 在FPGA上實現一個模塊,求32個輸入中的最大值和次大值
在FPGA上實現一個模塊,求32個輸入中的最大值和次大值
0. 題目
在FPGA上實現一個模塊,求32個輸入中的最大值和次大值,32個輸入由一個時鐘周期給出。(題目來自論壇,面試題,如果覺得不合適請留言刪除)
從我個人的觀點來看,這是一道很好的面試題目:
當然,輸入的位寬可能會影響最終的解題思路和最終的實現可能性。但位寬在一定范圍內,譬如8或者32,解題的方案應該都是一致的,只是會影響最終的頻率。后文針對這一題目做具體分析。(題目沒有說明重復元素如何處理,這里認為最大值和次大值可以是一樣的,即計算重復元素)
1. 解法
從算法本身來看,找最大值和次大值的過程很簡單;通過兩次遍歷:第一次求最大值,第二次求次大值; 算法復雜度是O(2n)。FPGA顯然不可能在一個周期內完成如此復雜的操作,一般需要流水設計。這一方法下,整個結構是這樣的
-
通過比較,求最大值,通過流水線實現兩兩之間的比較,32-16-8-4-2-1通過5個clk的延遲可以求得最大值;
-
由于需要求取次大值,因此需要確定最大值的位置,在求最大值的過程中需要維持最大值的坐標;
-
最大值坐標處取值清零(置為最小)
-
通過流水線實現兩兩之間的比較,32-16-8-4-2-1,再經過5個clk的延遲可以求得次大值;
這種解法有若干個缺點,包括:延遲求最大值和次大值分別需要5clk延時,總延遲會超過10個cycles;資源占用較高,維持最大值坐標和清零操作耗費了較多資源,同時為了計算次大值,需要將輸入寄存若干個周期,寄存器消耗較多。
另一個種思路考慮同時求最大值和次大值,由于這一邏輯較為復雜,可以將其流水化,如下圖。(以8輸入為例,32輸入需要增加兩級)
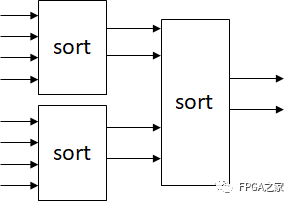
其中sort模塊完成對4輸入進行排序,得到最大值和次大值輸出的功能。4個數的排序較為復雜,這一過程大概需要2-3個cycles完成。對于32輸入而言,輸入數據經過32-16-8-4-2輸出得到結果,延遲大概也有10個周期。
2. 分治
如果需要在FPGA上實現一個特定的算法,那么去找一個合適的方法去實現就好了;但如果是要實現一個特定的功能,那么需要找一個優秀的且適合FPGA實現的方法。
求最大值和次大值是一個很不完全的排序,通過簡單的查找復雜度為O(2n),且不利于硬件實現。對于排序而言,無論快速排序或者歸并排序都用了分治的思想,如果我們試圖用分治的思想來解決這一問題。考慮當只有2個輸入時,通過一個比較就可以得到輸出,此時得到的是一個長度為2的有序數組。如果兩個有序數組,那么通過兩次比較就可以得到最大值和次大值。采用歸并排序的思想,查找最大值和次大值的復雜度為O(1.5n)(即為n/2+n/2+n/4… ,不知道有沒有算錯)。采用歸并排序的思想,從算法時間復雜度上看更為高效了。
那么這一方案是否適合FPGA實現呢,答案是肯定的。分治的局部性適合FPGA的流水實現,框圖如下。(以8輸入為例,32輸入需要增加兩級)
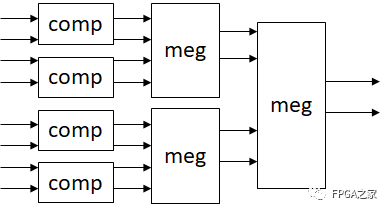
其中meg模塊內部有兩級的比較器,一般而言1clk就可以完成,輸入數據經過32-32-16-8-4-2得到結果,延遲為5個時鐘周期。實現代碼如下


module test#(
parameter DW = 8
)
(
input clk,
input [32*DW-1 :0] din,
output [DW-1:0] max1,
output [DW-1:0] max2
);
wire[DW-1:0] d[31:0];
generate
genvar i;
for(i=0;i<32;i=i+1)
begin:loop_assign
assign d[i] = din[DW*i+DW-1:DW*i];
end
endgenerate
// stage 1,comp
reg[DW-1:0] s1_max[15:0];
reg[DW-1:0] s1_min[15:0];
generate
for(i=0;i<16;i=i+1)
begin:loop_comp
always@(posedge clk)
if(d[2*i]>d[2*i+1])begin
s1_max[i] <= d[2*i];
s1_min[i] <= d[2*i+1];
end
else begin
s1_max[i] <= d[2*i+1];
s1_min[i] <= d[2*i];
end
end
endgenerate
// stage 2,
wire[DW-1:0] s2_max[7:0];
wire[DW-1:0] s2_min[7:0];
generate
for(i=0;i<8;i=i+1)
begin:loop_megs2
meg u_s2meg(
.clk(clk),
.g1_max(s1_max[2*i]),
.g1_min(s1_min[2*i]),
.g2_max(s1_max[2*i+1]),
.g2_min(s1_min[2*i+1]),
.max1(s2_max[i]),
.max2(s2_min[i])
);
end
endgenerate
// stage 3,
wire[DW-1:0] s3_max[3:0];
wire[DW-1:0] s3_min[3:0];
generate
for(i=0;i<4;i=i+1)
begin:loop_megs3
meg u_s3meg(
.clk(clk),
.g1_max(s2_max[2*i]),
.g1_min(s2_min[2*i]),
.g2_max(s2_max[2*i+1]),
.g2_min(s2_min[2*i+1]),
.max1(s3_max[i]),
.max2(s3_min[i])
);
end
endgenerate
// stage 4,
wire[DW-1:0] s4_max[1:0];
wire[DW-1:0] s4_min[1:0];
generate
for(i=0;i<2;i=i+1)
begin:loop_megs4
meg u_s4meg(
.clk(clk),
.g1_max(s3_max[2*i]),
.g1_min(s3_min[2*i]),
.g2_max(s3_max[2*i+1]),
.g2_min(s3_min[2*i+1]),
.max1(s4_max[i]),
.max2(s4_min[i])
);
end
endgenerate
// stage 5,
meg u_s5meg(
.clk(clk),
.g1_max(s4_max[0]),
.g1_min(s4_min[0]),
.g2_max(s4_max[1]),
.g2_min(s4_min[1]),
.max1(max1),
.max2(max2)
);
endmodule
module meg#(
parameter DW = 8
)
(
input clk,
input [DW-1 :0] g1_max,
input [DW-1 :0] g1_min,
input [DW-1 :0] g2_max,
input [DW-1 :0] g2_min,
output reg [DW-1:0] max1,
output reg [DW-1:0] max2
);
always@(posedge clk)
begin
if(g1_max>g2_max) begin
max1 <= g1_max;
if(g2_max>g1_min)
max2 <= g2_max;
else
max2 <= g1_min;
end
else begin
max1 <= g2_max;
if(g1_max>g2_min)
max2 <= g1_max;
else
max2 <= g2_min;
end
end
endmodule
3. 其他
簡單測試了上面的代碼,在上一代器件上(20nm FPGA),8bit數據輸入模塊能綜合到很高的頻率,邏輯級數大概是5級左右,對于整個工程而言瓶頸基本不會出現在這一部分。32bit數據輸入由于數據位寬太大,頻率不會太高,但是通過將meg模塊做一級流水,也幾乎不會成為整個系統的瓶頸。
32bit32輸入情況下,數據輸入位寬為1024(不是IO輸入,是內部信號)。之前在通信/數字信號處理方面可能不會用到這么大位寬的數據,但對于AI領域FPGA的應用,數千比特的輸入應該是很平常的,這的確會影響最終FPGA上實現的效果。要想讓機器學習算法在FPGA上跑得更好,還需要算法和FPGA共同努力才是。
審核編輯 :李倩
-
FPGA
+關注
關注
1626文章
21678瀏覽量
602037 -
模塊
+關注
關注
7文章
2674瀏覽量
47350 -
寄存器
+關注
關注
31文章
5325瀏覽量
120052 -
機器學習
+關注
關注
66文章
8382瀏覽量
132444
原文標題:3. 其他
文章出處:【微信號:ZYNQ,微信公眾號:ZYNQ】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論