 GTC23 | China AI Day 演講回顧:NVIDIA CUDA 技術助力網易瑤臺神經隱式曲面建模 20 倍加速
GTC23 | China AI Day 演講回顧:NVIDIA CUDA 技術助力網易瑤臺神經隱式曲面建模 20 倍加速
NVIDIA GTC 2023 春季大會成功落下帷幕,超過 30 萬名注冊用戶參與到 650 多場演講中,深入了解最新的 AI 技術和豐富的應用場景。
在本屆 GTC 特別活動 China AI Day 上,網易伏羲視覺計算負責人李林橙以《NVIDIA CUDA 技術助力網易瑤臺神經隱式曲面建模 20 倍加速》為題,分享了 AIGC 趨勢下其創新性的神經隱式曲面建模解決方案,以及項目過程中的實踐經驗和心得。以下為演講內容概要。
網易瑤臺項目背景
網易瑤臺是網易伏羲旗下沉浸式活動平臺,致力于用人工智能和科技創新打造數字空間新模式。網易瑤臺在底層的 AI 算法上,支持虛擬角色、虛擬場景的創建驅動;在底層的平臺上,有 ACE 分布式引擎來支持達到萬人級別的同屏實時互動,同時借助網易雷火游戲的美術積累,實現業內一流的 3D 美術制作和渲染管線。
作為一個提供一站式元宇宙營銷服務的元宇宙產品,網易瑤臺已經被廣泛地應用于會議活動、虛擬展會、在線展廳、社交娛樂等多元豐富的場景,為美國、日本、新加坡等一百多個國家的用戶舉辦累積兩百余場沉浸式虛擬活動,獲得了客戶的一致好評。
圖一
在這個過程中,我們了解到客戶的一個剛需是場景的數字化建模。一部分客戶希望重新打造一個虛擬場景,但更多的時候客戶希望復刻一個真實世界的場景,在虛擬的元宇宙中做到數字孿生。如圖一所示,左邊是網易瑤臺與河南省文化和旅游廳聯合推出的三維虛擬空間“元豫宙”之黃帝故里場景案例,我們運用數字科技復刻了物理世界場景,把黃帝故里等河南文旅 IP 景區重現在以網易瑤臺為數字基座的數字空間;右邊是浙江大學求是會議廳,我們也在網易瑤臺里做了一個 1:1 的數字孿生復刻。這樣的需求很多,但是復刻的過程一方面依賴很多實地測繪,需要現場拍很多照片和測量;另一方面也需要很大的人工工作量,用建模軟件一步一步地雕刻出一個個場景,然后把它們組合起來。這是一個很大的工作量,也不利于我們做規模化的數字孿生。
所以引出了網易瑤臺想要做到的方案,即如何快速便捷地建模數字化場景。我們想讓使用網易瑤臺的用戶用手機拍攝物體,能夠自動化且快速地做數字化建模,并且導入網易瑤臺的云會場,這是這個項目希望實現的目標。
融合 NVIDIA instant-ngp 和 NeuS 優勢的
神經隱式曲面建模方案
第二部分介紹一下我們奔著這個目標,做了怎樣的技術選型。從技術的角度,這是一個多視角三維場景重建的問題,希望從多視角照片中重建高精度的 3D 模型。這個方案的采集成本比較低,只需要智能手機就可以,適用于大眾來進行拍攝,同時做自動化的建模來提升 3D 內容數字孿生的生產效率。但是技術難點在于,和常見的多視角 3D 場景重建的各種方案不同的是,網易瑤臺的要求略有些特殊,要求高質量 Mesh 與貼圖,并且要求高效率,不讓用戶等的時間過長。目前已有的常見算法在效率和精度上通常無法兼顧。
圖二
3D 重建算法的本質都是輸入 2D 圖像,先計算相機位姿,之后再進一步重建 3D 模型。模型的表示可以是隱式的,比如使用 SDF、體密度來表示,也可以是顯式的,用傳統的點云、深度圖、Mesh 這些方式來表示。
這里我們對現有算法作了一個簡單的分類,如圖二。最左邊,近年來比較經典的一類方法是神經體渲染,代表方法是 NeRF,用 MLP 來表示神經隱式場。對用戶輸入的每一個三維點,從每一個方向的觀察,都輸出一個 RGB 和體密度,每一個點的顏色通過沿著一條射線積分 RGB 和體密度來得到。在這個方向上,去年 NVIDIA instant-ngp 也是完成了特別顯著的加速優化。
圖的中間示意,第二類是神經隱式曲面,把經典的體密度表示,換成了用 SDF 表示的方式,每個點表示了當前這個點到空間中的三維曲面的距離。這種表示方式可以獲得更加平滑的曲面,代表方法是 IDR 和 NeuS。
圖的右側,第三類是從傳統的 MVS 方法發展過來,先用傳統的特征匹配或者用神經網絡來預測一個深度圖,然后再將多幀的深度圖進行融合得到三維的曲面,這幾年比較好用的方式其中之一是 CasMVSNet。
下面我將逐一介紹網易瑤臺在這三個方向上的探索以及結果。
一,NeRF。NVIDIA instant-ngp 在 NeRF 的基礎上提出了多尺度的哈希編碼。傳統的編碼是用正余弦編碼來表示每一個頂點頻域分量,瑤臺的方案,是用一個網絡去生成哈希編碼來表達空間中每一個位置,同時也使用了球諧編碼,這種方式做到了顯著的加速。在實現的過程中,還用了 NVIDIA 的 tiny-cuda-nn 加速技術。把這些技術整合在一起之后,在訓練時間上從 NeRF 的 10 個小時大幅度提升到了 10 分鐘之內,可以做到高質量的 2D 視角生成。但不足之處在于,只能輸出相對低質量的 mesh 和紋理。本質原因在于,這種方式是為了 2D 的視角合成而不是為了 3D 的 mesh 生成設計的。
二,NeuS。用 SDF 取代體密度渲染,得到了更高的 mesh 重建的精度。它把場景分成了球內和球外,在球內用 SDF 生成一個前景的神經隱式場,在球外還是沿用了 NeRF 生成比較好的 2D 背景,編碼還是正常的正余弦編碼。這個方法的優勢是可以得到一個很高質量的 mesh,同時因為 mesh 比較精細,紋理對應的也可以是高質量的紋理,順便也可以做到比較高質量的 2D 視角合成。但是它的訓練時間很慢,和標準的 NeRF 一樣,訓練時間也要 10 個小時以上,同時需要每張圖手動截取物體邊框作為輸入。
三,深度圖融合的方式,代表方法是 CasMVSNet。它是通過多尺度級聯的深度估計網絡,先預測低分辨率的深度圖,再逐漸增加分辨率到高分辨率的深度圖,以達到預測速度和預測精度之間的 tradeoff。然后在多視角深度融合中用一致性過濾噪點,得到一個最終的 3D 點云。這個方法借助多尺度深度圖融合之后,推理時間可以做到兩分鐘,是很快的速度,同時能輸出高質量的點云。但因為是從深度圖融合后過濾的,被過濾掉的地方就變成了空洞。簡單來說,在準的地方很準,但是在有些區域是沒有信息的,即變成空洞。如果讓用戶拍出這樣的結果直接放到元宇宙的應用里,不能滿足用戶需求。而且深度圖的方法還需要有數據集的監督訓練,也是一個比較受限制的條件。

圖三
總結一下,如圖三所示。前面這幾類比較經典的方法,NeRF 是開山鼻祖,運行時間很長,但是給后續的方法提供了一個完全全新的思路。NVIDIA instant-ngp 在 NeRF 的基礎上做到了大幅的加速,做到了很理想的運行時間,但是還是沿用了 NeRF 的 2D 視角合成任務,沒有專門去關注 3Dmesh 生成任務,和我們的需求沒有完全匹配。NeuS 針對高質量的 3Dmesh 做了很好的優化,但是它的運行時間又回到了 10 個小時以上。CasMVSNet 速度非常快,但是生成的 3D 點云有些空洞。
圖四
針對這個技術現狀,我們分別提取 instant-ngp 和 NeuS 的優勢做了整合,設計了我們自己的整體流程(如圖四所示)。這個流程在大的框架上還是標準的模塊,如視頻抽幀、位姿估計、邊框估計、物體分割、到神經渲染重建、紋理貼圖等模塊。下方的圖是這個流程重建出來的部分結果。
神經隱式曲面建模方案工作流程
下面我們針對每個模塊展開具體的介紹。首先介紹和神經隱式場無關的位姿估計和預處理的模塊。
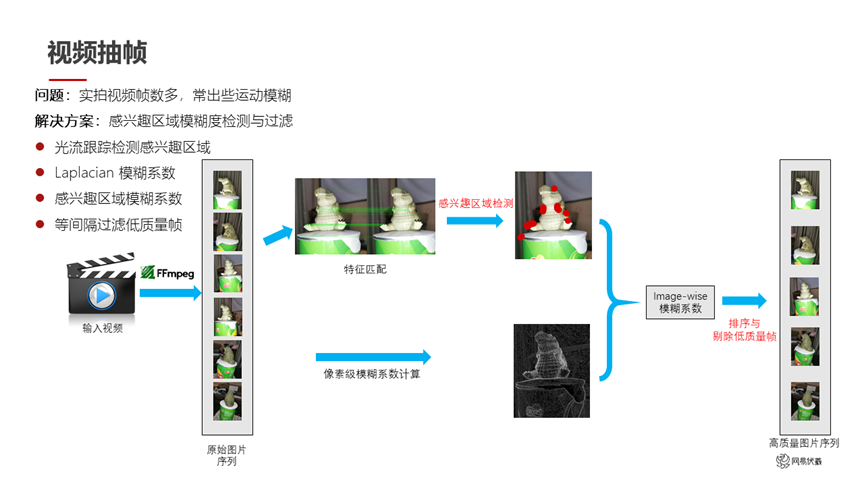
圖五
如圖五所示,我們輸入的是一個用戶拍攝的視頻,視頻幀數很多,而且會出現一些運動模糊。我們希望篩選出高質量幀,踢掉模糊幀,保留視角相對合適的幀。因為用戶拍的內容一般是針對感興趣的區域進行拍攝,所以我們針對用戶拍攝的圖片做特征匹配之后,能夠提取出用戶感興趣的區域。同時我們用模糊檢測的方法預測每一幀的模糊系數,從而剔除一些幀,得到高質量的圖片序列。
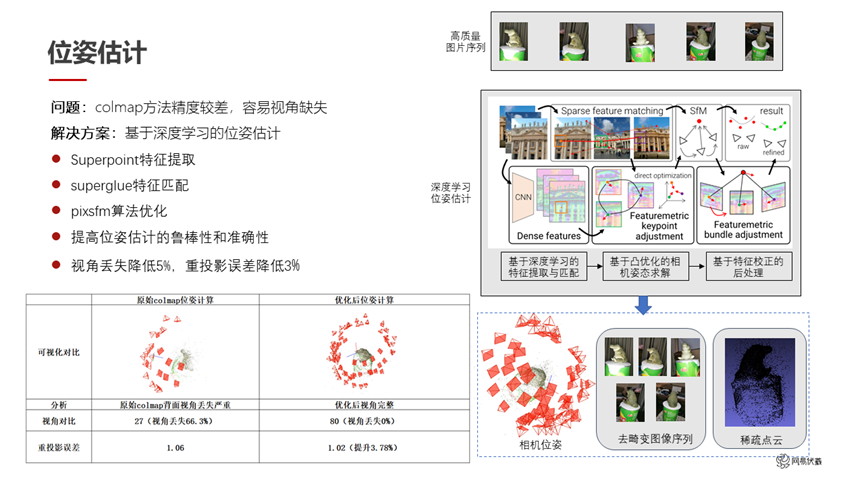
圖六
在位姿估計方面,傳統的 colmap 已經是比較成熟而且比較好用的方法。但是它也存在兩點問題,一是估計位姿的精度會差一些,二是視角容易缺失。我們用了一系列方法去優化這兩個問題。具體來說,我們使用 Superpoint 作為特征提取,使用 Superglue 作為特征匹配,使用 Pixsfm 作為算法的優化。這樣在特征的提取、匹配、優化的過程中各自做了一些改進和替換之后,我們提高了位姿估計的魯棒性和準確性。如圖六所示,左下角是原始的 colmap 和我們優化之后的對比,可以看到右側的結果位姿的丟失比較少。同時我們的重投影誤差也有了 3.7%的提升,從 1.06 提升到了 1.02。

圖七
在物體邊框估計方面,如果直接引用 NVIDIA instant-ngp 的話,物體邊框的估計出來會比較大。這里我們用位姿估計和稀疏的 3D 點估計結果去縮小這個邊框。首先進行噪點的過濾,然后估計出物體的中心:用最小二乘法計算各個視角交點,就可以認為是用戶感興趣的物體的中心。之后計算各個視角的最小深度,把各相機沿主軸平移到這個最小深度上,平移后的相機包圍框就是我們縮小之后的物體邊框。如圖七,右邊是一個對比,原始的 NVIDIA instant-ngp 是綠色框,我們把它優化到了紅色框里,這樣能減少一些計算資源。
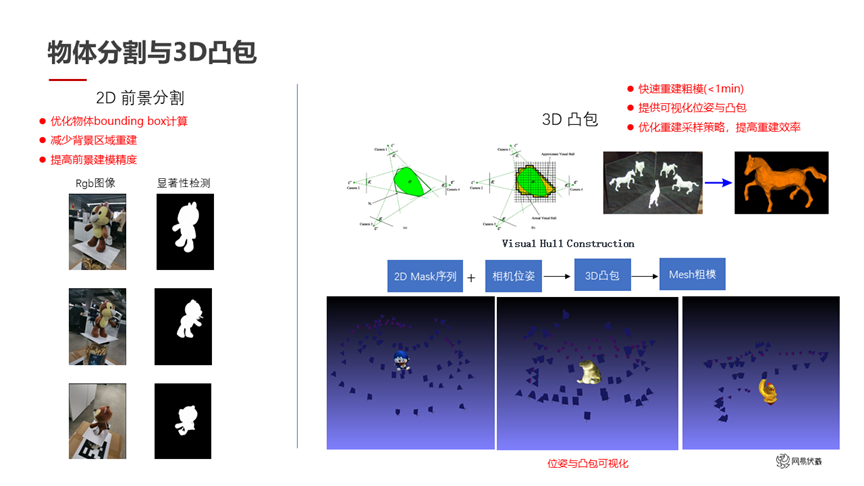
圖八
在物體分割方面,我們首先利用顯著性檢測,對用戶圖片進行前景分割,因為用戶拍攝的畫面中間那個東西,大概率是他感興趣的東西,而且是一個獨立的物體。我們在優化顯著性檢測之后,得到了左邊的結果。這個結果還能進一步互相校正,因為我們已經知道了每幀的位姿。檢測了 2D 分割后,我們可以根據位姿投影得到 3D 分割,也就是 3D 凸包,比如圖八右邊的展示。這些 3D 凸包一方面可以給用戶實現快速的預覽功能,只要不到一分鐘的時間就可以生成 3D 凸包,這些凸包相當于一個粗糙的模型。看到這個模型之后,用戶就知道后面的進一步細化會基于目前的這個粗糙狀態下進行,提前有一個預覽。同時這些 3D 凸包可以互相校正,一些 2D 顯著性檢測結果有分割錯誤的地方,在 3D 凸包上可以糾正回來。
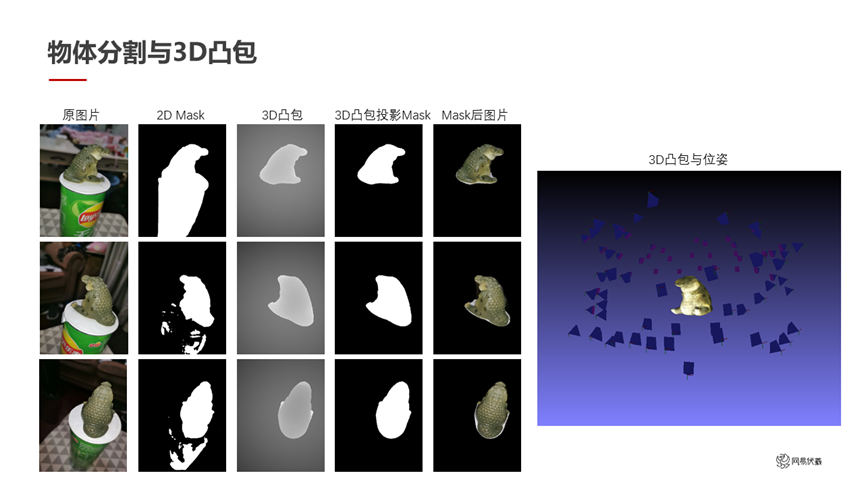
圖九
圖九是互相校正的例子。從左到右每一列依次是原圖、2D 顯著性分割的 mask,做了 3D 凸包的結果,互相校正之后得到的比較精確的 mask、最后是 mask 之后的圖片。右邊是一個粗糙的 3D 凸包,其實對于一些要求不高的物體來說,這個 3D 凸包可以直接作為重建結果使用,也可以指導后續的優化。
建模速度從 10 小時優化到了 10-20 分鐘
下面介紹一下我們對神經隱式曲面建模,進行了一些加速的操作(如圖十所示)。

圖十
整體來說,我們融合了 NVIDIA instant-ngp 和 NeuS 兩個方案的優點,同時借助 CasMVSNet 做先驗的指導。主要做了兩個方面工作,一方面是對編碼進行優化和網絡壓縮,另一方面是調整訓練策略。下面分別展開討論。
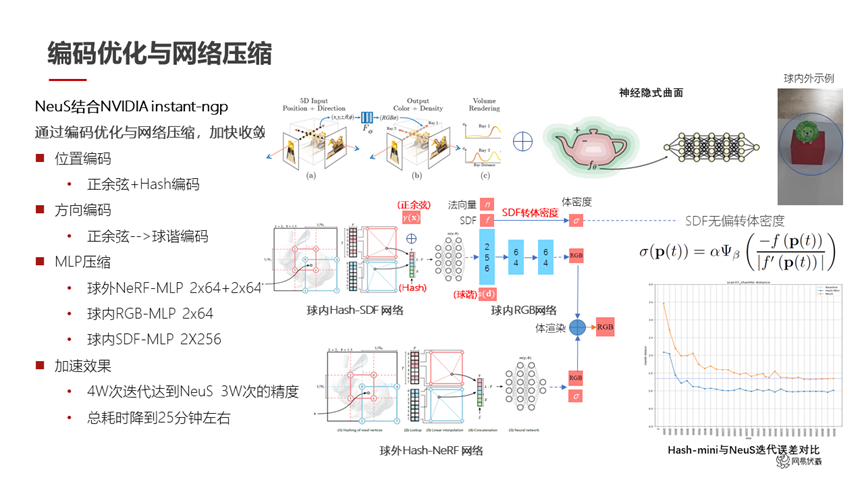
圖十一
針對編碼優化和網絡壓縮(如圖十一所示),我們做了以下工作:
首先位置編碼還是正常的正余弦編碼,再加上了 NVIDIA instant-ngp 的哈希編碼。這邊我們有一個操作:NVIDIA instant-ngp 把編碼改成了哈希編碼,我們在它的基礎上疊加了正余弦編碼 concat 上去。這個操作其實在數學上并不是一個特別優雅的方案,但是我們實驗下來能夠解決哈希編碼的一些問題。比如說哈希編碼會帶來一些空洞問題,通過這個正余弦編碼的疊加可以很大程度上的緩解。方向編碼我們沿用了 NVIDIA instant-ngp 的球諧編碼。在整體的 MLP 上,我們使用 NeuS 的 SDF 形式來表示三維場景,然后對 NeuS 的 MLP 進行了很大幅度的壓縮。球外是 2*64 這樣的小網絡,球內也是 2*64 和 2*256 這樣比較快速的網絡。
經過一系列的優化之后,我們這個小網絡的四萬次迭代就達到了 NeuS 這個大網絡的三十萬次迭代的精度。右下角圖里,橙色的線是 NeuS 的迭代誤差,藍色的線是我們的迭代誤差。同樣的迭代誤差下,我們用比較快的速度達到了 NeuS 相同的結果,總耗時也降到了 25 分鐘左右。
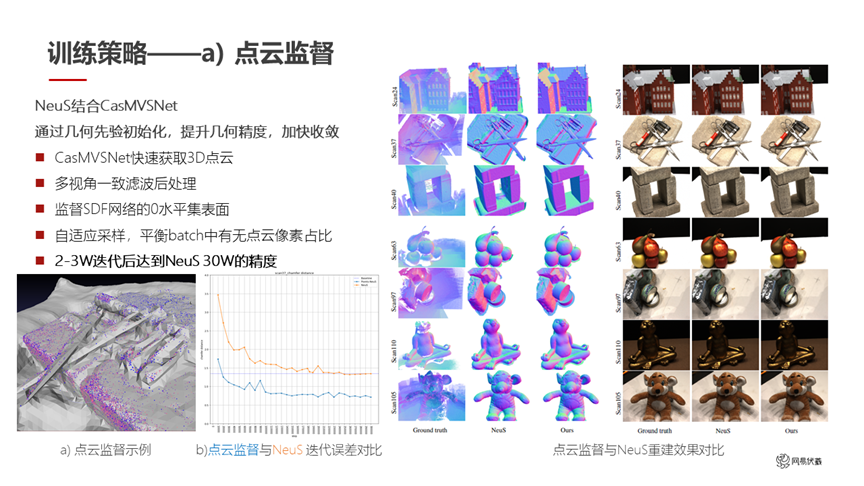
圖十二
在訓練策略上,我們首先借助 CasMVSNet 做點云的監督(如圖十二所示)。我們先通過 CasMVSNet 得到一個比較稀疏的點云,再對這個稀疏點云進行多視角一致性濾波,得到一個完成后處理的結果。這個結果可以用于監督 SDF 網絡訓練過程中的采樣,在有這個點云的附近多采一些點,在遠離這些點云的地方可以少采一些點,因為點云大概率代表了實際的 3D 網格就在它附近。同時我們做了一個自適應的采樣,平衡每一個 batch 中點云像素的占比,因為點云是稀疏排布的,部分地方沒有點云。
在以上操作之后,我們在兩到三萬次迭代后達到了 NeuS 三十萬次迭代的精度。如圖十二顯示,左下角這張圖里,藍色是我們用點云監督之后的結果,黃色是 NeuS 的原始結果。我們在很快的速度下達到了 NeuS 同樣精度的水平。右邊是我們用了點云監督之后和 NeuS 的重建結果對比,除了速度大幅提高之外,我們在精度上也有了一定的提高。比如第一行房子的屋頂上,我們的結果在屋頂上的凹陷就沒有了,但是 NeuS 的結果還有;在第四行的蘋果上,最上面那個蘋果我們也得到更精確的細節。
我們的第二個策略是做了多尺度和多視角的監督(如圖十三所示)。多尺度是一個比較容易想到的方案:用圖像金字塔進行重建,先做一個低分辨率的結果,然后逐漸擴大得到高分辨率的結果。這種方案可以增強局部的連續性,而且總的迭代次數減少為 NeuS 的 43%,進一步提升了計算速度。

圖十三
如圖十三所示,右上角是我們在原圖和二分之一圖訓練的一個對比。我們還做了多視角的監督。單步多視角是指我們在訓練時的 batchsize 可以設得很大,因為我們前面做了很多操作,網絡很小,batchsize 可以從 512 擴大到 2560 來盡量加快訓練速度。但是如果直接擴大 batchsize 會導致空洞的增多,就像右下角的第三個圖片,在白色的盆上出現了空洞。我們的做法是在單步訓練中使用 10 個視角。原來是每個 step 在一張輸入圖片上采一個 batch 的點去做訓練,我們改成了每個 step 從 10 個視角去采樣,在 10 張圖上總共采樣這么多點去做訓練。這種方式可以避免訓練過程中的空洞,比如右下角最右邊這張圖,用 10 個視角監督之后白色的盆上不再有這些空洞。相比小的 batch,我們用 17 分鐘就可以達到 NeuS 用 10 個小時的精度。
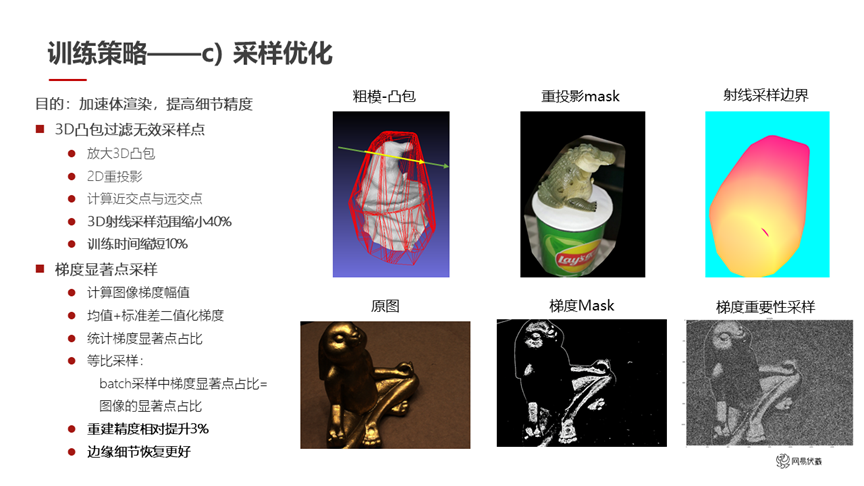
圖十四
我們還做了采樣的優化(如圖十四所示)。這部分目標是加速體渲染,提高細節的精度。因為我們有了一個比較精確的 3D 凸包,它可以過濾無效的采樣點,所以基于這個 3D 凸包和 2D 重投影,就可以算出來每個射線在 3D 凸包內的近交點和遠交點,那么我們采樣的范圍只需要在凸包內部就可以。采樣范圍直接縮小 40%,訓練時間也縮短了 10%。
另外我們做了梯度顯著點采樣。考慮到做采樣的時候,可能出問題的更多是在物體的邊緣附近,我們希望在物體邊緣多采一些點,在物體內部少采一些點。于是我們先統計梯度的顯著點,然后再根據這些顯著點去做采樣。同時我們做了等比采樣,batch 采樣中顯著點的占比要等于圖像中的顯著點占比。通過這個步驟重建精度進一步提升了 3%。因為邊緣的細節做得更好,非邊緣梯度較弱的地方簡單采樣也沒有太大問題,所以進一步提高了精度。
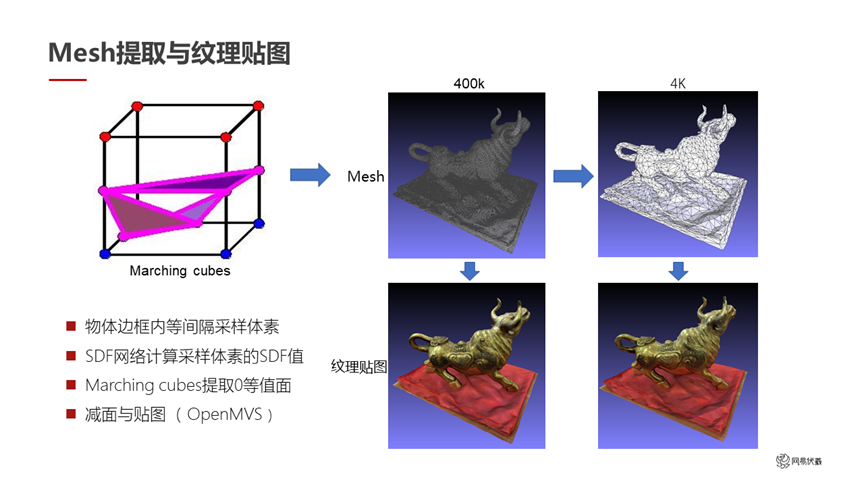
圖十五
做了這一系列工作之后,最后把 SDF 轉成 mesh 和紋理是比較常規的操作,如圖十五所示。我們直接計算每一個采樣體素的 SDF 值,用 marching cubes 提取零等值面,就直接輸出了 3D mesh。在這個 mesh 上,我們借助 OpenMVS 做減面和貼圖操作。右邊這組圖里最初輸出的是 40 萬面的 mesh,減面之后變成了 4000 面的 mesh。減面之后的 mesh 比較適合放在游戲引擎里去做元宇宙的應用。下面是兩種方式的紋理貼圖的對比,雖然減到了 4000 面,但是視覺效果看起來。這是我們最終輸出的小體積的重建結果,最后我們把它放到了網易瑤臺產品里。

圖十六
經過前面這些操作之后,我們總結一下目前達到的狀態。在 NVIDIA instant-ngp 和 tiny-cuda-nn 的幫助下,網易瑤臺神經隱式曲面建模的速度從一開始的 10 個小時,優化到了 10 到 20 分鐘。這個速度在用戶的使用過程中是可以接受的。

圖十七
圖十七是我們重建精度的對比。我們和一個商業軟件 RealityCapture 做了對比。
RealityCapture 是一個傳統的基于特征匹配做 MVS 重建的算法。上面的是網易瑤臺的輸出,下面的是 RealityCapture 的輸出。在視角不丟失的情況下,兩個方法的精度都是很好的。比如這個鱷魚或者最左邊的熊,在看得到或者說視角沒丟的那半邊其實是可以的,但視角丟了的那半邊沒有重建出來,而且會有一些噪聲導致在視角丟失的時候連到很大的區域上去。這種精度的結果就給人工修復帶來很大的工作量。相比之下我們的結果重建出來就可以直接放到網易瑤臺里使用。這是另外的一個優勢,除了視角丟失需要修復之外,我們在重建成功的區域的精度上也有一些優勢。
小結

圖十八
以上是網易瑤臺神經隱式曲面建模項目目前的進展。后續我們希望持續地提升建模的質量和效率,進一步提升紋理貼圖的質量。同時 NVIDIA 在 Text-to-3D 方面做了一個很好的榜樣,我們后面會和 NVIDIA 一起探索 Text-to-3D 技術,基于大模型進行文本生成三維模型,從而讓用戶更快的生成更多數字孿生的物體和場景,放到網易瑤臺這個數字孿生應用中。
注:本文字實錄由網易伏羲語音識別技術輔助提供。
本文署名作者:

李林橙
網易伏羲視覺計算負責人,浙江大學校外導師,專注計算機視覺研究。

張永強
網易伏羲視覺計算組,人工智能研究員,研究方向為神經渲染與多視角三維重建。
彩蛋:
近期,在計算機視覺和模式識別領域的頂級學術會議 CVPR 中,網易瑤臺 2 篇 3D 重建相關技術論文成功入選。感興趣的朋友們可以查閱進一步了解相關信息:
[1] Towards Unbiased Volume Rendering of Neural Implicit Surfaces with Geometry Priors, CVPR 2023
[2] NeFII: Inverse Rendering for Reflectance Decomposition with Near-Field Indirect Illumination, CVPR 2023
掃描海報二維碼,或點擊“閱讀原文”,即可觀看 NVIDIA 創始人兼首席執行官黃仁勛 GTC23 主題演講重播!
原文標題:GTC23 | China AI Day 演講回顧:NVIDIA CUDA 技術助力網易瑤臺神經隱式曲面建模 20 倍加速
文章出處:【微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3747瀏覽量
90834
原文標題:GTC23 | China AI Day 演講回顧:NVIDIA CUDA 技術助力網易瑤臺神經隱式曲面建模 20 倍加速
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NVIDIA助力Amdocs打造生成式AI智能體
日本企業借助NVIDIA產品加速AI創新
NVIDIA AI助力SAP生成式AI助手Joule加速發展
NVIDIA在加速計算和生成式AI領域的創新
HPE 攜手 NVIDIA 推出 NVIDIA AI Computing by HPE,加速生成式 AI 變革
NVIDIA推出NVIDIA AI Computing by HPE加速生成式 AI 變革
NVIDIA發布DeepStream 7.0,助力下一代視覺AI開發
助力科學發展,NVIDIA AI加速HPC研究

NVIDIA 通過 CUDA-Q 平臺為全球各地的量子計算中心提供加速

NVIDIA數字人技術加速部署生成式AI驅動的游戲角色

NVIDIA生成式AI研究實現在1秒內生成3D形狀

與NVIDIA深度參與GTC,向量數據庫大廠Zilliz與全球頂尖開發者共迎AI變革時刻
NVIDIA Isaac將生成式AI應用于制造業和物流業
SAP與NVIDIA攜手加速生成式AI在企業應用中的普及
NVIDIA 初創加速計劃 Omniverse 加速營






 工商網監
工商網監
評論