") 計(jì)算機(jī)編碼全解析(中)
計(jì)算機(jī)編碼全解析(中)
4.MBCS、DBCS
前面說(shuō)的ASCII,EASCII,ISO-8859中的每個(gè)字符使用的是8-bits表示的,所以稱(chēng)為“ 單字節(jié)字符集 ”(Single-Byte Character Set,簡(jiǎn)稱(chēng)SBCS)。
但是到了亞洲,如中,日,韓等國(guó)家每個(gè)文字就是一個(gè)字符,對(duì)于單字節(jié)的字符集來(lái),遠(yuǎn)遠(yuǎn)放不下了,于是亞洲國(guó)家制定了自己的字符集“多字節(jié)字符集” (Multi-Bytes Character Sets,簡(jiǎn)稱(chēng)MBCS)
windows 系統(tǒng)中,本地字符集就是MBCS,不過(guò)由于大部分字符是2字節(jié)的,所以又稱(chēng)為“雙字節(jié)字符集”(Double-Bytes Character Sets,簡(jiǎn)稱(chēng)DBCS),所以有的時(shí)候看到MBCS、DBCS,都是一回事。 MBCS是完全兼容標(biāo)準(zhǔn)ASCII碼的 。
5.GB2312、GBK、
當(dāng)計(jì)算機(jī)被引入中國(guó)后,相關(guān)部門(mén)設(shè)計(jì)了GB系列規(guī)范(GB為國(guó)家的拼音縮寫(xiě))。按照GB系列編碼方案,在一段文本中,如果一個(gè)字節(jié)是0~127,那么這個(gè)字節(jié)的含義與ASCII編碼相同,否則,這個(gè)字節(jié)和下一個(gè)字節(jié)共同組成漢字(或是GB編碼定義的其他字符)。因此,GB系列編碼方案向下完全直接兼容ASCII編碼方案。也就是說(shuō),如果當(dāng)前文本中使用的字符全是ASCII中的字符,則其GB編碼和ASCII編碼是完成一樣的。
GB2312是最早的GB編碼格式,收入了不足一萬(wàn)個(gè)漢字,基本能滿(mǎn)足日常需求,但是中國(guó)文件可是博大精深,區(qū)區(qū)一萬(wàn)字肯定無(wú)法滿(mǎn)足,于是又在GB2312基礎(chǔ)上進(jìn)行了擴(kuò)展, 擴(kuò)展后的編碼方案稱(chēng)之為GBK (K是擴(kuò)的拼音縮寫(xiě)),后來(lái)又在GBK的基礎(chǔ)上擴(kuò)了GB18030編碼方案,增加了一些少數(shù)名族的文字,一些生僻字被編到4個(gè)字節(jié)。
GB2312,GBK,GB18030(不包括GB13000)每次擴(kuò)展都會(huì)完全兼容前一個(gè)版本 。這里要指出,雖然都用多個(gè)字節(jié)表示一個(gè)字符,但是GB類(lèi)的漢字編碼與后文的Unicode編碼方案的UTF-8、UTF-16、UTF-32等字符編碼方式是毫無(wú)關(guān)系的
不過(guò),也正因?yàn)椴坏貌皇褂枚鄠€(gè)字節(jié)來(lái)表示一個(gè)字符,相較于只使用單個(gè)字節(jié)的ASCII編碼方案,GB系列編碼方案與后面要介紹的Unicode編碼方案一樣,無(wú)疑導(dǎo)致了更高的復(fù)雜度(包括時(shí)間復(fù)雜度、空間復(fù)雜度等)。
比如, 當(dāng)多字節(jié)字符與原先的ASCII字符混用時(shí) :
- 1) 要么將原先的ASCII字符重新編碼為多個(gè)字節(jié)表示,以便與其他多字節(jié)字符統(tǒng)一起來(lái)(UTF-16、UTF-32等采用的就是這種方法 );
- 2)要么保持ASCII字符為單個(gè)字節(jié)編碼不變,但將其他多字節(jié)字符編碼中的各個(gè)字節(jié)的最高位(即首位)設(shè)為1,以避免與字節(jié)最高位為0的ASCII編碼相沖突(GB、UTF-8等采用的就是這種方法) 。
前者具有更高的空間復(fù)雜度,因?yàn)樵戎恍枰獑蝹€(gè)字節(jié)表示的ASCII字符,現(xiàn)在也必須用多個(gè)字節(jié)來(lái)表示,顯然更為耗費(fèi)存儲(chǔ)空間;后者則具有更高的時(shí)間復(fù)雜度,因?yàn)闉榱吮苊鉀_突以及其他種種考慮(比如擴(kuò)展性、容錯(cuò)性等),使用了更為復(fù)雜的編碼算法(Encoding Algorithm),無(wú)疑更為耗費(fèi)計(jì)算時(shí)間。
GB2312
GB2312編碼方案,即《信息交換用漢字編碼字符集——基本集》,是由中國(guó)國(guó)家標(biāo)準(zhǔn)總局于1980年發(fā)布、1981年5月1日開(kāi)始實(shí)施的一套國(guó)家標(biāo)準(zhǔn),標(biāo)準(zhǔn)號(hào)為GB2312-1980。
GB2312編碼適用于漢字處理、漢字通信等系統(tǒng)之間的信息交換,通行于中國(guó)大陸 ;新加坡等地也采用此編碼。中國(guó)大陸幾乎所有的中文系統(tǒng)和國(guó)際化的軟件都支持GB2312。
GB2312編碼為了兼容ASCII碼,所有的編碼的字節(jié)都是從0x7F之后開(kāi)始的,一個(gè)漢字使用兩字節(jié)來(lái)表示,一個(gè)高字節(jié)一個(gè)低字節(jié),如果一個(gè)字節(jié)的小余0x7F的值,則表示的是一個(gè)ASCII碼值。
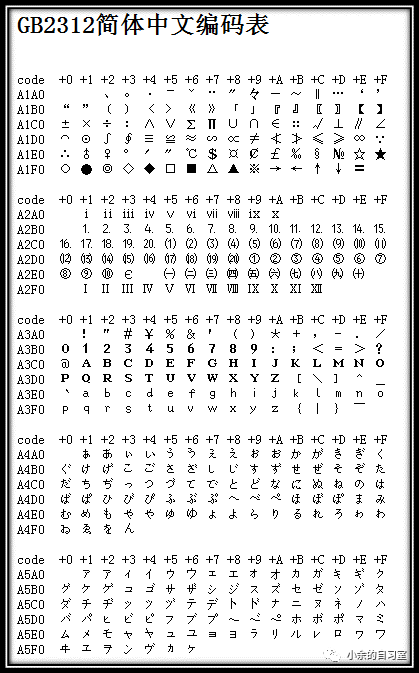
雖然GB2312完全兼容ASCII碼,但是其并不兼容其他擴(kuò)碼,如EASCII。
GB2312標(biāo)準(zhǔn)共收錄6763個(gè)漢字,其中一級(jí)漢字3755個(gè),二級(jí)漢字3008個(gè);同時(shí),除了漢字,GB2312還收錄了包括拉丁字母、希臘字母、日文平假名及片假名字符、俄語(yǔ)西里爾字母在內(nèi)的 682個(gè)字符 。
可能是處于美觀的考慮,除了漢字外的682個(gè)字符中,包括ASCII里本來(lái)就有的數(shù)字、標(biāo)點(diǎn)、字母等字符,又再次編寫(xiě)了兩字長(zhǎng)的GB2312版本。 這682個(gè)雙字節(jié)編碼字符就是常說(shuō)的“全角”字符,而這些字符所對(duì)應(yīng)的單字節(jié)編碼的ASCII字符就被稱(chēng)之為“半角”字符。
全角、半角
全角字符是中文顯示及雙字節(jié)中文編碼的歷史遺留問(wèn)題。
早期的點(diǎn)陣顯示器上由于像素有限,原先ASCII西文字符的顯示寬度(比如8像素的寬度)用來(lái)顯示漢字有些捉襟見(jiàn)肘(實(shí)際上早期的針式打印機(jī)在打印輸出時(shí)也存在這個(gè)問(wèn)題),因此就采用了兩倍于ASCII字符的顯示寬度(比如16像素的寬度)來(lái)顯示漢字。
這樣一來(lái),ASCII西文字符在顯示時(shí)其寬度為漢字的一半。或許是為了在西文字符與漢字混合排版時(shí),讓西文字符能與漢字對(duì)齊等視覺(jué)美觀上的考慮,于是就設(shè)計(jì)了讓西文字母、數(shù)字和標(biāo)點(diǎn)等特殊字符在外觀視覺(jué)上也占用一個(gè)漢字的視覺(jué)空間(主要是寬度),并且在內(nèi)部存儲(chǔ)上也同漢字一樣使用2個(gè)字節(jié)進(jìn)行存儲(chǔ)的方案。這些與漢字在顯示寬度上一樣的西文字符就被稱(chēng)之為全角字符。
而原來(lái)ASCII中的西文字符由于在外觀視覺(jué)上僅占用半個(gè)漢字的視覺(jué)空間(主要是寬度),并且在內(nèi)部存儲(chǔ)上使用1個(gè)字節(jié)進(jìn)行存儲(chǔ),相對(duì)于全角字符,因而被稱(chēng)之為半角字符。
后來(lái),其中的一些全角字符因?yàn)楸容^有用,就得到了廣泛應(yīng)用(比如全角的逗號(hào)“,”、問(wèn)號(hào)“?”、感嘆號(hào)“!”、空格“”等,這些字符在輸入法中文輸入狀態(tài)下的半角與全角是一樣的,英文輸入狀態(tài)下全角跟中文輸入狀態(tài)一樣,但半角大約為全角的二分之一寬),專(zhuān)用于中日韓文本,成為了標(biāo)準(zhǔn)的中日韓標(biāo)點(diǎn)字符。而其它的許多全角字符則逐漸失去了價(jià)值(現(xiàn)在很少需要讓純文本的中文和西文字符對(duì)齊了),就很少再用了。
現(xiàn)在全球字符編碼的事實(shí)標(biāo)準(zhǔn)是Unicode字符集及基于此的UTF-8、UTF-16等編碼實(shí)現(xiàn)方式。Unicode吸納了許多遺留(legacy)編碼,并且為了兼容性而保留了所有字符。因此中文編碼方案中的這些全角字符也保留下來(lái)了,而國(guó)家標(biāo)準(zhǔn)也仍要求字體和軟件都支持這些全角字符。
不過(guò),半角和全角字符的關(guān)系在UTF-8、UTF-16等中不再是簡(jiǎn)單的1字節(jié)和2字節(jié)的關(guān)系了。具體參見(jiàn)后文。
GBK
GB2312-1980共收錄6763個(gè)漢字,覆蓋了中國(guó)大陸99.75%的使用頻率,基本滿(mǎn)足了漢字的計(jì)算機(jī)處理需要。
但對(duì)于人名、古漢語(yǔ)等方面出現(xiàn)的罕用字、生僻字,GB2312不能處理,如部分在GB2312-1980推出以后才簡(jiǎn)化的漢字(如“啰”)、部分人名用字(如歌手陶喆的“喆”字)、臺(tái)灣及香港使用的繁體字、日語(yǔ)及朝鮮語(yǔ)漢字等,并未收錄在內(nèi)。
于是全國(guó)信息技術(shù)標(biāo)準(zhǔn)化技術(shù)委員會(huì)利用GB2312-1980未使用的碼點(diǎn)空間,收錄GB13000.1-1993的全部字符,于1995年12月1日發(fā)布了《漢字內(nèi)碼擴(kuò)展規(guī)范(GBK)》(Guo-Biao Kuozhan國(guó)家標(biāo)準(zhǔn)擴(kuò)展碼,是根據(jù)GB13000.1-1993(GB13000下文有詳細(xì)介紹),對(duì)GB2312-1980的擴(kuò)展;英文全稱(chēng)Chinese Internal Code Specification)
雖然GBK跟GB2312一樣是雙字節(jié)編碼,但GBK只要求第一個(gè)字節(jié)即高字節(jié)大于127就固定表示這是一個(gè)漢字的開(kāi)始(即GBK編碼高字節(jié)的首位必須是1;0~127當(dāng)然表示的還是ASCII字符),不再像GB2312一樣要求第二個(gè)字節(jié)即低字節(jié)也必須大于127(即GBK編碼低字節(jié)首位既可以是0,也可以是1)。
正因?yàn)槿绱耍鳛橥瑯邮请p字節(jié)編碼的GBK才可以收錄比GB2312更多的字符。
GBK字符集向后完全兼容GB2312,同時(shí)還支持GB2312-1980不支持的部分中文簡(jiǎn)體、中文繁體、日文(不過(guò)該字符集不支持韓國(guó)文字,也是其在實(shí)際使用中與Unicode字符集相比欠缺的部分),共收錄漢字21003個(gè)、符號(hào)883個(gè),并提供1894個(gè)造字碼位,簡(jiǎn)、繁體字融于一體。

GBK的編碼框架(Code Scheme):其中GBK/1收錄除GB2312字符外的其他增補(bǔ)字符,GBK/2收錄GB2312字符,GBK/3收錄CJK字符,GBK/4收錄CJK字符和增補(bǔ)字符,GBK/5為非中文字符,UDC為用戶(hù)自定義字符
GB18030
中國(guó)國(guó)家質(zhì)量技術(shù)監(jiān)督局于2000年3月17日推出了GB18030-2000標(biāo)準(zhǔn),以取代GBK。GB18030-2000除保留全部GBK編碼漢字之外,在第二字節(jié)再度進(jìn)行擴(kuò)展,增加了大約一百個(gè)漢字及四位元組編碼空間。
GB18030《信息交換用漢字編碼字符集基本集的補(bǔ)充》是我國(guó)繼GB2312-1980和GB13000-1993之后最重要的漢字編碼標(biāo)準(zhǔn),是我國(guó)計(jì)算機(jī)系統(tǒng)必須遵循的基礎(chǔ)性標(biāo)準(zhǔn)之一。
2005年,GB18030編碼方案在GB18030-2000的基礎(chǔ)上又進(jìn)行了擴(kuò)充,于是又有了GB18030-2005《信息技術(shù)中文編碼字符集》。
如前所述,GB18030-2000是GBK的升級(jí)版本,它的主要特點(diǎn)是在GBK基礎(chǔ)上增加了CJK中日韓統(tǒng)一表意文字?jǐn)U充A的漢字;而GB18030-2005的主要特點(diǎn)是在GB18030-2000基礎(chǔ)上又增加了CJK中日韓統(tǒng)一表意文字?jǐn)U充B的漢字。
微軟也為GB18030定義了專(zhuān)門(mén)的代碼頁(yè):CP54936,但是這個(gè)代碼頁(yè)實(shí)際上并沒(méi)有真正使用(在Windows 7的“控制面板”-“區(qū)域和語(yǔ)言”-“管理”-“非Unicode程序的語(yǔ)言”中沒(méi)有提供選項(xiàng);在Windows cmd命令行中可通過(guò)命令chcp 54936更改,之后在cmd中可顯示中文,但卻不支持中文輸入)。
GB13000
在所有的GB編碼方案中,除了逐步擴(kuò)展并保持向下兼容的GB2312、GBK、GB18030等GB系列編碼方案,還有一個(gè)與GB2312、GBK、GB18030等GB系列編碼方案不兼容的、 特殊的GB編碼方案——GB13000編碼方案 。(注意,雖然GBK的制定,主要目的就是為了收錄GB13000中的所有字符,但G BK的編碼方式與GB13000是完全不同的 。因此,習(xí)慣上所稱(chēng)的GB系列編碼方案一般并不包括GB13000在內(nèi)。)
為了對(duì)世界各個(gè)國(guó)家和地區(qū)的所有字符進(jìn)行統(tǒng)一編碼,以實(shí)現(xiàn)對(duì)世界上所有字符在計(jì)算機(jī)上的統(tǒng)一處理,國(guó)際標(biāo)準(zhǔn)化組織制定了新的編碼標(biāo)準(zhǔn)——ISO/IEC 10646標(biāo)準(zhǔn)(即Universal Character Set通用字符集,簡(jiǎn)稱(chēng)UCS,與統(tǒng)一聯(lián)盟制定的Unicode標(biāo)準(zhǔn)兼容,兩者的關(guān)系詳見(jiàn)后文)。
為了與國(guó)際標(biāo)準(zhǔn)接軌,中國(guó)于是制定了與ISO/IEC 10646.1:1993標(biāo)準(zhǔn)相對(duì)應(yīng)的中國(guó)國(guó)家標(biāo)準(zhǔn)——GB13000.1-1993 《信息技術(shù)通用多八位編碼字符集(UCS)第一部分:體系結(jié)構(gòu)與基本多文種平面》。
2010年又發(fā)布了其替代標(biāo)準(zhǔn)——GB13000-2010《信息技術(shù)通用多八位編碼字符集(UCS)》,此標(biāo)準(zhǔn)等同于國(guó)際標(biāo)準(zhǔn)ISO/IEC 10646:2003《信息技術(shù)通用多八位編碼字符集(UCS)》。
GB13000與國(guó)際標(biāo)準(zhǔn)ISO/IEC10646及Unicode標(biāo)準(zhǔn)目前在基本平面(即BMP,詳見(jiàn)后文)上基本保持一致。
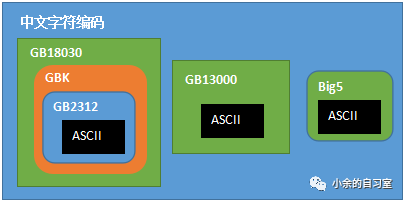
各漢字(中文字符)編碼方案之間的關(guān)系(Big5為繁體漢字編碼方案,主要通行于港澳臺(tái)地區(qū),本文不作詳細(xì)介紹)
6.ANSI 編碼
ANSI原意是指美國(guó)國(guó)家標(biāo)準(zhǔn)協(xié)會(huì),但是在windows系統(tǒng)中,ANSI編碼意思卻代表“本地編碼”。 。也就是說(shuō),在中國(guó)代表GBK,在臺(tái)灣代表Big5,在日本代表JIS,所以windows編程中常說(shuō)的ANSI字符串,就是指本地編碼的字符串,在中國(guó),就是一種DBCS,用1個(gè)和2個(gè)字節(jié)表示一個(gè)字符的編碼。
這也就是我們使用Notepad++進(jìn)行文件編寫(xiě)的時(shí)候,會(huì)默認(rèn)給我們提供ANSI的編碼格式,其實(shí)就是GBK編碼啦。
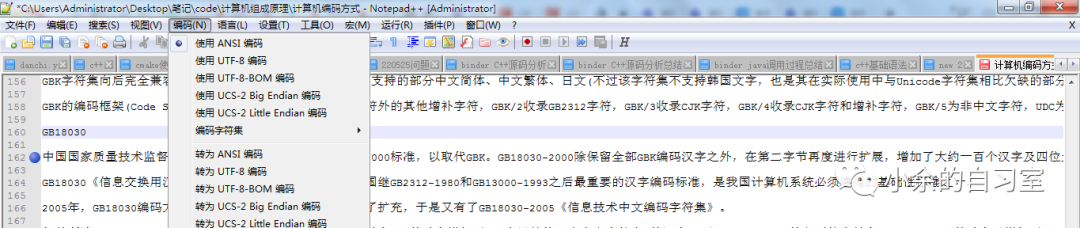
事實(shí)上并沒(méi)有ANSI編碼,ANSI是什么,是American National Standards Institute美國(guó)國(guó)家標(biāo)準(zhǔn)協(xié)會(huì),協(xié)會(huì),機(jī)構(gòu)而已。ANSI也有自己的ASCII標(biāo)準(zhǔn)。但是我們看到的這個(gè)ANSI并不是特指ANSI的ASCII標(biāo)準(zhǔn),這個(gè)應(yīng)該指所有的本地化編碼。
這個(gè)是微軟的鍋 。一開(kāi)始只有英文操作系統(tǒng),用ANSI表示ANSI的Extend ASCII編碼。但是到了歐洲就是ISO-8859-1編碼,到中國(guó)應(yīng)該是GBK編碼,日本應(yīng)該是JIS編碼等等,為了把實(shí)際編碼的差異隱藏起來(lái),用所謂的ANSI編碼來(lái)表示所有Windows系統(tǒng)上的地區(qū)化編碼,然后操作系統(tǒng)自己做轉(zhuǎn)換,不同的國(guó)家地區(qū),就會(huì)對(duì)應(yīng)不同的編碼規(guī)范。ANSI應(yīng)該叫地區(qū)化編碼,只出現(xiàn)在Windows系統(tǒng)中,就好像一種工廠模式,被Windows系統(tǒng)用來(lái)統(tǒng)一地區(qū)化編碼的叫法。
-
計(jì)算機(jī)
+關(guān)注
關(guān)注
19文章
7430瀏覽量
87733 -
編碼
+關(guān)注
關(guān)注
6文章
935瀏覽量
54771 -
BUG
+關(guān)注
關(guān)注
0文章
155瀏覽量
15653
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
在計(jì)算機(jī)與第三方設(shè)備通信時(shí),常用的計(jì)算機(jī)編碼
計(jì)算機(jī)在教學(xué)中的應(yīng)用
什么是計(jì)算機(jī)系統(tǒng)、計(jì)算機(jī)硬件和計(jì)算機(jī)軟件?
什么是計(jì)算機(jī)
計(jì)算機(jī)應(yīng)用基礎(chǔ)課程
用SD卡設(shè)計(jì)8086全硅計(jì)算機(jī)的硬盤(pán)
計(jì)算機(jī)尋址方式解析
可穿戴計(jì)算機(jī)中的語(yǔ)音識(shí)別、編碼和合成等技術(shù)的介紹

量子計(jì)算機(jī)的優(yōu)點(diǎn)_量子計(jì)算機(jī)的應(yīng)用_量子計(jì)算機(jī)的未來(lái)應(yīng)用
從5個(gè)方面來(lái)解析計(jì)算機(jī)中的字符編碼概念

計(jì)算機(jī)算術(shù)運(yùn)算實(shí)現(xiàn)原理全解
計(jì)算機(jī)編碼全解析(上)

計(jì)算機(jī)編碼全解析(下)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論