") GTC 2023:多模態(tài)短視頻模型推理優(yōu)化方案解析
GTC 2023:多模態(tài)短視頻模型推理優(yōu)化方案解析
關(guān)于多模態(tài)短視頻模型推理優(yōu)化方案解析
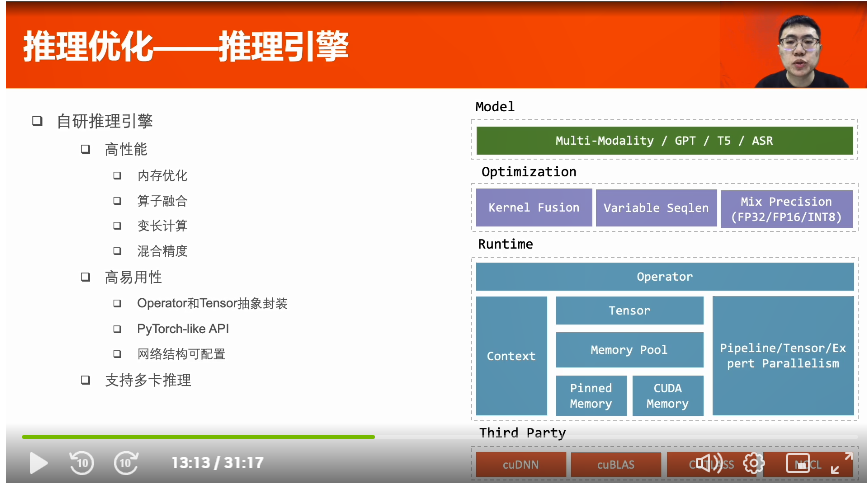
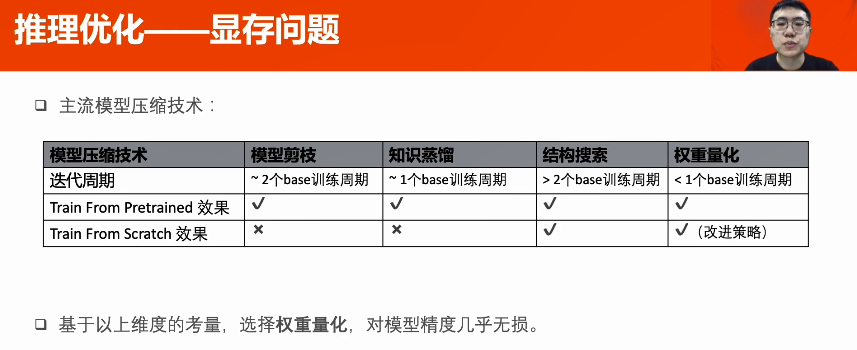
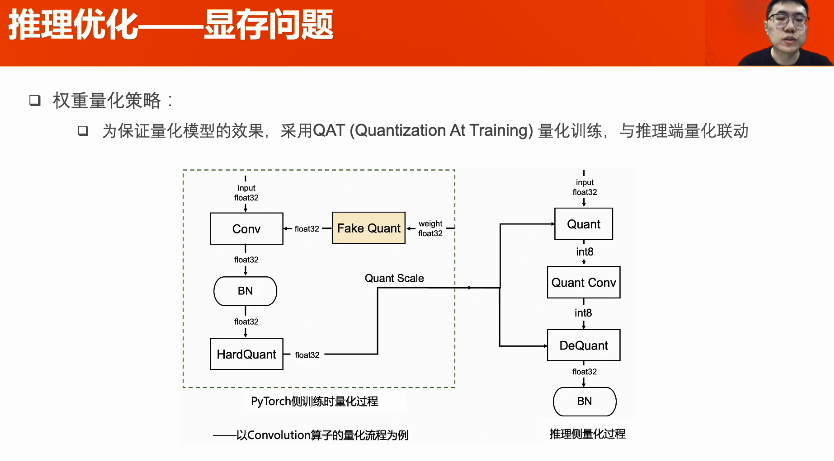
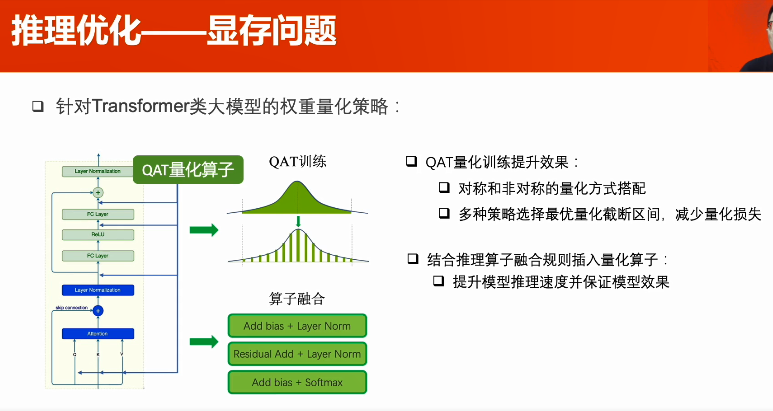
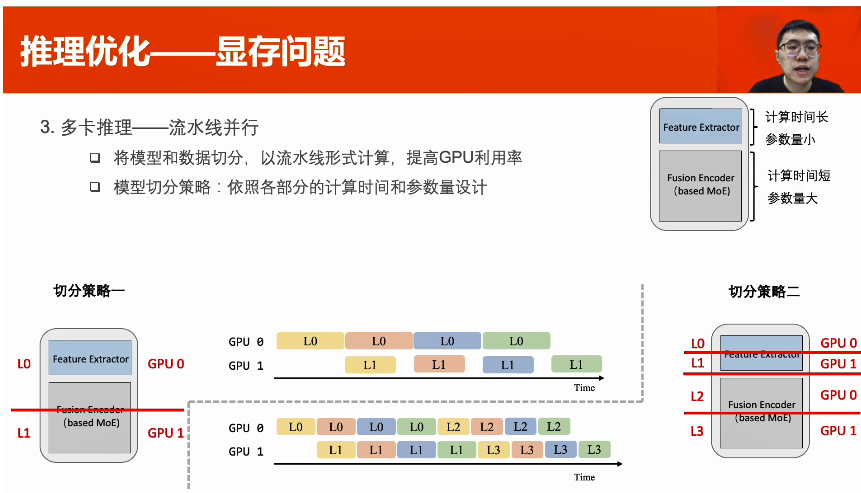
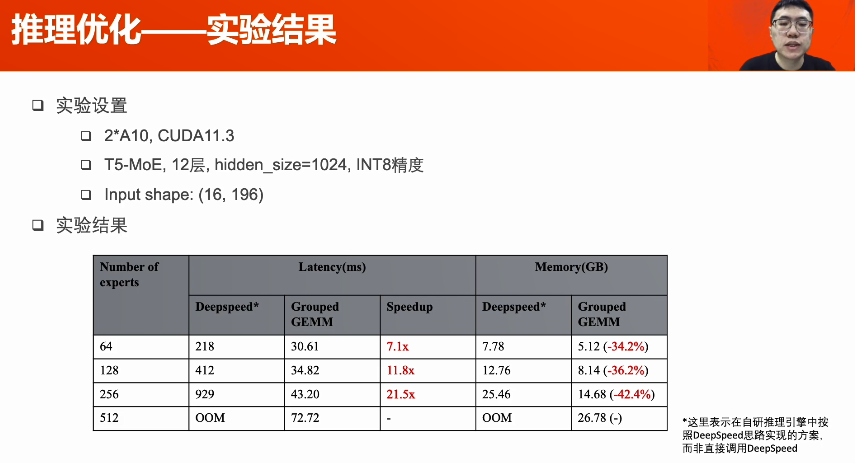
多卡推理--流水線并行:將模型和數(shù)據(jù)切分,以流水線形式計(jì)算,提高GPU利用率。模型切分策略:依照各部分的計(jì)算時(shí)間和參數(shù)量設(shè)計(jì)。

聲明:本文內(nèi)容及配圖由入駐作者撰寫(xiě)或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場(chǎng)。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問(wèn)題,請(qǐng)聯(lián)系本站處理。
舉報(bào)投訴
-
gpu
+關(guān)注
關(guān)注
28文章
4703瀏覽量
128725 -
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3749瀏覽量
90856 -
gtc
+關(guān)注
關(guān)注
0文章
73瀏覽量
4417 -
短視頻
+關(guān)注
關(guān)注
1文章
124瀏覽量
8914
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
CDN高級(jí)技術(shù)專家周哲:深度剖析短視頻分發(fā)過(guò)程中的用戶體驗(yàn)優(yōu)化技術(shù)點(diǎn)
和分發(fā)的角度介紹整體方案,并且重點(diǎn)講解短視頻加速的注意事項(xiàng)和用戶體驗(yàn)優(yōu)化要點(diǎn)。深圳云棲大會(huì)已經(jīng)圓滿落幕,在3月29日飛天技術(shù)匯-彈性計(jì)算、網(wǎng)絡(luò)和CDN專場(chǎng)中,阿里云CDN高級(jí)技術(shù)專家周哲為我們帶來(lái)
發(fā)表于 04-03 14:32
基于層次注意力機(jī)制的多模態(tài)圍堵情感識(shí)別模型
識(shí)別模型。在音頻模態(tài)中加人頻率注意力機(jī)制學(xué)習(xí)頻域上下文信息,利用多模態(tài)注意力機(jī)制將視頻特征與音頻特征進(jìn)行融合,依據(jù)改進(jìn)的損失函數(shù)對(duì)
發(fā)表于 04-01 11:20
?9次下載

蛋白質(zhì)能量模型的多模態(tài)優(yōu)化算法綜述
算法的基礎(chǔ),提出了一種基于二面角相似度的蛋白質(zhì)構(gòu)象多模態(tài)優(yōu)化方法。首先,執(zhí)行模態(tài)探測(cè),將 Rosetta粗粒度能量模型作為篩選高質(zhì)量新個(gè)體的
發(fā)表于 05-18 15:33
?1次下載
云海計(jì)費(fèi)系統(tǒng)v4.1 視頻解析解析收費(fèi)接口專用 短視頻解析解析收費(fèi)接口專用 影視視頻電影解析計(jì)費(fèi)平臺(tái)源碼程序
介紹:云海計(jì)費(fèi)系統(tǒng)v4.1 視頻解析 短視頻解析 影視視頻電影解析計(jì)費(fèi)平臺(tái)源碼程序云海
發(fā)表于 01-11 16:02
?13次下載

GTC 2023:短視頻多模態(tài)超大模型的場(chǎng)景應(yīng)用
快手科技圍繞提高模型計(jì)算效率和可部署開(kāi)展技術(shù)攻關(guān),沉淀了一套通用的混合并行訓(xùn)練、壓縮、推理整體解決方案。

VisCPM:邁向多語(yǔ)言多模態(tài)大模型時(shí)代
可以大致分為兩類: 1. 在圖生文(image-to-text generation)方面,以 GPT-4 為代表的多模態(tài)大模型,可以面向圖像進(jìn)行開(kāi)放域?qū)υ捄蜕疃?b class='flag-5'>推理; 2. 在文生圖

更強(qiáng)更通用:智源「悟道3.0」Emu多模態(tài)大模型開(kāi)源,在多模態(tài)序列中「補(bǔ)全一切」
熱度。Flamingo 具備強(qiáng)大的多模態(tài)上下文少樣本學(xué)習(xí)能力。 Flamingo 走的技術(shù)路線是將大語(yǔ)言模型與一個(gè)預(yù)訓(xùn)練視覺(jué)編碼器結(jié)合,并插入可學(xué)習(xí)的層來(lái)捕捉跨模態(tài)依賴,其采用圖文對(duì)、

北大&華為提出:多模態(tài)基礎(chǔ)大模型的高效微調(diào)
深度學(xué)習(xí)的大模型時(shí)代已經(jīng)來(lái)臨,越來(lái)越多的大規(guī)模預(yù)訓(xùn)練模型在文本、視覺(jué)和多模態(tài)領(lǐng)域展示出杰出的生成和推理能力。然而大

探究編輯多模態(tài)大語(yǔ)言模型的可行性
不同于單模態(tài)模型編輯,多模態(tài)模型編輯需要考慮更多的模態(tài)信息。文章出發(fā)點(diǎn)依然從單
發(fā)表于 11-09 14:53
?485次閱讀
大模型+多模態(tài)的3種實(shí)現(xiàn)方法
我們知道,預(yù)訓(xùn)練LLM已經(jīng)取得了諸多驚人的成就, 然而其明顯的劣勢(shì)是不支持其他模態(tài)(包括圖像、語(yǔ)音、視頻模態(tài))的輸入和輸出,那么如何在預(yù)訓(xùn)練LLM的基礎(chǔ)上引入跨模態(tài)的信息,讓其變得更強(qiáng)

自動(dòng)駕駛和多模態(tài)大語(yǔ)言模型的發(fā)展歷程
多模態(tài)大語(yǔ)言模型(MLLM) 最近引起了廣泛的關(guān)注,其將 LLM 的推理能力與圖像、視頻和音頻數(shù)據(jù)相結(jié)合,通過(guò)多
發(fā)表于 12-28 11:45
?492次閱讀

李未可科技正式推出WAKE-AI多模態(tài)AI大模型
李未可科技多模態(tài) AI 大模型正式發(fā)布,積極推進(jìn) AI 在終端的場(chǎng)景應(yīng)用 ? 4月18日,2024中國(guó)生成式AI大會(huì)上李未可科技正式發(fā)布為眼鏡等未來(lái)終端定向優(yōu)化等自研WAKE-AI
發(fā)表于 04-18 17:01
?568次閱讀

Meta發(fā)布多模態(tài)LLAMA 3.2人工智能模型
Meta Platforms近日宣布了一項(xiàng)重要技術(shù)突破,成功推出了多模態(tài)LLAMA 3.2人工智能模型。這一創(chuàng)新模型不僅能夠深度解析文本信息
利用OpenVINO部署Qwen2多模態(tài)模型
多模態(tài)大模型的核心思想是將不同媒體數(shù)據(jù)(如文本、圖像、音頻和視頻等)進(jìn)行融合,通過(guò)學(xué)習(xí)不同模態(tài)之間的關(guān)聯(lián),實(shí)現(xiàn)更加智能化的信息處理。簡(jiǎn)單來(lái)說(shuō)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論