 河套IT TALK 67: (原創) 基于深度學習的超分技術(萬字長文)
河套IT TALK 67: (原創) 基于深度學習的超分技術(萬字長文)


當我們談論視頻技術時,超高清視頻(Ultra High Definition,簡稱UHD)無疑是當今最令人興奮的領域之一。上期,我們介紹了使用復雜的算法來創建一個三維聲場,給觀眾帶來音頻的空間感、方位感、高還原度、高沉浸度、臨場感,個性化的三維聲技術。本期,我們就聊聊最近非常火的基于深度學習的超分技術。
關聯回顧
全圖說電視的發展歷史
全圖說視頻編解碼的發展歷史
由淺入深說高清——聊聊高動態范圍(HDR)
由淺入深說高清——HDR的標準之爭
由淺入深說高清——HDR的適配性與流程化的挑戰由淺入深說高清——讓人眼花繚亂的超高清視頻編解碼格式由淺入深說高清——超高清視頻的三維聲技術1. 前言
視頻超分技術(Video super-resolution),簡稱VSR,是將低分辨率(Low Resolution,簡稱:LR)的視頻轉換為高分辨率(High Resolution,簡稱:HR)視頻的過程。與單圖像超分技術(Single Image Super-Resolution,簡稱:SISR)不同,這不是把視頻圖像的每一幀恢復到更多的細節,更重要的是能夠保持整個視頻幀的運動一致性。
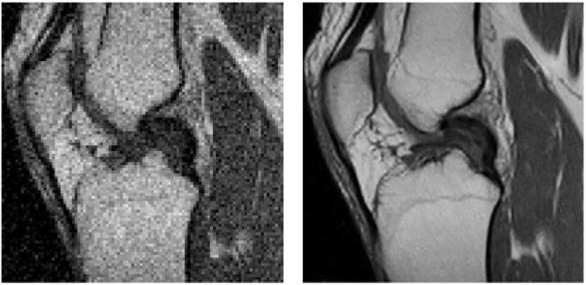
為什么我們不直接看高分辨率的視頻,而要使用超分技術去逆向轉換呢?答案也非常簡單:因為沒有高清片源。高清視頻是最近幾年才火起來的事情,在這之前大量的視頻片源就沒有高清。而且我們經常在手機上觀看以為的高清視頻,投射到大的液晶屏幕上,就顯得模糊不清,因為同樣像素的視頻內容,被延展到更大屏幕上,只會把原本很小的彩色像素點拉成一個一個肉眼可見的彩色小方塊。如果不通過超分技術,要么忍受這種模糊,要么就只能在高清電視上重新去搜索匹配的高清片源,但又要花錢不是?能搜到片源還算好的,好多時候,花錢也未必能解決問題。比如在醫學圖像領域(MRT、CT、PET等等),出于圖像掃描技術的局限,片源的分辨率很難做上來,如果沒有超分技術,那些原始醫療圖像掃描完,醫生看到就都是慘不忍睹的噪點。
第一次正式提出深度學習這個詞兒的是加州大學的計算機科學教授麗娜·德克特(Rina Dechter)。她在 1986 年的一篇論文中率先使用了深度學習(Deep Learning)。深度學習是機器學習的一種,它使用多層人工神經網絡 (ANN) 對數據中的復雜模式進行建模。對于必須將多少層的 ANN 視為“深度”并沒有嚴格的規定,但通常,具有多個隱藏層的神經網絡可被視為深度學習模型。實際上,深度學習模型可以有幾十層、幾百層甚至幾千層。然而,層數本身并不是決定深度學習模型性能的唯一因素,其他因素如每層神經元數量、使用的激活函數和訓練方法也會對深度學習模型產生重大影響。模型的有效性。
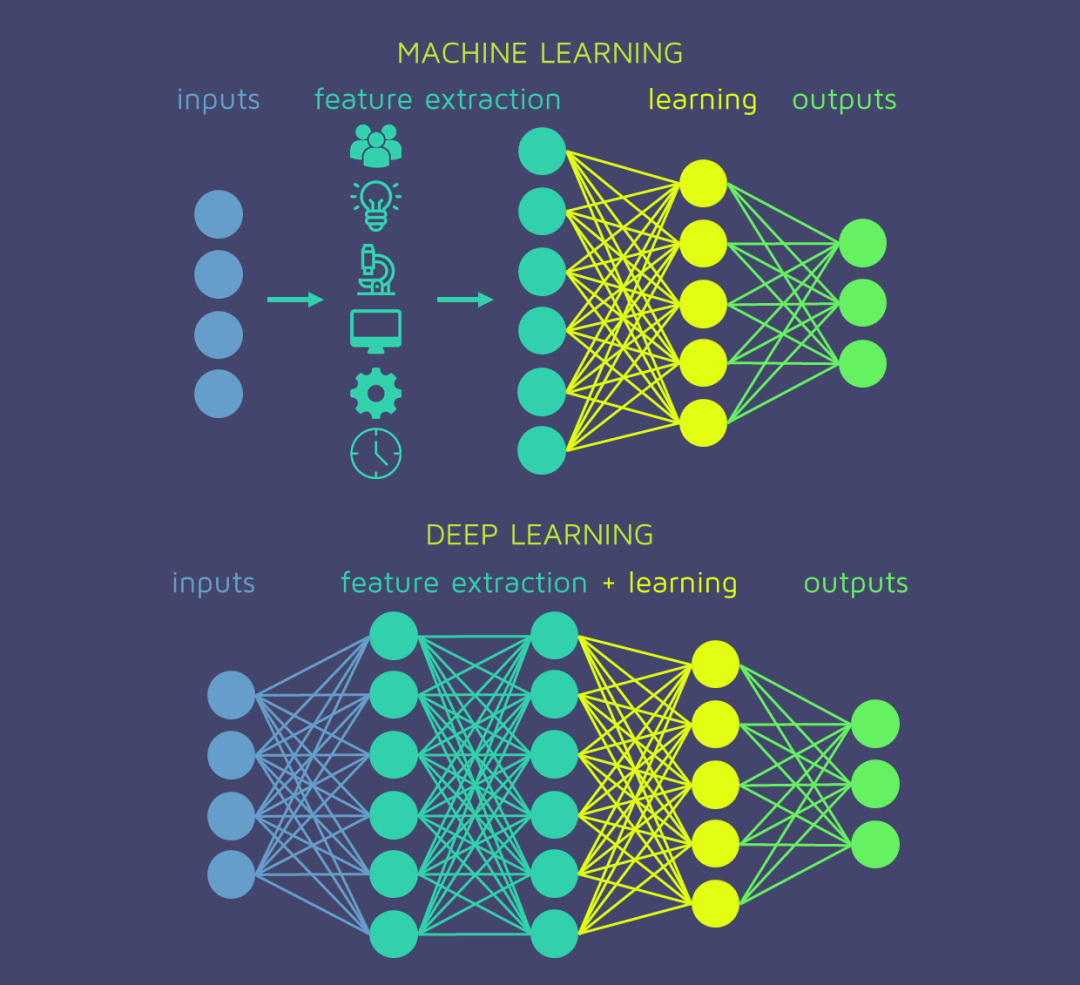
深度學習使用多層從原始輸入中逐步提取更高級別的特征。例如,在圖像處理中,較低層可以識別邊緣,而較高層可以識別與人類相關的概念,例如數字、字母或面孔。從另一個角度來看深度學習,深度學習是指“計算機模擬”或“自動化”人類從源(例如,狗的圖像)到學習對象(狗)的學習過程。
深度學習的算法本來就有很多種,比較經典的包括:深度神經網絡(Deep Neural Networks, 簡稱DNN)、深度置信網絡(Deep Belief Networks, 簡稱DBN)、深度強化學習(Deep Reinforcement Learning, 簡稱DRN)、遞歸神經網絡(Recurrent Neural Networks, 簡稱RNN)、卷積神經網絡(Convolutional Neural Networks, 簡稱CNN)以及我們最近非常火的應用在ChatGPT中的Transformer。這些算法被廣泛應用在計算機視覺、語音識別、自然語言處理、機器翻譯、生物信息學、藥物設計、氣象科學、信息管理等領域。視頻超分當然是其中的熱門應用場景。
3. 為什么現在才熱起來?你可能會好奇,為啥基于深度學習的視頻超分技術最近才火起來?深度學習也不是一個新鮮概念了。萬事萬物的發展都是相互關聯和相互促進的,任何技術領域的拐點或者奇點爆發,都是經過長時間的鋪墊和蓄能醞釀。在25年前,我還在讀研究生的時候,當時的課題就是通過神經網絡的方式用紫外光傳感器對制冷系統中潤滑油質量分數的實時測量。我理解為什么深度學習被研究人員一直追捧,但總是雷聲大雨點小,主要有以下幾個約束:1. 計算機的處理性能;2. 網絡速度的局限;3. 學習樣本的局限,以及在學習樣本中的數字版權問題;4. 缺乏良好的開源軟件管理系統讓算法被充分共享。近些年,以上瓶頸都已經化解,深度學習開始出現了爆炸式的增長。
4. 基于深度學習的超分技術的優勢有一些傳統的超分技術,包括小波變換和第二代小波變換的頻域超分技術、使用卡爾曼濾波器的迭代自適應濾波算法、最大后驗(MAP)和馬爾可夫隨機場(MRF)的概率方法等等,毫無疑問,這些傳統超分技術表現并不如意。近期,基于深度學習的視頻超分算法表現出了比傳統超分算法明顯的優勢,主要表現以下幾點:
-
-
學習復雜關系的能力強:傳統方法依靠手工制作的特征和啟發式方法在低分辨率視頻幀中插入缺失的信息。這限制了他們學習低分辨率和高分辨率視頻幀之間復雜關系的能力,并且他們可能無法生成視覺上令人愉悅的高辨率視頻。基于深度學習的方法可以學習低分辨率和高分辨率視頻幀之間更復雜的關系,使它們能夠產生更準確和視覺上令人愉悅的結果。
-
不必依賴特定運動模型:傳統方法假設視頻幀有特定的運動模型,例如全局運動或塊運動。這會限制它們處理視頻幀之間復雜運動的能力,并可能導致運動偽影和高辨率視頻中的模糊。基于深度學習的方法可以處理視頻幀之間的復雜運動。
-
計算成本低:傳統方法的計算成本可能很高,并且可能需要大量計算資源才能生成高分辨率視頻。這限制了它們實時執行超分計算的能力,并可能使它們對某些應用不切實際。許多基于深度學習的視頻超分方法可以實時進行超分計算,這對于低成本視頻流和實時視頻分析等應用很重要。
- 對噪聲和偽影的魯棒性強:傳統方法對輸入視頻幀中的噪聲和偽影敏感,并且在面對嘈雜或低質量輸入幀時可能會產生模糊或失真的結果。而基于深度學習的方法對輸入視頻幀中的噪聲和偽影的魯棒性更強,即使輸入幀有噪聲或失真,也能生成高質量的高辨率視頻。
-
正是因為前面提到的優勢,使得基于深度學習的超分技術最近成為視頻處理和計算機視覺領域許多應用的熱門選擇,顯示出巨大潛力。現在,深度學習如春筍般在超分技術領域開得漫山遍野,但目前尚未出現一種深度學習的超分算法展露絕對的優勢,達到普遍“令人滿意”的狀態。以至于直到當下,不管在研究領域,還是在生態運用領域,所有的算法都是百花爭鳴,各有千秋。之所以出現這種狀況,有以下幾個原因:
-
-
不同的數據集:基于深度學習的視頻超分算法需要在特定的數據集上進行訓練和評估,以確保其有效性。然而,不同的數據集具有不同的特征,例如分辨率、噪聲水平和運動模式。這會影響視頻超分算法的性能,這意味著在一個數據集上表現良好的方法在另一個數據集上可能表現不佳。這其實也暴露了深度學習一直以來的問題,就是結果的不可預知性。
-
不同視頻類型的運動特征差異巨大:視頻幀可以有不同類型的運動,例如全局運動、局部運動和復雜運動。不同的視頻超分方法可能更適合處理不同類型的運動,這意味著在一種類型的運動上表現良好的方法可能在另一種類型的運動上表現不佳。
-
不同因素的權衡,魚與熊掌不可兼得:不同的視頻超分方法可能會在計算復雜度、視覺質量和速度等因素之間做出不同的權衡。例如,生成高質量高分辨率視頻的方法可能計算量大且速度慢,而速度更快的方法可能生成質量較低的視頻。
-
看來我們要簡單明了地單刀直入,講明白基于深度學習的超分技術并不容易,必須要娓娓道來。
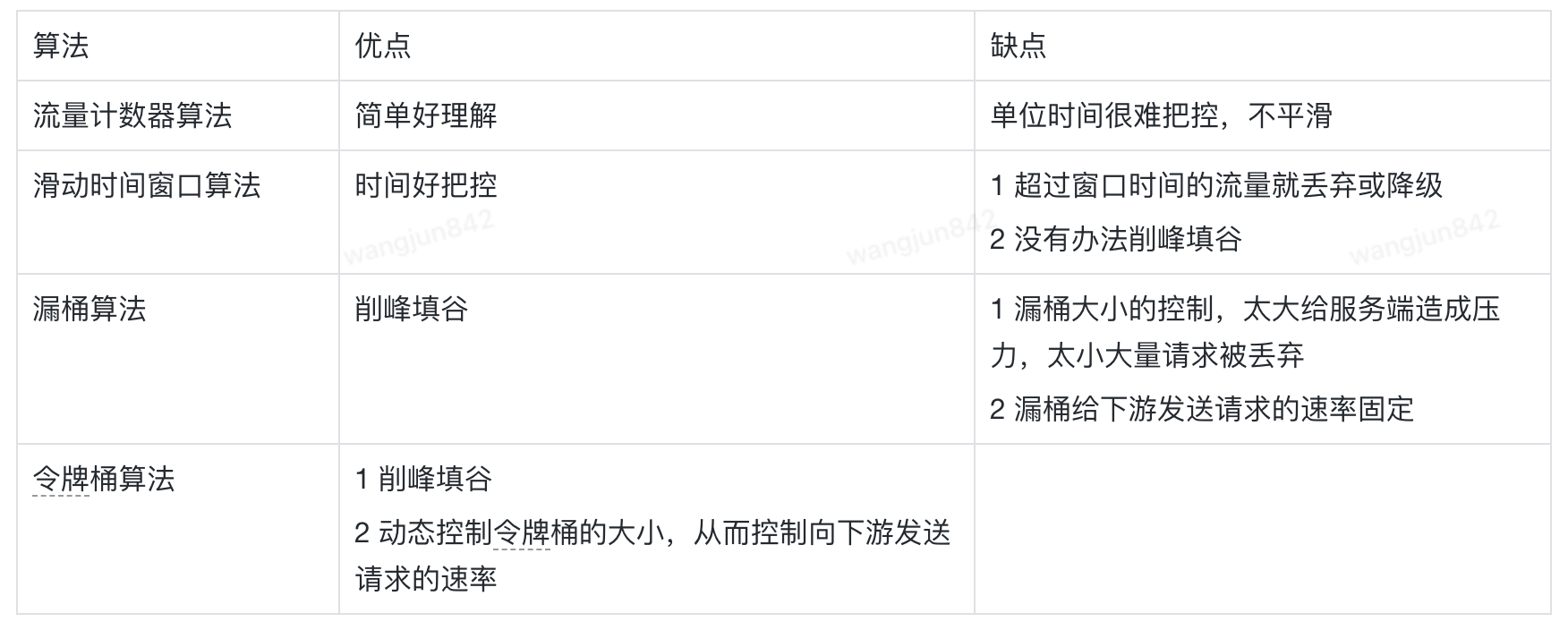
6. 超分技術的基本概念和評價指標高清視頻的退化公式
談超分技術,必須要懂得基礎圖像的知識,首當其沖,就是要理解高清視頻的退化公式:
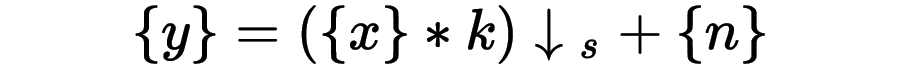
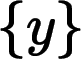 ?—— 代表低分辨率幀序列
?—— 代表低分辨率幀序列
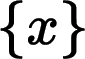 ?—— 代表原始高分辨率幀序列
?—— 代表原始高分辨率幀序列
* ——卷積運算
k——模糊核
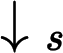 ?——?代表下采樣s倍
?——?代表下采樣s倍
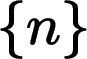 ?——?代表高斯噪聲
?——?代表高斯噪聲
超分計算是逆運算,也就是根據幀序列來估計幀序列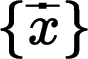 ,并且讓接近原裝的這么一個過程。
,并且讓接近原裝的這么一個過程。
視頻質量主要通過峰值信噪比(PSNR)和結構相似性指數(SSIM)來評價。
峰值信噪比(PSNR)
PSNR是峰值信噪比(Peak Signal-to-Noise Ratio)的英文縮寫。
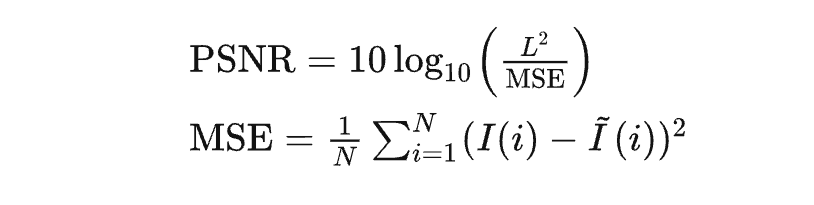
其中L表示顏色值的最大范圍,通常為255,N表示圖像中像素的總數,MSE經常作為損失函數出現。MSE表示輸出視頻和原始視頻的均方誤差(Mean Square Error)。
盡管PSNR是最普遍和使用最為廣泛的一種圖像客觀評價指標,然而它并未考慮到人眼的視覺特性(人眼對空間頻率較低的對比差異敏感度較高,人眼對亮度對比差異的敏感度較色度高,人眼對一個區域的感知結果會受到其周圍鄰近區域的影響等),因而經常出現評價結果與人的主觀感覺不一致的情況。
結構相似性(SSIM)
SSIM是結構相似性(Structural SIMilarity)的英文縮寫。
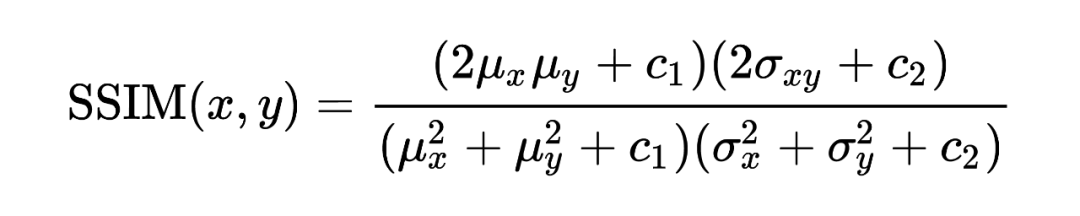
SSIM是一種衡量兩幅圖像相似度的指標。SSIM 在圖像處理社區以及電視和社交媒體行業得到廣泛采用。該指標首先由德州大學奧斯丁分校的圖像和視頻工程實驗室(Laboratory for Image and Video Engineering)提出。而如果兩幅圖像是壓縮前和壓縮后的圖像,那么SSIM算法就可以用來評估壓縮后的圖像質量。SSIM公式基于樣本之間的三個比較衡量:亮度 (luminance)、對比度 (contrast) 和結構 (structure)。
目前除了PSNR和SSIM,還有一些其他的指標也被使用,包括:信息保真度標準(IFC)、視覺信息保真度(VIF)、基于運動的視頻完整性評估指數(MOVIE)和視頻多方法評估融合(VMAF)等等,但是這些指標也并無完美,目前缺乏客觀指標來驗證視頻超分辨率方法還原真實細節的能力。該領域目前正在進行研究。很多機構組織的視頻超分技術比拼的基準測試,普遍都是用PSNR , SSIM等客觀指標來評價,當然也會依賴于平均意見得分(MOS)非常主觀的評價進行糾偏和修正。
7. 基于深度學習的超分算法示例既然基于深度學習的超分技術對應的算法很多,我們就無法做到一一解釋,不僅讓本篇的篇幅冗長,而且全部都是專業術語,相信也會超級乏味,嚇阻你們繼續讀下去。所以我們僅摘錄其中典型的算法給大家簡單解釋一下,希望能讓大家有一個基本概況的了解。但即便如此,今天談到的超分算法也有9大類16個算法,而這些只是諸多超分算法中的一小部分。
7.1 預上采樣
“預上采樣”部分意味著低分辨率輸入圖像在被輸入深度學習模型之前首先使用簡單的算法(例如雙線性插值)增加尺寸。這樣做的原因是為模型提供更詳細的信息以供處理,從而產生更高質量的輸出圖像。通過在輸入圖像通過模型之前對其進行上采樣,模型可以更好地理解圖像的細節和紋理,并產生更準確和詳細的輸出。總的來說,預上采樣超分辨率是一種通過使用輸入圖像的放大版本的深度學習模型來使低分辨率圖像看起來更好的技術。
7.1.1 SRCNN
SRCNN是超分卷積神經網絡(Super-Resolution Convolutional. Neural Network)的縮寫。
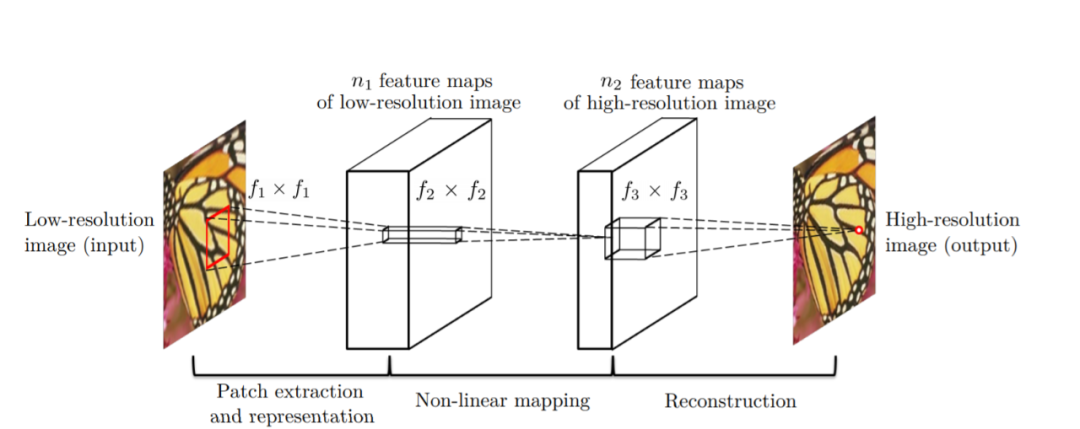
SRCNN 架構,由三層組成:補丁提取層(Patch Extraction and Representation)、非線性映射層(Non-Linear Mapping)和重建層(Reconstruction)。補丁提取層用于從輸入中提取密集補丁,并使用卷積濾波器表示它們。非線性映射層由 1×1 卷積濾波器組成,用于改變通道數并添加非線性。最后,重建層來重建高分辨率圖像。

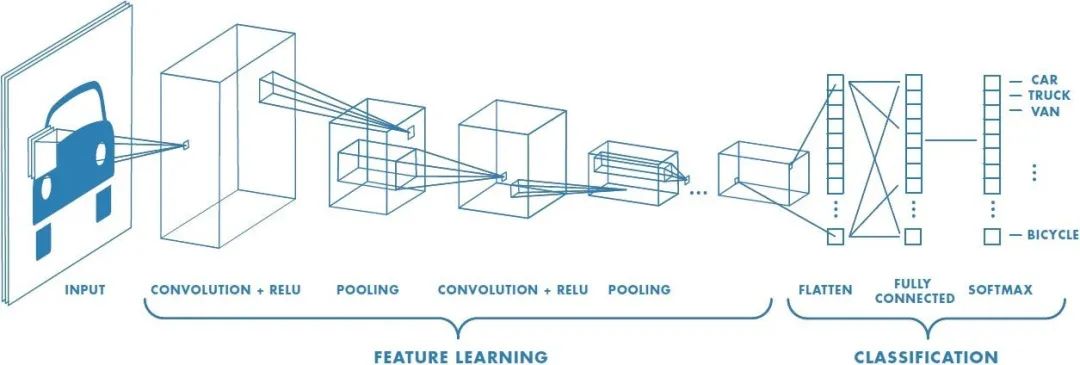 卷積神經網絡(Convolutional Neural Networks,簡稱:CNN) 背后的基本思想是使用卷積層從輸入數據中自動學習和提取特征。卷積是一種數學運算,它將兩個函數結合起來產生第三個函數,該函數表示一個原始函數如何被另一個函數修改。在 CNN 中,卷積層將一組過濾器應用于輸入數據,這些過濾器可以識別圖像中的特定特征或模式,例如邊緣、角或紋理。
卷積神經網絡(Convolutional Neural Networks,簡稱:CNN) 背后的基本思想是使用卷積層從輸入數據中自動學習和提取特征。卷積是一種數學運算,它將兩個函數結合起來產生第三個函數,該函數表示一個原始函數如何被另一個函數修改。在 CNN 中,卷積層將一組過濾器應用于輸入數據,這些過濾器可以識別圖像中的特定特征或模式,例如邊緣、角或紋理。CNN 通常由多層組成,包括卷積層、池化層和全連接層。池化層用于減小輸入的空間大小,同時保留重要特征,全連接層用于根據卷積層和池化層學習到的特征進行預測。
CNN 已被證明在許多圖像和視頻相關任務中非常有效,例如對象檢測、圖像分類和分割。
7.1.2 VDSR
VDSR是非常深超分 (Very Deep Super Resolution) 的縮寫,VDSR是對 SRCNN 的改進,增加了以下功能:
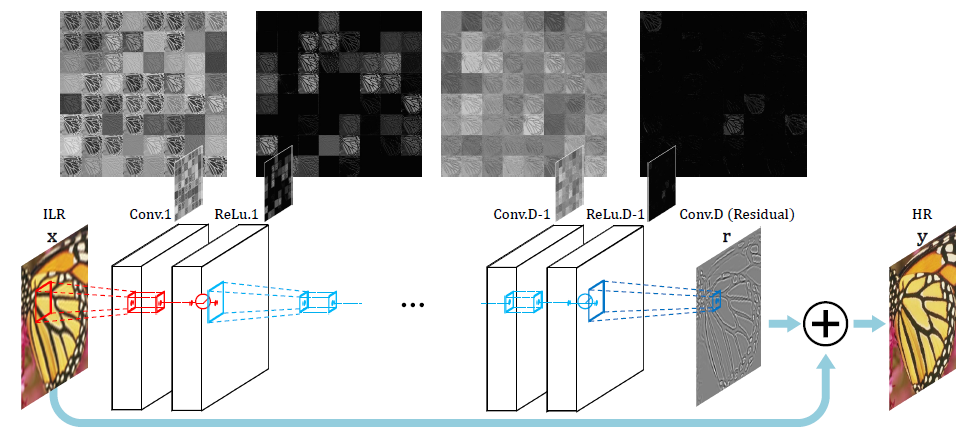
網絡嘗試學習輸出圖像和插值輸入的殘差,而不是學習直接映射(如 SRCNN),如上圖所示。這種操作簡化了任務,將初始的低分辨率圖像添加到網絡輸出中以獲得最終的 高分辨率輸出。
通過梯度裁剪用于訓練具有更高學習率的深度網絡。梯度裁剪是一種在訓練期間用于防止梯度變得太大或太小的技術。當梯度的范數超過某個閾值時,按比例縮小梯度,使其范數等于閾值。這有助于穩定訓練過程并防止數值不穩定,以幫助模型更快收斂并產生更好的結果。避免在某些情況下,梯度會變得太大或太小,這會導致優化算法發散或收斂太慢。
7.2 后上采樣
上文說到的預上采樣,存在諸多不便:
-
-
?預上采樣首先使用簡單的上采樣算法增加輸入圖像的分辨率,這在計算上可能很昂貴,尤其是對于大圖像。
-
預上采樣有時會導致過度擬合,模型會記住上采樣算法的細節,而不是學習圖像的底層特征。
-
預上采樣用于提高輸入圖像分辨率的上采樣算法是固定的,這可能導致分辨率與訓練分辨率不同的圖像輸出圖像質量較低。
-
預上采樣首先使用簡單的上采樣算法提高輸入圖像的分辨率,而后上采樣在圖像經過超分模型處理后再執行上采樣。具體來說就是低分辨率輸入圖像通過深度學習模型,學習從圖像中提取高級特征和細節。一旦模型處理完圖像,就會使用學習到的上采樣算法將生成的特征圖上采樣到所需的分辨率。最終通過將上采樣的特征圖與原始低分辨率圖像相結合而獲得高分辨率圖像。
這樣一來,后上采樣在處理圖像之前不需要額外的上采樣步驟,從而降低計算復雜度和內存使用量。同時由于上采樣算法是作為模型的一部分學習的,又會避免過度擬合。最后,深度學習模型可以在上采樣之前從低分辨率輸入圖像中學習最相關的特征和細節,更有效地處理不同的分辨率,從而產生更準確和更詳細的輸出圖像。
7.2.1 FSRCNN
FSRCNN是快速超分卷積神經網絡(Fast Super-Resolution Convolutional Neural Network)的縮寫。
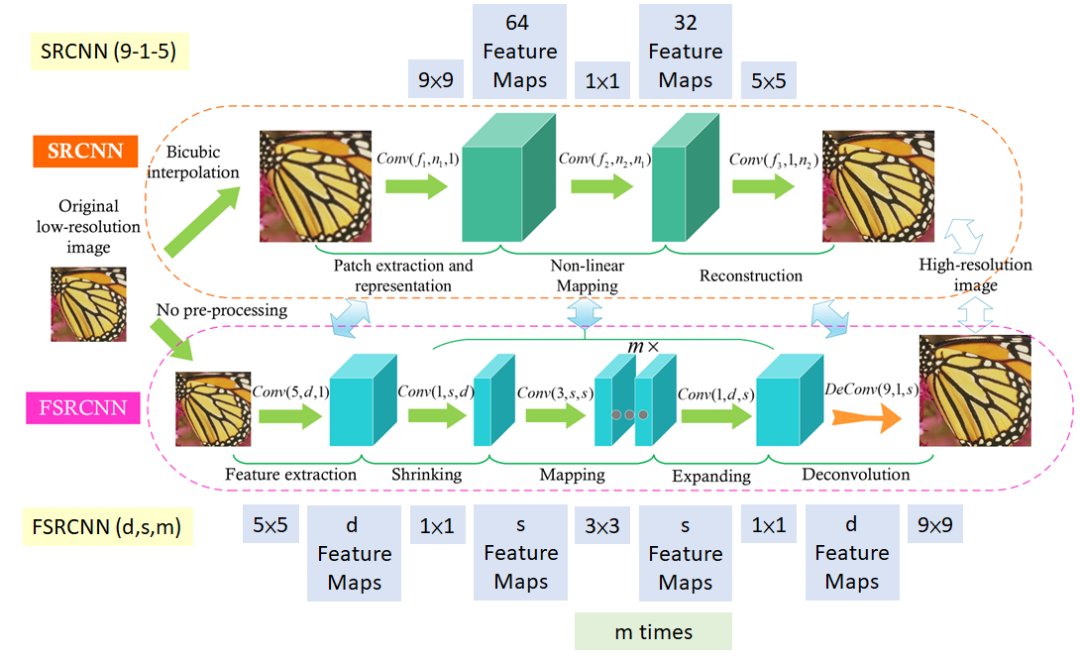
從上圖可以看出,和SRCNN相比,FSRCNN有以下變化:
-
-
更少的參數:與 SRCNN 相比,FSRCNN 的參數更少,這使其速度更快,內存效率更高。使用多個 3×3 卷積,而不是使用大的卷積濾波器,類似于視覺幾何組(VGG)網絡通過簡化架構來減少參數數量的工作方式。
-
更快的推理:在初始 5×5 卷積之后使用 1×1 卷積來減少通道數量,從而減少計算和內存。FSRCNN 旨在通過使用較少數量的過濾器和減小中間特征圖的大小來比 SRCNN 更快。這使其能夠實時或接近實時地執行超分辨率,使其適用于現實世界的應用。
-
多個上采樣階段:FSRCNN 使用多個上采樣階段來逐漸提高圖像的分辨率,這有助于保留精細細節并減少偽影。上采樣是通過使用學習的反卷積濾波器完成的,從而改進了模型。
-
端到端訓練:FSRCNN 是端到端訓練的,這意味著整個網絡一起優化,而不是使用單獨的預處理步驟進行上采樣。一開始沒有預處理或上采樣。特征提取發生在低分辨率空間中。這會導致更好的性能和更有效地使用訓練數據。
-
更好的結果:FSRCNN 已被證明在多項基準測試中優于 SRCNN,包括 PSNR 和視覺質量指標。這意味著它可以生成質量更好的超分辨率圖像,尤其是對于高放大倍數。
-
FSRCNN 最終取得了比 SRCNN 更好的結果,同時速度也更快。
7.2.2 ESPCN
ESPCN是高效的像素卷積神經網絡(Efficient Sub-Pixel CNN)的縮寫。
在圖像處理中,亞像素(Sub-Pixel)是指像素的一部分。像素是可以顯示在數字屏幕上或打印在紙上的圖像的最小單位。亞像素是用于表示像素的不同顏色分量的較小單元。
數字圖像中的每個像素都由三種顏色成分組成:紅色、綠色和藍色 (RGB)。一個亞像素代表每個顏色分量的一小部分。例如,在 RGB 圖像中,每個像素包含三個亞像素,每個亞像素對應一個顏色分量。
亞像素用于各種圖像處理技術,包括亞像素渲染和亞像素運動估計。在亞像素渲染中,亞像素用于在圖像中創建更高分辨率或更平滑邊緣的外觀。在亞像素運動估計中,亞像素通過分析相鄰亞像素之間的顏色值差異來估計視頻中對象的運動。
ESPCN技術中,亞像素卷積用于通過重新排列低分辨率圖像的通道以形成更高分辨率的圖像來提高圖像的分辨率,其中高分辨率圖像中的每個像素對應于低分辨率圖像中的一組亞像素。亞像素卷積層將低分辨率特征圖作為輸入,通過重新排列低分辨率特征圖的通道輸出高分辨率特征圖。通過以這種方式重新排列通道,亞像素卷積層能夠有效地提高圖像的分辨率,而不會引入偽影或模糊。
ESPCN 引入了亞像素卷積的概念來代替反卷積層進行上采樣。這解決了與之相關的兩個問題:
-
-
反卷積發生在高分辨率空間,因此計算成本更高。
-
它解決了反卷積中的棋盤問題,這是由于卷積的重疊操作而發生的(如下圖所示)。
-
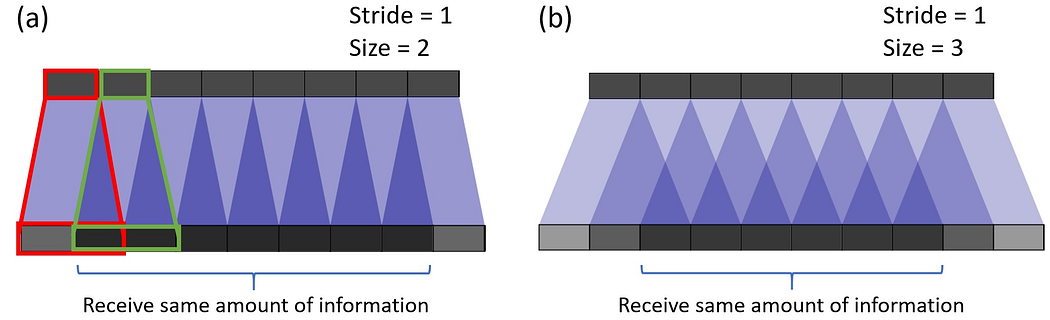
亞像素卷積通過將深度轉換為空間來工作,如下圖所示。來自低分辨率圖像中多個通道的像素被重新排列到高分辨率圖像中的單個通道。舉個例子,尺寸為 5×5×4 的輸入圖像可以將最后四個通道中的像素重新排列為一個通道,從而產生 10×10 高分辨率圖像。
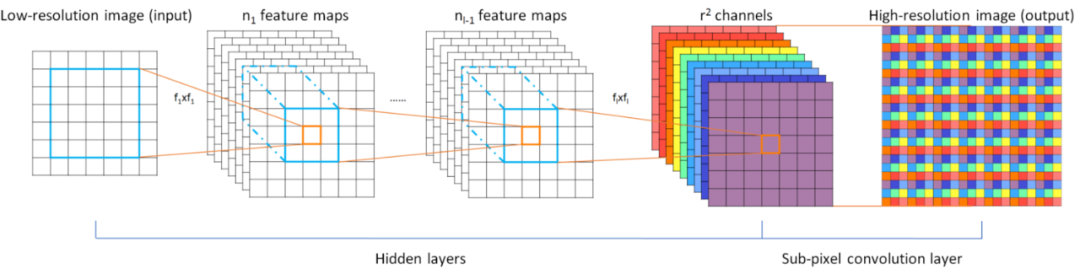
-
-
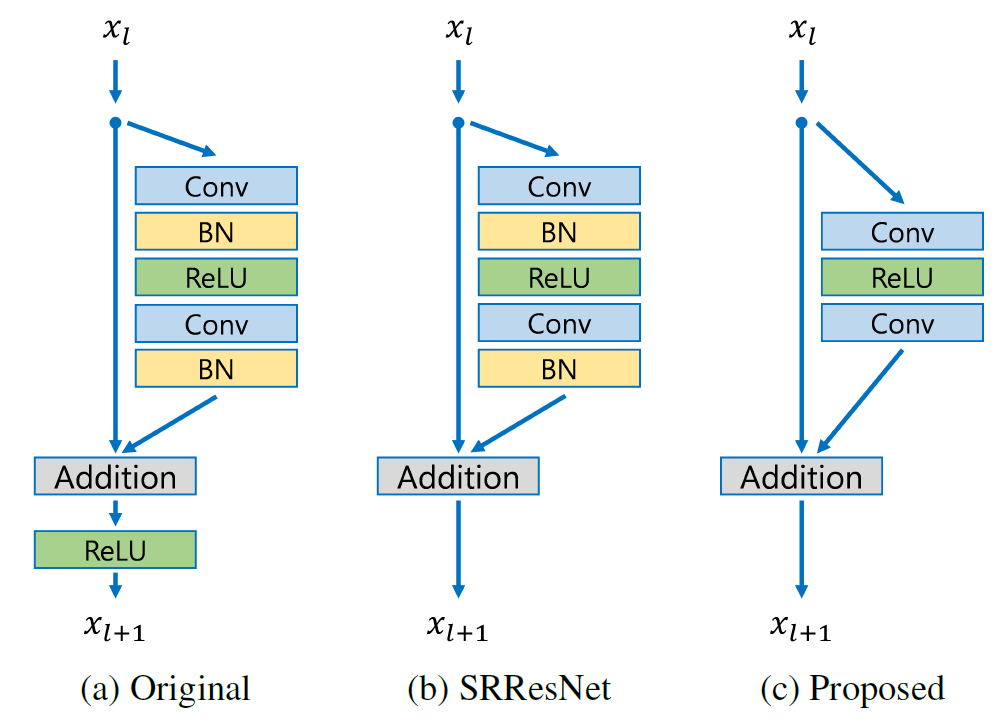
EDSR 使用比 SRResNet 更深的網絡,這使其能夠學習低分辨率和高分辨率圖像之間更復雜的映射。EDSR 還使用比 SRResNet 中使用的殘差塊計算效率更高的殘差塊,這有助于降低該方法的總體計算成本。
-
EDSR 的另一個進步是刪除批量歸一化層(Batch Normalization layers,簡稱:BN),因為批量歸一化會在超分辨率圖像中引入不需要的偽影。EDSR 使用一種稱為“均值減法”的標準化形式來標準化每一層的輸入。這有助于減少在訓練深度神經網絡時可能發生的內部協變量偏移問題,而不會引入不需要的偽影。因為去除 BN 會提高準確度,還可減少高達 40% 的內存,從而使網絡訓練更加高效。
-
EDSR 還使用一種稱為 Charbonnier 損失的新型損失函數,這是一種 L1 損失,它對異常值的敏感度低于 SRResNet 中使用的均方誤差 (MSE) 損失。這有助于減少超分辨率圖像中的偽影并獲得更高質量的結果。
-
7.3.2 MDSR
MDSR是多尺度深度超分(multi-scale deep super-resolution)的縮寫。
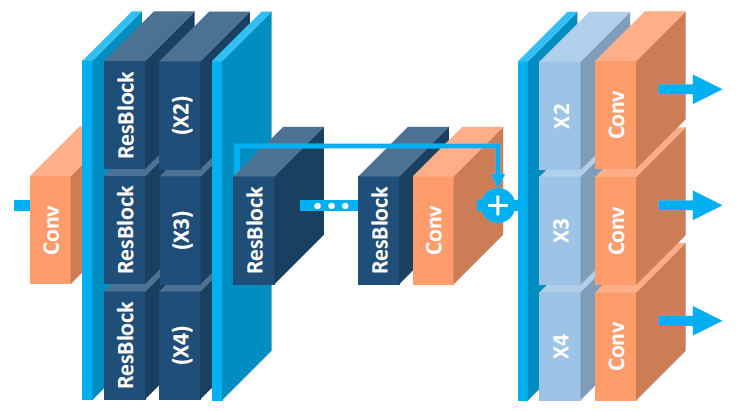
MDSR 是 EDSR 的擴展,具有多個輸入和輸出模塊,可在 2x、3x 和 4x 提供相應的分辨率輸出。一開始,存在用于特定尺度輸入的預處理模塊,由兩個具有 5×5 內核的殘差塊組成。
MDSR使用多個尺度來學習低分辨率和高分辨率圖像之間的映射。MDSR可以更有效地處理具有不同細節級別的圖像。通過使用多個子網絡,該方法可以學習對具有不同細節量的圖像的不同部分進行上采樣。這有助于保留圖像中的高頻細節并生成更高質量的超分辨率圖像。
MDSR預處理層中使用更大的內核,增加網絡感受野同時保持其淺層和計算效率。神經網絡的感受野是指網絡中每個神經元對輸入圖像敏感的區域。在超分技術領域,感受野越大越好,因為它允許網絡捕獲有關輸入圖像的更多信息并產生更高質量的高分辨率圖像。增加神經網絡感受野的一種方法是使用更大的卷積核。然而,使用更大的內核也會增加網絡中的參數數量,這會導致過度擬合和更慢的訓練時間。在多尺度深度超分辨率方法中,一種保持網絡淺層同時仍實現高感受野的方法是在網絡的預處理層中使用更大的卷積核。這些層通常在低分辨率輸入圖像上運行,并用于提取與超分辨率相關的高級特征。通過在這些層中使用更大的內核,網絡可以在不增加太多參數數量的情況下捕獲有關輸入圖像的更多信息。這有助于提高網絡性能,同時保持其計算效率。
MDSR在特定比例的預處理模塊的末尾是共享殘差塊,這是所有分辨率數據的公共塊。最后,在共享殘差塊之后是特定比例的上采樣模塊。
MDSR比 EDSR 等方法的計算效率更高。這是因為每個子網絡都被訓練為以較小的因子對輸入圖像進行上采樣,這需要更少的層和更少的參數。這可以導致更快的訓練時間和更低的計算成本。
MDSR的缺點是它們的實施和訓練比 EDSR 等方法更復雜。這是因為它們涉及訓練多個子網絡并組合它們的輸出以生成最終的超分辨率圖像。這可能需要更仔細地調整超參數和更長的訓練時間。盡管與單尺度 EDSR 相比,MDSR 的整體深度是 5 倍,但由于共享參數,參數數量僅為 2.5 倍,而不是 5 倍。MDSR 取得了與規模特定的 EDSR 相當的結果。
總的來說,多尺度深度超分辨率和EDSR都各有優缺點。方法的選擇取決于應用程序的具體要求以及可用于訓練和推理的資源。
7.3.3 CARNCARN是級聯殘差網絡(Cascading Residual Network)的縮寫。CARN在傳統殘差網絡之上提出了以下改進:
局部和全局級別的級聯機制,合并來自多個層的特征并賦予網絡接收更多信息的能力。
除了 CARN 之外,在遞歸網絡架構的幫助下,還提出了一個更小的 CARN-M,它具有更輕的架構,并且結果不會有太大的惡化。
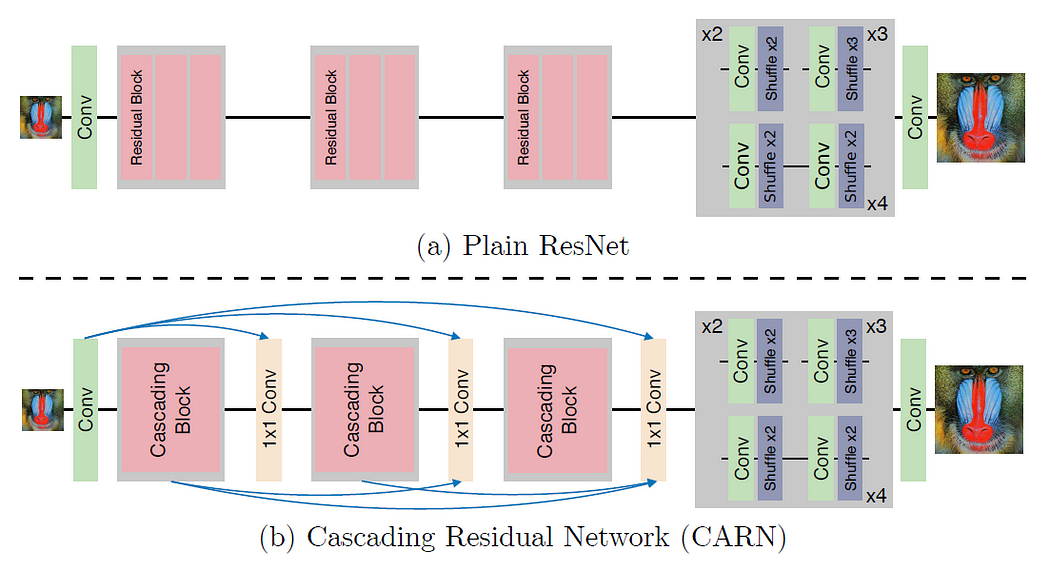
CARN 中的全局連接如上圖所示。每個具有 1×1 卷積的級聯塊的頂點接收來自所有先前級聯塊的輸入和初始輸入,從而導致信息的有效傳輸。
7.4 多階段殘差網絡多級殘差網絡(Multi-Stage Residual Networks),顧名思義,涉及使用多級或多級殘差網絡將圖像從低分辨率圖像上采樣到高分辨率圖像。
多階段殘差網絡中,低分辨率輸入圖像首先通過預處理階段,該階段通常由一組具有小感受野的卷積層組成。預處理階段的輸出然后通過一系列殘差階段,每個殘差階段包含多個殘差塊。
在每個階段,網絡學習按特定因子(例如 2 倍或 4 倍)對圖像進行上采樣。然后將每個階段的輸出傳遞到下一個階段,下一個階段通過提高分辨率進一步細化圖像。
多階段殘差網絡的一個優點是它們可以在使用相對較少的參數的同時生成高質量的超分圖像。這是因為使用殘差連接和小的卷積濾波器可以幫助提高網絡的效率。
總體而言,多級殘差網絡是一種強大且流行的超分技術,已在多個基準數據集上實現了最先進的性能。
7.4.1 BTSRN BTSRN是平衡兩階段殘差網絡(balanced two-stage residual networks)的縮寫。
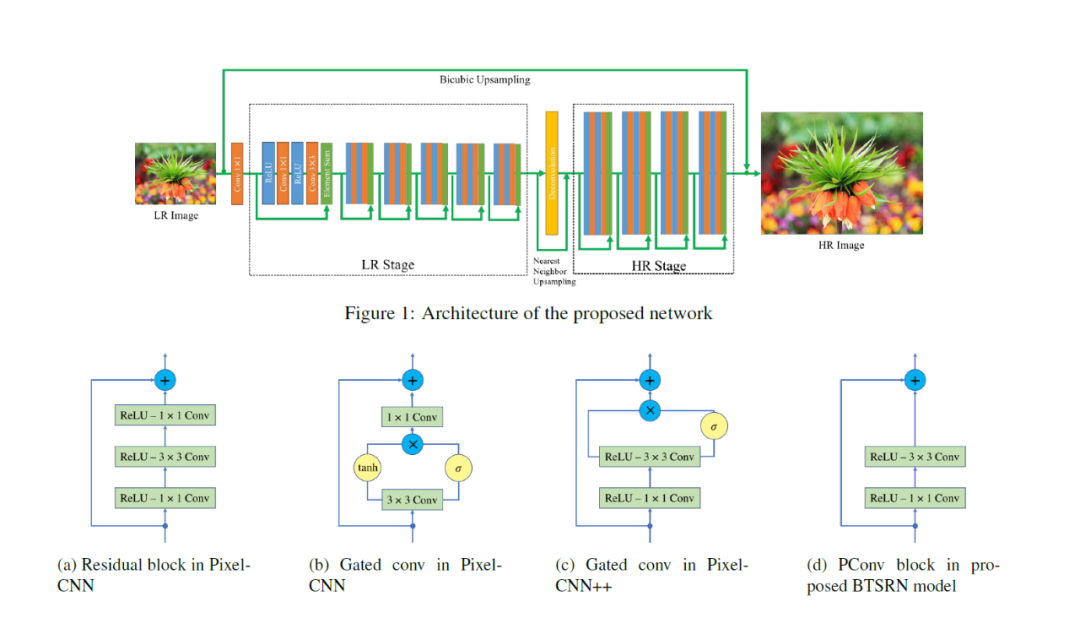
BTSRN使用兩級殘差網絡將圖像從低分辨率圖像上采樣到高分辨率圖像。與使用多個階段并增加上采樣級別的多階段殘差網絡相比,BTSRN 平衡每個階段中使用的濾波器數量以提高網絡性能。
BTSRN 的第一階段由一系列對低分辨率輸入圖像進行操作的殘差塊組成(如上圖,第一階段由 6 個殘差塊組成。)。此階段通常將輸入圖像的分辨率提高兩倍或四倍。第一階段的輸出隨后被傳遞到第二階段,第二階段進一步將圖像上采樣到所需的高分辨率輸出。
BTSRN 的第二階段使用一組相似的殘差塊,但過濾器數量與第一階段不同(如上圖,第二階段由 4 個殘差塊組成。)。每個塊中的過濾器數量是平衡的,以確保網絡能夠有效地學習低級和高級特征。
BTSRN 的一個優點是它可以在使用相對較少的參數的同時生成高質量的超分辨率圖像。通過平衡每個階段的過濾器數量,BTSRN 可以有效地學習不同尺度下輸入圖像的特征,這有助于提高網絡性能。
7.5 遞歸網絡遞歸網絡(Recursive Networks)是使用遞歸或迭代過程從低分辨率輸入生成高分辨率圖像。這種技術有時也稱為迭代超分辨率(Iterative Super-Resolution)。
遞歸網絡背后的基本思想是首先使用簡單的插值方法(例如雙三次插值)生成高分辨率圖像的初始估計。然后將該初始估計輸入深度神經網絡,該網絡通過學習提取和合并額外的高頻細節進一步完善估計。
在神經網絡的每一輪處理之后,使用另一種插值方法(例如最近鄰插值)將生成的圖像放大到所需的分辨率。然后將放大后的圖像反饋到神經網絡中進行進一步處理。這個過程會重復多次,通常是 5 到 10 輪,直到輸出圖像達到所需的分辨率。
遞歸網絡的一個優點是即使輸入圖像的分辨率非常低,它們也可以生成高質量的超分辨率圖像。這是因為網絡能夠在多個尺度上逐步細化圖像,提取低分辨率輸入中不存在的高頻細節。
然而,遞歸網絡的計算成本可能很高,尤其是在使用具有多層的深度神經網絡時。此外,該方法的迭代性質有時會導致對訓練數據的過度擬合,從而導致新圖像的泛化性能不佳。因此,需要仔細的正則化和驗證技術來確保遞歸網絡在各種不同的圖像和輸入分辨率上表現良好。
總體而言,BTSRN 是一種強大而有效的超分辨率技術,已在多個基準數據集上實現了最先進的性能。
7.5.1 DRCN DRCN是深度遞歸卷積網絡(Deeply-Recursive Convolutional Network)的縮寫。
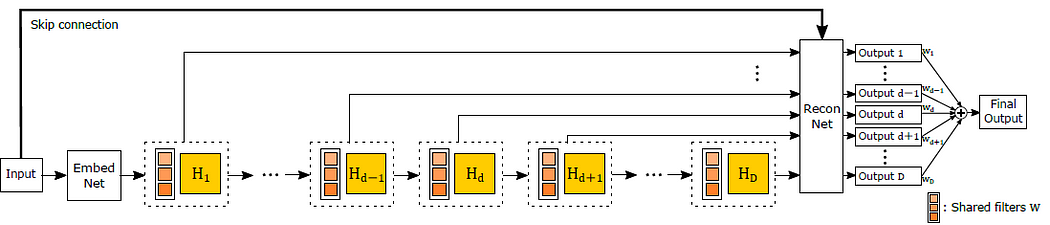
DRCN使用具有大量卷積層的非常深的神經網絡來生成高質量的超分辨率圖像。
DRCN 背后的基本思想類似于遞歸網絡,因為它使用迭代過程從低分辨率輸入中逐漸生成更詳細的圖像。然而,DRCN 不是每次迭代都使用相對較淺的神經網絡,而是使用具有多級遞歸的非常深的網絡。
DRCN 架構由兩個主要組件組成:特征提取網絡和重建網絡。特征提取網絡負責從輸入圖像中學習一組低級和高級特征。該網絡通常由多層卷積和池化操作組成,類似于典型的卷積神經網絡。
另一方面,重建網絡負責根據特征提取網絡學習的特征生成高分辨率輸出圖像。該網絡使用一系列反卷積層(也稱為轉置卷積層)將特征圖放大到所需的分辨率。
除了這兩個主要組件之外,DRCN 還在特征提取網絡的每一層和重建網絡的相應層之間加入了跳躍連接。這些跳過連接允許網絡繞過某些層并保留來自早期處理階段的重要信息。
DRCN 的一個優勢是它能夠從輸入圖像中捕獲非常復雜和高級的特征,這要歸功于其深層架構。然而,這也意味著 DRCN 的計算成本可能很高,并且需要大量的訓練數據才能獲得良好的結果。此外,跳躍連接的使用有時會導致過度擬合,因此需要仔細的正則化和驗證技術以確保良好的泛化性能。
7.5.2 DRRN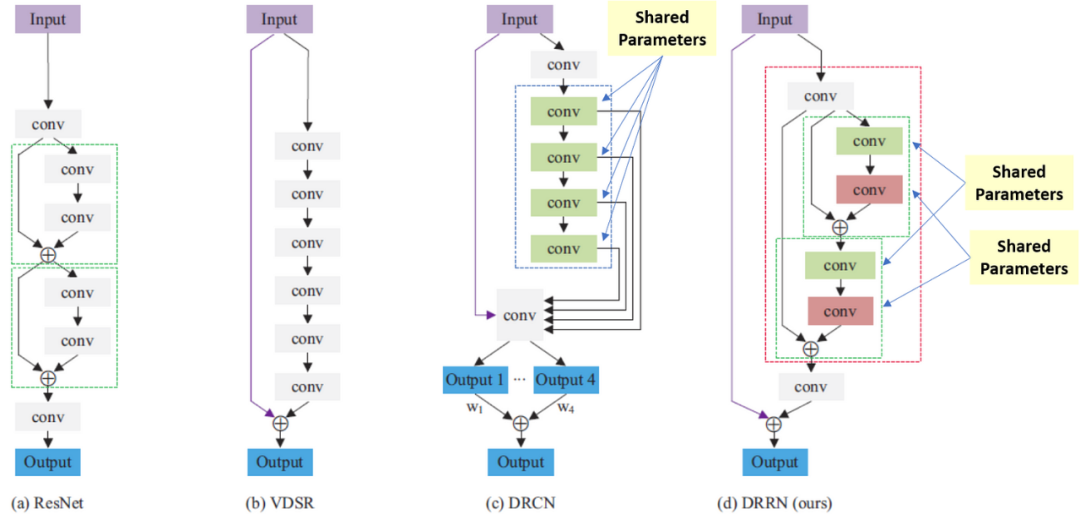 DRRN是深度遞歸殘差網絡(Deep Recursive Residual Network)的縮寫。
DRRN是深度遞歸殘差網絡(Deep Recursive Residual Network)的縮寫。DRRN建立在殘差網絡 (ResNet) 架構和遞歸網絡中使用的遞歸方法之上。
DRRN 利用一個深度神經網絡架構,該架構由幾個殘差塊組成,它們之間有跳躍連接。每個殘差塊包含多個卷積層和批量歸一化層,殘差連接將輸入直接傳遞到塊的輸出。這允許網絡學習低分辨率輸入和高分辨率輸出圖像之間的殘差或差異,然后將其添加到低分辨率輸入以生成超分辨率圖像。
DRRN 的遞歸方面來自于它使用遞歸過程來細化超分辨圖像。在每次遞歸迭代中,首先使用雙三次插值或其他簡單的上采樣方法對低分辨率輸入圖像進行放大。然后由 DRRN 網絡處理此放大圖像以生成初始超分辨率圖像。然后在下一次遞歸迭代中將這個超分辨率圖像用作網絡的輸入,進一步完善它。這個過程一直持續到達到所需的超分辨率水平。
由于使用了殘差連接和遞歸方法,DRRN 的優勢之一是它能夠使用相對較少的參數生成高質量的超分辨率圖像。此外,批歸一化層的使用有助于加快訓練速度并提高泛化性能。然而,DRRN 的計算成本仍然很高,尤其是在每個殘差塊使用大量遞歸迭代或大量卷積層時。
7.6 漸進重建網絡 漸進重建網絡(Progressive Reconstruction Networks(PRN))采用漸進方法生成高分辨率圖像。它涉及生成一系列中間圖像,每個圖像的分辨率都比前一個圖像高,直到達到所需的最終分辨率。PRN 方法包括三個主要階段:從粗到精階段、殘差學習階段和重建階段。
-
-
第一階段,使用雙三次插值或其他簡單的上采樣方法將低分辨率輸入圖像放大到中等分辨率。然后將該中間分辨率圖像用作深度神經網絡的輸入,該網絡生成分辨率稍高的輸出圖像。這個過程重復多次,每個階段的輸出用作下一個階段的輸入,直到達到最終所需的分辨率。
-
第二階段,PRN 網絡使用殘差學習方法來細化第一階段生成的中間圖像。殘差學習方法涉及學習中間圖像與其對應的高分辨率地面實況圖像之間的差異。這允許網絡學習生成低分辨率輸入圖像中不存在的高頻細節。
-
最后的重建階段,將中間圖像組合起來生成最終的高分辨率圖像。這是使用融合技術完成的,該融合技術以保留在殘差學習階段學習到的高頻細節的方式組合中間圖像。
-
PRN 的優勢之一是它能夠以相對較少的參數生成高質量圖像,這要歸功于漸進式重建和殘差學習的使用。此外,PRN 生成的中間圖像可用于其他計算機視覺任務,例如圖像修復或去噪。然而,PRN 的計算成本仍然很高,尤其是在生成高分辨率圖像時,并且可能需要大量的計算資源來訓練和部署。
7.6.1 LAPSRN
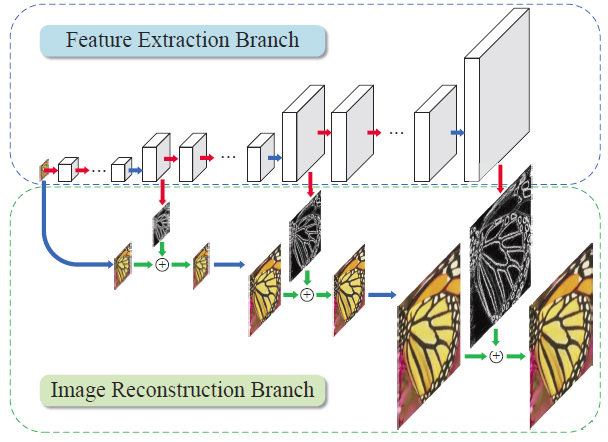
LapSRN 是拉普拉斯金字塔超分網絡(Laplacian Pyramid Super-Resolution Network)的縮寫。LapSRN通過使用一系列拉普拉斯金字塔對低分辨率圖像進行逐步上采樣來生成高分辨率圖像。拉普拉斯金字塔是一種多尺度圖像表示,可將圖像分解為一系列子帶,每個子帶包含不同級別的細節。
LapSRN 方法包括三個主要階段:特征提取階段、拉普拉斯金字塔構造階段和重建階段。
-
-
在特征提取階段,低分辨率輸入圖像由深度神經網絡處理,提取多個尺度的特征圖。然后使用這些特征圖在下一階段構建拉普拉斯金字塔。
-
在拉普拉斯金字塔構造階段,使用拉普拉斯金字塔分解將特征圖分解為一系列子帶。每個子帶代表不同的細節級別,頻率最高的子帶包含最詳細的信息。
-
在重建階段,拉普拉斯金字塔用于通過使用深度神經網絡逐步對每個子帶進行上采樣來生成高分辨率圖像。上采樣以自下而上的方式完成,最高頻率的子帶首先被上采樣,然后是較低頻率的子帶。上采樣過程是使用卷積層和像素洗牌操作的組合完成的,這允許網絡學習生成高頻細節。
-
由于使用了拉普拉斯金字塔分解,LapSRN 的優勢之一是它能夠以相對較少的參數生成高質量圖像。此外,拉普拉斯金字塔的使用允許網絡生成高頻細節,而不會引入其他超分辨率方法中常見的偽影。然而,LapSRN 的計算成本仍然很高,尤其是在生成高分辨率圖像時,并且可能需要大量的計算資源來訓練和部署。
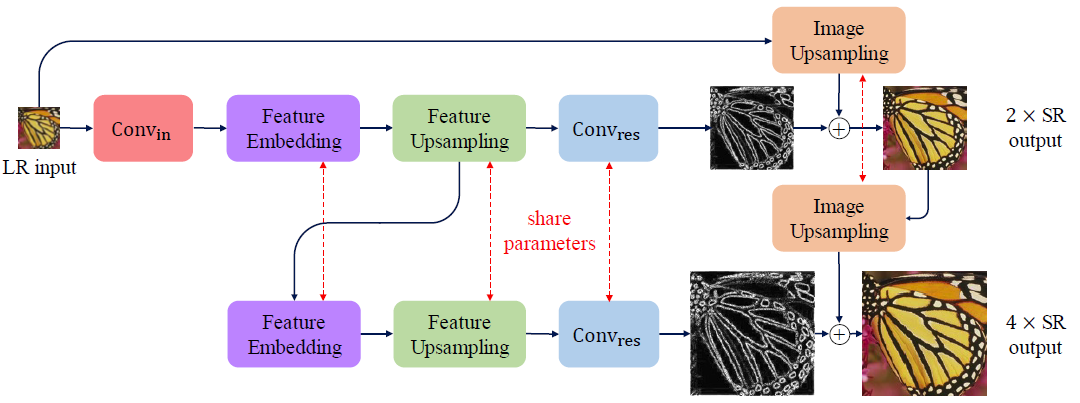
多分支網絡(Multi-branch networks),也稱為多分支卷積神經網絡,是一種具有多個分支的深度學習架構,每個分支以不同的方式處理輸入數據。每個分支由一系列卷積層組成,然后是激活函數和池化層。
每個分支中卷積層的輸出以某種方式組合,通常是將它們連接起來,然后傳遞到網絡中的下一層或分支。這允許網絡通過同時以多種方式處理輸入數據來捕獲輸入數據的不同方面。
在超分辨率任務中,多分支網絡可用于通過利用輸入圖像的不同尺度和分辨率來生成具有更精細細節的高質量圖像。例如,一個分支可以處理低分辨率的輸入圖像,而另一個分支可以處理高分辨率的圖像。然后可以組合這些分支的輸出,以生成比使用單個分支可能具有更多細節的高分辨率圖像。
多分支網絡已成功用于各種計算機視覺任務,例如對象識別、分割和檢測。多分支網絡還在超分辨率任務中生成具有改進的感知質量和精細細節的高質量圖像。然而,多分支網絡的計算成本可能很高,并且需要大量資源來訓練和部署。
7.7.1 CMSC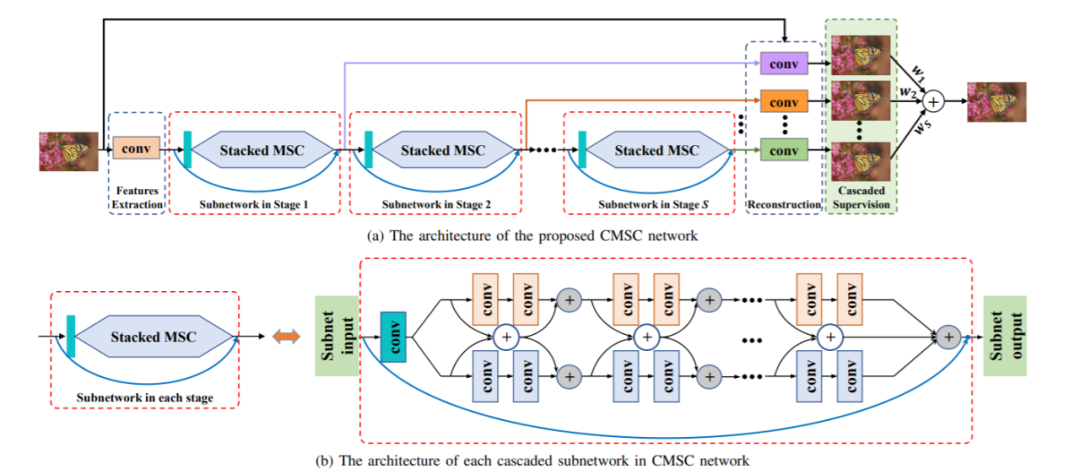 CMSC是級聯多尺度交叉網絡(Cascaded Multi-Scale Cross-Network)的縮寫。CMSC是一種利用級聯多尺度網絡生成高分辨率圖像的超分辨率方法。CMSC 由兩個主要階段組成:從粗到精階段和微調階段。
CMSC是級聯多尺度交叉網絡(Cascaded Multi-Scale Cross-Network)的縮寫。CMSC是一種利用級聯多尺度網絡生成高分辨率圖像的超分辨率方法。CMSC 由兩個主要階段組成:從粗到精階段和微調階段。-
-
在粗到精階段,輸入的低分辨率圖像首先使用雙三次插值放大 2 倍,然后由一系列多尺度網絡處理。序列中的每個網絡都設計為以不同的規模運行,并專注于圖像的不同方面。然后組合這些網絡的輸出以生成中間高分辨率圖像。
-
在微調階段,使用單尺度網絡進一步細化中間高分辨率圖像。微調網絡使用內容損失和對抗性損失的組合進行訓練,以提高生成圖像的感知質量。
-
CMSC 的關鍵特征之一是它使用跨網絡連接,它允許在網絡的不同規模和階段之間共享信息。這有助于提高網絡的準確性和穩定性,并使其能夠生成具有精細細節的高質量圖像。
CMSC 的另一個優勢是它能夠通過相應地調整網絡架構和訓練策略來處理不同的比例因子。這使其成為一種通用且適應性強的方法,可應用于廣泛的超分辨率任務。
7.8 注意力網絡注意力網絡(Attention-Based Networks)是指一系列深度學習模型,它們利用注意力機制來提高超分辨率圖像的質量。引入這些網絡是為了解決傳統超分辨率技術的局限性,傳統超分辨率技術通常使用固定且統一的濾波器來插值低分辨率圖像。基于注意力的網絡使用一組可學習的權重,這些權重可以根據圖像內容自適應地調整每個像素的濾波器系數。這使網絡能夠專注于圖像最重要的特征,并生成具有更清晰邊緣和更多細節的高質量超分辨率圖像。
基于注意力的網絡在超分辨率方面的主要優勢在于它們能夠選擇性地關注圖像中的重要特征,并生成具有更準確細節的高質量超分辨率圖像。此外,這些網絡可以處理復雜的圖像結構和圖像內容的變化,使其適用于計算機視覺中的廣泛應用,例如對象識別、圖像分類和自然語言處理。
7.8.1 SelNet
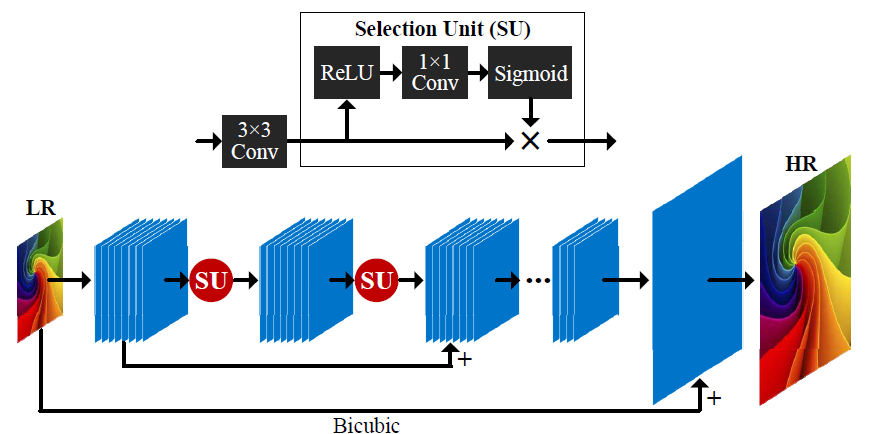
SelNet是具有注意力機制的選擇性卷積神經網絡(Selective Convolutional Neural Network with Attention Mechanism)的縮寫。SelNet是2019年提出的一種基于注意力的超分辨率網絡。SelNet旨在選擇性地強調圖像中的重要特征,同時抑制不相關的細節,使其能夠生成高分辨率的質量超分辨率圖像。
SelNet 由一系列卷積層組成,后面是一組注意力模塊,這些模塊自適應地加權特征圖中每個像素的重要性。注意模塊由一組卷積層和一個 soft-max 函數組成,該函數根據每個像素與參考特征的相似性為其分配權重。參考特征是在訓練期間學習的,代表圖像內容的學習表示。
SelNet 的關鍵優勢在于它能夠自適應地選擇和強調重要的圖像特征,同時抑制不相關的細節。這是通過注意力機制實現的,它允許網絡學習強調圖像重要區域的空間變化加權方案。
與其他基于注意力的網絡相比,SelNet 相對簡單,但可以有效生成高質量的超分辨率圖像。
7.8.2 RCAN
RCAN是剩余通道注意力網絡(Residual Channel Attention Networks)的縮寫。
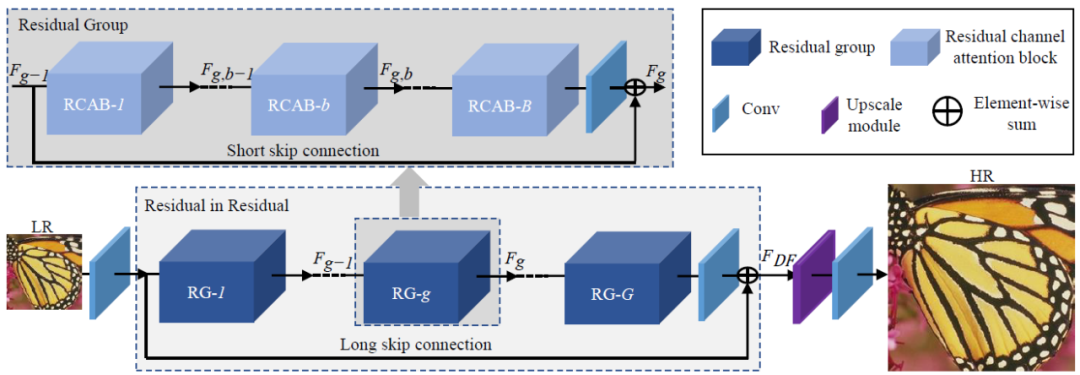
RCAN是 2018 年提出的另一種基于注意力的超分辨率網絡。RCAN 旨在通過使用通道注意力機制來增強網絡層之間剩余連接的學習。
RCAN 由一系列殘差塊組成,其中每個殘差塊包含一個卷積層,后跟一個通道注意模塊。通道注意模塊對每個殘差塊的特征圖進行操作,并根據每個通道與圖像重建任務的相關性自適應地對每個通道的重要性進行加權。
RCAN 中的通道注意力模塊包括兩個步驟:第一步計算每個通道的平均特征激活,而第二步使用一組全連接層來學習一組通道權重,放大或抑制每個通道的重要性渠道。這允許網絡有選擇地強調重要通道,同時抑制嘈雜或不相關的通道。
RCAN 的關鍵優勢在于它能夠更有效地學習網絡層之間的殘余連接。通過結合通道注意機制,RCAN 可以學習選擇性地放大或抑制每個殘差連接的重要性,從而導致更有效的信息流和更好的生成高質量超分辨率圖像的性能。
7.9 生成模型生成模型(Generative models)是指一類深度學習模型,它學習從低分辨率輸入圖像生成高分辨率圖像。這些模型通常在低分辨率和高分辨率圖像對的數據集上進行訓練,目標是學習兩者之間的映射。
超分辨率生成模型的優勢在于能夠生成訓練集中不存在的高分辨率圖像。這使得它們可用于圖像修復和具有復雜內容的圖像的超分辨率等任務。然而,它們也可能比其他超分辨率方法的計算成本更高,并且可能需要更大量的訓練數據才能獲得良好的性能。
7.9.1 SRGAN SRGAN是超分生成對抗網絡(Super-Resolution Generative Adversarial Networks)的縮寫。
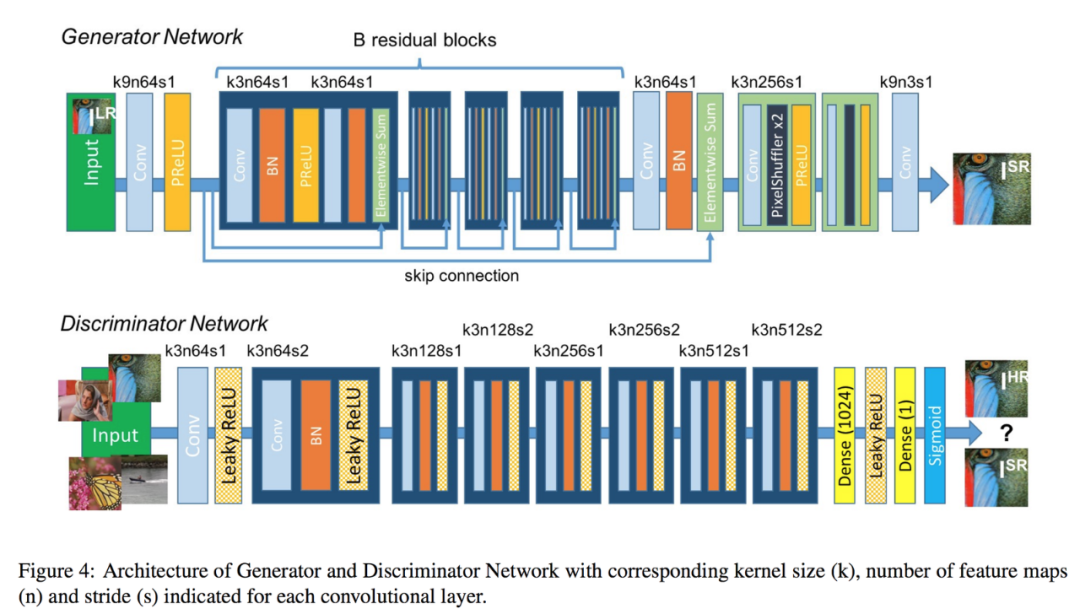
SRGAN使用生成對抗網絡 (GAN) 從低分辨率輸入圖像生成高分辨率圖像。
SRGAN 的架構由兩個網絡組成:生成器網絡和鑒別器網絡。生成器網絡接收低分辨率圖像并生成高分辨率圖像,而鑒別器網絡試圖區分生成的高分辨率圖像和真實的高分辨率圖像。這兩個網絡以對抗方式進行訓練,其中生成器嘗試生成可以欺騙鑒別器的圖像,而鑒別器則嘗試正確區分真實圖像和生成的圖像。
SRGAN 的關鍵創新是使用感知損失函數,它衡量生成的高分辨率圖像與特征空間中相應的地面真值高分辨率圖像之間的差異。具體來說,感知損失函數基于預訓練的深度神經網絡,該網絡計算網絡不同層的特征圖。通過使用感知損失函數,SRGAN 能夠生成高分辨率圖像,這些圖像不僅在視覺上與地面真實圖像相似,而且具有相似的高級特征和結構。
SRGAN 已被證明在視覺質量和定量指標(如峰值信噪比 (PSNR) 和結構相似性指數 (SSIM))方面實現了最先進的性能。它們還能夠生成具有精細細節和紋理的圖像,這對于醫學成像和衛星成像等應用非常重要。
7.9.2 EnhanceNet

EnhanceNet 使用深度神經網絡來學習低分辨率和高分辨率圖像之間的映射。它基于條件 GAN 的概念,其中生成器網絡從低分辨率輸入圖像生成高分辨率圖像,鑒別器網絡區分生成的高分辨率圖像和真實高分辨率圖像。
EnhanceNet 的架構由編碼器-解碼器網絡組成,其中編碼器網絡將輸入圖像下采樣為低分辨率特征圖,解碼器網絡將特征圖上采樣為所需的高分辨率輸出圖像。該網絡使用像素級損失和對抗性損失的組合進行訓練,其中像素級損失衡量生成的高分辨率圖像與真實高分辨率圖像之間的差異,而對抗性損失鼓勵生成器網絡生成與圖像無法區分的圖像。真正的高分辨率圖像。
EnhanceNet 的獨特之處之一是在編碼器和解碼器網絡之間使用殘差連接,這有助于在上采樣過程中保留輸入圖像的高頻細節。此外,EnhanceNet 還采用了一種感知損失函數,該函數結合了預訓練的深度卷積神經網絡(例如 VGG),以根據感知特征來衡量生成的高分辨率圖像與真實高分辨率圖像之間的相似性。
8. 本期專業術語和縮略語匯總| 縮寫 | 英文 | 中文 |
|
UHD?? |
Ultra High Definition? |
超高清視頻 |
|
HDR |
High Dynamic Range |
高動態范圍 |
|
VSR |
Video super-resolution |
視頻超分技術 |
|
LR |
Low Resolution |
低分辨率 |
|
HR |
High Resolution |
高分辨率 |
|
SISR |
Single Image Super-Resolution |
單圖像超分技術 |
|
DL |
Deep Learning |
深度學習 |
|
ANN |
Artificial neural networks |
人工神經網絡 |
|
DNN |
Deep Neural Networks |
深度神經網絡 |
|
DBN |
Deep Belief Networks |
深度置信網絡 |
|
DRN |
Deep Reinforcement Learning |
深度強化學習 |
|
RNN |
Recurrent Neural Networks |
遞歸神經網絡 |
|
CNN |
Convolutional Neural Networks |
卷積神經網絡 |
|
SKF |
Schmidt–Kalman Filter |
施密特-卡爾曼濾波器 |
|
LMS |
least mean squares |
最小平均方差 |
|
MAP |
maximum a posteriori |
最大后驗 |
|
MRF |
Markov random fields |
馬爾可夫隨機場 |
|
PSNR |
Peak Signal-to-Noise Ratio |
峰值信噪比 |
|
MSE |
Mean Square Error |
均方誤差 |
|
SSIM |
Structural SIMilarity |
結構相似性 |
|
IFC |
Information Fidelity Criterion |
信息保真度標準 |
|
VIF |
Visual Information Fidelity |
視覺信息保真度 |
|
MOVIE |
Motion-based Video Integrity Evaluation index |
基于運動的視頻完整性評估指數 |
|
VMAF |
Video Multimethod Assessment Fusion |
視頻多方法評估融合 |
|
MOS |
Mean opinion score |
平均意見得分 |
|
SRCNN |
Super-Resolution Convolutional. Neural Network |
超分卷積神經網絡 |
|
VDSR |
Very Deep Super Resolution |
非常深超分 |
|
VGG |
Visual Geometry Group |
視覺幾何組 |
|
FSRCNN |
Fast Super-Resolution Convolutional Neural Network |
快速超分卷積神經網絡 |
|
ESPCN |
Efficient Sub-Pixel CNN |
高效的像素卷積神經網絡 |
|
SP |
Sub-Pixel |
亞像素 |
|
ResNets |
Residual Networks |
殘差網絡 |
|
EDSR |
Enhanced Deep Super Resolution |
增強的深度超分 |
|
BN |
Batch Normalization layers |
批量歸一化層 |
|
MDSR |
multi-scale deep super-resolution |
多尺度深度超分 |
|
CARN |
Cascading Residual Network |
級聯殘差網絡 |
|
MSRN |
Multi-Stage Residual Networks |
多級殘差網絡 |
|
BTSRN |
balanced two-stage residual networks |
平衡兩階段殘差網絡 |
|
RN |
Recursive Networks |
遞歸網絡 |
|
ISR |
Iterative Super-Resolution |
迭代超分辨率 |
|
DRCN |
Deeply-Recursive Convolutional Network |
深度遞歸卷積網絡 |
|
DRRN |
Deep Recursive Residual Network |
深度遞歸殘差網絡 |
|
PRN |
Progressive Reconstruction Networks |
漸進重建網絡 |
|
LapSRN |
Laplacian Pyramid Super-Resolution Network |
拉普拉斯金字塔超分網絡 |
|
MBN |
Multi-branch networks |
多分支網絡 |
|
CMSC |
Cascaded Multi-Scale Cross-Network |
級聯多尺度交叉網絡 |
|
ABN |
Attention-Based Networks |
注意力網絡 |
|
SelNet |
Selective Convolutional Neural Network with Attention Mechanism |
具有注意力機制的選擇性卷積神經網絡 |
|
RCAN |
Residual Channel Attention Networks |
剩余通道注意力網絡 |
|
GM |
Generative models |
生成模型 |
|
SRGAN |
Super-Resolution Generative Adversarial Networks |
超分生成對抗網絡 |
好了,恭喜你能看到這里,說明這個萬字長文確實讓您受益了。這是迄今為止,網絡上最為詳細的介紹超分技術的文章了,整整寫了18000多字。今天,我們就先聊到這里,下一期,我們再展開談一下超高清視頻的另外一個話題:數字版權管理。
-
開源技術
+關注
關注
0文章
389瀏覽量
7914 -
OpenHarmony
+關注
關注
25文章
3661瀏覽量
16159
原文標題:河套IT TALK 67: (原創) 基于深度學習的超分技術(萬字長文)
文章出處:【微信號:開源技術服務中心,微信公眾號:共熵服務中心】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
單日獲客成本超20萬,國產大模型開卷200萬字以上的長文本處理

NPU在深度學習中的應用
AI大模型與深度學習的關系
深度學習中的時間序列分類方法
萬字長文淺談系統穩定性建設
深度學習的模型優化與調試方法
深度學習在自動駕駛中的關鍵技術
MiniMax推出“海螺AI”,支持超長文本處理
深度解析深度學習下的語義SLAM

阿里通義千問重磅升級,免費開放1000萬字長文檔處理功能
“單純靠大模型無法實現 AGI”!萬字長文看人工智能演進

詳解深度學習、神經網絡與卷積神經網絡的應用

深度學習如何訓練出好的模型






 工商網監
工商網監
評論