 ImPosing:用于視覺定位的隱式姿態編碼
ImPosing:用于視覺定位的隱式姿態編碼
主要內容:
提出了一種新的基于學習的用于車輛上的視覺定位算法,該算法可以在城市規模的環境中實時運行。
算法設計了隱式姿態編碼,通過2個獨立的神經網絡將圖像和相機姿態嵌入到一個共同的潛在表示中來計算每個圖像-姿態對的相似性得分。通過以分層的方式在潛在空間來評估候選者,相機位置和方向不是直接回歸的,而是逐漸細化的。算法占的存儲量非常緊湊且與參考數據庫大小無關。
Pipeline:
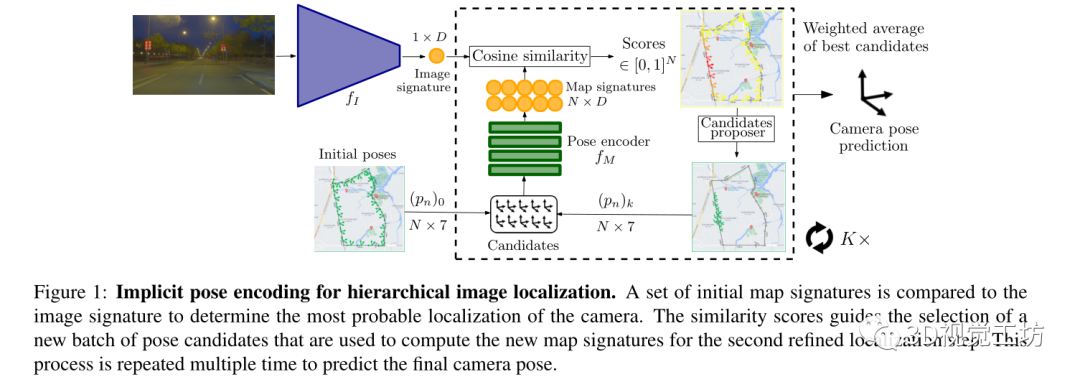
輸入為查詢圖像
輸出為查詢圖像的六自由度姿態(t,q)∈SE(3),t是平移向量,q是旋轉四元數。
訓練是在帶有相機姿態label的數據庫圖像上進行訓練,沒有用額外的場景3D模型。
先通過圖像編碼器計算表示圖像向量。然后通過評估分布在地圖上的初始姿態候選來搜索相機姿態。姿態編碼器對相機姿態進行處理以產生可以與圖像向量相匹配的潛在表示,每個候選姿態都會有一個基于到相機姿態的距離的分數。高分提供了用于選擇新候選者的粗略定位先驗。通過多次重復這個過程使候選池收斂到實際的相機姿態。
論文技術點:
圖像編碼器:
使用圖像編碼器從輸入的查詢圖像計算圖像特征向量。
編碼器架構包括一個預訓練的CNN backbone,然后是全局平均池以及一個具有d個輸出神經元的全連接層。
特征向量比圖像檢索中常用的全局圖像描述符小一個數量級(使用d=256)以便在隨后的步驟中將其與一大組姿態候選進行有效比較。
初始姿態候選:
起點是一組N個相機姿態,這是從參考姿態(=訓練時相機姿態)中采樣。通過這種初始選擇為定位過程引入了先驗,類似于選擇錨點姿態。
姿態編碼器:
姿態候選通過一個神經網絡處理,輸出潛在向量,這種隱式表示學習到了給定場景中的相機視點與圖像編碼器提供的特征向量之間的對應關系。
首先使用傅立葉特征將相機姿態的每個分量(tx,ty,tz,qx,qy,qz,qw)投影到更高維度:
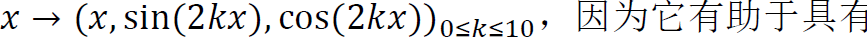 ,因為它有助于具有低維輸入的網絡擬合高頻函數。然后使用具有4層256個神經元和隱藏層為ReLU激活的MLP。每一組候選姿態都是在一次batch的前向傳遞中計算出來的。
,因為它有助于具有低維輸入的網絡擬合高頻函數。然后使用具有4層256個神經元和隱藏層為ReLU激活的MLP。每一組候選姿態都是在一次batch的前向傳遞中計算出來的。
相似性分數:
為每個圖像-姿態對計算余弦相似性來獲得相似性得分s。
在點積之后添加一個ReLU層,使得s∈[0,1]。
直觀地說,其目標是學習與實際相機姿態接近的候選姿態的高分。
有了這個公式后可以評估關于相機姿態的假設,并搜索得分高的姿態候選者。
相似性分數定義為:
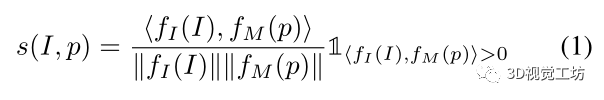
建議新的候選姿態:
基于在上一次迭代中使用的姿態候選獲得的分數,為這一次迭代選擇新的姿態候選。
首先選擇得分最高的B=100的姿態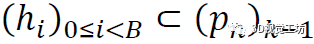
然后從(hi)中以高斯混合模型的方式對新的候選者進行采樣:
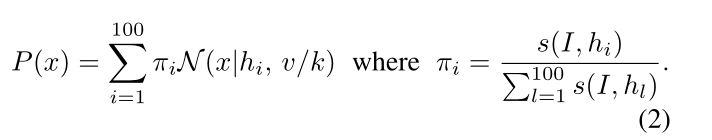
迭代姿態優化:
在每次迭代之后,將噪聲向量除以2,使得新的候選者被采樣為更接近先前的高分。
因此可以在千米級地圖中收斂到精確的姿態估計,同時只評估有限的稀疏姿態集。在每個時間步長獨立評估每個相機幀,但可以使用以前時間步長的定位先驗來減少車輛導航場景中的迭代次數。
每次迭代時所選姿態的示例如圖2所示。通過對初始姿態的N個候選進行采樣,保留了一個恒定的記憶峰值。

姿態平均:
最終的相機姿態估計是256個得分較高的候選姿態的加權平均值,與直接選擇得分最高的姿態相比,它具有更好的效果。使用分數作為加權系數,并實現3D旋轉平均。
損失函數:
通過計算參考圖像和以K種不同分辨率采樣的姿態候選者之間的分數來訓練網絡,
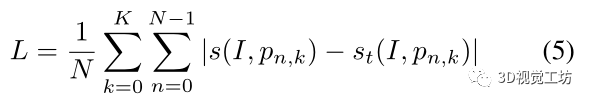
其中,st是基于相機姿態和候選姿態之間的平移和旋轉距離來定義。
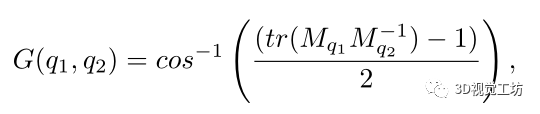
實驗:
與最近的方法在幾個數據集上進行了比較,這些數據集涵蓋了大規模室外環境中的各種自動駕駛場景。
由于戶外環境的動態部分(移動物體、照明、遮擋等),這項任務極具挑戰性。
驗證了其算法能夠在9個不同的大型室外場景中進行精確定位。
然后展示了算法可以擴展到多地圖場景
Baseline:
將ImPosing與基于學習的方法進行比較。使用CoordiNet報告了牛津數據集上絕對姿態回歸結果作為基線。
將ImPosing與檢索進行比較,使用了NetVLAD和GeM,使用全尺寸圖像來計算全局圖像描述符,然后使用余弦相似度進行特征比較,然后對前20個數據庫圖像的姿態進行姿態平均。
沒有使用基于結構的方法進行實驗,因為使用3D模型進行幾何推理,這些方法比更準確,但由于存儲限制使得嵌入式部署變得困難。
在Oxford RobotCar和Daoxiang Lake數據集上的定位誤差比較
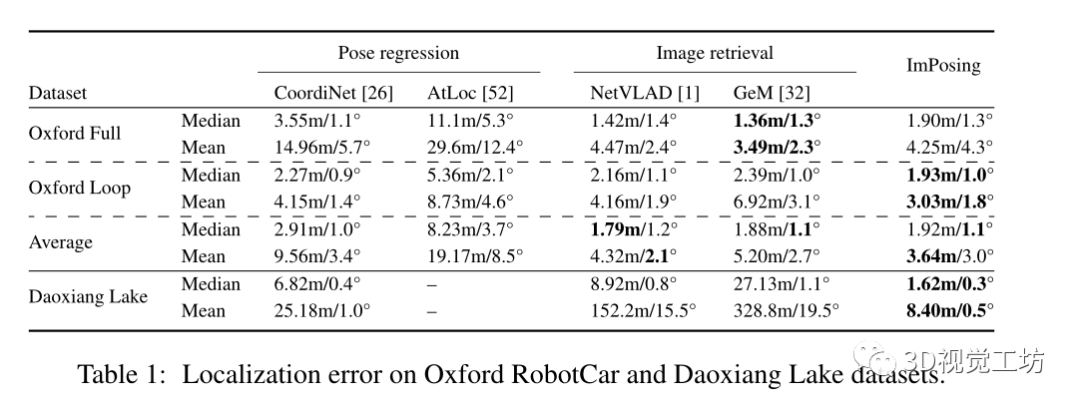
Daoxiang Lake是一個比Oxford RobotCar更具挑戰性的數據集,因為它的重復區域幾乎沒有判別特征,環境也多種多樣(城市、城郊、高速公路、自然等)。因此,圖像檢索的性能比姿態回歸差。ImPosing要準確得多,并且顯示出比競爭對手小4倍的中值誤差。
在4Seasons數據集上的比較:
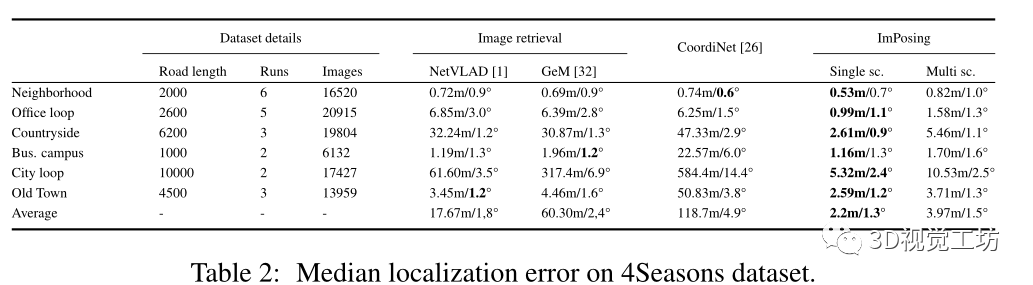
4Seasons數據集包含慕尼黑地區在不同季節條件下的各種場景(城市、居民區、鄉村)中記錄的數據。
因為是針對車輛部署的視覺定位算法,比較了各種算法的性能效率:
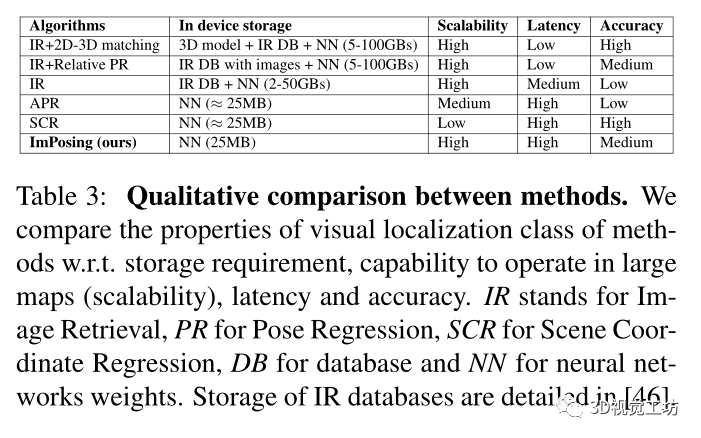
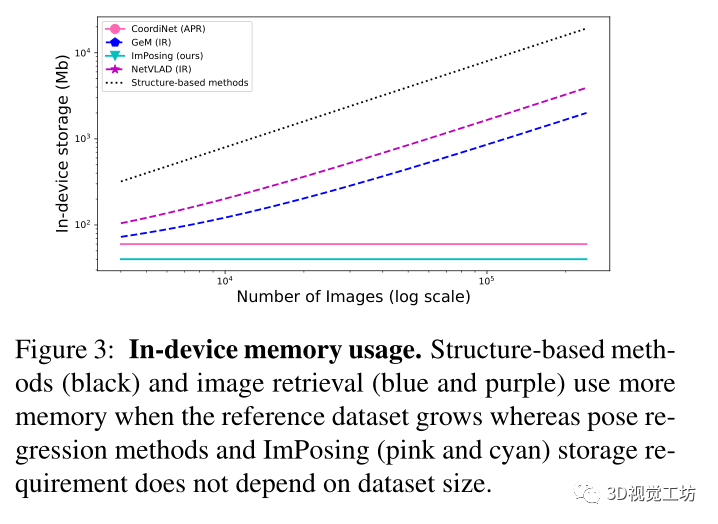
論文的算法只需要在設備中存儲神經網絡權重和初始姿態候選,其中圖像編碼器為23MB,姿態編碼器小于1MB,初始姿態候選為1MB。
在圖3中報告了不同類別視覺定位方法的內存占用相對于參考數據庫大小的縮放規律。這是有大量數據可用的自動駕駛場景中的一個重要方面。對于給定的地圖,基于學習的方法具有恒定的內存需求,因為地圖信息嵌入在網絡權重中。
總結:
提出了一種新的視覺定位范式,通過使用地圖的隱式表示,將相機姿態和圖像特征連接在一個非常適合定位的潛在高維流形中。
證明了通過一個簡單的姿態候選采樣過程,能夠估計圖像的絕對姿態。
通過提供一種高效準確的基于圖像的定位算法,該算法可以實時大規模操作,使其可以直接應用于自動駕駛系統。
但是方法的準確性在很大程度上取決于可用的訓練數據的數量。而且與回歸的方法類似,其不會泛化到遠離訓練示例的相機位置。
提出的方法可以在許多方面進行改進,包括探索更好的姿態編碼器架構;找到一種隱式表示3D模型的方法,將隱式地圖表示擴展到局部特征,而不是全局圖像特征。
審核編輯 :李倩
-
編碼器
+關注
關注
45文章
3595瀏覽量
134156 -
神經網絡
+關注
關注
42文章
4762瀏覽量
100537 -
算法
+關注
關注
23文章
4599瀏覽量
92643
原文標題:WACV 2023 | ImPosing:用于視覺定位的隱式姿態編碼
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

【芯靈思A83T試用申請】嵌入式視覺--遠距離物體跟蹤與定位
嵌入式姿態測量系統的姿態參數怎么計算?
基于三元Golay隱寫碼的快速隱寫算法
TPMS外置編碼存儲器式輪胎定位技術設計方案
面向AAV壓縮域的通用隱寫分析方法
網絡編碼姿態監控體域網的容錯性
醫療器械視覺定位應用
關于3D視覺定位技術詳細解析
STM32操作增量式編碼器(二)----使用編碼器接口實現定位

機器視覺檢測與機器視覺定位的區別與應用
一種基于RGB-D圖像序列的協同隱式神經同步定位與建圖(SLAM)系統
一種將NeRFs應用于視覺定位任務的新方法






 工商網監
工商網監
評論