 陳純院士報告分享:時序大數據流(圖)實時計算及智能決策
陳純院士報告分享:時序大數據流(圖)實時計算及智能決策
人類社會和物理空間在信息空間中映射有兩種基本表達結構,分別是針對對象的特征空間結構和針對關系的關聯圖譜結構。在互聯網、移動互聯網出現之后,這兩種結構所表達的數據都可以擁有時間戳。基于時間戳的數據被稱為 “時序數據”,時序數據是從2013年開始提出了的概念。從計算機算法的角度來看,時序數據有幾個特點:第一是增量的;第二是時序的,時間不能隔斷;第三是動態的;第四需要處理復雜的時序變化。
在2015年的時候,我們開始研究時序數據,有別于歷史數據和實時數據的處理,針對時序大數據流的實時計算,我們希望做到每秒千萬級并發訪問,千億級流水和高實時。
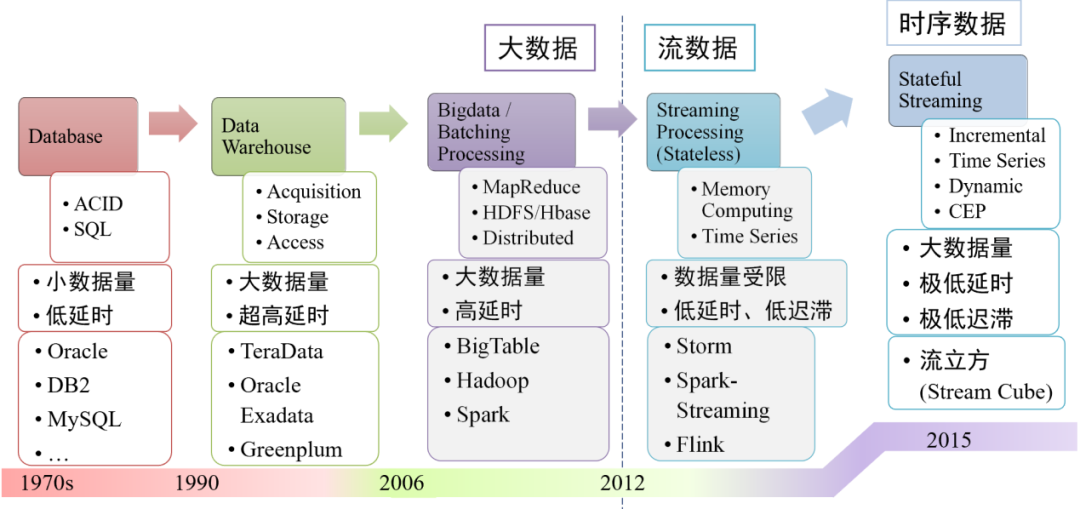
大數據、流數據到“時序大數據”發展歷程
針對時序大數據的處理,我們的研究工作涉及到四項關鍵技術,分別是:
1. 面向復雜統計指標的實時增量計算。基于多項式拆解的復雜算子增量計算算法,實現了在長周期、多尺度、高密度時間窗口中的方差、協方差、K階中心矩等數十種復雜算子實時計算。例如,從數學上,我們需要把計算協方差的方法重新寫成增量的方法,以前的數據不是簡單的原數據,而是通過計算以后的中間量,這需要花費很長的時間。我們用了十幾年的時間,把每個算法從數學的角度重新定義。
2. 面向時序數據處理的動態時間窗口技術。時間窗口需要提供滾動、滑動的漂移能力,也要支持長周期時間窗口的動態精度控制,并且還要支持基于彈性時間窗口的實時ADHoc查詢。
3. 多源時序數據的實時關聯計算。關聯分析非常重要,不僅僅是一個特征的時序分析,還需要關聯起來,這個時候需要有一個關聯分析的引擎。針對關聯分析的引擎,我們必須在內存里面有非常大的空間,但是要做到實時也是非常難的。
4. 基于流的事件序列識別(復雜事件處理CEP)。主要是支持CEP的增量匹配及數理統計問題,要把增量匹配增量統計。
通過多年的努力,我們基本上解決了四大關鍵技術問題,形成了我們稱之為的流立方技術。流立方能夠和均勻流架構完全結合起來,具有歷史數據的大數據量的處理能力,同時又具有流處理的實時能力。這是一個大數據處理的方式,因為在具體應用當中,大家會碰到很多大數據的分析,但是很多時候,都沒有加上時間這個緯度的分析,當然沒有加上時間緯度的分析也許能夠解決問題,但是要花費很大的計算量。這四項關鍵是處理大數據實時時序的大數據流分析,后面結合AI的模型,可以形成一個實時的流的管理。
流立方,除了流之外,還可以在圖上展示。特征空間的分析用特征向量就可以,加了一個在每個特征空間里面時間緯度,形成時序的時間分析。圖的分析是關聯分析,關聯分析圖也是可以加時間緯度。
如下圖所示,在2017年的時候已經知道圖數據的處理非常重要。同樣的,到了2018年的時候,圖越來越大,需要進行實時的圖計算,這個時候我們想到很多的方式,分布式的實時圖數據也有,類似于流處理,和以前的批處理的架構一樣。以前所謂的圖處理,現在是實時圖處理,關鍵是加上時序分析。到了2018年有1.0版,目前我們希望有2.0版,這里有大量的工作需要做。尤其是圖計算越來越重要,圖計算能夠產生80%的數據創新。通過圖計算分析能夠洞徹數據之間的關聯關系,提高社會運行效率,這是戰略的制高點。
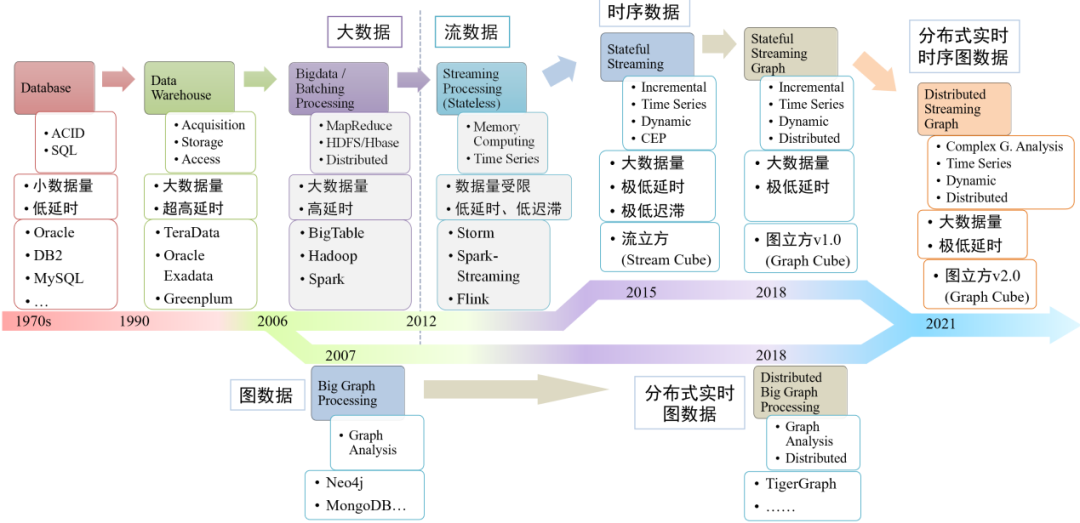
從“時序流”到“時序動態圖”的發展歷程
圖計算也是非常難的,實時圖計算,時序圖的動態回溯和分析,百億級頂點,萬億億的邊,兩兩都有邊,時間軸會變一下,有的頂點增加,有的頂點減少,有的關聯邊沒有了,有的邊增加了,這個關聯度要建立起來。這樣的應用案例非常多,去年在新冠期間,在實時的時空關聯中,有很多頂點,除了每個人是一個頂點之外,把時空分割起來也是一個頂點。所以,一個人在時間、空間上和你關聯起來,就是時空關聯。幾百億的頂點和邊,怎么做都是困難的,這里通過時序圖的實時增量計算和動態回溯,時序圖的分布式處理,時序圖的智能決策都有很大的挑戰性。在我們的研究工作中,這里依然由四項關鍵技術。
1. 時序圖的實時增量計算,包括統計特征,聚合的統計,聚合邊的關聯。圖和流不一樣,圖實時動,圖的結構就變了,到了下一時刻,原來是兩億的點的圖,變成了現在的2.3億,增加三千萬點。需要動態建圖,并且時序圖的增量匹配是個問題。事件驅動的圖模式并行匹配,需要很大的工作量,除此之外,更難的是原有的圖算法很多,需要進行圖算法的增量計算,有大量工作要做。
2. 時序圖的實時動態回溯。支持長周期、混合時間尺度的時序計算能力,以及支持彈性時間窗口的視圖實時回溯能力。關系在變化,每個切面都要變,需要實時進行查詢。
3. 時序圖的分布式內存存儲引擎。這么大的圖做到實時,一定要把數據導進內存,能不能做一個分布式的內存架構顯得非常重要。到目前為止,開源的流效益依然不高。我們做的時序圖分布式存儲引擎叫做cubebose,希望對圖的結構更加有效。
4. 面向時序圖的實時決策(三核智能決策引擎),把數據從實時采集到實時決策,指標計算特征提取這里面有圖數據庫,時間關系等。
針對時序圖的應用,銀行交易反欺詐系統是一個典型的案例。這個系統用到了流的處理引擎,是一個精巧的計算,可以不用大量的算力和計算機來做這個工作。銀聯要求每秒5萬個并發,希望在50毫秒內全球要響應,IBM的硬件要一千多萬,我們的算法只使用4臺PC設備。如果沒有時序流的計算,硬件不僅僅4臺,可能要40臺都不夠。
第二案例是鐵路12306,大量的爬票程序存在,需要在每秒170萬的并發量,幾千臺設備管理買票都要宕機。阿里的雙11支付的峰值是每秒60多萬,鐵路12306峰值達到180萬,是阿里的雙11的3倍。采用了我們的算法,僅僅使用了22臺設備。現在鐵路12306核心處理只有22臺,安裝了22個節點的流立方,可以做到每秒200萬的處理能力。
在數字經濟時代,數據怎么處理,從時間軸上面考慮,這是非常重要的。因為以前的算法沒有時間這個緯度,我們通過很多AI模型來計算來解決這個問題,但是加上時間,一切問題迎刃而解。黑客攻擊也是一樣,以前沒有時間戳,沒有辦法,加上時間戳很多問題很多模型都簡化很多,所以我建議大家在具體的數字經濟時代,當我們在處理數據的時候,結合場景,加一個緯度(時間)加上去看看,能不能起到一個很好的作用。
審核編輯 :李倩
-
算法
+關注
關注
23文章
4601瀏覽量
92673 -
模型
+關注
關注
1文章
3178瀏覽量
48731 -
大數據
+關注
關注
64文章
8864瀏覽量
137310
原文標題:陳純院士報告分享:時序大數據流(圖)實時計算及智能決策
文章出處:【微信號:信息與電子工程前沿FITEE,微信公眾號:信息與電子工程前沿FITEE】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
常見大數據應用有哪些?
ARMS: 原來實時計算可以這么簡單!
LabVIEW數據流語言的特點和有效控制方法
LabVIEW數據流控制方法研究
基于數據流的Java字節碼分析
網絡數據流存儲算法分析與實現

數據流的網絡實時入侵檢測
數據流是什么
實時計算在貝殼的實踐






 工商網監
工商網監
評論