 字節跳動在令牌桶限速器優化上的實踐
字節跳動在令牌桶限速器優化上的實踐
限速器(rate limiter)是一個非常基礎的網絡包處理功能,被廣泛應用于各類網元設備,在流量調度、網絡安全等領域發揮著重要作用。常見的限速器的實現方式基于令牌桶(token bucket),盡管令牌桶的原理已經被人熟知,在具體實踐中,我們也發現了一些挑戰和共性問題。本文總結了近兩年字節跳動系統與技術工程團隊(簡稱 STE 團隊)在限速器優化方面的一些探索,將一些經驗和教訓總結出來,以饗讀者。
令牌桶限速器的基本原理
相信每個寫網絡包處理的工程師都寫過基本的令牌桶限速器。令牌桶是一個形象的描述,既可以想象有一個桶可以容納一定量的令牌(token),每放行一個數據包便消耗一定量的令牌,數據包的放行與否取決于令牌桶中的令牌個數。
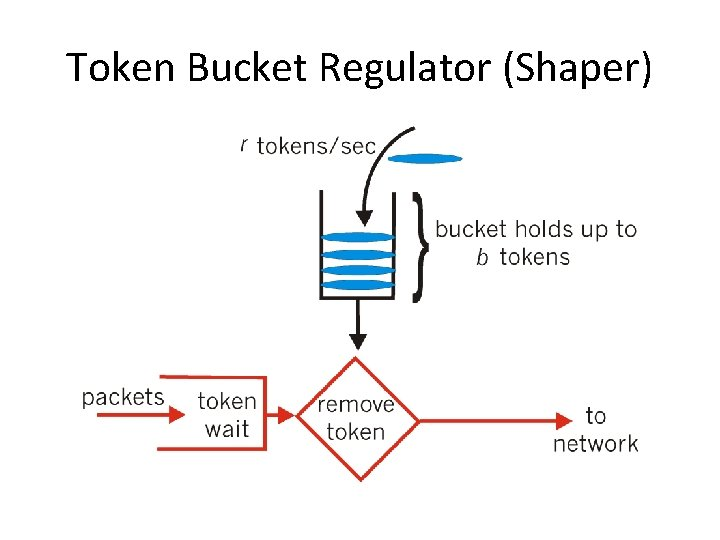
圖1 令牌桶圖示

在具體實踐中,令牌桶具有實現簡單、效率高等特點,在很多場景下,提到限速器,基本是令牌桶的代名詞。
存在的問題
在具體工程時間中,我們遇到了以下三個問題:
1. 精度問題
實際工程實踐中,時間計量單位其實是受限于系統,比如時間戳可能是以微秒(us)為單位,而每次計算的時間差可能只有 1~2us。那么一個 PPS=300K 的限速器,可能一次計算,所產生的令牌是 0.3 個,容易被整數運算忽略。最終的結果則是,實際限制為 300K/s,最后效果是只有 250Kpps 流量放行。精度過低,效果不理想。
這種解決方式也比較簡單,可以讓一個數據包消耗的令牌量不是 1個,而是 1000個。這樣,即使 1us,令牌桶產生的令牌數是 300個,而非 0.3個,這樣便保證了精度。但此時又引入了新的問題,因為令牌數擴大了 1000 倍,此時需要考慮令牌桶的深度是否會溢出 32bit。一旦溢出,則會出現其他詭異的問題。
2. 級聯補償問題
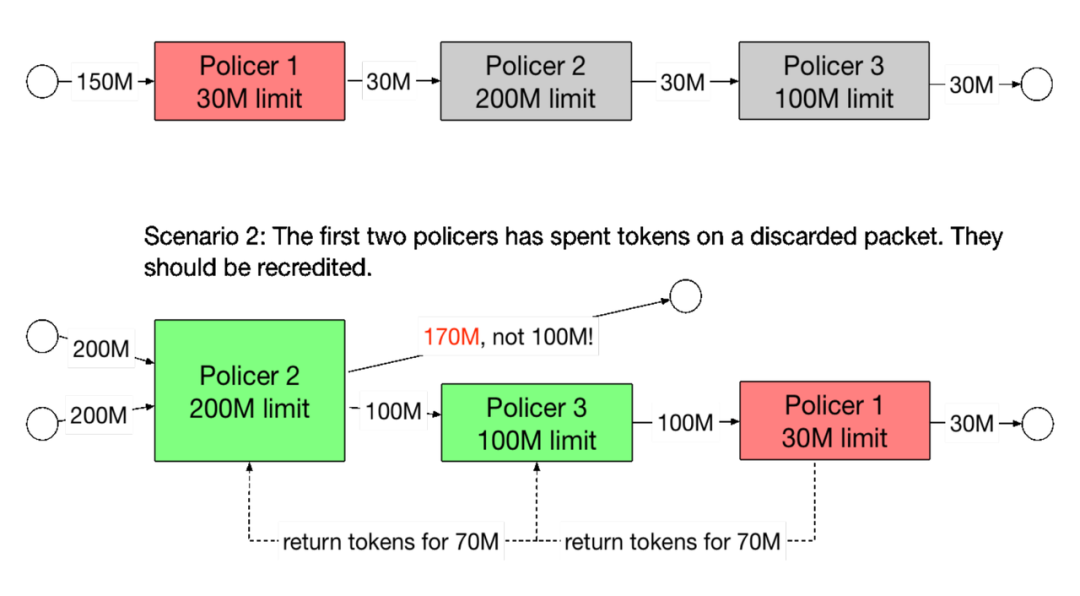 圖2 限速器級聯補償
圖2 限速器級聯補償
我們在實踐中發現,多個限速器級聯的時候,需要補償令牌。比如對于限速器 A,這個包是放行,消耗了 A 的令牌。對于限速器 B,這個包是丟棄,因為 B 沒令牌了。此時包被丟了。那么此時 A 的令牌就白白消耗了,即消耗了 token,然后包還是丟了。如果想達到一個準確的限速效果,限速器A的令牌應該被補償。如圖 2 所示那樣。
級聯補償使得多個限速器互相耦合,在代碼編寫上也比較麻煩。我們在實際中發現,如果限速器 A 和限速器 B 的限速值接近,并且都有丟包,那么缺乏級聯補償會對精度有嚴重影響。但如果限速值差的很遠,則對精度的影響沒有那么大。
3. TCP對丟包敏感問題
令牌桶是沒有緩存的,一旦速率超過限定值,則會出現丟包。而 TCP 協議則對丟包非常敏感,一旦出現丟包,TCP 的對速率的調整比較激進。令牌桶這一特性使得他在應用于 TCP 這種流量時,經常會導致限制 100Mbps,實際上最多只能跑到 80Mbps,因為不斷的丟包導致 TCP 不斷地降低發送窗口。
在 vSwitch 的使用時,BPS (Bits Per Second)限速對 TCP 的損耗尤其大,這是因為,一般虛擬網卡都開啟了 TSO(TCP Segmentation Offload)優化,開啟 TSO 情況下,主機向外發送的 TCP 包都很大,一個包有可能是 64K 字節,在這么大的情況下,隨便丟若干個包,就對 TCP 的速率影響非常明顯了。
第一次改進:端口借貸反壓限速器
我們在實踐中發現,級聯補償反饋問題雖然存在但不是非常突出,原因是一般級聯的限速器的限速值差距很大,比如單網卡的速率和整機速率,一般差距較大,不容易出現精度問題。最嚴重的問題是 TCP 丟包敏感導致的限速帶寬達不到,影響用戶體驗。由圖3所示,隨著 TCP RTT 的增加,實際可以達到的帶寬會明顯下降。
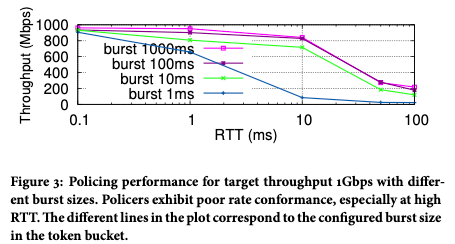
圖3 流量通過1Gbps限速器之后,實際獲得速率
反壓(backpressure),就是針對 TCP 對丟包敏感這一問題進行的改進。我們在第一次設計的時候,其實針對的是一個特定的場景。既虛機的虛擬網卡進行限速。而且我們的限速器正好是每個網卡有一個特定的限速器。
每個虛擬網卡都有若干隊列,vSwitch 會持續的輪詢這些隊列拿到數據包發出。這些隊列本質上其實就是包的緩存區。反壓,其實就是停止或者延緩對這些隊列的輪詢發包,讓數據包在隊列上堆積,而達到將壓力反饋到 Guest Kernel 的目的,這樣 Guest Kernel 的 TCP 棧就會感知到擁塞,調整發送的節奏。
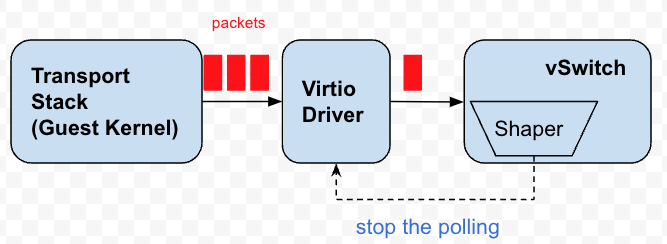
圖4 反壓限速器
當時我們設計反壓限速器的時候,有一個限制影響了最后的實現:
虛機的虛擬網卡沒有提供 Peek 功能,即 vSwitch 只是 Peek 數據包,而非真正將數據包從隊列中拿出。這一個限制導致了我們利用了“借貸”的思想。既設置一個開始輪詢的準許時間點,如果當前時間超過了準許時間點,那么將隊列中的數據包一股腦全部發出,不考慮令牌是否足夠,如果令牌足夠則沒有問題,但是當令牌不夠了,那么就考慮向未來借貸一筆令牌,反向計算出一個未來的時間戳,那么在這個時間戳之前,vSwitch 停止輪詢虛擬網卡。
借貸方法的提出,一開始只是為了性能考慮,避免好不容易將數據包從虛機隊列拷貝出來,卻發現令牌不夠又只能丟棄。既然不想丟棄,索性就向未來借貸一筆令牌都發出去。
如今回過頭來看這個設計,和 Peek 相比,其實有好有壞:
1)每次借貸的令牌量,不可控。這會導致公平性問題。大象流會不斷的獲取借貸資格,而小流則會趨向于餓死,在限速器競爭中,如果一方取得了優勢,優勢方容易持續獲得優勢。
2)簡單的時間戳比較,開銷比 peek 低。如果能夠 peek 數據包,就不會有借貸的機制,也就沒有停止輪詢的可能,而是每次都會去虛擬隊列里查看,反而開銷有點大。
3)反過來,有 peek 功能的話,也可以先看看隊列里積壓的數據包,可以等待隊列積累了一定量數據包之后,計算將下一次 Batch 個數據包發出的時間戳,在此之前都停止輪詢。這對增加 batch 提升性能反而有好處。
反壓限速器因為反壓的是虛機的網卡隊列,只能對虛機往外發數據包有限制,而無法限制虛機的收方向的流量。這是因為我們無法反壓物理網卡的數據包,物理網卡的數據包可能發往不同的虛擬網卡,每個網卡的限速值是不一樣的,我們無法計算出一個確切的時間點,在這個時間點之前可以不用輪詢數據包。況且,物理網卡隊列滿了之后,只會丟包,而虛機網卡隊列滿了之后,可以反壓 TCP 協議棧,兩者效果是不一樣的。
因此在入向流量的限制上,我們只是延續了準許時間戳的思想。如果當前時間超過準許時間,就放行所有數據包,如果沒有,則丟棄所有數據包。
第二次改進:Carousel限速器
Carousel 限速器是 Google 在 SIGCOMM 17' 上的論文提出的一種限速器算法[2],實際上想法也很簡單,即給每個數據包計算一個發出的時間戳,如果當前時間戳小于發出時間戳,則緩存在一個時間輪里,即不是丟包,而是將數據包延遲發送。
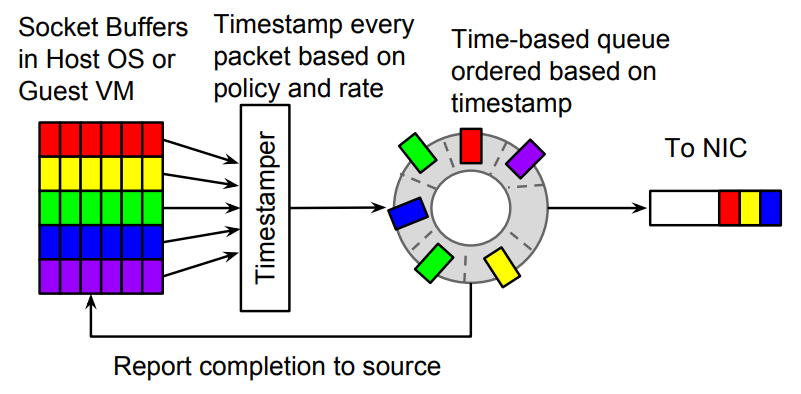
圖5 Carousel限速器
我們基于這個算法基本原理,在 OVS-DPDK 實現了一個類似限速器,這中間有很多細節決定了算法的參數,比如一次輪詢的時間粒度是 1us 還是 10us ?實際使用的限速器的速率區間在什么范圍?是 300Kpps 還是 3Mpps?這些都直接決定了算法的參數設置,諸多細節就不展開說明了。
Carousel 最大的一個好處是引入了緩存。時間輪的本質就是一個緩存,這個對 TCP 流量有明顯的好處,同時,時間輪也解決了虛機入向流量的無法反壓的問題,使得所有的流量都能統一在一個時間輪下。第三個好處,可能有點意想不到,就是它一定程度的消除了級聯補償的必要性,因為數據包不在丟包,而是延遲發送。在沒有丟包的情況下,不需要級聯補償。
下圖是在限速 10Gbps 下,通過 iperf 工具,測試 100s 情況下,虛機出入向,在使用老的反壓限速器和新的 Carousel 限速器的對比效果。
橫軸是時間(s),豎軸是吞吐(Gbps),即每秒 iperf 報告出的當前的吞吐性能。可以看到入向流量增加了 500Mbps。更靠近 10Gbps。
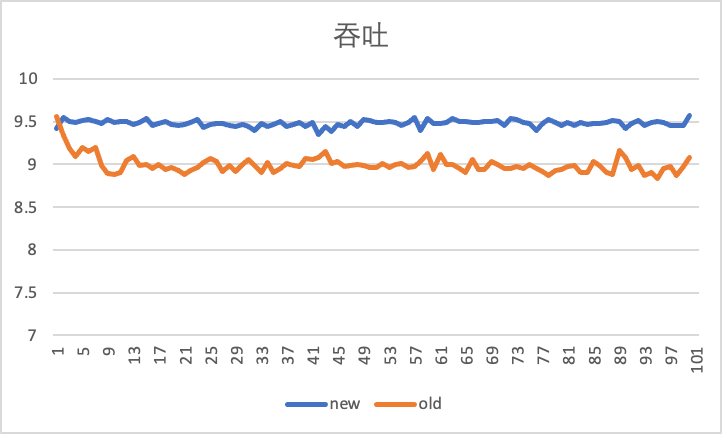
出向吞吐性能,可以看出 Carousel 限速器更加穩定: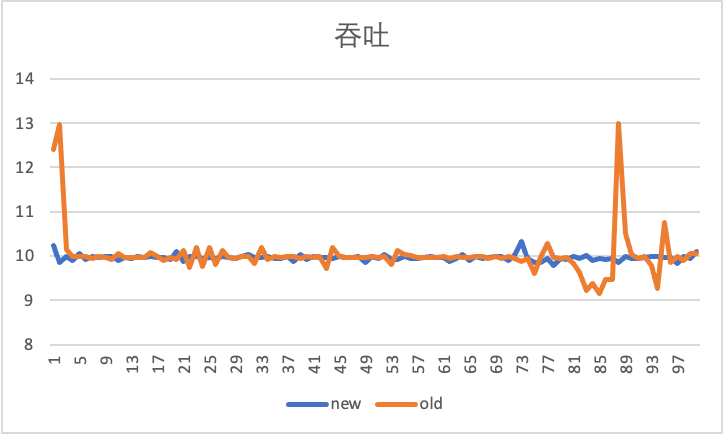
這些改進的源頭,都來自于緩存對 TCP 流量的平滑作用。
未來的改進和小結
1. 進一步改進
基于借貸機制的反壓限速,當限速值較大時,因借貸超發的數據包對整個限速抖動影響是有限的。比如限速 1G,在某個時刻超發幾個包,對限速的抖動影響是比較小的。但是如果限速值很小,比如小到 5Mbps,那么超發幾個數據包的影響就會比較大。此時,通過時間戳控制虛機端口的輪詢,會帶來 ON-OFF 效應,既在虛機看來,出向流量的路徑上,好像有一個閘門,一會打開,一會關閉。
但這只是在虛機發送端視角看到的情況,接收端因為有時間輪的調節,速率會比較穩定。為在發送端帶來比較穩定的體驗,需要將反壓的效果更加細化,既降低超發的幾率。
此外,基于端口粒度的限速可以通過控制端口的輪詢來實現,但是對于粒度小于端口的限速,則不好實現反壓。為了實現更細粒度的反壓,Google 在論文 PicNIC[3] 中,在Carousel 之上,利用 virtio 支持 OOO completion (亂序完成) 的特點,實現了更細粒度的反壓,這些都為進一步優化限速器提供了思路。
2. 主動限速(基于ECN或者修改TCP window選項)
我們可以在 vSwitch 中對 TCP 的 Window 窗口進行跟蹤修改,協商一個小窗口進行的方式,獲得更平穩的 TCP 吞吐。同時ECN標記也可以在 vSwitch 中進行感知,通過直接或者間接的方式反饋到虛機內部,或者影響 vSwitch 的輪詢頻率。
3. 鎖機制改進
以上所有的限速器改進均是針對網絡方面,系統方面由于多核存在,而限速器的粒度經常跨越線程,如何設計一個無鎖的限速器也是一個值得探索的方向。
4. 小結
從限速器的改進歷史中可以看出,當前的算法已經越來越和實際場景相關。算法不再只是一個獨立的組件,而越來越和實際的運行系統和產品特性緊密耦合。
審核編輯:劉清
-
PPS
+關注
關注
0文章
27瀏覽量
10538 -
RTT
+關注
關注
0文章
65瀏覽量
17089 -
虛擬機
+關注
關注
1文章
908瀏覽量
28109 -
TCP通信
+關注
關注
0文章
146瀏覽量
4217
原文標題:字節跳動在限速器優化上的實踐探索
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
字節跳動全面屏電子設備專利曝光 有望應用于字節跳動旗下堅果手機





 工商網監
工商網監
評論