASIC芯片就是通過(guò)臺(tái)積電等代工廠流片的芯片。目前,基于ASIC的人工智能芯片有地平線BPU、谷歌的TPU。
基于ASIC開發(fā)人工智能芯片開發(fā)周期較長(zhǎng)。基于ASIC開發(fā)人工智能芯片更像是電路設(shè)計(jì),需要反復(fù)優(yōu)化,需要經(jīng)歷較長(zhǎng)的流片周期,故開發(fā)周期較長(zhǎng)。
量產(chǎn)后ASIC人工智能芯片成本及價(jià)格較低。雖然相較于FPGA, ASIC人工智能芯片需要經(jīng)歷較長(zhǎng)的開發(fā)周期,并且需要價(jià)格昂貴的流片投入,但是這些前期開發(fā)投入在量產(chǎn)后會(huì)被攤薄,所以量產(chǎn)后,ASIC人工智能芯片的成本和價(jià)格會(huì)低于FPGA人工智能芯片。
ASIC芯片性能功耗比較高。從性能功耗比來(lái)看,ASIC作為定制芯片,其性能要比基于通用芯片F(xiàn)PGA開發(fā)出的各種半定制人工智能芯片更具有優(yōu)勢(shì)。而且ASIC也并不是完全不具備可配置能力,只是沒有FPGA那么靈活,只要在設(shè)計(jì)的時(shí)候把電路做成某些參數(shù)可調(diào)即可。
ASIC人工智能芯片主要面向消費(fèi)電子市場(chǎng)。ASIC更高的性能,更低的量產(chǎn)成本以及有限可配置特性,使其主要面向消費(fèi)電子市場(chǎng),如寒武紀(jì)等公司。
5.4 類腦芯片
類人腦芯片架構(gòu)是一款基于神經(jīng)形態(tài)的工程,旨在打破“馮·諾依曼”架構(gòu)的束縛,模擬人腦處理過(guò)程,感知世界、處理問(wèn)題。這種芯片的功能類似于大腦的神經(jīng)突觸,處理器類似于神經(jīng)元,而其通訊系統(tǒng)類似于神經(jīng)纖維,可以允許開發(fā)者為類人腦芯片設(shè)計(jì)應(yīng)用程序。通過(guò)這種神經(jīng)元網(wǎng)絡(luò)系統(tǒng),計(jì)算機(jī)可以感知、記憶和處理大量不同的信息。類腦芯片的兩大突破:1、有望形成自主認(rèn)知的新形式;2、突破傳統(tǒng)計(jì)算機(jī)體系結(jié)構(gòu)的限制,實(shí)現(xiàn)數(shù)據(jù)并行傳送、分布式處理,能以極低功耗實(shí)時(shí)處理大量數(shù)據(jù)。
06.總結(jié)
CPU 有強(qiáng)大的調(diào)度、管理、協(xié)調(diào)能力。應(yīng)用范圍廣。開發(fā)方便且靈活。但其在大量數(shù)據(jù)處理上沒有 GPU 專業(yè),相對(duì)運(yùn)算量低,但功耗不低。
GPU:是單指令、多數(shù)據(jù)處理,采用數(shù)量眾多的計(jì)算單元和超長(zhǎng)的流水線,如名字一樣,圖形處理器, GPU善于處理圖像領(lǐng)域的運(yùn)算加速。但GPU無(wú)法單獨(dú)工作,必須由CPU進(jìn)行控制調(diào)用才能工作。CPU可單獨(dú)作用,處理復(fù)雜的邏輯運(yùn)算和不同的數(shù)據(jù)類型,但當(dāng)需要大量的處理類型統(tǒng)一的數(shù)據(jù)時(shí),則可調(diào)用GPU進(jìn)行并行計(jì)算。
FPGA:和GPU相反,F(xiàn)PGA適用于多指令,單數(shù)據(jù)流的分析,因此常用于預(yù)測(cè)階段,如云端。 FPGA是用硬件實(shí)現(xiàn)軟件算法,因此在實(shí)現(xiàn)復(fù)雜算法方面有一定的難度,缺點(diǎn)是價(jià)格比較高。將FPGA和GPU對(duì)比發(fā)現(xiàn),一是缺少內(nèi)存和控制所帶來(lái)的存儲(chǔ)和讀取部分,速度更快。二是因?yàn)槿鄙僮x取的作用,所以功耗低,劣勢(shì)是運(yùn)算量并不是很大。結(jié)合CPU和GPU各自的優(yōu)勢(shì),有一種解決方案就是異構(gòu)。
ASIC芯片:是專用定制芯片,為實(shí)現(xiàn)特定要求而定制的芯片。 除了不能擴(kuò)展以外,在功耗、可靠性、體積方面都有優(yōu)勢(shì),尤其在高性能、低功耗的移動(dòng)端。谷歌的TPU、寒武紀(jì)的MLU,地平線的BPU都屬于ASIC芯片。谷歌的TPU比CPU和GPU的方案快30-80倍,與CPU和GPU相比,TPU把控制縮小了,因此減少了芯片的面積,降低了功耗。
四種架構(gòu)將走向哪里?
眾所周知,通用處理器(CPU)的摩爾定律已入暮年,而機(jī)器學(xué)習(xí)和Web 服務(wù)的規(guī)模卻在指數(shù)級(jí)增長(zhǎng)。
人們使用定制硬件來(lái)加速常見的計(jì)算任務(wù),然而日新月異的行業(yè)又要求這些定制的硬件可被重新編程來(lái)執(zhí)行新類型的計(jì)算任務(wù)。
將以上四種架構(gòu)對(duì)比,GPU未來(lái)的主攻方向是高級(jí)復(fù)雜算法和通用性人工智能平臺(tái),其發(fā)展路線分兩條走: 一是主攻高端算法的實(shí)現(xiàn),對(duì)于指令的邏輯性控制要更復(fù)雜一些,在面向需求通用的AI計(jì)算方面具有優(yōu)勢(shì);二是主攻通用性人工智能平臺(tái),GPU的通用性強(qiáng),所以應(yīng)用于大型人工智能平臺(tái)可高效完成不同的需求。FPGA更適用于各種細(xì)分的行業(yè),人工智能會(huì)應(yīng)用到各個(gè)細(xì)分領(lǐng)域。
ASIC芯片是全定制芯片,長(zhǎng)遠(yuǎn)看適用于人工智能。現(xiàn)在很多做AI算法的企業(yè)也是從這個(gè)點(diǎn)切入。因?yàn)樗惴◤?fù)雜度越強(qiáng),越需要一套專用的芯片架構(gòu)與其進(jìn)行對(duì)應(yīng),ASIC基于人工智能算法進(jìn)行定制,其發(fā)展前景看好。類腦芯片是人工智能最終的發(fā)展模式,但是離產(chǎn)業(yè)化還很遙遠(yuǎn)。
幾個(gè)品牌的SOC及域控制器做的還是不錯(cuò)的,尤其是基于NVIDIA Xavier以及前期PX2等芯片的開發(fā)。國(guó)內(nèi)大部分企業(yè)的應(yīng)用比較集中在Xavier平臺(tái)和Linux系統(tǒng),尤其是新勢(shì)力造車企業(yè),而傳統(tǒng)車企更青睞TI、瑞薩等半導(dǎo)體公司的智能AI芯片以及QNX系統(tǒng)。國(guó)內(nèi)基于Xavier做開發(fā)的企業(yè)很多,天津優(yōu)控智行目前的域控制器產(chǎn)品在行業(yè)內(nèi)屬于中等偏上水平,但是其軟件工具和服務(wù)做得相對(duì)有些優(yōu)勢(shì),后期有時(shí)間也扒一扒地平線、智行者等企業(yè)的域控制器學(xué)習(xí)學(xué)習(xí)。
-
FPGA
+關(guān)注
關(guān)注
1626文章
21666瀏覽量
601833 -
芯片
+關(guān)注
關(guān)注
453文章
50400瀏覽量
421800 -
asic
+關(guān)注
關(guān)注
34文章
1193瀏覽量
120324 -
gpu
+關(guān)注
關(guān)注
28文章
4700瀏覽量
128699
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
ASIC和FPGA的優(yōu)勢(shì)與劣勢(shì)
自動(dòng)駕駛主流架構(gòu)方案對(duì)比:GPU、FPGA、ASIC
到底什么是ASIC和FPGA?
cogoask講解fpga和ASIC是什么意思
FPGA和ASIC芯片解密有哪些性能分析
AI運(yùn)算核心,FPGA領(lǐng)域前程遠(yuǎn)大
ASIC和FPGA有什么區(qū)別
ai芯片和gpu的區(qū)別
什么是ASIC芯片?與CPU、GPU、FPGA相比如何?
淺析GPU、FPGA、ASIC三種主流AI芯片的區(qū)別
AI的三種專用芯片 GPU和FPGA以及ASIC
關(guān)于AI芯片的介紹與四大芯片的特性和總結(jié)及對(duì)比
自動(dòng)駕駛主流芯片:GPU、FPGA、ASIC
FPGA、ASIC技術(shù)對(duì)比





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論