 Linux中top輸出的利用率信息是如何計算出來的?它精確嗎?
Linux中top輸出的利用率信息是如何計算出來的?它精確嗎?
在線上服務器觀察線上服務運行狀態的時候,絕大多數人都是喜歡先用 top 命令看看當前系統的整體 cpu 利用率。例如,隨手拿來的一臺機器,top 命令顯示的利用率信息如下:

這個輸出結果說簡單也簡單,說復雜也不是那么容易就能全部搞明白的。例如:
問題 1:top 輸出的利用率信息是如何計算出來的,它精確嗎?
問題 2:ni 這一列是 nice,它輸出的是 cpu 在處理啥時的開銷?
問題 3:wa 代表的是 io wait,那么這段時間中 cpu 到底是忙碌還是空閑?
今天我們對 cpu 利用率統計進行深入的學習。通過今天的學習,你不但能了解 cpu 利用率統計實現細節,還能對 nice、io wait 等指標有更深入的理解。
今天我們先從自己的思考開始!
一、先思考一下
拋開 Linux 的實現先不談,如果有如下需求,有一個四核服務器,上面跑了四個進程。
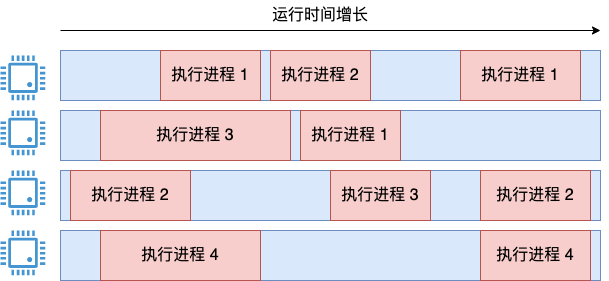
讓你來設計計算整個系統 cpu 利用率的這個需求,支持像 top 命令這樣的輸出,滿足以下要求:
cpu 使用率要盡可能地準確;
要盡可能地體現秒級瞬時 cpu 狀態。
可以先停下來思考幾分鐘。
好,思考結束。經過思考你會發現,這個看起來很簡單的需求,實際還是有點小復雜的。
其中一個思路是把所有進程的執行時間都加起來,然后再除以系統執行總時間*4。
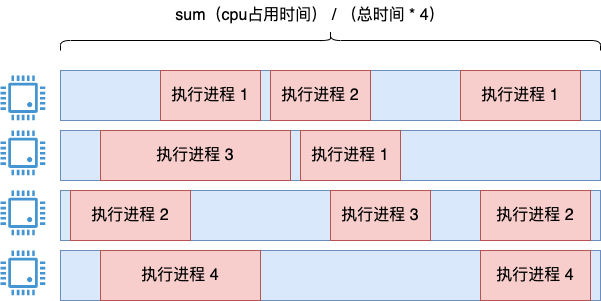
這個思路是沒問題的,用這種方法統計很長一段時間內的 cpu 利用率是可以的,統計也足夠的準確。
但只要用過 top 你就知道 top 輸出的 cpu 利用率并不是長時間不變的,而是默認 3 秒為單位會動態更新一下(這個時間間隔可以使用 -d 設置)。我們的這個方案體現總利用率可以,體現這種瞬時的狀態就難辦了。你可能會想到那我也 3 秒算一次不就行了?但這個 3 秒的時間從哪個點開始呢。粒度很不好控制。
上一個思路問題核心就是如何解決瞬時問題。提到瞬時狀態,你可能就又來思路了。那我就用瞬時采樣去看,看看當前有幾個核在忙。四個核中如果有兩個核在忙,那利用率就是 50%。
這個思路思考的方向也是正確的,但是問題有兩個:
你算出的數字都是 25% 的整數倍;
這個瞬時值會導致 cpu 使用率顯示的劇烈震蕩。
比如下圖:
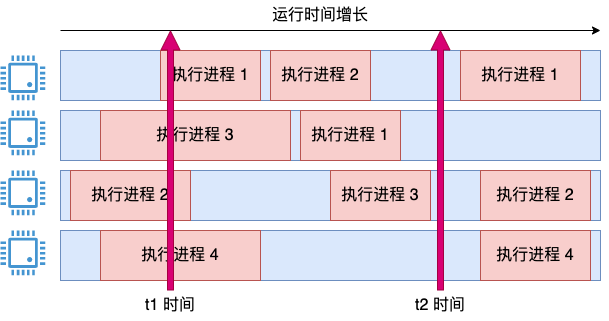
在 t1 的瞬時狀態看來,系統的 cpu 利用率毫無疑問就是 100%,但在 t2 時間看來,使用率又變成 0% 了。思路方向是對的,但顯然這種粗暴的計算無法像 top 命令一樣優雅地工作。
我們再改進一下它,把上面兩個思路結合起來,可能就能解決我們的問題了。在采樣上,我們把周期定得細一些,但在計算上我們把周期定得粗一些。
我們引入采用周期的概念,定時比如每 1 毫秒采樣一次。如果采樣的瞬時,cpu 在運行,就將這 1 ms 記錄為使用。這時會得出一個瞬時的 cpu 使用率,把它都存起來。
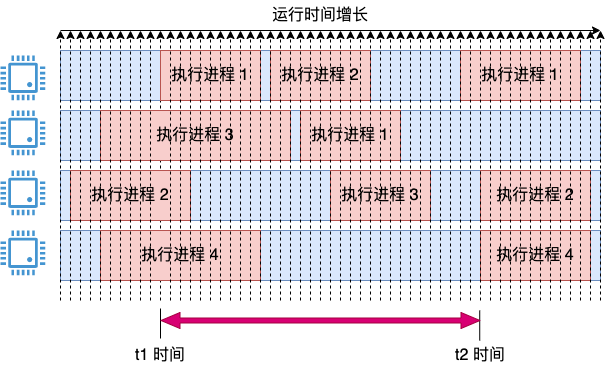
在統計 3 秒內的 cpu 使用率的時候,比如上圖中的 t1 和 t2 這段時間范圍。那就把這段時間內的所有瞬時值全加一下,取個平均值。這樣就能解決上面的問題了,統計相對準確,避免了瞬時值劇烈震蕩且粒度過粗(只能以 25% 為單位變化)的問題了。
可能有同學會問了,假如 cpu 在兩次采樣中間發生變化了呢,如下圖這種情況。
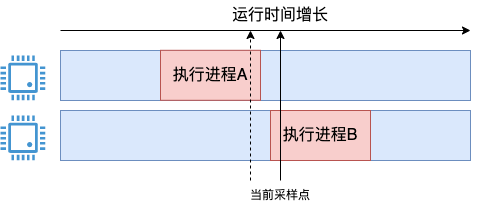
在當前采樣點到來的時候,進程 A 其實剛執行完,有一點點時間既沒被上一個采樣點統計到,本次也統計不到。對于進程 B,其實只開始了一小段時間,把 1 ms 全記上似乎有點多記了。
確實會存在這個問題,但因為我們的采樣是 1 ms 一次,而我們實際查看使用的時候最少也是秒級別地用,會包括有成千上萬個采樣點的信息,所以這種誤差并不會影響我們對全局的把握。
事實上,Linux 也就是這樣來統計系統 cpu 利用率的。雖然可能會有誤差,但作為一項統計數據使用已經是足夠了的。在實現上,Linux 是將所有的瞬時值都累加到某一個數據上的,而不是真的存了很多份的瞬時數據。
接下來就讓我們進入 Linux 來查看它對系統 cpu 利用率統計的具體實現。
二、top 命令使用數據在哪兒
上一節我們說的 Linux 在實現上是將瞬時值都累加到某一個數據上的,這個值是內核通過 /proc/stat 偽文件來對用戶態暴露。Linux 在計算系統 cpu 利用率的時候用的就是它。
整體上看,top 命令工作的內部細節如下圖所示。
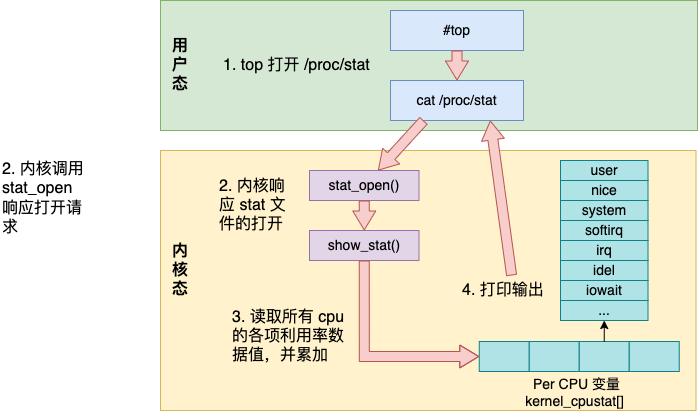
top 命令訪問 /proc/stat 獲取各項 cpu 利用率使用值;
內核調用 stat_open 函數來處理對 /proc/stat 的訪問;
內核訪問的數據來源于 kernel_cpustat 數組,并匯總;
打印輸出給用戶態。
接下來我們把每一步都展開來詳細看看。
通過使用 strace 跟蹤 top 命令的各種系統調用,可以看到它對該文件的調用。
#stracetop ... openat(AT_FDCWD,"/proc/stat",O_RDONLY)=4 openat(AT_FDCWD,"/proc/2351514/stat",O_RDONLY)=8 openat(AT_FDCWD,"/proc/2393539/stat",O_RDONLY)=8 ...
除了 /proc/stat 外,還有各個進程細分的 /proc/{pid}/stat,是用來計算各個進程的 cpu 利用率時使用的。
內核為各個偽文件都定義了處理函數,/proc/stat 文件的處理方法是 proc_stat_operations。
//file:fs/proc/stat.c
staticint__initproc_stat_init(void)
{
proc_create("stat",0,NULL,&proc_stat_operations);
return0;
}
staticconststructfile_operationsproc_stat_operations={
.open=stat_open,
...
};
proc_stat_operations 中包含了該文件對應的操作方法。當打開 /proc/stat 文件的時候,stat_open 就會被調用到。stat_open 依次調用 single_open_size,show_stat 來輸出數據內容。我們來看看它的代碼:
//file:fs/proc/stat.c
staticintshow_stat(structseq_file*p,void*v)
{
u64user,nice,system,idle,iowait,irq,softirq,steal;
for_each_possible_cpu(i){
structkernel_cpustat*kcs=&kcpustat_cpu(i);
user+=kcs->cpustat[CPUTIME_USER];
nice+=kcs->cpustat[CPUTIME_NICE];
system+=kcs->cpustat[CPUTIME_SYSTEM];
idle+=get_idle_time(kcs,i);
iowait+=get_iowait_time(kcs,i);
irq+=kcs->cpustat[CPUTIME_IRQ];
softirq+=kcs->cpustat[CPUTIME_SOFTIRQ];
...
}
//轉換成節拍數并打印出來
seq_put_decimal_ull(p,"cpu",nsec_to_clock_t(user));
seq_put_decimal_ull(p,"",nsec_to_clock_t(nice));
seq_put_decimal_ull(p,"",nsec_to_clock_t(system));
seq_put_decimal_ull(p,"",nsec_to_clock_t(idle));
seq_put_decimal_ull(p,"",nsec_to_clock_t(iowait));
seq_put_decimal_ull(p,"",nsec_to_clock_t(irq));
seq_put_decimal_ull(p,"",nsec_to_clock_t(softirq));
...
}
在上面的代碼中,for_each_possible_cpu 是在遍歷存儲著 cpu 使用率數據的 kcpustat_cpu 變量。該變量是一個 percpu 變量,它為每一個邏輯核都準備了一個數組元素。里面存儲著當前核所對應各種事件,包括 user、nice、system、idel、iowait、irq、softirq 等。
在這個循環中,將每一個核的每種使用率都加起來。最后通過 seq_put_decimal_ull 將這些數據輸出出來。
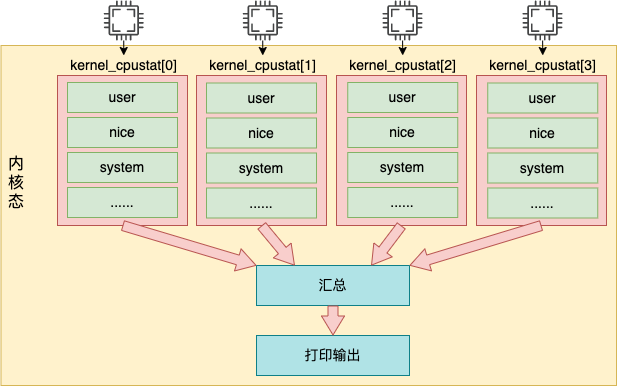
注意,在內核中實際每個時間記錄的是納秒數,但是在輸出的時候統一都轉化成了節拍單位。至于節拍單位多長,下一節我們介紹。總之, /proc/stat 的輸出是從 kernel_cpustat 這個 percpu 變量中讀取出來的。
我們接著再看看這個變量中的數據是何時加進來的。
三、統計數據怎么來的
前面我們提到內核是以采樣的方式來統計 cpu 使用率的。這個采樣周期依賴的是 Linux 時間子系統中的定時器。
Linux 內核每隔固定周期會發出 timer interrupt (IRQ 0),這有點像樂譜中的節拍的概念。每隔一段時間,就打出一個拍子,Linux 就響應之并處理一些事情。
一個節拍的長度是多長時間,是通過 CONFIG_HZ 來定義的。它定義的方式是每一秒有幾次 timer interrupts。不同的系統中這個節拍的大小可能不同,通常在 1 ms 到 10 ms 之間。可以在自己的 Linux config 文件中找到它的配置。
#grep^CONFIG_HZ/boot/config-5.4.56.bsk.10-amd64 CONFIG_HZ=1000
從上述結果中可以看出,我的機器每秒要打出 1000 次節拍。也就是每 1 ms 一次。
每次當時間中斷到來的時候,都會調用 update_process_times 來更新系統時間。更新后的時間都存儲在我們前面提到的 percpu 變量 kcpustat_cpu 中。
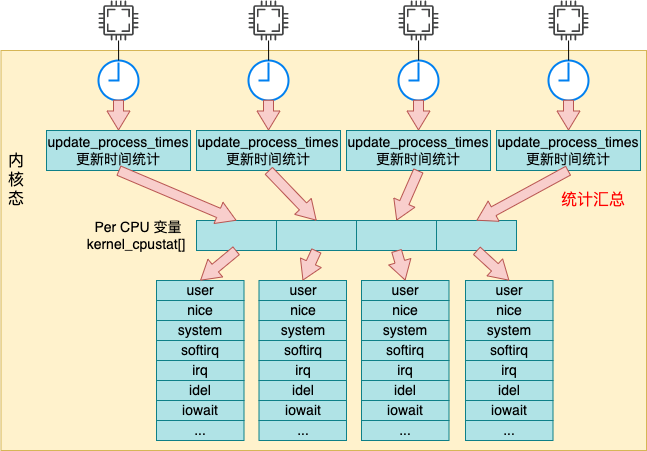
我們來詳細看下匯總過程 update_process_times 的源碼,它位于 kernel/time/timer.c 文件中。
//file:kernel/time/timer.c
voidupdate_process_times(intuser_tick)
{
structtask_struct*p=current;
//進行時間累積處理
account_process_tick(p,user_tick);
...
}
這個函數的參數 user_tick 指的是采樣的瞬間是處于內核態還是用戶態。接下來調用 account_process_tick。
//file:kernel/sched/cputime.c
voidaccount_process_tick(structtask_struct*p,intuser_tick)
{
cputime=TICK_NSEC;
...
if(user_tick)
//3.1統計用戶態時間
account_user_time(p,cputime);
elseif((p!=rq->idle)||(irq_count()!=HARDIRQ_OFFSET))
//3.2統計內核態時間
account_system_time(p,HARDIRQ_OFFSET,cputime);
else
//3.3統計空閑時間
account_idle_time(cputime);
}
在這個函數中,首先設置 cputime = TICK_NSEC, 一個 TICK_NSEC 的定義是一個節拍所占的納秒數。接下來根據判斷結果分別執行 account_user_time、account_system_time 和 account_idle_time 來統計用戶態、內核態和空閑時間。
3.1 用戶態時間統計
//file:kernel/sched/cputime.c
voidaccount_user_time(structtask_struct*p,u64cputime)
{
//分兩種種情況統計用戶態CPU的使用情況
intindex;
index=(task_nice(p)>0)?CPUTIME_NICE:CPUTIME_USER;
//將時間累積到/proc/stat中
task_group_account_field(p,index,cputime);
......
}
account_user_time 函數主要分兩種情況統計:
如果進程的 nice 值大于 0,那么將會增加到 CPU 統計結構的 nice 字段中。
如果進程的 nice 值小于等于 0,那么增加到 CPU 統計結構的 user 字段中。
看到這里,開篇的問題 2 就有答案了,其實用戶態的時間不只是 user 字段,nice 也是。之所以要把 nice 分出來,是為了讓 Linux 用戶更一目了然地看到調過 nice 的進程所占的 cpu 周期有多少。
我們平時如果想要觀察系統的用戶態消耗的時間的話,應該是將 top 中輸出的 user 和 nice 加起來一并考慮,而不是只看 user!
接著調用 task_group_account_field 來把時間加到前面我們用到的 kernel_cpustat 內核變量中。
//file:kernel/sched/cputime.c staticinlinevoidtask_group_account_field(structtask_struct*p,intindex, u64tmp) { __this_cpu_add(kernel_cpustat.cpustat[index],tmp); ... }
3.2 內核態時間統計
我們再來看內核態時間是如何統計的,找到 account_system_time 的代碼。
//file:kernel/sched/cputime.c
voidaccount_system_time(structtask_struct*p,inthardirq_offset,u64cputime)
{
if(hardirq_count()-hardirq_offset)
index=CPUTIME_IRQ;
elseif(in_serving_softirq())
index=CPUTIME_SOFTIRQ;
else
index=CPUTIME_SYSTEM;
account_system_index_time(p,cputime,index);
}
內核態的時間主要分 3 種情況進行統計。
如果當前處于硬中斷執行上下文, 那么統計到 irq 字段中;
如果當前處于軟中斷執行上下文, 那么統計到 softirq 字段中;
否則統計到 system 字段中。
判斷好要加到哪個統計項中后,依次調用 account_system_index_time、task_group_account_field 來將這段時間加到內核變量 kernel_cpustat 中。
//file:kernel/sched/cputime.c
staticinlinevoidtask_group_account_field(structtask_struct*p,intindex,
u64tmp)
{
__this_cpu_add(kernel_cpustat.cpustat[index],tmp);
}
3.3 空閑時間的累積
沒錯,在內核變量 kernel_cpustat 中不僅僅是統計了各種用戶態、內核態的使用時間,空閑也一并統計起來了。
如果在采樣的瞬間,cpu 既不在內核態也不在用戶態的話,就將當前節拍的時間都累加到 idle 中。
//file:kernel/sched/cputime.c
voidaccount_idle_time(u64cputime)
{
u64*cpustat=kcpustat_this_cpu->cpustat;
structrq*rq=this_rq();
if(atomic_read(&rq->nr_iowait)>0)
cpustat[CPUTIME_IOWAIT]+=cputime;
else
cpustat[CPUTIME_IDLE]+=cputime;
}
在 cpu 空閑的情況下,進一步判斷當前是不是在等待 IO(例如磁盤 IO),如果是的話這段空閑時間會加到 iowait 中,否則就加到 idle 中。從這里,我們可以看到 iowait 其實是 cpu 的空閑時間,只不過是在等待 IO 完成而已。
看到這里,開篇問題 3 也有非常明確的答案了,io wait 其實是 cpu 在空閑狀態的一項統計,只不過這種狀態和 idle 的區別是 cpu 是因為等待 io 而空閑。
四、總結
本文深入分析了 Linux 統計系統 CPU 利用率的內部原理。全文的內容可以用如下一張圖來匯總:
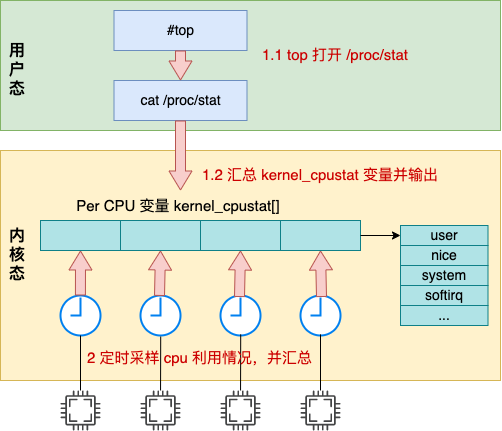
Linux 中的定時器會以某個固定節拍,比如 1 ms 一次采樣各個 cpu 核的使用情況,然后將當前節拍的所有時間都累加到 user/nice/system/irq/softirq/io_wait/idle 中的某一項上。
top 命令是讀取的 /proc/stat 中輸出的 cpu 各項利用率數據,而這個數據在內核中是根據 kernel_cpustat 來匯總并輸出的。
回到開篇問題 1,top 輸出的利用率信息是如何計算出來的,它精確嗎?
/proc/stat 文件輸出的是某個時間點的各個指標所占用的節拍數。如果想像 top 那樣輸出一個百分比,計算過程是分兩個時間點 t1, t2 分別獲取一下 stat 文件中的相關輸出,然后經過個簡單的算術運算便可以算出當前的 cpu 利用率。
再說是否精確。這個統計方法是采樣的,只要是采樣,肯定就不是百分之百精確。但由于我們查看 cpu 使用率的時候往往都是計算 1 秒甚至更長一段時間的使用情況,這其中會包含很多采樣點,所以查看整體情況是問題不大的。
另外從本文,我們也學到了 top 中輸出的 cpu 時間項目其實大致可以分為三類:
第一類:用戶態消耗時間,包括 user 和 nice。如果想看用戶態的消耗,要將 user 和 nice 加起來看才對。
第二類:內核態消耗時間,包括 irq、softirq 和 system。
第三類:空閑時間,包括 io_wait 和 idle。其中 io_wait 也是 cpu 的空閑狀態,只不過是在等 io 完成而已。如果只是想看 cpu 到底有多閑,應該把 io_wait 和 idle 加起來才對。
審核編輯:劉清
-
服務器
+關注
關注
12文章
9021瀏覽量
85184 -
定時器
+關注
關注
23文章
3237瀏覽量
114467 -
LINUX內核
+關注
關注
1文章
316瀏覽量
21618
原文標題:Linux 中 CPU 利用率是如何算出來的?
文章出處:【微信號:良許Linux,微信公眾號:良許Linux】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論