") CPU是怎么實(shí)現(xiàn)加速的?
CPU是怎么實(shí)現(xiàn)加速的?
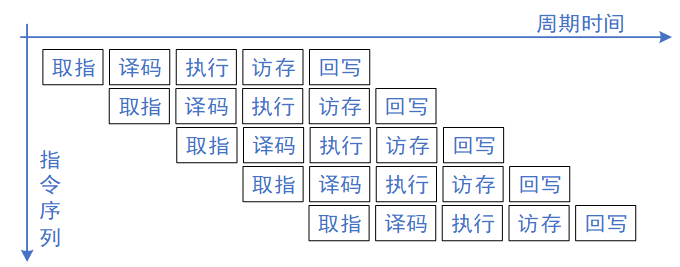
軟件在CPU上執(zhí)行,采用一定的流水線執(zhí)行指令,通常有取指(Instruction Fetch)、譯碼(Instruction Decode)、執(zhí)行(Execute)、訪存(Memory)、寫回(Write Back)這幾步操作。如下圖所示,為5個(gè)階段的順序執(zhí)行的處理器指令流,即CPU執(zhí)行指令按照流水線,有一定的先后順序,單線程同一時(shí)刻只能計(jì)算出一個(gè)結(jié)果。

那么,我們?cè)偕钊胩接懸幌翪PU的體系結(jié)構(gòu),不外乎下圖的幾種:馮.諾依曼體系結(jié)構(gòu)、哈佛體系結(jié)構(gòu)、改進(jìn)的哈佛體系結(jié)構(gòu),這幾種結(jié)構(gòu)有其各自的優(yōu)勢(shì),應(yīng)用于不同的產(chǎn)品中,也有各自的優(yōu)缺點(diǎn),其中X86最典型的馮.諾依曼結(jié)構(gòu),廣泛應(yīng)用于個(gè)人電腦、工作站、服務(wù)器等;而ARM是最典型的哈佛結(jié)構(gòu),廣泛應(yīng)用于單片機(jī)、ARM芯片等終端芯片,如手機(jī)、平板等,終端設(shè)備等。關(guān)于具體的細(xì)分,詳見下方思維導(dǎo)圖。
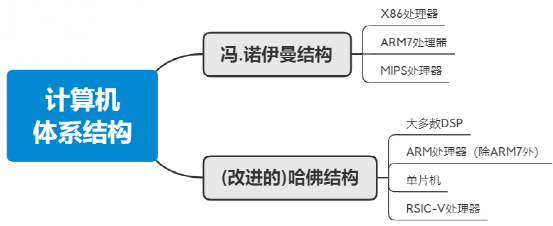
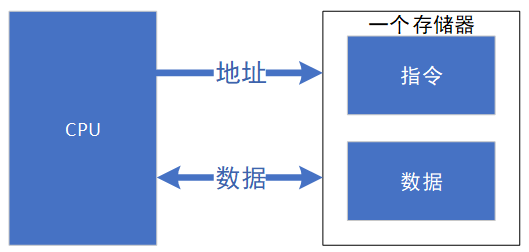
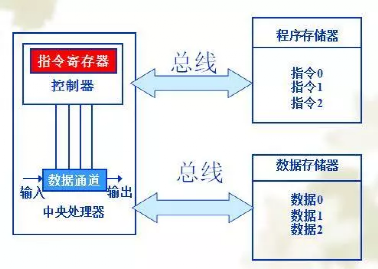
馮.諾依曼結(jié)構(gòu)(von Eeumann Architecture),也稱普林斯頓結(jié)構(gòu),如下圖所示,是一種將程序指令和數(shù)據(jù)合并在一起的存儲(chǔ)器結(jié)構(gòu)。該結(jié)構(gòu)中指令和數(shù)據(jù)共用一條總線,通過(guò)分時(shí)復(fù)用的方式進(jìn)行讀寫操作,結(jié)構(gòu)相對(duì)簡(jiǎn)單,總線面積較小,但缺點(diǎn)是效率低,無(wú)法同時(shí)取指令和數(shù)據(jù),成為了執(zhí)行的瓶頸。
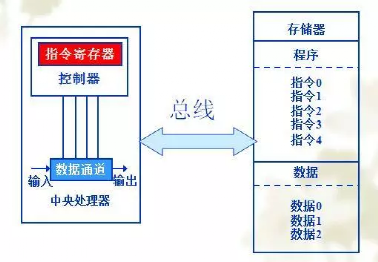
為了解決馮.諾依曼結(jié)構(gòu)無(wú)法并行取指令和數(shù)據(jù),提高計(jì)算的效率,在此基礎(chǔ)上提出了哈佛結(jié)構(gòu)(Harvard Architecture),這是一種將程序指令和數(shù)據(jù)分開的存儲(chǔ)器結(jié)構(gòu),如今下圖所示。該結(jié)構(gòu)由于程序的指令和數(shù)據(jù)存儲(chǔ)在兩個(gè)獨(dú)立的存儲(chǔ)器,各自有獨(dú)立的訪問(wèn)總線,因此提供了更大的存儲(chǔ)器帶寬,減輕了程序運(yùn)行時(shí)訪問(wèn)內(nèi)存的瓶頸。但相應(yīng)的也需要獨(dú)立的存儲(chǔ)器,以及更大的總線面積,其中ARM就是典型的哈佛結(jié)構(gòu)。
同樣采用流水線,相對(duì)于馮.諾依曼結(jié)構(gòu),哈佛結(jié)構(gòu)的指令效率更高。哈佛結(jié)構(gòu)在當(dāng)前指令譯碼的時(shí)候,可以進(jìn)行下一條指令的取指,然后在執(zhí)行下一條指令的同時(shí),又開始了第三條指令的取指。這一過(guò)程,通過(guò)指令預(yù)取,加快了原先5個(gè)步驟的流水線結(jié)構(gòu),提高了流水線的并行度。
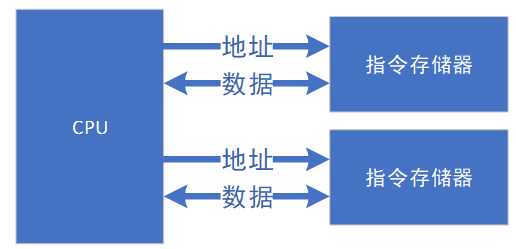
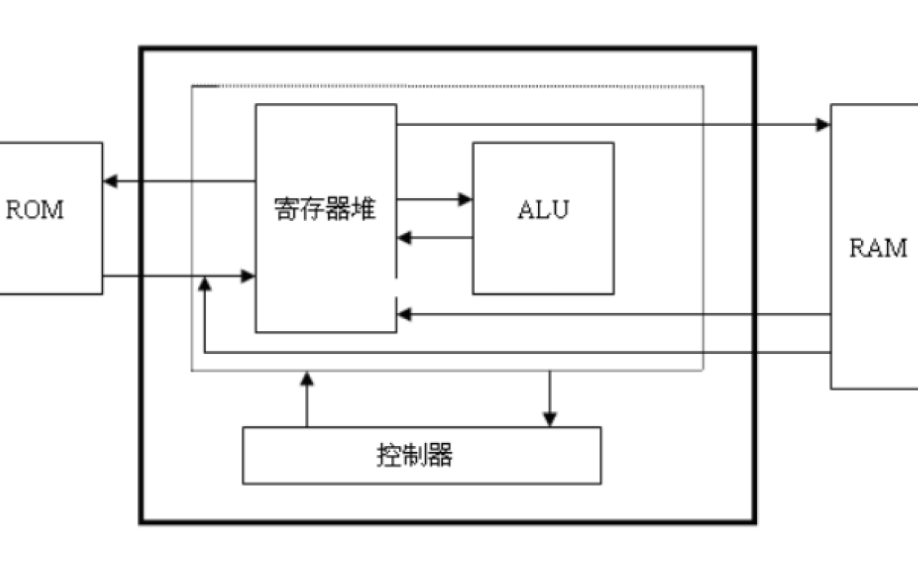
實(shí)際上計(jì)算機(jī)體系結(jié)構(gòu)發(fā)展到現(xiàn)在,馮.諾伊曼結(jié)構(gòu),和哈佛結(jié)構(gòu)的界限已經(jīng)沒(méi)有那么清晰。比如改進(jìn)型的哈佛結(jié)構(gòu),指令和數(shù)據(jù)還是一起存儲(chǔ)在主存中,但CPU有額外的指令Cache和數(shù)據(jù)Cache(如下圖所示),在主存帶寬足夠允許的前提下,使得CPU可以同時(shí)去取指令和數(shù)據(jù)Cache,所以可以認(rèn)為結(jié)構(gòu)上對(duì)外是馮.諾伊曼結(jié)構(gòu),對(duì)內(nèi)是哈佛結(jié)構(gòu),這就是改進(jìn)型的哈佛結(jié)構(gòu)。
由于本章僅在高層次上,對(duì)CPU架構(gòu)設(shè)計(jì)帶來(lái)的加速進(jìn)行基礎(chǔ)的描述,這塊就不再深入。那么,我們繼續(xù)探討,如何可以讓CPU流水線計(jì)算地更快。
1)采用更先進(jìn)的工藝
從28nm到5nm/3nm,更先進(jìn)的工藝使得允許我們可以在更高的頻率下進(jìn)行工作,當(dāng)然也意味著更高的流片成本。典型的以28nm為例,A53可以跑到1.5GHz,而在16nm工藝下,A53可以跑到2.3GHz的主頻(以上數(shù)據(jù)僅供參考,跟具體優(yōu)化有關(guān))。
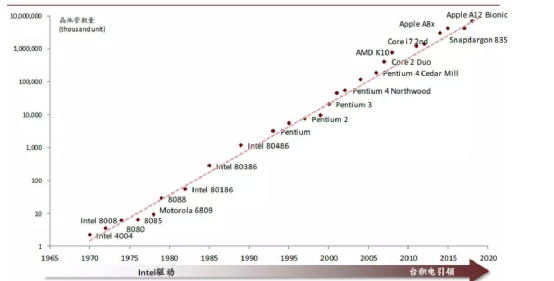
但摩爾定律的終結(jié),意味著一味地通過(guò)工藝的升級(jí)來(lái)提高主頻,變得越來(lái)越困難,除了單純的提升工藝,增加核數(shù)量,我們還得從微架構(gòu)上探索,如何跑的更快。
2)超級(jí)流水線處理器
由于時(shí)鐘頻率受流水線中計(jì)算耗時(shí)最大的的,即我們的主頻需要滿足各階段的setup/hold time,如果將每一步計(jì)算拆分為更細(xì)的顆粒度,那么我們更容易滿足setup/hold time,因而可以跑在更高的主頻下——這就是超級(jí)流水線處理器/深流水線。
如下圖所謂,為細(xì)分后的超級(jí)流水線示意圖。

3)標(biāo)量流水線處理器
用更細(xì)的計(jì)算顆粒,我們可以運(yùn)行在更高的主頻,這是提高了流水的速率。
換個(gè)思路,大力出奇跡:如果我們擁有多條河流,那我們可以成倍的提高流水的效率,這就是標(biāo)量流水線處理器,如下圖所示:
在上圖中,每條流水線執(zhí)行仍然需要5個(gè)周期,但上下兩個(gè)流水線可以重疊執(zhí)行。圖中用9個(gè)周期,完成了5條指令,但即當(dāng)流水線滿載時(shí),每個(gè)周期都可以完成一條指令,相比于單流水線,提高了5倍的效率。當(dāng)然我們擁有了5條河流來(lái)提高速率,也是付出了面積的代價(jià),即FPGA中常用的面積換速度的思維。
4)超標(biāo)量流水線處理器
結(jié)合超級(jí)流水線,以及標(biāo)量流水線的特性,也自然有了超級(jí)標(biāo)量流水線結(jié)構(gòu)的處理器,其流水結(jié)構(gòu)如下圖所示:
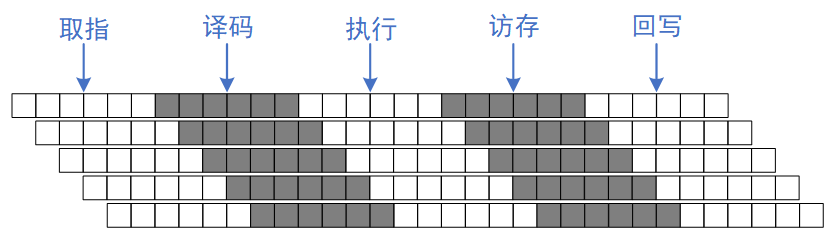
超標(biāo)量流水線處理器指令流
即采用了多條流水線的結(jié)構(gòu),增加了并行計(jì)算性能;同時(shí)通過(guò)流水線每一階段的顆粒度,提高了運(yùn)行的主頻。當(dāng)然,相對(duì)于兩個(gè)種優(yōu)化的結(jié)構(gòu),超標(biāo)量流水線結(jié)構(gòu)也是以更大的面積為代價(jià)。目前市場(chǎng)上幾乎所有處理器,都是超標(biāo)量流水處理器結(jié)構(gòu)。
5)采用多核CPU結(jié)構(gòu)
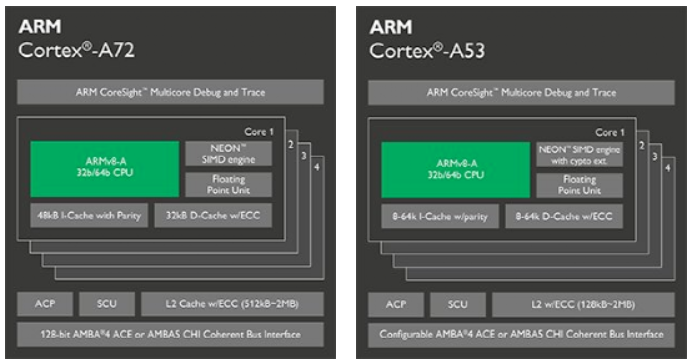
當(dāng)在確定的工藝,以及一定的超標(biāo)量流水線結(jié)構(gòu)的處理器下,單核CPU的性能很難再實(shí)現(xiàn)質(zhì)的飛躍,那么多核處理器的結(jié)構(gòu),再次通過(guò)面積換速度,成倍的提升了CPU的硬件性能。典型的以下圖為例,為***處理器中,4核A72 + 4核A53的大小核結(jié)構(gòu)。多核處理器,在進(jìn)行SOC設(shè)計(jì)時(shí),給架構(gòu)師提出了更高的挑戰(zhàn);同時(shí)在軟件應(yīng)用時(shí),也對(duì)多核并行處理提出了更高的要求,如下圖所示,為AR72/A53的多核結(jié)構(gòu)。
-
ARM
+關(guān)注
關(guān)注
134文章
9054瀏覽量
366827 -
存儲(chǔ)器
+關(guān)注
關(guān)注
38文章
7453瀏覽量
163608 -
cpu
+關(guān)注
關(guān)注
68文章
10826瀏覽量
211160 -
流水線
+關(guān)注
關(guān)注
0文章
120瀏覽量
25623 -
指令
+關(guān)注
關(guān)注
1文章
607瀏覽量
35651
原文標(biāo)題:CPU是怎么實(shí)現(xiàn)加速的?
文章出處:【微信號(hào):處芯積律,微信公眾號(hào):處芯積律】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
【FPGA干貨分享六】基于FPGA協(xié)處理器的算法加速的實(shí)現(xiàn)
為什么FPGA協(xié)處理器可以實(shí)現(xiàn)算法加速?
對(duì)步進(jìn)電機(jī)的控制,加速和減速是如何實(shí)現(xiàn)的?
CPU流水線的定義
渦輪加速升壓(Turbo-boost)充電器可為CPU渦輪加速模式提供支持

渦輪加速升壓 (Turbo-boost) 充電器可為 CPU 渦輪加速模式提供支持
Java底層實(shí)現(xiàn),CPU還有10個(gè)術(shù)語(yǔ)!
Javascript如何實(shí)現(xiàn)GPU加速?
使用FPGA實(shí)現(xiàn)CPU設(shè)計(jì)的畢業(yè)論文總結(jié)
如何使用FPGA實(shí)現(xiàn)八位RISC CPU的設(shè)計(jì)
為什么FPGA主頻比CPU慢,但卻可以用來(lái)幫CPU做加速
Intel Sapphire Rapids CPU,吹響反攻DPU的號(hào)角
基于CPCI總線CPU主控模塊的設(shè)計(jì)與實(shí)現(xiàn)

基于雙CPU的電能質(zhì)量監(jiān)測(cè)系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)
音視頻解碼器硬件加速:實(shí)現(xiàn)更流暢的播放效果






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論