 納多德端到端IB解決方案
納多德端到端IB解決方案
在 ChatGPT 引爆科技領域之后,人們一直在討論 AI「下一步」的發展會是什么,很多學者都提到了多模態,我們并沒有等太久。近期,OpenAI 發布了多模態預訓練大模型 GPT-4,GPT-4 實現了以下幾個方面的飛躍式提升:強大的識圖能力、文字輸入限制提升至 2.5 萬字、回答準確性顯著提高、能夠生成歌詞、創意文本,實現風格變化。
如此高效的迭代,離不開人工智能大規模模型訓練,需要大量的計算資源和高速的數據傳輸網絡。其中,端到端IB(InfiniBand)網絡是一種高性能計算網絡,特別適合用于高性能計算和人工智能模型訓練。本文將介紹什么是AIGC模型訓練,為什么需要端到端IB網絡以及如何使用ChatGPT模型進行AIGC訓練。
AIGC是什么?
AIGC 即 AI Generated Content,是指人工智能自動生成內容,可用于繪畫、寫作、視頻等多種類型的內容創作。2022年AIGC高速發展,這其中深度學習模型不斷完善、開源模式的推動、大模型探索商業化的可能,成為AIGC發展的“加速度”。以最近爆火的聊天機器人ChatGPT為例,這款機器人既會寫論文,也能創作小說,還可編代碼,上線僅2個月,月活用戶達1億。因為出乎意料的“聰明”,AIGC被認為是“科技行業的下一個顛覆者”“內容生產力的一次重大革命”。
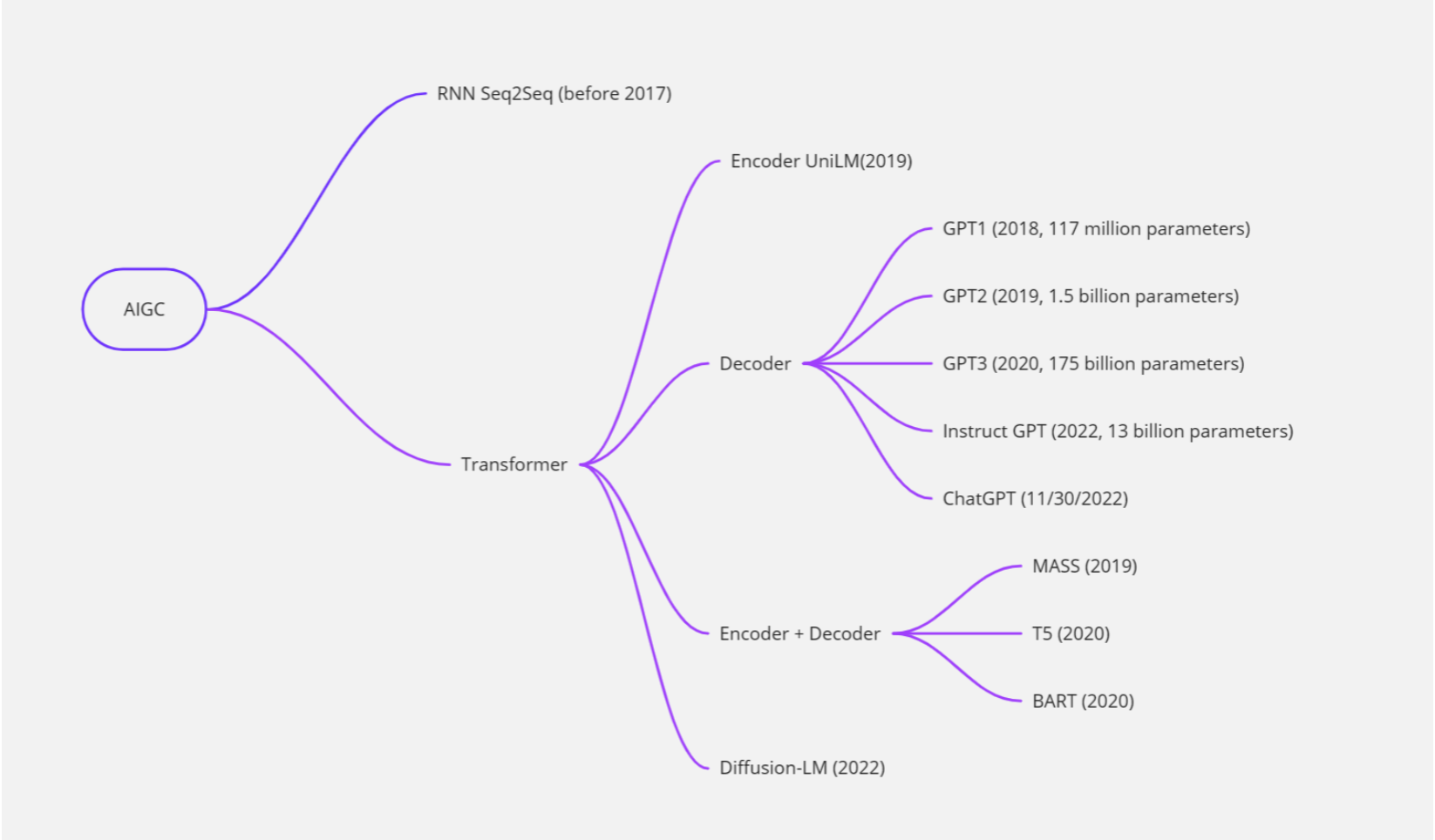
大型語言模型(LLM)和ChatGPT
大型語言模型(Large Language Model)是一種能夠自動學習并理解自然語言的人工智能技術。它通常基于深度學習算法,通過對大量文本數據的學習來獲取語言知識,并能夠自動生成自然語言文本,如對話、文章等。
ChatGPT是一種基于大型語言模型的聊天機器人,它采用了OpenAI開發的GPT(Generative Pre-trained Transformer)模型,通過對大量文本數據的預訓練和微調,能夠生成富有語言表達力的自然語言文本,并實現與用戶的交互。
因此,可以說ChatGPT是一種基于大型語言模型技術的聊天機器人,它利用了大型語言模型的強大語言理解和生成能力,從而能夠在對話中進行自然語言文本的生成和理解。
隨著深度學習技術的發展,大型語言模型的能力和規模不斷提升。最初的語言模型(如N-gram模型)只能考慮有限的上下文信息,而現代的大型語言模型(如BERT、GPT-3等)能夠考慮更長的上下文信息,并且具有更強的泛化能力和生成能力。
大型語言模型通常采用深度神經網絡進行訓練,如循環神經網絡(RNN)、長短時記憶網絡(LSTM)、門控循環單元(GRU)和變壓器網絡(Transformer)等。在訓練中,模型利用大規模的文本數據集,采用無監督或半監督的方式進行訓練。例如,BERT模型通過預測掩碼、下一個句子等任務來訓練,而GPT-3則采用了大規模的自監督學習方式。
大型語言模型在自然語言處理領域有廣泛的應用,例如機器翻譯、自然語言生成、問答系統、文本分類、情感分析等。
當前訓練LLM的瓶頸在哪里?
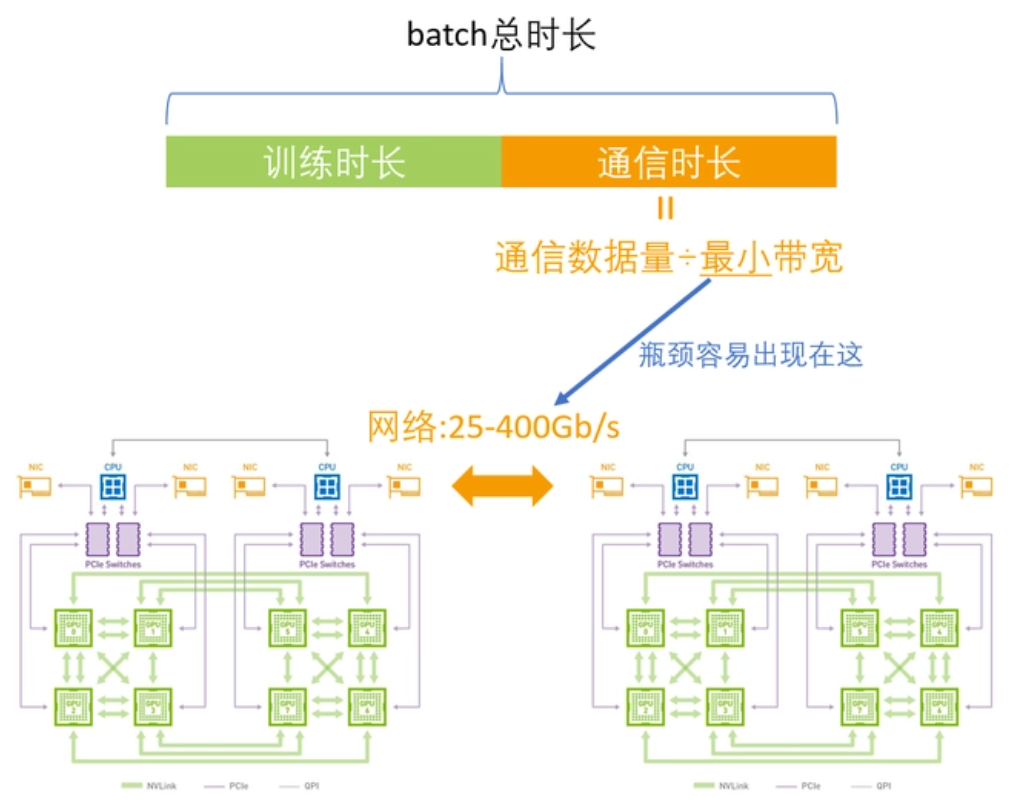
在訓練大型語言模型時,需要高速、可靠的網絡來傳輸大量的數據。例如OpenAI發布了第一版GPT模型(GPT-1),其模型規模為1.17億個參數。之后,OpenAI相繼發布了GPT-2和GPT-3等更大的模型,分別擁有1.5億和1.75萬億個參數。如此大的參數在單機訓練是完全不可能的,需要高度依賴GPU計算集群,目前的瓶頸在于如何解決訓練集群中各節點之間高效通信的問題。
目前比較常用的GPU通信算法就是Ring-Allreduce。其基本思想就是讓GPU形成一個環,讓數據在環內流動。環中的GPU都被安排在一個邏輯中,每個GPU有一個左鄰和一個右鄰,它只會向它的右鄰居發送數據,并從它的左鄰居接收數據。
該算法分兩個步驟進行:首先是scatter-reduce,然后是allgather。在scatter-reduce步驟中,GPU將交換數據,使每個GPU可得到最終結果的一個塊。在allgather步驟中,GPU將交換這些塊,以便所有GPU得到完整的最終結果。
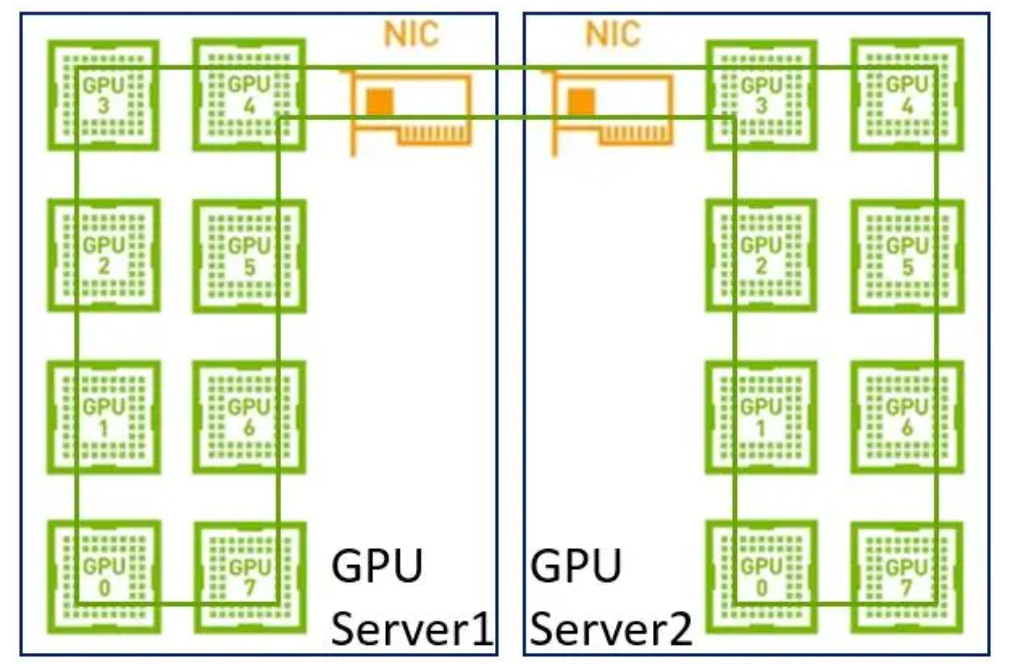
在早期,單機內部沒有NVLink,網絡上沒有RDMA,帶寬相對較低,單機分布式和多機分布式在帶寬上沒太大差別,所以建一個大環即可。
但是現在我們單機內部有了NVLink,在使用同樣的方法就不合適了。因為網絡的帶寬是遠低于NVLink,如果再用一個大環,那會導致NVLink的高帶寬被嚴重拉低到網絡的水平。其次,現在是具備多網卡的環境,如果只用一個環也無法充分利用多網卡優勢。
因此,在這樣的場景下建議采用兩級環:首先利用NVLink高帶寬優勢在單機內部的GPU之間完成數據同步;然后多機之間的GPU利用多網卡建立多個環,對不同分段數據進行同步;最后單機內部的GPU再同步一次,最終完成全部GPU的數據同步,在這里就不得不提到NCCL。
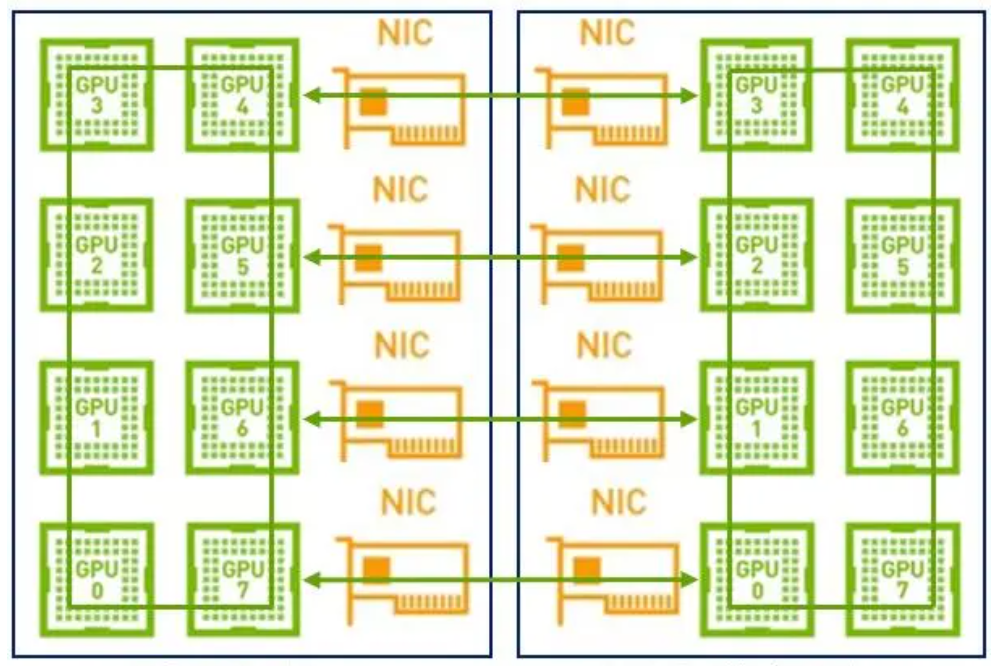
NVIDIA集體通信庫(NCCL)實現了針對NVIDIA GPU和網絡優化的多GPU和多節點通信原語。
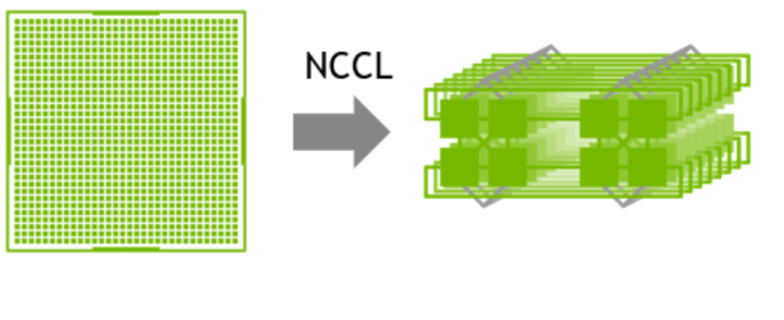
1GPU->multi-GPU multi node
NCCL提供全收集、全減、廣播、減少、減少散射以及點對點發送和接收等例程,這些例程經過優化,通過節點內和NVIDIA Mellanox網絡通過PCIe和NVLink高速互連實現高帶寬和低延遲。
為什么要使用端到端IB網絡?
以太網是一種廣泛使用的網絡協議,但其傳輸速率和延遲無法滿足大型模型訓練的需求。相比之下,端到端IB(InfiniBand)網絡是一種高性能計算網絡,能夠提供高達 400 Gbps 的傳輸速率和微秒級別的延遲,遠高于以太網的性能。這使得IB網絡成為大型模型訓練的首選網絡技術。
此外,端到端IB網絡還支持數據冗余和糾錯機制,能夠保證數據傳輸的可靠性。這在大型模型訓練中尤為重要,因為在處理如此多的數據時,數據傳輸錯誤或數據丟失可能會導致訓練過程中斷甚至失敗。
隨著網絡節點數目的急劇增加和計算能力不斷上升,高性能計算消除性能瓶頸和改進系統管理變得比以往更加重要。InfiniBand被認為是可以提升當前I/O架構性能瓶頸的一種極具潛力的I/O技術,如圖所示。InfiniBand是一種普及的、低延遲的、高帶寬的互連通信協議,處理開銷很低,非常適合在單個連接上承載多種流量類型(集群、通信、存儲和管理)。1999年,IBTA (InfiniBand Trade Association)制定了InfiniBand相關標準,在InfiniBand?中規范定義了用于互連服務器、通信基礎設施設備、存儲和嵌入式系統的輸入/輸出體系結構。InfiniBand是一項成熟的、經過現場驗證的技術,被廣泛應用于高性能計算集群中。
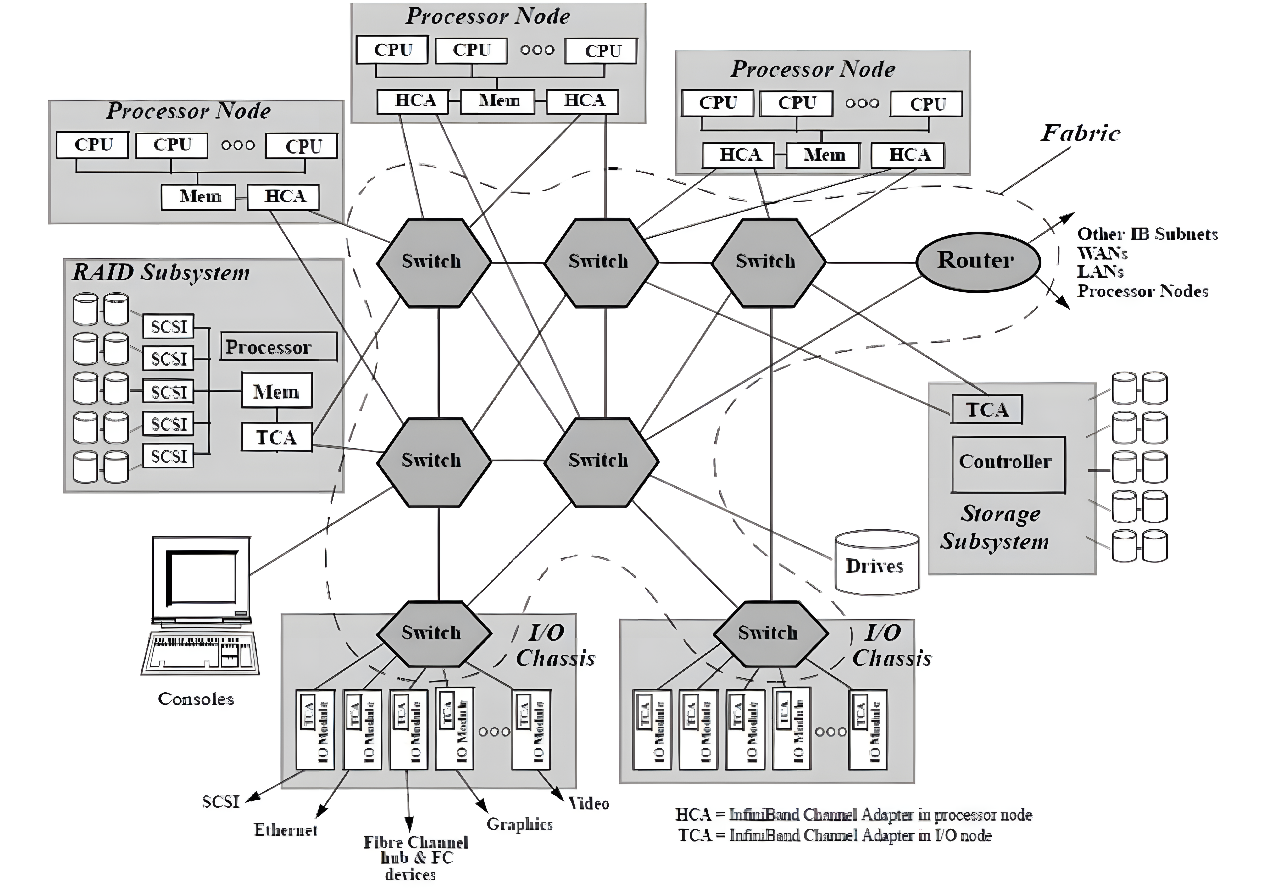
InfiniBand互連架構圖
InfiniBand互聯協議中規定,每個端節點必須有一個主機通道適配器(HCA)來設置和維護與主機設備的鏈接,交換機包含多個端口,并將數據包從一個端口轉發到另一個端口,完成在子網內傳輸數據的功能。子網管理器(Subnet Manager, SM)用于配置其本地子網并確保其持續運行,借助子網管理器數據包(Subnet Manager Packet, SMP)和每個InfiniBand設備上的子網管理代理(Subnet Manager Agent, SMA),子網管理器發現并初始化網絡,為所有設備分配唯一標識符,確定MTU(Maximum Transmission Unit,最小傳輸單元),并根據選定的路由算法生成交換機路由表。SM還定期對子網進行光掃描,以檢測任何拓撲變化,并相應地配置網絡。與其他網絡通信協議相比,InfiniBand網絡提供了更高的帶寬、更低的延遲和更強的可擴展性。此外,由于InfiniBand提供了基于credit的流控制(其中發送方節點發送的數據不會超過鏈路另一端的接收緩沖區公布的credit數量),傳輸層不需要像TCP窗口算法那樣的丟包機制來確定最佳的正在傳輸的數據包數量,這使得InfiniBand網絡能夠以極低的延遲和極低的CPU使用率為應用程序提供極高的數據傳輸速率。InfiniBand使用RDMA技術(Remote Direct Memory Access,遠程直接內存訪問)將數據從通道一端傳輸到另一端,RDMA是一種通過網絡在應用程序之間直接傳輸數據的協議,無需操作系統的參與,同時消耗雙方極低的CPU資源(零拷貝傳輸),一端的應用程序只需直接從內存中讀取消息,消息就已成功傳輸,減少的CPU開銷增加了網絡快速傳輸數據的能力,并允許應用程序更快地接收數據。
納多德端到端IB網絡解決方案
納多德基于對高速率網絡發展趨勢的理解,和豐富的HPC、AI項目實施經驗,提供基于NVIDIA Quantum-2交換機、 ConnectX InfiniBand 智能網卡和靈活的400Gb/s InfiniBand端到端解決方案,在降低成本和復雜性的同時在高性能計算 (HPC)、AI 和超大規模云基礎設施中帶來超強性能。
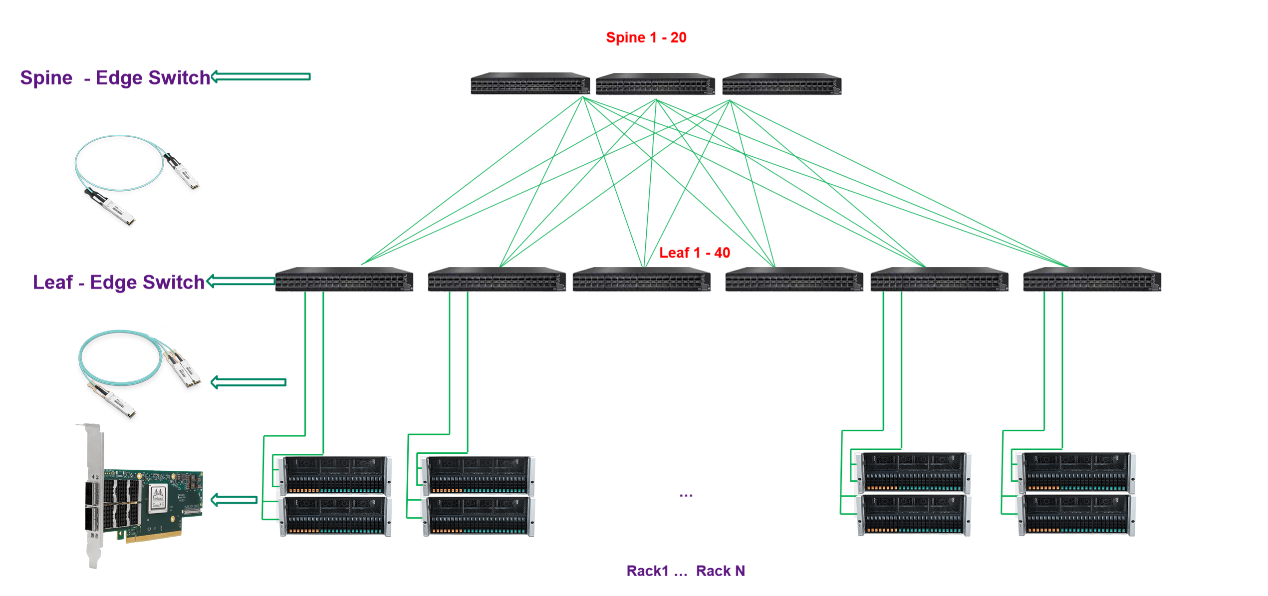
納多德數據中心IB網絡解決方案
交換機
更快的服務器、高性能存儲和日益復雜的計算應用正在將數據帶寬要求推向新的高度。NVIDIA Mellanox QM9700 交換機提供具有極低的延遲,NVIDIA Quantum-2 采用第七代 NVIDIA InfiniBand 架構,可為 AI 開發者和科學研究人員提供超強網絡性能和豐富功能,幫助他們解決充滿挑戰性的問題。NVIDIA Quantum-2 通過軟件定義網絡、網絡計算、性能隔離、高級加速引擎、遠程直接內存訪問 (RDMA) 以及高達 400 Gb/s 的超快的速度,為先進的超級計算數據中心提供助力。
智能網卡
納多德在網卡側提供NVIDIA ConnectX SmartNIC智能網卡,NVIDIA ConnectX InfiniBand 智能網卡支持更快的速度和創新的網絡計算技術,實現了超強性能和可擴展性。NVIDIA ConnectX 降低了每次操作的成本,從而可為高性能計算 (HPC)、機器學習、高性能存儲及數據庫業務和低延遲嵌入式等應用提高投資回報率。來自 NVIDIA Quantum-2 InfiniBand 架構的 ConnectX-7 智能網卡(HCA)可提供超高的網絡性能,用于處理極具挑戰性的工作負載。ConnectX-7 支持超低時延、400Gb/s 吞吐量和創新的 NVIDIA 網絡計算加速引擎,實現額外加速,為超級計算機、人工智能和超大規模云數據中心提供所需的高可擴展性和功能豐富的技術。
光模塊
納多德提供靈活的NVIDIA 400Gb/s InfiniBand光連接方案,包括使用單模和多模收發器、MPO光纖跳線、有源銅纜(ACC)和無源銅纜(DAC),用以滿足搭建各種網絡拓撲的需要。
>配有帶鰭設計的 OSFP 連接器的雙端口收發器適用于風冷固定配置交換機,而配有扁平式OSFP 連接器的雙端口收發器則適用于液冷模塊化交換機和 HCA 中。
>在交換機互連上,可選擇采用全新OSFP封裝 2XNDR(800Gbps) 光模塊進行兩臺 QM9700交換機的互連,帶鰭的設計,可以大大提高光模塊散熱性。
>交換機和HCA的互聯上,交換機端采用OSFP封裝2xNDR(800Gbps)帶鰭光模塊,網卡端采用帶有扁平OSFP 400Gbps光模塊,MPO光纖跳線可提供3-150米,一對二分光器光纖可提供3-50米。
>交換機到HCA的連接也提供DAC(最長1.5米)或者ACC(最長3米)的解決方案,一對二式分接線纜可用于交換機的一個OSFP端口(配備兩個400Gb/s InfiniBand端口)和兩個獨立的400Gb/s HCA。一分四式分接線纜可用于連接交換機的一個OSFP交換機端口和四個200Gb/s HCA。
納多德是光網絡解決方案的領先提供商,是NVIDIA網絡產品的Elite Partner,攜手NVIDIA實現光連接+網絡產品與解決方案的強強聯合,尤其是在InfiniBand高性能網絡建設與應用加速方面擁有深刻的業務理解和豐富的項目實施經驗,可根據用戶不同的應用場景,提供最優的InfiniBand高性能交換機+智能網卡+AOC/DAC/光模塊產品組合方案,為數據中心、高性能計算、邊緣計算、人工智能等應用場景提供更具優勢與價值的光網絡產品和整體解決方案,以低成本和出色的性能,大幅提高客戶業務加速能力。
審核編輯:湯梓紅
-
NVIDIA
+關注
關注
14文章
4949瀏覽量
102828 -
光模塊
+關注
關注
76文章
1240瀏覽量
58893 -
ChatGPT
+關注
關注
29文章
1549瀏覽量
7508 -
AIGC
+關注
關注
1文章
357瀏覽量
1512
發布評論請先 登錄
相關推薦
恩智浦完整的Matter端到端解決方案
華為端到端解決方案
集成數據網絡端到端和段到段監測解決方案
Airvana宣布全球首個端到端LTE毫微微蜂窩解決方案
USB Type-C端到端解決方案的應用
首個基于APP應用端的5G SA端到端切片解決方案成功實現
中興通訊端到端傳輸解決方案實現承載業務“光速直達”

松下幫助高校提供端到端解決方案
是德科技發布端到端PCIe5.0/6.0測試解決方案
華為IPv6+端到端解決方案通過信通院IPv6+ 2.0 Advanced測試評估

Mobileye端到端自動駕駛解決方案的深度解析






 工商網監
工商網監
評論