") 內(nèi)存Cache還有哪些不足?Write buffer是為了解決什么問題?
內(nèi)存Cache還有哪些不足?Write buffer是為了解決什么問題?
一、內(nèi)存Cache還有哪些不足?
上一篇文章我們談到了內(nèi)存Cache,并且描述了典型的Cache一致性協(xié)議MESI。Cache的根本目的,是解決內(nèi)存與CPU速度多達兩個數(shù)量級的性能差異。一個包含Cache的計算機系統(tǒng),其結(jié)構(gòu)可以簡單的表示為下圖:
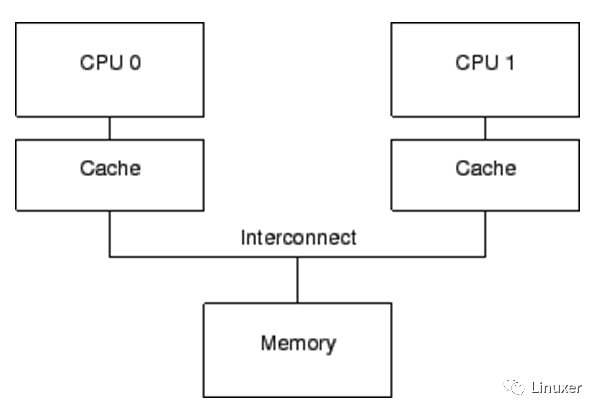
僅僅只有Cache的計算機系統(tǒng),它還存在如下問題:
1、Cache的速度,雖然比內(nèi)存有了極大的提升,但是仍然比CPU慢幾倍。
2、在發(fā)生“warmup cache miss”、“capacity miss”、“associativity miss”時,CPU必須等待從內(nèi)存中讀取數(shù)據(jù),此時CPU會處于一種Stall的狀態(tài)。其等待時間可能達到幾百個CPU指令周期。
顯然,這是現(xiàn)代計算機不能承受之重:)
二、Write buffer是為了解決什么問題?
如果CPU僅僅是執(zhí)行foo = 1這樣的語句,它其實無須從內(nèi)存或者緩存中讀取foo現(xiàn)在的值。因為無論foo當(dāng)前的值是什么,它都會被覆蓋。在僅僅只有Cache的系統(tǒng)中,foo = 1 這樣的操作也會形成寫停頓。自然而然的,CPU設(shè)計者應(yīng)當(dāng)會想到在Cache 和CPU之間再添加一級緩存。由于這樣的緩存主要是應(yīng)對寫操作引起的Cache Miss,并且緩存的數(shù)據(jù)與寫操作相關(guān),因此CPU設(shè)計者將它命名為“Write buffer”。調(diào)整后的結(jié)構(gòu)示意圖如下(圖中的store buffer即為write buffer):
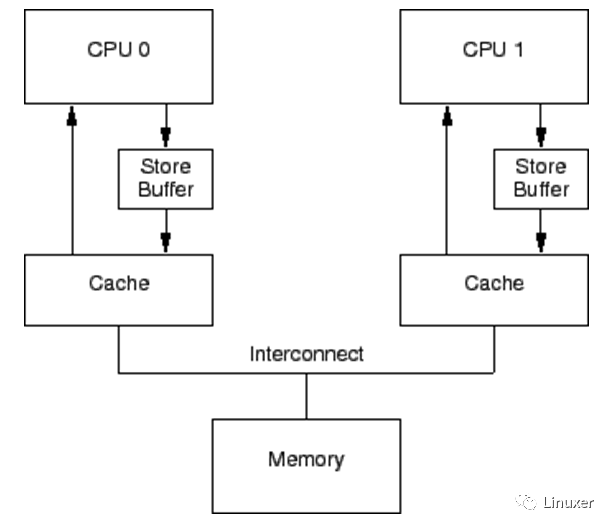
通過增加這些Write buffer,CPU可以簡單的將要保存的數(shù)據(jù)放到Write buffer 中,并且繼續(xù)運行,而不會真正去等待Cache從內(nèi)存中讀取數(shù)據(jù)并返回。
對于特定CPU來說,這些Write buffer是屬于本地的。或者在硬件多線程系統(tǒng)中,它對于特定核來說,是屬于本地的。無論哪一種情況,一個特定CPU僅僅允許訪問分配給它的Writebuffer。例如,在上圖中,CPU 0不能訪問CPU 1的存儲緩沖,反之亦然。
Write buffer進一步提升了系統(tǒng)性能,但是它也會為硬件設(shè)計者帶來一些困擾:
第一個困擾:違反了自身一致性。
考慮如下代碼:變量“a”和“b”都初始化為0,包含變量“a”緩存行,最初被CPU 1所擁有,而包含變量“b”的緩存行最初被CPU0所擁有:
1 a = 1;
2 b = a + 1;
3 assert(b == 2);
沒有哪一位軟件工程師希望斷言被觸發(fā)!
然而,如果采用上圖中的簡單系統(tǒng)結(jié)構(gòu),斷言確實會被觸發(fā)。理解這一點的關(guān)鍵在于:a最初被CPU 1所擁有,而CPU 0在執(zhí)行a = 1時,將a的新值存儲在CPU 0的Write buffer中。
在這個簡單系統(tǒng)中,觸發(fā)斷言的事件順序可能如下:
1.CPU 0 開始執(zhí)行a = 1。
2.CPU 0在緩存中查找“a”,并且發(fā)現(xiàn)緩存缺失。
3.因此,CPU 0發(fā)送一個“讀使無效(read-invalidate message)”消息,以獲得包含“a”的獨享緩存行。
4.CPU 0將“a”記錄到存儲緩沖區(qū)。
5.CPU 1接收到“讀使無效”消息,它通過發(fā)送緩存行數(shù)據(jù),并從它的緩存行中移除數(shù)據(jù)來響應(yīng)這個消息。
6.CPU 0開始執(zhí)行b = a + 1。
7.CPU 0從CPU 1接收到緩存行,它仍然擁有一個為“0”的“a”值。
8.CPU 0從它的緩存中讀取到“a”的值,發(fā)現(xiàn)其值為0。
9.CPU 0將存儲隊列中的條目應(yīng)用到最近到達的緩存行,設(shè)置緩存行中的“a”的值為1。
10.CPU 0將前面加載的“a”值0加1,并存儲該值到包含“b”的緩存行中(假設(shè)已經(jīng)被CPU 0所擁有)。
11.CPU 0 執(zhí)行assert(b == 2),并引起錯誤。
針對這種情況,硬件設(shè)計者對軟件工程師還是給予了必要的同情。他們會對系統(tǒng)進行稍許的改進,如下圖:
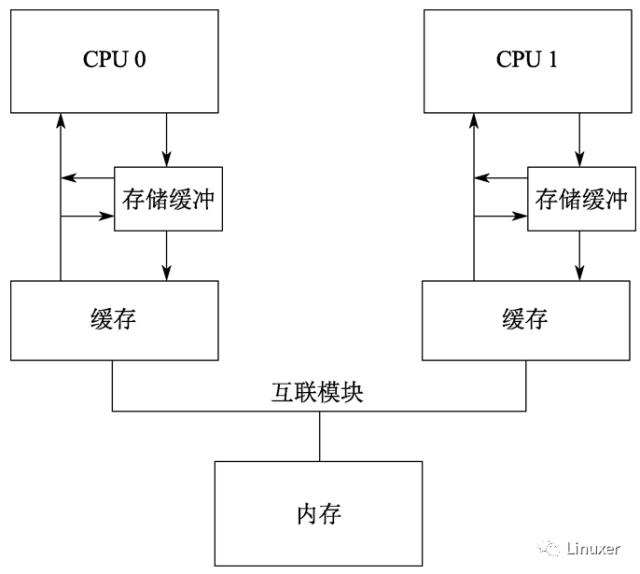
在調(diào)整后的架構(gòu)中,每個CPU在執(zhí)行加載操作時,將考慮(或者嗅探)它的Writebuffer。這樣,在前面執(zhí)行順序的第8步,將在存儲緩沖區(qū)中為“a”找到正確的值1 ,因此最終的“b”值將是2,這正是我們期望的。
Write buffer帶來的第二個困擾,是違反了全局內(nèi)存序。考慮如下的代碼順序,其中變量“a”、“b”的初始值是0。
1 void foo(void)
2 {
3 a = 1;
4 b = 1;
5 }
6
7 void bar(void)
8 {
9 while (b == 0) continue;
10 assert(a == 1);
11 }
假設(shè)CPU 0執(zhí)行foo(),CPU1執(zhí)行bar(),再進一步假設(shè)包含“a”的緩存行僅僅位于CPU1的緩存中,包含“b”的緩存行被CPU 0所擁有。那么操作順序可能如下:
1.CPU 0 執(zhí)行a = 1。緩存行不在CPU0的緩存中,因此CPU0將“a”的新值放到Write buffer,并發(fā)送一個“讀使無效”消息。
2.CPU 1 執(zhí)行while (b == 0) continue,但是包含“b”的緩存行不在它的緩存中,因此它發(fā)送一個“讀”消息。
3.CPU 0 執(zhí)行 b = 1,它已經(jīng)擁有了該緩存行(換句話說,緩存行要么已經(jīng)處于“modified”,要么處于“exclusive”狀態(tài)),因此它存儲新的“b”值到它的緩存行中。
4.CPU 0 接收到“讀”消息,并且發(fā)送緩存行中的最近更新的“b”的值到CPU1,同時將緩存行設(shè)置為“shared”狀態(tài)。
5.CPU 1 接收到包含“b”值的緩存行,并將其值寫到它的緩存行中。
6.CPU 1 現(xiàn)在結(jié)束執(zhí)行while (b ==0) continue,因為它發(fā)現(xiàn)“b”的值是1,它開始處理下一條語句。
7.CPU 1 執(zhí)行assert(a == 1),并且,由于CPU 1工作在舊的“a”的值,因此斷言驗證失敗。
8.CPU 1 接收到“讀使無效”消息,并且發(fā)送包含“a”的緩存行到CPU 0,同時在它的緩存中,將該緩存行變成無效。但是已經(jīng)太遲了。
9.CPU 0 接收到包含“a”的緩存行,并且及時將存儲緩沖區(qū)的數(shù)據(jù)保存到緩存行中,CPU1的斷言失敗受害于該緩存行。
請注意,“內(nèi)存屏障”已經(jīng)在這里隱隱約約露出了它鋒利的爪子!!!!
三、使無效隊列又是為了解決什么問題?
一波未平,另一波再起。
問題的復(fù)雜性還不僅僅在于Writebuffer,因為僅僅有Write buffer,硬件還會形成嚴(yán)重的性能瓶頸。
問題在于,每一個核的Writebuffer相對而言都比較小,這意味著執(zhí)行一段較小的存儲操作序列的CPU,很快就會填滿它的Writebuffer。此時,CPU在能夠繼續(xù)執(zhí)行前,必須等待Cache刷新操作完成,以清空它的Write buffer。
清空Cache是一個耗時的操作,因為必須要在所在CPU之間廣播MESI消息(使無效消息),并等待對這些MESI消息的響應(yīng)。為了加快MESI消息響應(yīng)速度,CPU設(shè)計者增加了使無效隊列。也就是說,CPU將接收到的使無效消息暫存起來,在發(fā)送使無效消息應(yīng)答時,并不真正將Cache中的值無效。而是等待在合適的時候,延遲使無效操作。
下圖是增加了使無效隊列的系統(tǒng)結(jié)構(gòu):
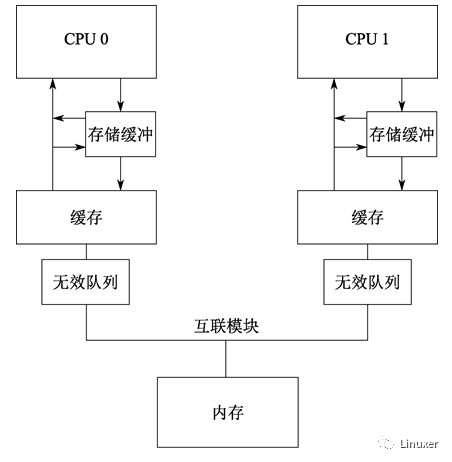
將一個條目放進使無效隊列,實際上是由CPU承諾:在發(fā)送任何與該緩存行相關(guān)的MESI協(xié)議消息前,處理該條目。在Cache競爭不太劇烈的情況下,CPU會很出色地完成此事。
使無效隊列帶來的問題是:在沒有真正將Cache無效之前,就告訴其他CPU已經(jīng)使無效了。這多少有一點欺騙的意思。然而現(xiàn)代CPU確實是這樣設(shè)計的。
這個事實帶來了額外的內(nèi)存亂序的機會,看看如下示例:
假設(shè)“a”和“b”被初始化為0,“a”是只讀的(MESI“shared”狀態(tài)),“b”被CPU 0擁有(MESI“exclusive”或者“modified”狀態(tài))。然后假設(shè)CPU 0執(zhí)行foo()而CPU1執(zhí)行bar(),代碼片段如下:
1 void foo(void)
2 {
3 a = 1;
4 smp_mb();
5 b = 1;
6 }
7
8 void bar(void)
9 {
10 while (b == 0) continue;
11 assert(a == 1);
12 }
操作順序可能如下:
1.CPU 0執(zhí)行a = 1。在CPU0中,相應(yīng)的緩存行是只讀的,因此CPU 0將“a”的新值放入存儲緩沖區(qū),并發(fā)送一個“使無效”消息,這是為了使CPU1的緩存中相應(yīng)的緩存行失效。
2.CPU 1執(zhí)行while (b == 0)continue,但是包含“b”的緩存行不在它的緩存中,因此它發(fā)送一個“讀”消息。
3.CPU 1接收到CPU 0的“使無效”消息,將它排隊,并立即響應(yīng)該消息。
4.CPU 0接收到來自于CPU 1的響應(yīng)消息,因此它放心的通過第4行的smp_mb(),從存儲緩沖區(qū)移動“a”的值到緩存行。
5.CPU 0執(zhí)行b = 1。它已經(jīng)擁有這個緩存行(也就是說,緩存行已經(jīng)處于“modified”或者“exclusive”狀態(tài)),因此它將“b”的新值存儲到緩存行中。
6.CPU 0接收到“讀”消息,并且發(fā)送包含“b”的新值的緩存行到CPU 1,同時在自己的緩存中,標(biāo)記緩存行為“shared”狀態(tài)。
7.CPU 1接收到包含“b”的緩存行并且將其應(yīng)用到本地緩存。
8.CPU 1現(xiàn)在可以完成while (b ==0) continue,因為它發(fā)現(xiàn)“b”的值為1,接著處理下一條語句。
9.CPU 1執(zhí)行assert(a == 1),并且,由于舊的“a”值還在CPU 1的緩存中,因此陷入錯誤。
10.雖然陷入錯誤,CPU 1處理已經(jīng)排隊的“使無效”消息,并且(遲到)在自己的緩存中刷新包含“a”值的緩存行。
四、內(nèi)存屏障
既然硬件設(shè)計者通過Write buffer和使無效隊列引入了額外的內(nèi)存亂序問題,那么就應(yīng)當(dāng)為軟件工程師提供某種方法來解決這個問題。即使相應(yīng)的解決方法會折磨軟件工程師。
答案就是內(nèi)存屏障。對于Linux內(nèi)核資深工程師來說,這個答案也顯得比較沉重,它太折磨人了:)
我們先看看Write buffer一節(jié)中,觸發(fā)斷言的例子,應(yīng)該怎么修改。
在那個例子中,硬件設(shè)計者不能直接幫助我們,因為 CPU沒有辦法識別那些相關(guān)聯(lián)的變量(例子中的a和b),更不用說它們?nèi)绾侮P(guān)聯(lián)。因此,硬件設(shè)計者提供內(nèi)存屏障指令,以允許軟件告訴CPU這些關(guān)系的存在。程序必須修改,以包含內(nèi)存屏障:
1 void foo(void)
2 {
3 a = 1;
4 smp_mb();
5 b = 1;
6 }
7
8 void bar(void)
9 {
10 while (b == 0) continue;
11 assert(a == 1);
12 }
內(nèi)存屏障smp_mb()將導(dǎo)致CPU在刷新后續(xù)的緩存行(包含b的緩存行)之前,前面的Write buffer被先刷新。在繼續(xù)處理之前,CPU可能采取的動作是:
1、簡單的停頓下來,直到存儲緩沖區(qū)變成空;
2、也可能是使用存儲緩沖區(qū)來持有后續(xù)的存儲操作,直到前面所有的存儲緩沖區(qū)已經(jīng)被保存到緩存行中。
理解其中第2點,能夠幫助我們理解“內(nèi)存屏障”這個單詞的來歷!!
后一種情況下,操作序列可能如下所示:
1.CPU 0執(zhí)行a= 1。緩存行不在CPU0的緩存中,因此CPU 0將“a”的新值放到存儲緩沖中,并發(fā)送一個“讀使無效”消息。
2.CPU 1 執(zhí)行while(b == 0) continue,但是包含“b”的緩存行不在它的緩存中,因此它發(fā)送一個“讀”消息。
3.CPU 0執(zhí)行smp_mb(),并標(biāo)記當(dāng)前所有存儲緩沖區(qū)的條目。(也就是說a = 1這個條目)。
4.CPU 0執(zhí)行b= 1。它已經(jīng)擁有這個緩存行了。(也就是說, 緩存行已經(jīng)處于“modified”或者“exclusive”狀態(tài)),但是在存儲緩沖區(qū)中存在一個標(biāo)記條目。因此,它不將“b”的新值存放到緩存行,而是存放到存儲緩沖區(qū)中。(但是“b”不是一個標(biāo)記條目)。
5.CPU 0接收“讀”消息,隨后發(fā)送包含原始“b”值的緩存行給CPU1。它也標(biāo)記該緩存行的復(fù)制為“shared”狀態(tài)。
6.CPU 1讀取到包含“b”的緩存行,并將它復(fù)制到本地緩存中。
7.CPU 1現(xiàn)在可以裝載“b”的值了,但是,由于它發(fā)現(xiàn)其值仍然為“0”,因此它重復(fù)執(zhí)行while語句。“b”的新值被安全的隱藏在CPU0的存儲緩沖區(qū)中。
8.CPU 1接收到“讀使無效”消息,發(fā)送包含“a”的緩存行給CPU 0,并且使它的緩存行無效。
9.CPU 0接收到包含“a”的緩存行,使用存儲緩沖區(qū)的值替換緩存行,將這一行設(shè)置為“modified”狀態(tài)。
10.由于被存儲的“a”是存儲緩沖區(qū)中唯一被smp_mb()標(biāo)記的條目,因此CPU0能夠存儲“b”的新值到緩存行中,除非包含“b”的緩存行當(dāng)前處于“shared”狀態(tài)。
11.CPU 0發(fā)送一個“使無效”消息給CPU 1。
12.CPU 1接收到“使無效”消息,使包含“b”的緩存行無效,并且發(fā)送一個“使無效應(yīng)答”消息給 CPU 0。
13.CPU 1執(zhí)行while(b == 0) continue,但是包含“b”的緩存行不在它的緩存中,因此它發(fā)送一個“讀”消息給 CPU 0。
14.CPU 0接收到“使無效應(yīng)答”消息,將包含“b”的緩存行設(shè)置成“exclusive”狀態(tài)。CPU 0現(xiàn)在存儲新的“b”值到緩存行。
15.CPU 0接收到“讀”消息,同時發(fā)送包含新的“b”值的緩存行給 CPU 1。它也標(biāo)記該緩存行的復(fù)制為“shared”狀態(tài)。
16.CPU 1接收到包含“b”的緩存行,并將它復(fù)制到本地緩存中。
17.CPU 1現(xiàn)在能夠裝載“b”的值了,由于它發(fā)現(xiàn)“b”的值為1,它退出while循環(huán)并執(zhí)行下一條語句。
18.CPU 1執(zhí)行assert(a== 1),但是包含“a”的緩存行不在它的緩存中。一旦它從CPU0獲得這個緩存行,它將使用最新的“a”的值,因此斷言語句將通過。
正如你看到的那樣,這個過程涉及不少工作。即使某些事情從直覺上看是簡單的操作,就像“加載a的值”這樣的操作,都會包含大量復(fù)雜的步驟。
前面提到的,其實是寫端的屏障,它解決Write buffer引入的內(nèi)存亂序。接下來我們看看讀端的屏障,它解決使無效隊列引入的內(nèi)存亂序。
要避免使無效隊列例子中的錯誤,應(yīng)當(dāng)再使用讀端內(nèi)存屏障:
讀端內(nèi)存屏障指令能夠與使無效隊列交互,這樣,當(dāng)一個特定的CPU執(zhí)行一個內(nèi)存屏障時,它標(biāo)記無效隊列中的所有條目,并強制所有后續(xù)的裝載操作進行等待,直到所有標(biāo)記的條目都保存到CPU的Cache中。因此,我們可以在bar函數(shù)中添加一個內(nèi)存屏障,如下:
1 void foo(void)
2 {
3 a = 1;
4 smp_mb();
5 b = 1;
6 }
7
8 void bar(void)
9 {
10 while (b == 0) continue;
11 smp_mb();
12 assert(a == 1);
13 }
有了這個變化后,操作順序可能如下:
1.CPU 0執(zhí)行a= 1。相應(yīng)的緩存行在CPU0的緩存中是只讀的,因此CPU0將“a”的新值放入它的存儲緩沖區(qū),并且發(fā)送一個“使無效”消息以刷新CPU1相應(yīng)的緩存行。
2.CPU 1 執(zhí)行while(b == 0) continue,但是包含“b”的緩存行不在它的緩存中,因此它發(fā)送一個“讀”消息。
3.CPU 1 接收到 CPU 0的“使無效”消息,將它排隊,并立即響應(yīng)它。
4.CPU 0 接收到CPU1的響應(yīng),因此它放心的通過第4行的smp_mb()語句,將“a”從它的存儲緩沖區(qū)移到緩存行。
5.CPU 0 執(zhí)行b= 1。它已經(jīng)擁有該緩存行(換句話說, 緩存行已經(jīng)處于“modified”或者“exclusive”狀態(tài)),因此它存儲“b”的新值到緩存行。
6.CPU 0 接收到“讀”消息,并且發(fā)送包含新的“b”值的緩存行給CPU1,同時在自己的緩存中,標(biāo)記緩存行為“shared”狀態(tài)。
7.CPU 1 接收到包含“b”的緩存行并更新到它的緩存中。
8.CPU 1 現(xiàn)在結(jié)束執(zhí)行while (b == 0) continue,因為它發(fā)現(xiàn)“b”的值為 1,它處理下一條語句,這是一條內(nèi)存屏障指令。
9.CPU 1 必須停頓,直到它處理完使無效隊列中的所有消息。
10.CPU 1 處理已經(jīng)入隊的“使無效”消息,從它的緩存中使無效包含“a”的緩存行。
11.CPU 1 執(zhí)行assert(a== 1),由于包含“a”的緩存行已經(jīng)不在它的緩存中,它發(fā)送一個“讀”消息。
12.CPU 0 以包含新的“a”值的緩存行響應(yīng)該“讀”消息。
13.CPU 1 接收到該緩存行,它包含新的“a”的值1,因此斷言不會被觸發(fā)。
即使有很多MESI消息傳遞,CPU最終都會正確的應(yīng)答。這一節(jié)闡述了CPU設(shè)計者為什么必須格外小心地處理它們的緩存一致性優(yōu)化操作。
但是,這里真的需要一個讀端內(nèi)存屏障么?在assert()之前,不是有個循環(huán)么?
難道在循環(huán)結(jié)束之前,會執(zhí)行assert(a == 1)?
對此有疑問的讀者,您需要補充一點關(guān)于猜測(冒險)執(zhí)行的背景知識!可以找CPU參考手冊看看。簡單的說,在循環(huán)的時候,a== 1這個比較條件,有可能會被CPU預(yù)先加載a的值到流水線中。臨時結(jié)果不會被保存到Cache或者Write buffer中,而是在CPU流水線中的臨時結(jié)果寄存器中暫存起來 。
這是不是非常的反直覺?然而事實就是如此。
審核編輯:劉清
-
計算機系統(tǒng)
+關(guān)注
關(guān)注
0文章
281瀏覽量
24089 -
Cache
+關(guān)注
關(guān)注
0文章
129瀏覽量
28304 -
LINUX內(nèi)核
+關(guān)注
關(guān)注
1文章
316瀏覽量
21619
原文標(biāo)題:謝寶友:深入理解Linux RCU:從硬件說起之內(nèi)存屏障
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
Cache和Write Buffer一般性介紹
(RTOS_SDK)mbedtls_ssl_write內(nèi)存不足怎么解決?
Cache機制的原理是什么?
為什么會出現(xiàn)中斷的概念呢?這個概念是為了解決什么問題
cache的性能和數(shù)組的組織形式有何關(guān)系呢
詳談嵌入式編程需注意的Cache機制和原理
Buffer和Cache之間區(qū)別是什么?
Linux內(nèi)核Page Cache和Buffer Cache兩類緩存的作用及關(guān)系如何






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論