") GPGPU流式多處理器架構(gòu)剖析(上)
GPGPU流式多處理器架構(gòu)剖析(上)
流式多處理器(Stream Multi-processor,SM)是構(gòu)建整個(gè) GPU的核心模塊(執(zhí)行整個(gè) Kernel Grid),一個(gè)流式多處理器上一般同時(shí)運(yùn)行多個(gè)線程塊。每個(gè)流式多處理器可以視為具有較小結(jié)構(gòu)的CPU,支持指令并行(多發(fā)射)。流式多處理器是線程塊的運(yùn)行載體,但一般不支持亂序執(zhí)行。每個(gè)流式多處理器上的單個(gè)Warp以SIMD方式執(zhí)行相同指令。
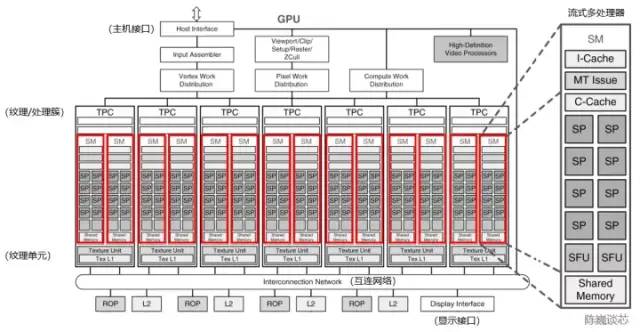
圖 3-1 流式多處理器在GPU架構(gòu)中的位置(以NVIDIA Tesla架構(gòu)為例,修改自NVIDIA)
3.1 整體微架構(gòu)
圖 3-3是流式多處理器(SM,AMD稱之為計(jì)算單元)微架構(gòu)(根據(jù)公開(kāi)文獻(xiàn)和專利信息綜合獲得)。
流式多處理器按照流水線可以分為SIMT前端和SIMD后端。整個(gè)流水線處理劃分為六個(gè)階段,包括取指、譯碼、發(fā)射、操作數(shù)傳送、執(zhí)行與寫(xiě)回。

圖 3-2 GPGPU的流式多處理器結(jié)構(gòu)劃分
SIMD即單指令多數(shù)據(jù),采用一個(gè)控制器來(lái)控制多組計(jì)算單元(或處理器),同時(shí)對(duì)一組數(shù)據(jù)(向量)中的每一個(gè)數(shù)據(jù)分別執(zhí)行相同的操作從而實(shí)現(xiàn)空間并行性計(jì)算的技術(shù)。
SIMT即單指令多線程,多個(gè)線程對(duì)不同的數(shù)據(jù)集執(zhí)行相同指令。SIMT的的優(yōu)勢(shì)在于無(wú)須把數(shù)據(jù)整理為合適的矢量長(zhǎng)度,并且SIMT允許每個(gè)線程有不同的邏輯分支。
按照軟件級(jí)別,SIMT層面,流式多處理器由線程塊組成,每個(gè)線程塊由多個(gè)線程束組成;SIMD層面,每個(gè)線程束內(nèi)部在同一時(shí)間執(zhí)行相同指令,對(duì)應(yīng)不同數(shù)據(jù),由統(tǒng)一的線程束調(diào)度器(Warp scheduler)調(diào)度。
一般意義上的CUDA核,對(duì)應(yīng)于流處理器(SP),以計(jì)算單元和分發(fā)端口為主組成。
線程塊調(diào)度程序?qū)⒕€程塊分派給 SIMT 前端,線程在流式多處理器上以Warp為單位并行執(zhí)行。

圖 3-3 GPGPU的流式多處理器微架構(gòu)
流式多處理器中的主要模塊包括:
取指單元(I-Fetch):負(fù)責(zé)將指令請(qǐng)求發(fā)送到指令緩存。并將程序計(jì)數(shù)器 (PC)指向下一條指令。
指令緩存(I-Cache):如來(lái)自取指單元的請(qǐng)求在指令緩存中被命中,則將指令傳送給譯碼單元,否則把請(qǐng)求保存在未命中狀態(tài)保持寄存器(MSHR)中。
譯碼單元(Decode):將指令解碼并轉(zhuǎn)發(fā)至I-Buffer。該單元還將源和目標(biāo)寄存器信息轉(zhuǎn)發(fā)到記分牌,并將指令類型、目標(biāo)地址(用于分支)和其他控制流相關(guān)信息轉(zhuǎn)發(fā)到 SIMT 堆棧。
SIMT 堆棧(SIMT Stack):SIMT堆棧負(fù)責(zé)管理控制流相關(guān)的指令和提供下一程序計(jì)數(shù)器相關(guān)的信息。
記分牌(Scoreboard):用于支持指令級(jí)并行。并行執(zhí)行多條獨(dú)立指令時(shí),由記分牌跟蹤掛起的寄存器寫(xiě)入狀態(tài)避免重復(fù)寫(xiě)入。
指令緩沖(I-Buffer):保存所有Warp中解碼后的指令信息。Warp 的循環(huán)調(diào)度策略決定了指令發(fā)射到執(zhí)行和寫(xiě)回階段的順序。
后端執(zhí)行單元:后端執(zhí)行單元包括CUDA核心(相當(dāng)于ALU)、特殊功能函數(shù)、LD/ST單元、張量核心(Tensor core)。特殊功能單元的數(shù)量通常比較少,計(jì)算相對(duì)復(fù)雜且執(zhí)行速度較慢。(例如,正弦、余弦、倒數(shù)、平方根)。
共享存儲(chǔ):除了寄存器文件,流式多處理器也有共享存儲(chǔ),用于保存線程塊不同線程經(jīng)常使用的公共數(shù)據(jù),以減少對(duì)全局內(nèi)存的訪問(wèn)頻率。
3.2 取指與譯碼

圖 3-4 GPU執(zhí)行流程(修改自 GPGPU-Sim)
取指-譯碼-執(zhí)行,是處理器運(yùn)行指令所遵循的一般周期性操作。
取指一般是指按照當(dāng)前存儲(chǔ)在程序計(jì)數(shù)器(Program Counter,PC)中的存儲(chǔ)地址,取出下一條指令,并存儲(chǔ)到指令寄存器中的過(guò)程。在取指操作結(jié)束時(shí),PC 指向?qū)⒃谙乱粋€(gè)周期讀取的下一條指令。
譯碼一般是指將存儲(chǔ)在指令寄存器中的指令解釋為傳輸給執(zhí)行單元的一系列控制信號(hào)。

圖 3-5 取指譯碼結(jié)構(gòu)
在GPGPU中,譯碼之后要對(duì)指令進(jìn)行調(diào)度,以保證后繼執(zhí)行單元的充分利用。這一調(diào)度通過(guò)線程束調(diào)度器(Warp Scheduler)實(shí)現(xiàn)。
線程束是為了提高效率打包的線程集合(NVIDIA稱之為Warps,AMD稱為Wavefronts)。在每一個(gè)循環(huán)中的調(diào)度單位是Warp,同一個(gè)Warp內(nèi)每個(gè)線程在同一時(shí)刻執(zhí)行相同命令。
取指與譯碼操作過(guò)程如下:
取指模塊(I-Fetch)根據(jù)PC指向的指令,從內(nèi)存中獲取到相應(yīng)的指令塊。需要注意的是,在GPGPU中,一般沒(méi)有CPU中常見(jiàn)的亂序執(zhí)行。

圖 3-5 取指模塊
-
指令緩存(I-Cache)讀取固定數(shù)量的字節(jié)(對(duì)齊),并將指令位存儲(chǔ)到寄存器中。
-
對(duì)I-Cache的請(qǐng)求會(huì)導(dǎo)致命中、未命中或保留失敗(Reservation fail)。保留失敗發(fā)生于未命中保持寄存器 (MSHR) 已滿或指令緩存中沒(méi)有可替換的區(qū)塊。不管命中或者未命中,循環(huán)取指都會(huì)移向下一Warp。
在命中的情況下,獲取的指令被發(fā)送到譯碼階段。在未命中的情況下,指令緩存將生成請(qǐng)求。當(dāng)接收到未命中響應(yīng)時(shí),新的指令塊被加載到指令緩存中,然后Warp再次訪問(wèn)指令緩存。
-
指令緩沖(I-Buffer)用于從I-Cache中獲取指令后對(duì)譯碼后的指令進(jìn)行緩沖。最近獲取的指令被譯碼器譯碼并存儲(chǔ)在 I-Buffer 中的相應(yīng)條目中,等待發(fā)射。
-
每個(gè) Warp 都至少對(duì)應(yīng)兩個(gè) I-Buffer。每個(gè) I-Buffer 條目都有一個(gè)有效位(Valid)、就緒位(Ready)和一個(gè)存于此 Warp 的已解碼的指令。有效位表示在 I-Buffer 中的該已解碼的指令還未發(fā)射,而就緒位則表示該Warp的已解碼的指令已準(zhǔn)備好發(fā)射到執(zhí)行流水線。

圖 3-4 指令緩沖
當(dāng)Warp內(nèi)的I-Buffer 為空時(shí),Warp以循環(huán)順序訪問(wèn)指令緩存。(默認(rèn)情況下,會(huì)獲取兩條連續(xù)的指令)這時(shí)對(duì)應(yīng)指令在I-Buffer中的有效位被激活,直到該Warp的所有提取的指令都被發(fā)送到執(zhí)行流水線。
當(dāng)所有線程都已執(zhí)行,且沒(méi)有任何未完成的存儲(chǔ)或?qū)Ρ镜丶拇嫫鞯膾炱饘?xiě)入,則 Warp 完成執(zhí)行且不再取指。當(dāng)線程塊中的所有Warp都執(zhí)行完成且沒(méi)有掛起的操作,標(biāo)記線程塊完成。所有線程塊完成標(biāo)記為內(nèi)核已完成。
相對(duì)于CPU,GPU的前端一般沒(méi)有亂序發(fā)射,每個(gè)核心的尺寸就可以更小,算力更密集。
3.3 發(fā)射
發(fā)射是指令就緒后,從指令緩沖進(jìn)入到執(zhí)行單元的過(guò)程。
在(譯碼后的)指令發(fā)射階段,指令循環(huán)仲裁選擇一個(gè)Warp,將I-Buffer中的發(fā)射到流水線的后級(jí),且每個(gè)周期可從同一Warp發(fā)射多條指令。
所發(fā)射的有效指令應(yīng)符合以下條件:
- 在Warp里未被設(shè)置為屏障等待狀態(tài);
- 在I-Buffer中已被設(shè)置為有效指令(有效位被置為1);
- 已通過(guò)計(jì)分板(Scoreboard)檢查;
- 指令流水線的操作數(shù)訪問(wèn)階段處于有效狀態(tài)。
在GPU中,不同的線程束的不同指令,經(jīng)由SIMT堆棧和線程束調(diào)度,選擇合適的就緒的指令發(fā)射。
在發(fā)射階段,存儲(chǔ)相關(guān)指令(Load、Store等)被發(fā)送至存儲(chǔ)流水線進(jìn)行相關(guān)存儲(chǔ)操作。其他指令被發(fā)送至后級(jí)SP(流處理器)進(jìn)行相關(guān)計(jì)算。
-
cpu
+關(guān)注
關(guān)注
68文章
10824瀏覽量
211138 -
gpu
+關(guān)注
關(guān)注
28文章
4700瀏覽量
128695 -
多處理器
+關(guān)注
關(guān)注
0文章
22瀏覽量
8912
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
GPGPU的流式多處理器微架構(gòu)原理解析
請(qǐng)問(wèn)有誰(shuí)做過(guò)串口的多處理器通信嗎?
什么是MSP430多處理器?MSP430多處理器有哪些技術(shù)要點(diǎn)?
總線可重配置的多處理器架構(gòu)
多處理器分組實(shí)時(shí)調(diào)度算法
基于NiosII的SOPC多處理器系統(tǒng)設(shè)計(jì)方法
什么是同步多處理器
GPGPU流式多處理器架構(gòu)及原理
GPGPU流式多處理器架構(gòu)剖析(下)
基于VPX6—460的多處理器通信設(shè)計(jì)

基于VPX6-460的多處理器通信設(shè)計(jì)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論