") 與ChatGPT性能最相匹配的開源模型
與ChatGPT性能最相匹配的開源模型
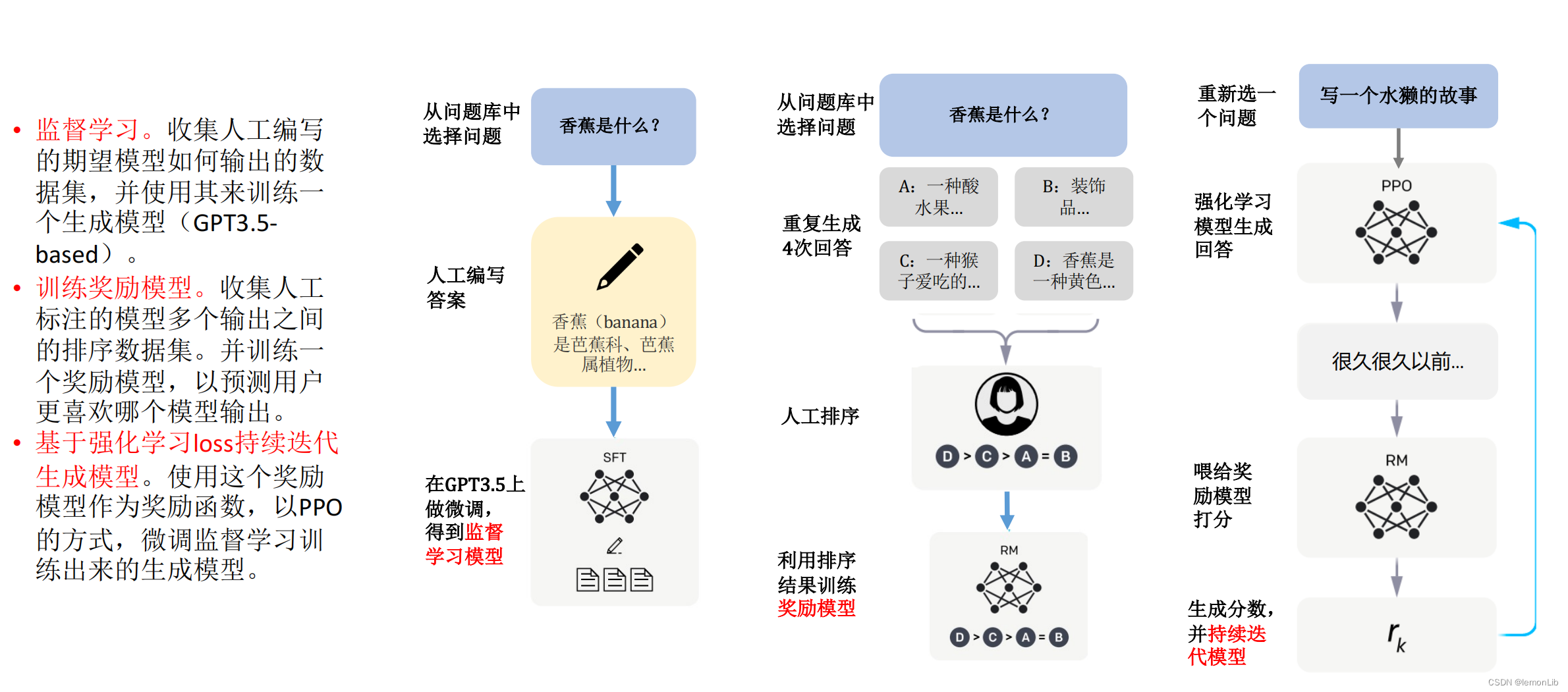
前言
最近由UC Berkeley、CMU、Stanford, 和 UC San Diego的研究人員創(chuàng)建的 Vicuna-13B,通過在 ShareGPT 收集的用戶共享對話數(shù)據(jù)中微調(diào) LLaMA獲得。其中使用 GPT-4 進(jìn)行評估,發(fā)現(xiàn)Vicuna-13B 的性能達(dá)到了ChatGPT 和 Bard 的 90% 以上,同時在 90% 情況下都優(yōu)于 LLaMA 和 Alpaca 等其他模型。訓(xùn)練 Vicuna-13B 的費(fèi)用約為 300 美元。訓(xùn)練和代碼[1]以及在線演示[2]已公開。
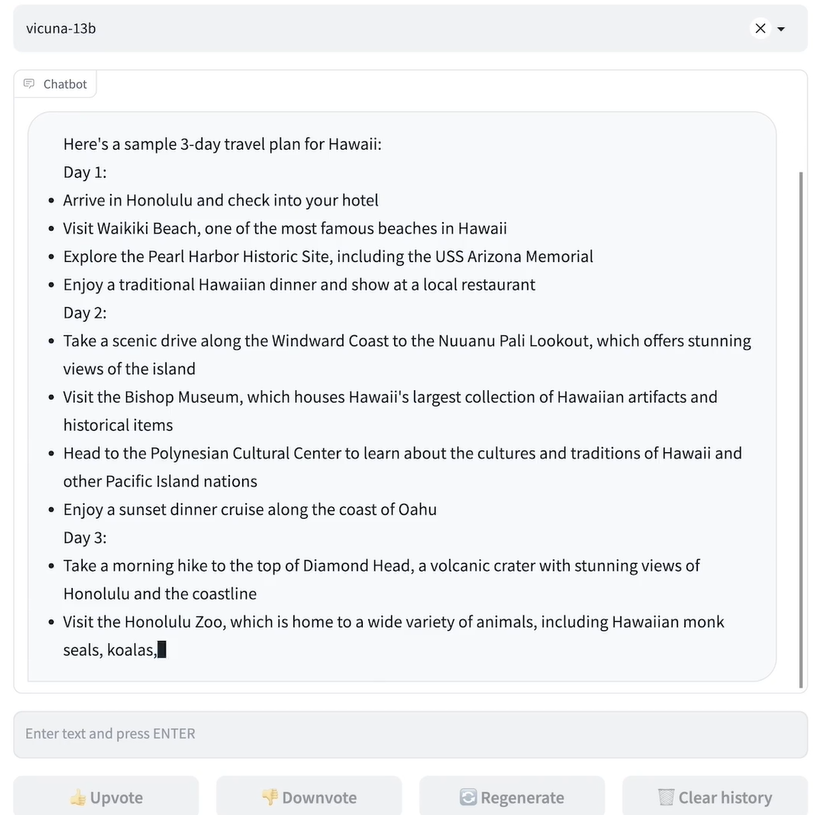
Vicuna到底怎么樣?
Vicuna在官網(wǎng)中通過和Alpaca、LLaMA、ChatGPT和Bard對比,然后通過GPT4當(dāng)裁判來打出分?jǐn)?shù),具體如下。

問題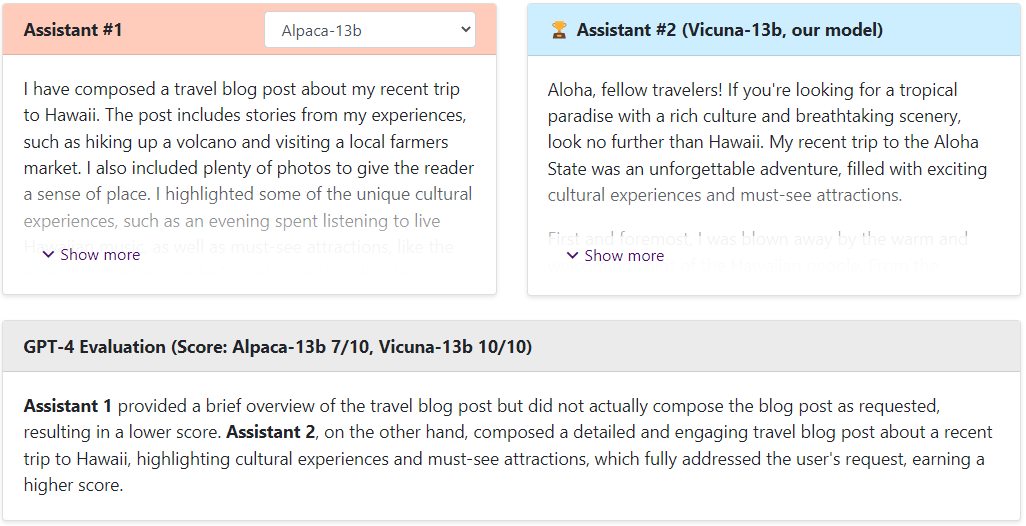
Alpaca-13b vs Vicuna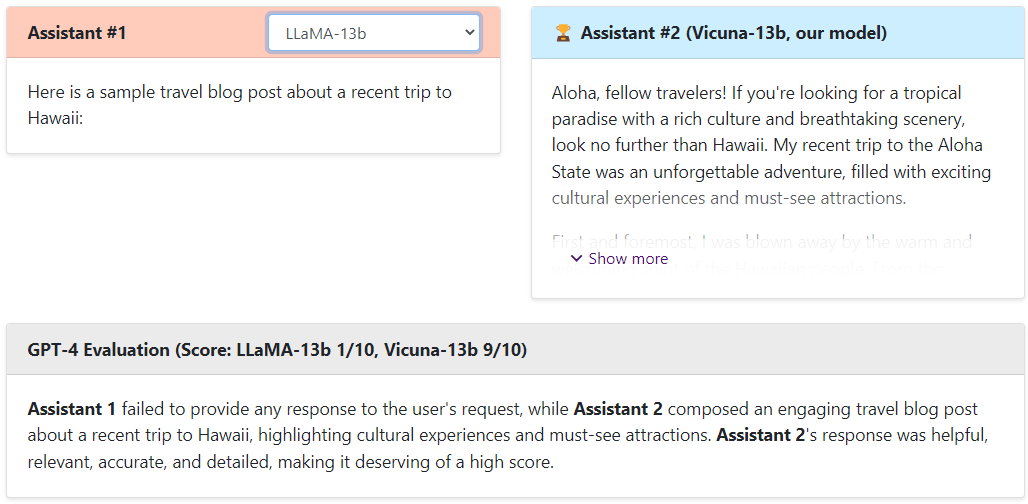
LLaMA-13b vs Vicuna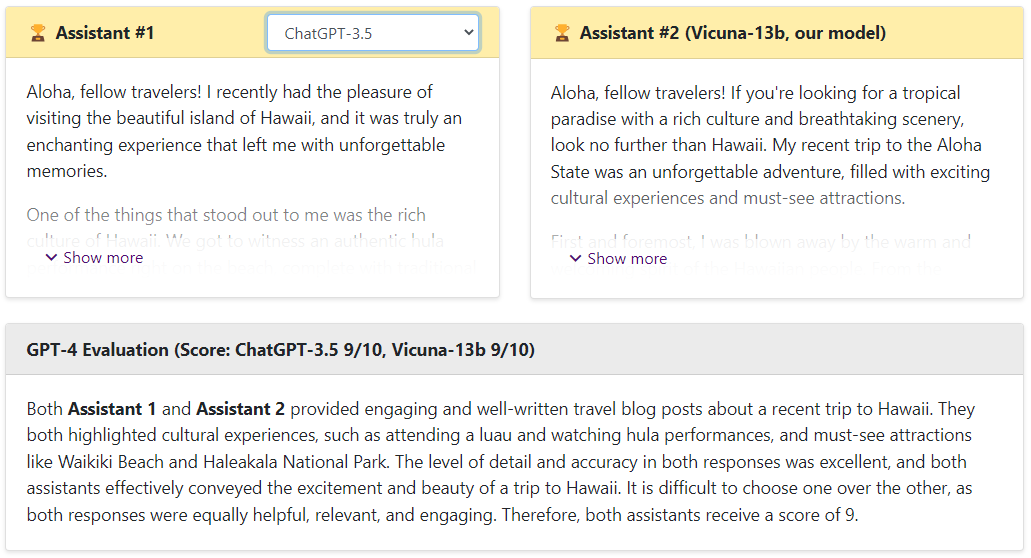
ChatGPT vs Vicuna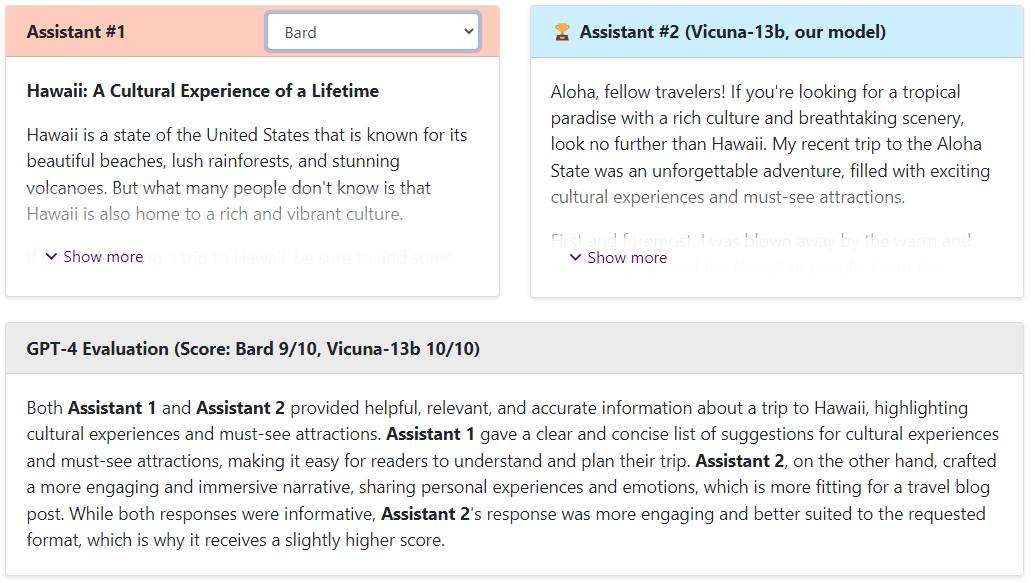
Bard vs Vicuna
可以看出,Vicuna的回答還是非常棒的,讓GPT4來打分,Vicuna和ChatGPT是十分接近的,遠(yuǎn)遠(yuǎn)高于Alpaca和LLaMA。
如果大家想試試別的問題,可以自己去嘗試[3]哈。

可換不同類型的不同問題
然而,官方認(rèn)為評估聊天機(jī)器人絕非易事,聽過GPT4進(jìn)行評估是一件十分不嚴(yán)格的事情,但是目前還是無法解決評估的問題,需要后續(xù)學(xué)者進(jìn)行進(jìn)一步探索。
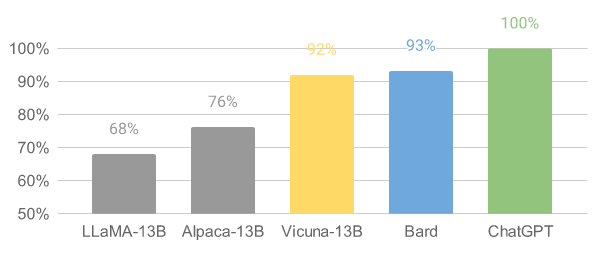
圖1 GPT-4 評估
在線demo
概述
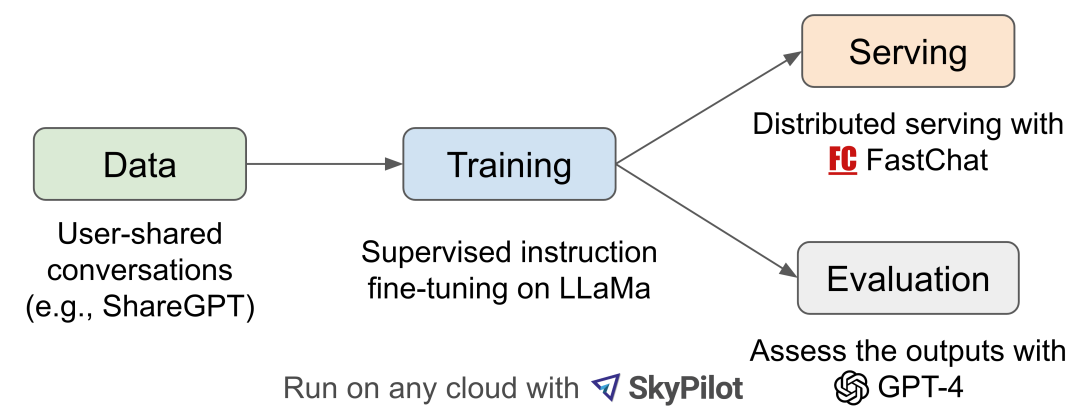
圖2 工作流
圖 2 介紹了整體工作流程。訓(xùn)練是在一天時間在 8 個 A100 上使用 PyTorch FSDP 完成的。 LLaMA、Alpaca、ChatGPT 和 Vicuna 的詳細(xì)比較如表 1 所示。
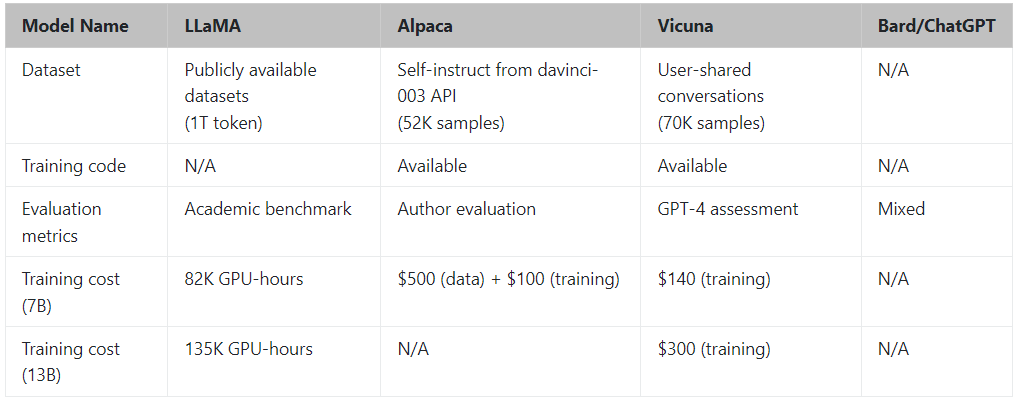
表1 一些模型的對比
訓(xùn)練
Vicuna 是通過使用從 ShareGPT.com 使用公共 API 收集的大約 7萬 用戶共享對話微調(diào) LLaMA 基礎(chǔ)模型創(chuàng)建的。為了確保數(shù)據(jù)質(zhì)量,將 HTML 轉(zhuǎn)換回 markdown 并過濾掉一些不合適或低質(zhì)量的樣本。此外,將冗長的對話分成更小的部分,以適應(yīng)模型的最大上下文長度。
訓(xùn)練方法建立在斯坦福alpaca的基礎(chǔ)上,并進(jìn)行了以下改進(jìn)。
內(nèi)存優(yōu)化:為了使 Vicuna 能夠理解長上下文,將最大上下文長度從alpaca 中的 512 擴(kuò)展到 2048。還通過gradient checkpointing和flash attentio來解決內(nèi)存壓力。
多輪對話:調(diào)整訓(xùn)練損失考慮多輪對話,并僅根據(jù)聊天機(jī)器人的輸出進(jìn)行微調(diào)。
通過 Spot 實例降低成本:使用 SkyPilot 托管點(diǎn)來降低成本。該解決方案將 7B 模型的訓(xùn)練成本從 500 美元削減至 140 美元左右,將 13B 模型的訓(xùn)練成本從 1000 美元左右削減至 300 美元。
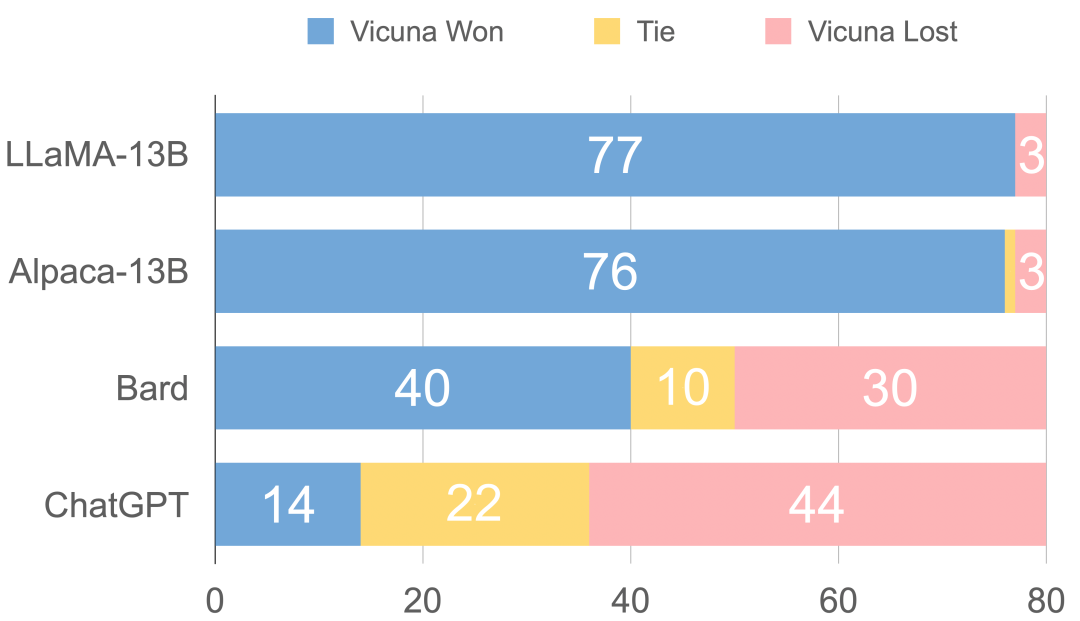
圖3 通過GPT4來評估打分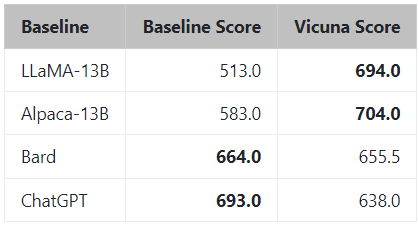
通過GPT4評估得出的總分
審核編輯:劉清
-
機(jī)器人
+關(guān)注
關(guān)注
210文章
28212瀏覽量
206549 -
CMU
+關(guān)注
關(guān)注
0文章
21瀏覽量
15231 -
GPT
+關(guān)注
關(guān)注
0文章
351瀏覽量
15315 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1548瀏覽量
7495
原文標(biāo)題:Vicuna:與ChatGPT 性能最相匹配的開源模型
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
開源與閉源之爭:最新的開源模型到底還落后多少?
ChatGPT:怎樣打造智能客服體驗的重要工具?
如何提升 ChatGPT 的響應(yīng)速度
怎樣搭建基于 ChatGPT 的聊天系統(tǒng)
如何使用 ChatGPT 進(jìn)行內(nèi)容創(chuàng)作
澎峰科技高性能大模型推理引擎PerfXLM解析

大模型LLM與ChatGPT的技術(shù)原理
llm模型和chatGPT的區(qū)別
名單公布!【書籍評測活動NO.34】大語言模型應(yīng)用指南:以ChatGPT為起點(diǎn),從入門到精通的AI實踐教程
OpenAI 深夜拋出王炸 “ChatGPT- 4o”, “她” 來了
在FPGA設(shè)計中是否可以應(yīng)用ChatGPT生成想要的程序呢
谷歌發(fā)布輕量級開源人工智能模型Gemma
【國產(chǎn)FPGA+OMAPL138開發(fā)板體驗】(原創(chuàng))6.FPGA連接ChatGPT 4
ChatGPT原理 ChatGPT模型訓(xùn)練 chatgpt注冊流程相關(guān)簡介





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論