") 從2023 GTC談NVIDIA硬核技術(shù)
從2023 GTC談NVIDIA硬核技術(shù)
2023 年 GTC 大會上,英偉達 CEO 發(fā)布了四個全新推理平臺,每個平臺都包含針對特定的 AIGC 推理工作負載優(yōu)化的 NVIDIA GPU 以及專用軟件:
1)用于圖像渲染和 AI 視頻的 L4。L4 提供增強的視頻解碼/轉(zhuǎn)碼、視頻流、增強現(xiàn)實以及生成 AI 視頻等功能,可提供比 CPU 高 120 倍的 AI 視頻性能,一臺 8 卡 L4 服務(wù)器能夠替代 100 多臺用于處理 AI 視頻的雙插槽 CPU 服務(wù)器。
2)用于 Omniverse、圖像生成、文本轉(zhuǎn)圖像等各類生成式 AI 的 L40。L40 針對圖形和支持 AI 的 2D、視頻和 3D 圖像生成進行了優(yōu)化。L40 平臺作為 Omniverse 的引擎,用于在數(shù)據(jù)中心構(gòu)建和運行元宇宙應(yīng)用程序,推理性能是云推理 GPU T4 的 10 倍。
3)用于大語言模型(LLM)推理的 H100 NVL。H100 NVLGPU 適用于大規(guī)模部署 ChatGPT 等大型 LLM。H100 NVL 通過 NVLINK 將兩張 H100 PCIE 橋接在一起,其中的每張卡擁有 94GB HBM3 內(nèi)存,同時內(nèi)置 Transformer 引擎。與目前唯一可以在云上處理 GPT 模型的 HXG A100 相比,一臺搭載四對 H100 NVL 和雙 GPU NVLINK 的服務(wù)器可以將推理速度提高 10 倍。
4)Grace Hopper Superchip 適用于推薦模型、向量數(shù)據(jù)庫和大型語言模型的 AI 數(shù)據(jù)庫,并通過 NVLink-C2C 技術(shù)為 Grace CPU 和 Hopper GPU 之間提供高達 900GB/s 的高速連接,CPU 查詢和存儲巨型嵌入表,GPU 負責(zé)將收到的結(jié)果進行推理,整體是 PCIE 速度的 7 倍。
一、DGX CloudAI超級計算服務(wù)DGX Cloud提供專用的NVIDIA DGX AI超級計算集群,搭配NVIDIA AI軟件,可讓企業(yè)立即訪問為生成AI和其他突破性應(yīng)用程序訓(xùn)練高級模型所需的基礎(chǔ)設(shè)施和軟件。該服務(wù)使每個企業(yè)都可以使用簡單的網(wǎng)絡(luò)瀏覽器訪問自己的AI超級計算機,企業(yè)按月租用DGX Cloud集群,確保可快速輕松地擴展大型多節(jié)點訓(xùn)練工作負載的開發(fā),而無需等待通常需求量很大的加速計算資源。 NVIDIA Base Command平臺軟件:可使用其管理和監(jiān)控DGX Cloud訓(xùn)練工作負載,該軟件可在DGX Cloud以及本地NVIDIA DGX超級計算機上提供無縫的用戶體驗。使用Base Command Platform,客戶可將其工作負載與每項工作所需的正確數(shù)量和類型的DGX基礎(chǔ)設(shè)施相匹配。DGX Cloud包括NVIDIA AI Enterprise,平臺的軟件層,提供端到端的AI框架和預(yù)訓(xùn)練模型。今日發(fā)布的NVIDIA AI Enterprise 3.1提供了新的預(yù)訓(xùn)練模型、優(yōu)化框架和加速數(shù)據(jù)科學(xué)軟件庫,為開發(fā)人員的AI項目提供了額外的快速啟動。行業(yè)巨頭案例:
①Amgen(世界領(lǐng)先的生物技術(shù)公司之一)正在使用DGX Cloud和NVIDIA BioNeMo大型語言模型軟件來加速藥物發(fā)現(xiàn),包括NVIDIA AI Enterprise軟件,內(nèi)含NVIDIA RAPIDS數(shù)據(jù)科學(xué)加速庫。
②CCC Intelligent Solutions (領(lǐng)先的財產(chǎn)和意外傷害保險經(jīng)濟云平臺,CCC)正在使用DGX Cloud來加速和擴展其AI模型的開發(fā)和培訓(xùn)。
③ServiceNow(數(shù)字業(yè)務(wù)平臺提供商)將DGX Cloud與本地NVIDIA DGX超級計算機結(jié)合使用,以實現(xiàn)靈活、可擴展的混合云AI超級計算,這有助于推動其在大型語言模型、代碼生成和因果分析方面的AI研究。二、Picasso Service云服務(wù)
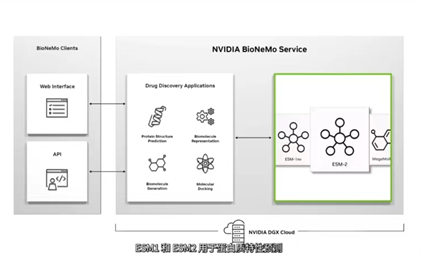
用途:用于構(gòu)建和部署生成式AI驅(qū)動的圖像、視頻和3D應(yīng)用程序,具有高級文本到圖像、文本到視頻和文本轉(zhuǎn)3D功能,可通過簡單云API提高創(chuàng)造力、設(shè)計和數(shù)字模擬的生產(chǎn)力。用法:軟件制造商、服務(wù)提供商和企業(yè)可使用Picasso在其專有數(shù)據(jù)上訓(xùn)練NVIDIA Edify基礎(chǔ)模型,以構(gòu)建使用自然文本提示的應(yīng)用程序,從而為數(shù)百個用例快速創(chuàng)建和定制視覺內(nèi)容,包括產(chǎn)品設(shè)計、數(shù)字孿生、講故事和人物創(chuàng)作。拓展:要構(gòu)建自定義應(yīng)用程序,企業(yè)還可以從Picasso的Edify模型集開始,這些模型使用完全許可的數(shù)據(jù)進行預(yù)訓(xùn)練,還可以使用Picasso來優(yōu)化和運行生成式AI模型。三、NVIDIA BioNeMo服務(wù)BioNeMo Service是一種用于早期藥物發(fā)現(xiàn)中生成AI的云服務(wù),具有九種最先進的大型語言和擴散模型。可通過Web界面或完全托管的API訪問,并且可以在NVIDIA DGX Cloud上進一步訓(xùn)練和優(yōu)化,生物學(xué)生成式AI的工作流程得到了優(yōu)化和統(tǒng)包。 BioNeMo服務(wù)具有九個AI生成模型,涵蓋了開發(fā)AI藥物發(fā)現(xiàn)管道的廣泛應(yīng)用:AlphaFold 2、ESMFold和OpenFold用于根據(jù)一級氨基酸序列預(yù)測3D蛋白質(zhì)結(jié)構(gòu)、用于蛋白質(zhì)特性預(yù)測的ESM-1nv和ESM-2、用于蛋白質(zhì)生成的ProtGPT2、MegaMolBART和MoFlow用于小分子生成、用于預(yù)測小分子與蛋白質(zhì)結(jié)合結(jié)構(gòu)的DiffDock等。
四、推出四種配置:L4、L40、H100 NVL、Grace Hopper
L4:一臺8-GPU L4服務(wù)器將取代一百多臺用于處理AI視頻的雙插槽CPU服務(wù)器。L40:針對Omniverse、圖形渲染以及文本轉(zhuǎn)圖像和文本轉(zhuǎn)視頻等生成式AI,推出L40,其性能是云推理GPU T4的10倍。
H100 NVL:針對ChatGPT等大型語言模型的推理,推出Hopper GPU,配備雙GPU NVLink的 PCIE H100 , H100 NVL配備94GB HBM3顯存,可處理擁有1750億參數(shù)的GPT-3, 同時還可支持商用PCIE服務(wù)器輕松擴展。
Grace Hopper:新超級芯片,通過900GB/秒高速一致性芯片到芯片接口,非常適合處理大型數(shù)據(jù)集,例如推薦系統(tǒng)和大型語言模型的AI數(shù)據(jù)庫借助Grace Hopper,Grace可以查詢嵌入表,并將結(jié)果直接傳入到Hopper,速度比PCIE快7倍。
五、Omniverse應(yīng)用Omniverse是實現(xiàn)工業(yè)數(shù)字化的數(shù)字到物理操作系統(tǒng),是云原生,同時不限平臺,可讓團隊隨時隨地在我們的虛擬工場中展開協(xié)作。Omniverse網(wǎng)絡(luò)中的網(wǎng)絡(luò)正在呈指數(shù)級增長,還連接了Siemens Teamcenter、NX和Process Simulate、RockWell Automation Emulate3D、Cesium、Unity等許多應(yīng)用。應(yīng)用于汽車企業(yè)數(shù)字化:①沃爾沃汽車公司和通用汽車使用Omniverse USD Composer連接和統(tǒng)一其資產(chǎn)工作流,并將汽車零部件在虛擬環(huán)境中組裝成數(shù)字孿生汽車,在工程和仿真中, Omniverse將Powerflow空氣動力學(xué)可視化。 ②新一代梅賽德斯-奔馳和捷豹陸虎汽車,使用Omniverse Drive Sim生成,梅賽德斯奔馳使用Omniverse為新車型構(gòu)建、優(yōu)化和規(guī)劃組裝流水線。 ③豐田公司使用Omniverse構(gòu)建工廠的數(shù)字孿生。
三款專為Omniverse設(shè)計的系統(tǒng):
①新工作站,由NVIDIA Ada RTX GPU和英特爾最新款CPU提供動力支持,適合光線追蹤、物理仿真、神經(jīng)圖形和生成式AI,2023年3月起,BOXX、戴爾、惠普、聯(lián)想將提供這款工作站。
②新型NVIDIA OVX服務(wù)器,由Omniverse優(yōu)化而來,OVX由服務(wù)器GPU Ada RTX L40和BlueField-3組成,將由戴爾、HPE、Quanta、技嘉、聯(lián)想和Supermicro提供。
③Omniverse Cloud,基于NVIDIA OVX運算系統(tǒng)推出, 每一層Omniverse堆棧包括芯片、系統(tǒng)、網(wǎng)絡(luò)和軟件都是新發(fā)明,正將Omniverse連接到微軟365生產(chǎn)力套件。
六、超算及云服務(wù)
發(fā)布Grace、Grace-Hopper和BlueField-3三款新芯片,適用于超級節(jié)能加速數(shù)據(jù)中心,更新了100個加速庫,包括用于量子計算的cuQuantum、用于組合優(yōu)化的cuOpt、以及用于計算光刻的cuLitho(與臺積電、ASML和Synopsys合作,達到2nm及更高制程),可將計算光刻用時提速40倍。計算光刻:500套DGX H100(包含4000顆Hopper GPU)可完成與4萬顆CPU運算服務(wù)器相同的工作量,但速度快40倍,功耗低9倍,即意味著GPU加速后,生產(chǎn)光掩模的計算光刻工作用時可以從幾周減少到八小時。 NVIDIA DGX AI超級計算機是生成式大型言模型取得突破的引擎,DGX H100 AI超級計算機正在生產(chǎn),并即將通過全球不斷擴大的OEM和云服務(wù)合作伴網(wǎng)絡(luò)面世。DGX沒有止步于研究,正在成為現(xiàn)代化AI工廠,Nvidia通過與Azure、Google GCP、Oracle OCI合作,拓展NVIDIA DGX Cloud業(yè)務(wù)模式。
七、總結(jié)
英偉達推出了新的推理平臺,包括四種配置和一個體系架構(gòu):
①適用于處理AI視頻的8-GPU服務(wù)器L4。
②適用于Omniverse和圖形渲染的L40。
③適用于擴展LLM推理的H100PCIE。
④適用于推薦系統(tǒng)和向量數(shù)據(jù)庫的Grace-Hopper。 此外,通過與Google合作,Google GCP成為首款NVIDIA AI云,NVIDIA AI Foundations是一個云服務(wù)和代工廠,用于構(gòu)建自定義語言模型和生成式AI,包括語言視覺和生物學(xué)模型構(gòu)建服務(wù)。
Omniverse是實現(xiàn)工業(yè)數(shù)字化的數(shù)字到物理操作系統(tǒng),可以統(tǒng)一端到端工作流,并將價值3萬億美元的汽車行業(yè)數(shù)字化;在Azure上進行托管,與微軟合作,將Omniverse Cloud引入各行業(yè)。
審核編輯 :李倩
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4940瀏覽量
102815 -
超級計算機
+關(guān)注
關(guān)注
2文章
460瀏覽量
41923 -
數(shù)字化
+關(guān)注
關(guān)注
8文章
8610瀏覽量
61639
原文標(biāo)題:從2023 GTC談NVIDIA硬核技術(shù)
文章出處:【微信號:AI_Architect,微信公眾號:智能計算芯世界】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
【限時領(lǐng)取精美禮品】報名2022 GTC大會,與行業(yè)大咖探索 AI 前沿科技
助力AI產(chǎn)業(yè)落地,云知聲展示全棧AI硬核技術(shù)
小米將投入資金超100億元,爭取在“硬核技術(shù)”上突圍
GTC2022大會亮點:RAPIDS是NVIDIA備受歡迎的NVIDIA SDK之一

GTC23 | 倒計時 5 天,火速收藏 NVIDIA 高性能加速網(wǎng)絡(luò)專場預(yù)約攻略!
NVIDIA GTC 2023看點:AI計算系統(tǒng)、生成式AI 、工業(yè)元宇宙與機器人

NVIDIA GTC 2023:GPU算力是AI的必需品
NVIDIA GTC 2023:摩爾定律的動力來源是AI

英偉達 GTC 2023上黃仁勛談生成式AI

GTC 2023上英偉達發(fā)布NVIDIA DGX Cloud人工智能云服務(wù)

GTC 2023:NVIDIA cuLitho將加速計算引入計算光刻技術(shù)領(lǐng)域的突破性成果

GTC 2023上黃仁勛談AI ChatGPT僅是一個起點NVIDIA將AI引入各行各業(yè)

GTC 2023 NVIDIA將加速計算引入半導(dǎo)體光刻 計算光刻技術(shù)提速40倍

自動駕駛資訊集錦:GTC 最新發(fā)布及汽車數(shù)字工廠精彩視頻!
周五研討會預(yù)告 | 回顧 GTC23 精彩內(nèi)容,助力創(chuàng)業(yè)生態(tài)發(fā)展 — NVIDIA 初創(chuàng)加速計劃 Omniverse 加速營






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論