 Linux系統CPU 100%打滿了!
Linux系統CPU 100%打滿了!
昨天下午突然收到運維郵件報警,顯示數據平臺服務器cpu利用率達到了98.94%,而且最近一段時間一直持續在70%以上,看起來像是硬件資源到瓶頸需要擴容了,但仔細思考就會發現咱們的業務系統并不是一個高并發或者CPU密集型的應用,這個利用率有點太夸張,硬件瓶頸應該不會這么快就到了,一定是哪里的業務代碼邏輯有問題。
2、排查思路
2.1定位高負載進程pid
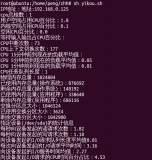
首先登錄到服務器使用top命令確認服務器的具體情況,根據具體情況再進行分析判斷。
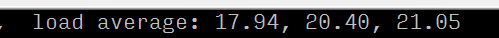
通過觀察load average,以及負載評判標準(8核),可以確認服務器存在負載較高的情況;
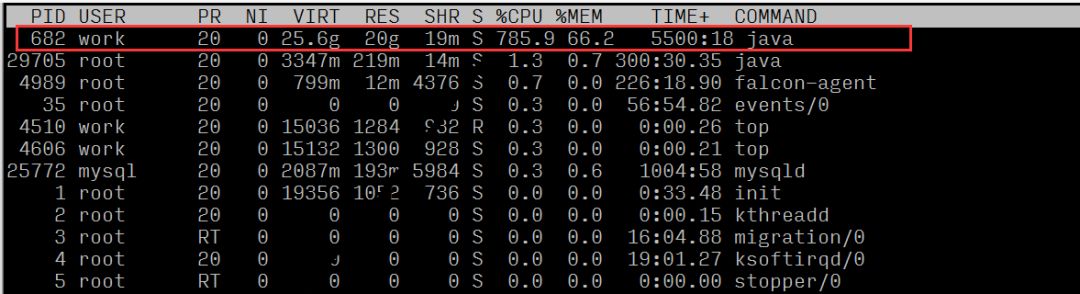
觀察各個進程資源使用情況,可以看出進程id為682的進程,有著較高的CPU占比
2.2定位具體的異常業務
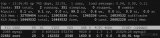
這里咱們可以使用 pwdx 命令根據 pid 找到業務進程路徑,進而定位到負責人和項目:

可得出結論:該進程對應的就是數據平臺的web服務。
2.3定位異常線程及具體代碼行
傳統的方案一般是4步:
1、top oder by with P:1040 // 首先按進程負載排序找到 maxLoad(pid)
2、top -Hp 進程PID:1073 // 找到相關負載 線程PID
3、printf “0x%x ”線程PID:0x431 // 將線程PID轉換為 16進制,為后面查找 jstack 日志做準備
4、jstack 進程PID | vim +/十六進制線程PID - // 例如:jstack 1040|vim +/0x431 -
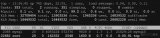
但是對于線上問題定位來說,分秒必爭,上面的 4 步還是太繁瑣耗時了,之前介紹過淘寶的oldratlee 同學就將上面的流程封裝為了一個工具:show-busy-java-threads.sh,可以很方便的定位線上的這類問題:
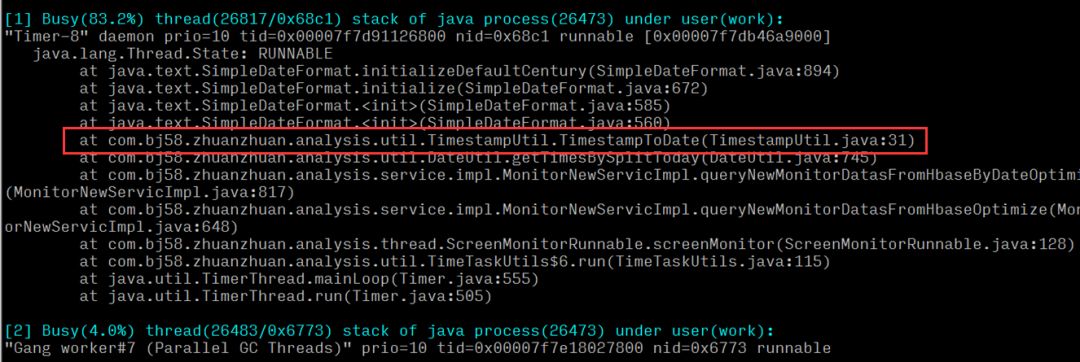
可得出結論:是系統中一個時間工具類方法的執行cpu占比較高,定位到具體方法后,查看代碼邏輯是否存在性能問題。
※如果線上問題比較緊急,可以省略 2.1、2.2 直接執行 2.3,這里從多角度剖析只是為了給大家呈現一個完整的分析思路。
3、根因分析
經過前面的分析與排查,最終定位到一個時間工具類的問題,造成了服務器負載以及cpu使用率的過高。
異常方法邏輯:是把時間戳轉成對應的具體的日期時間格式;
上層調用:計算當天凌晨至當前時間所有秒數,轉化成對應的格式放入到set中返回結果;
邏輯層:對應的是數據平臺實時報表的查詢邏輯,實時報表會按照固定的時間間隔來,并且在一次查詢中有多次(n次)方法調用。
那么可以得到結論,如果現在時間是當天上午10點,一次查詢的計算次數就是 10*60*60*n次=36,000*n次計算,而且隨著時間增長,越接近午夜單次查詢次數會線性增加。由于實時查詢、實時報警等模塊大量的查詢請求都需要多次調用該方法,導致了大量CPU資源的占用與浪費。
4、解決方案
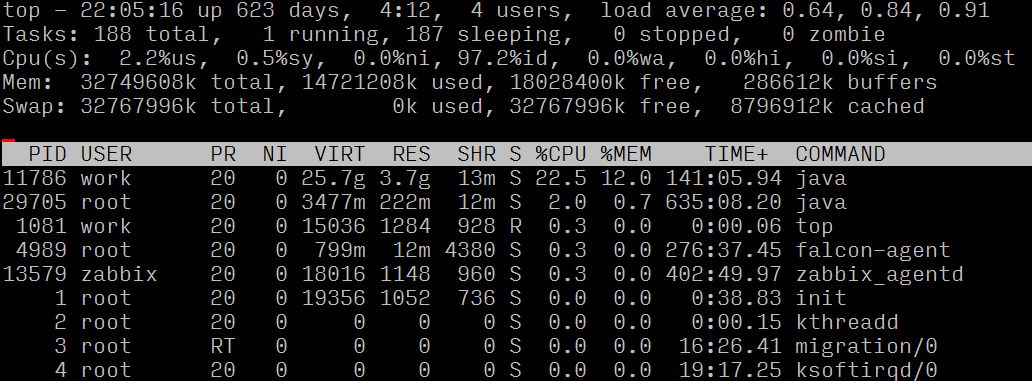
定位到問題之后,首先考慮是要減少計算次數,優化異常方法。排查后發現,在邏輯層使用時,并沒有使用該方法返回的set集合中的內容,而是簡單的用set的size數值。確認邏輯后,通過新方法簡化計算(當前秒數-當天凌晨的秒數),替換調用的方法,解決計算過多的問題。上線后觀察服務器負載和cpu使用率,對比異常時間段下降了30倍,恢復至正常狀態,至此該問題得已解決。
5、總結
在編碼的過程中,除了要實現業務的邏輯,也要注重代碼性能的優化。一個業務需求,能實現,和能實現的更高效、更優雅其實是兩種截然不同的工程師能力和境界的體現,而后者也是工程師的核心競爭力。
在代碼編寫完成之后,多做 review,多思考是不是可以用更好的方式來實現。
線上問題不放過任何一個小細節!細節是魔鬼,技術的同學需要有刨根問題的求知欲和追求卓越的精神,只有這樣,才能不斷的成長和提升。
審核編輯 :李倩
-
cpu
+關注
關注
68文章
10825瀏覽量
211149 -
服務器
+關注
關注
12文章
9021瀏覽量
85183 -
PID
+關注
關注
35文章
1471瀏覽量
85289
原文標題:我去,Linux 系統 CPU 100% 打滿了!
文章出處:【微信號:良許Linux,微信公眾號:良許Linux】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
嵌入式Linux系統CPU控制常見辦法測試
怎么在Linux系統中查看CPU信息
Linux系統CPU占用率100%的排查思路

關于系統打實時補丁,以及linux&u-boot移植方面的問題
嵌入式Linux系統驅動hp1020打印機的方法步驟
嵌入式linux磁盤被寫滿了再寫會出現什么后果
CPU占用率100%的故障解決
Linux CPU的性能應該如何優化

如何用腳本來獲取linux系統CPU、內存、磁盤IO,及原理解釋
嵌入式Linux系統驅動hp1020打印機

分享排查Linux系統CPU占用的一個Shell腳本

如何在Linux系統中檢查CPU使用率
Linux服務器CPU飆升的原因





 工商網監
工商網監
評論