 基于機器學習的水體化學需氧量高光譜反演模型對比研究
基于機器學習的水體化學需氧量高光譜反演模型對比研究
引言
化學需氧量(COD)是以化學方法測量水樣中需要被氧化的還原性物質的量。水樣在一定條件下的COD以氧化1升水樣中還原性物質縮小化的氧化劑的量為指標,折算成每升水樣全部被氧化后,需要的氧的毫克數,以mg·L-1來表示。COD測試可以很容易地量化水中有機物的含量。COD最常見的應用是量化地表水(如湖泊和河流)或廢水中可氧化污染物的量,在水質監測中起到了巨大的作用。傳統的有重鉻酸鹽滴定法和分光光度法等方法,電化學方法和流動注射分析法用于COD檢測,但這些檢測方法都存在檢測周期較長?消耗試劑等缺點,對水體的批量檢測也難以實現。
而利用高光譜技術和機器學習手段對水質參數進行反演近期已成為國內外熱點研究問題。高光譜技術能夠獲得物體連續的光譜信息,近年來逐步應用于水農產品檢測?生植被和水資源調控等領域。在水質參數高光譜反演建模中,國內外學者采取機器學習方法對不同水質參數進行建模,如總氮?總磷?水質濁度?一般懸浮物?化學需氧量等,并取得了一定成果。
實驗部分
2.1 預處理
高光譜數據通常包含由相機或儀器產生的隨機噪聲和光譜變化。光譜預處理可以減少或消除數據中與自身性質無關的信息,降低模型的復雜性,提高數據和模型的可解釋性(魯棒性和準確性)。光譜數據的預處理在進行多變量分析之前是必不可少的。SG平滑能夠使光譜曲線平滑,MSC方法能夠消除基線漂移和平移現象。采用SG平滑?MSC以及SG平滑結合MSC光譜預處理手段對原始光譜進行預處理并進行比較。
2.2 特征波段提取
高光譜波段由大量的波段組成,有些波段的相關性較高而且存在冗余以及噪聲等。對特征波段的提取在一定程度上可以規避這兩種情況。
2.3 反演模型
選取線性回歸?隨機森林?AdaBoost?XGBoost四種機器學習建模方法。線性回歸是一種確定兩個或多個變量間相互依賴定量關系的機器學習方法;隨機森林算法是決策樹的集成,通過平均決策樹可以大大降低過擬合的風險,是比單一決策樹性能更優的模型;Adaboost是將弱學習器結合創造一個強學習器的機器學習方法;XGBoost是一種改進的梯度提升迭代決策樹(GBDT)算法。
2.4 模型評估
采取RMSE,R2和RPD三個指標對反演模型進行對比和評價。
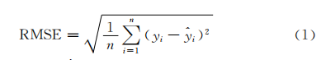

結果與討論
3.1 原始光譜及數值統計分析
圖1為樣本水體的原始光譜曲線,水體在550~600nm的反射率較高,在700~750nm的反射率較低。從圖中可以看出每個水體樣本曲線的變化趨勢類似,沒有呈現較大的差異,而且難以直接通過光譜曲線對其COD含量進行判斷。水體樣本的COD值統計結果如表1所示。
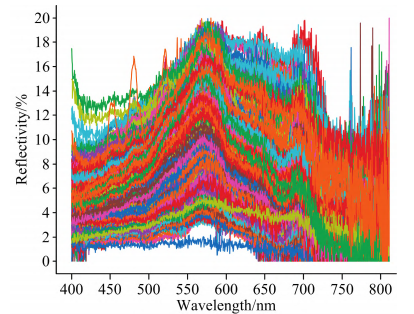
圖1 水體樣本原始光譜反射率曲線
表1 COD含量描述統計分析
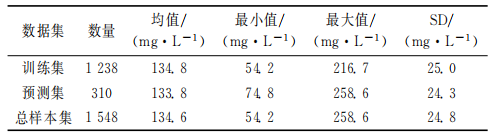
圖 2 土壤樣本去包絡的反射率
3.2 光譜預處理結果
使用三種光譜預處理方法對原始光譜進行預處理,預處理后的光譜分布如圖3(a,b,c)所示。經過光譜預處理后,高光譜的數據質量得到了一定改善,但還是無法直觀的從光譜曲線上判斷水體的COD含量,因此還需要通過機器學習方法對其建模進行分析。
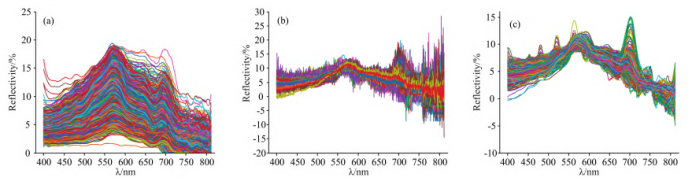
圖3 水體樣本預處理后的光譜分布
3.3 反演模型
對原始光譜數據和三種不同的預處理方法分別使用四種機器學習模型建模。模型的反演精度與建模的訓練時間如表2—表5所示。由表2—表5中數據可以看到,XGBoost在原始光譜以及三種經過預處理數據上的建模精度均優于其他模型,且訓練時間小于隨機森林模型以及Adaboost模型。線性回歸所建的反演模型表現較差,說明COD與光譜數據并沒有直接的線性關系。在所有的模型中,通過XGBooost對經過SG平滑和MSC處理的數據所建的反演模型精度最高,其中R2為0.92,RMSE為7.1mg·L-1,RPD為3.4。通過不同預處理方式所得的XGBoost反演模型散點圖如圖4(a—d)所示。
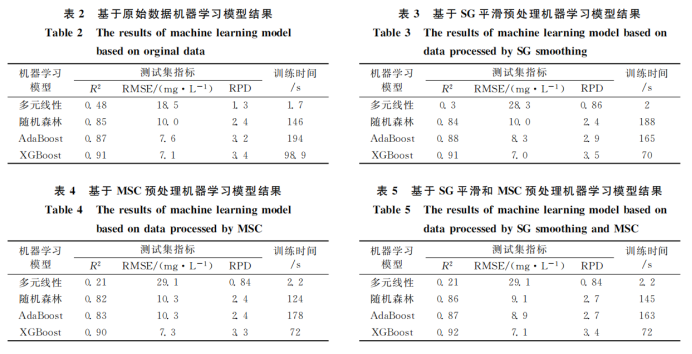
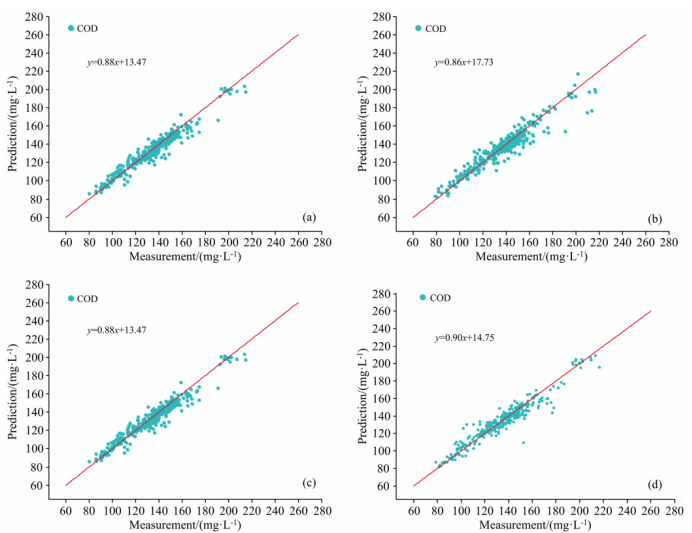
圖4 不同預處理方法下XGBoost反演模型COD預測值與實測值關系散點圖
結論
在實際生產過程中可根據實際需求,綜合考慮模型精度?模型訓練時間等因素進行模型的選擇。研究結果表明,基于機器學習的高光譜COD反演模型精度可以達到較高水平,為機器學習在高光譜水質監測領域的應用提供了參考。此外,機器學習模型可解釋性需要進一步研究。
歡迎關注公眾號:萊森光學,了解更多光譜知識。
萊森光學(深圳)有限公司是一家提供光機電一體化集成解決方案的高科技公司,我們專注于光譜傳感和光電應用系統的研發、生產和銷售。
審核編輯黃宇
-
機器學習
+關注
關注
66文章
8378瀏覽量
132415 -
高光譜
+關注
關注
0文章
327瀏覽量
9917
發布評論請先 登錄
相關推薦
光學知識水體COD光譜特性分析
水體參數高光譜反演模型對比研究

機器學習在遙感高光譜圖像中的應用
機器學習中的無模型強化學習算法及研究綜述

模型化深度強化學習應用研究綜述

利用反射率、偏振度光譜特性進行葉綠素濃度反演
高光譜遙感技術在懸沙水體研究中的應用說明
高光譜遙感技術在地質領域的應用研究
手持式地物光譜儀對水體葉綠素的光譜特性測試研究
高光譜技術估測煙草生化成分的機理和研究進展
基于高光譜的模擬壁畫鹽含量反演
內陸水體藻藍蛋白遙感反演研究進展





 工商網監
工商網監
評論