") 為什么mAP已成為目標(biāo)檢測的首選指標(biāo)?
為什么mAP已成為目標(biāo)檢測的首選指標(biāo)?
計算機(jī)視覺界已經(jīng)集中在度量 mAP 上,來比較目標(biāo)檢測系統(tǒng)的性能。在這篇文章中,我們將深入了解平均精度均值 (mAP) 是如何計算的,以及為什么 mAP 已成為目標(biāo)檢測的首選指標(biāo)。
目標(biāo)檢測的快速概述
在我們考慮如何計算平均精度均值之前,我們將首先定義它正在測量的任務(wù)。目標(biāo)檢測模型試圖識別圖像中相關(guān)對象的存在,并將這些對象劃分為相關(guān)類別。例如,在醫(yī)學(xué)圖像中,我們可能希望能夠計算出血流中的紅細(xì)胞 (RBC)、白細(xì)胞 (WBC) 和血小板的數(shù)量,為了自動執(zhí)行此操作,我們需要訓(xùn)練一個對象檢測模型來識別這些對象并對其進(jìn)行正確分類。
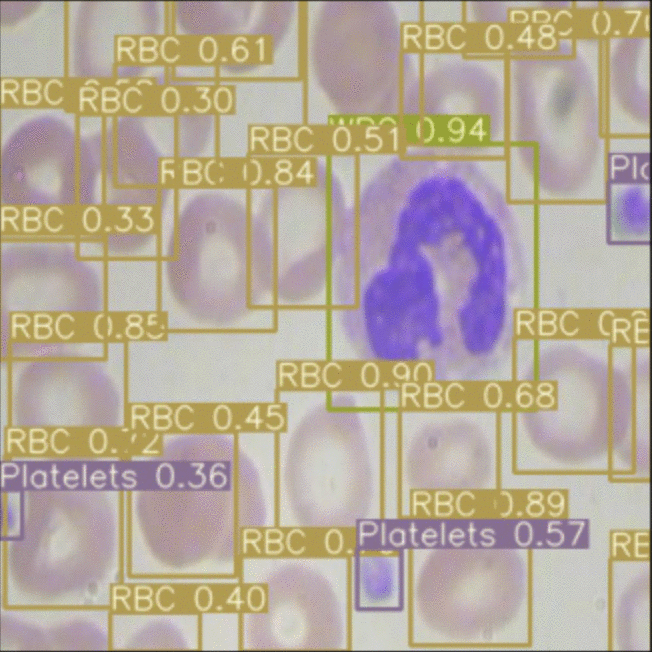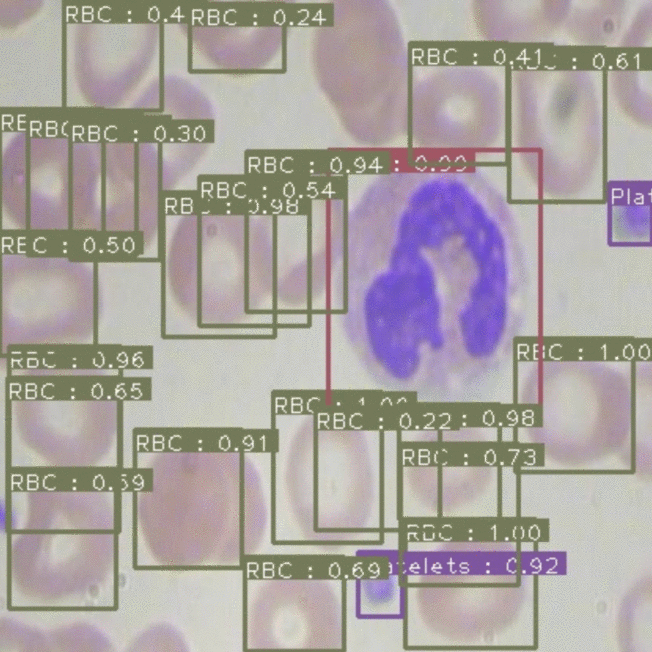
EfficientDet(綠色)與 YOLOv3(黃色)的示例輸出
這兩個模型都預(yù)測了圖片中細(xì)胞周圍的邊界框,然后他們?yōu)槊總€邊界框分配一個類。對于每個任務(wù),網(wǎng)絡(luò)都會對其預(yù)測的置信度進(jìn)行建模,可以在此處看到我們共有三個類別(RBC、WBC 和Platelets)。
我們應(yīng)該如何決定哪個模型更好?查看圖像,看起來 EfficientDet(綠色)繪制了過多的 RBC 框,并且在圖像邊緣漏掉了一些細(xì)胞。這當(dāng)然是從事物表面來看——但是我們可以相信圖像和直覺嗎?
如果我們能夠直接量化每個模型在測試集中的圖像、類和不同置信閾值下的表現(xiàn),那就太好了。要理解平均精度均值,我們必須花一些時間來研究精度-召回曲線。
精確-召回曲線
精確是“模型猜測它正確猜測的次數(shù)?” 的一個衡量標(biāo)準(zhǔn),召回是一種衡量“模型每次應(yīng)該猜到的時候都猜到了嗎?” 。假設(shè)一個具有有 10 個紅細(xì)胞的圖像,模型只找到這 10 個中正確標(biāo)記的一個,因為“RBC”具有完美的精度(因為它做出的每一個猜測都是正確的),但并不同時具有完美的召回(僅發(fā)現(xiàn)十個 RBC 細(xì)胞中的一個)。
包含置信元素的模型可以通過調(diào)整進(jìn)行預(yù)測所需的置信水平來權(quán)衡召回的精確度。也就是,如果模型處于避免假陽性(當(dāng)細(xì)胞是白細(xì)胞時說明存在紅細(xì)胞)比避免假陰性更重要的情況下,它可以將其置信閾值設(shè)置得更高,以鼓勵模型只產(chǎn)生以降低其覆蓋率(召回)為代價的高精度預(yù)測。
精度-召回曲線是繪制模型精度和以召回率作為模型置信閾值函數(shù)的過程。它是向下傾斜的,因為隨著置信度的降低,會做出更多的預(yù)測,進(jìn)而預(yù)測的準(zhǔn)確性會降低(影像精確度)。
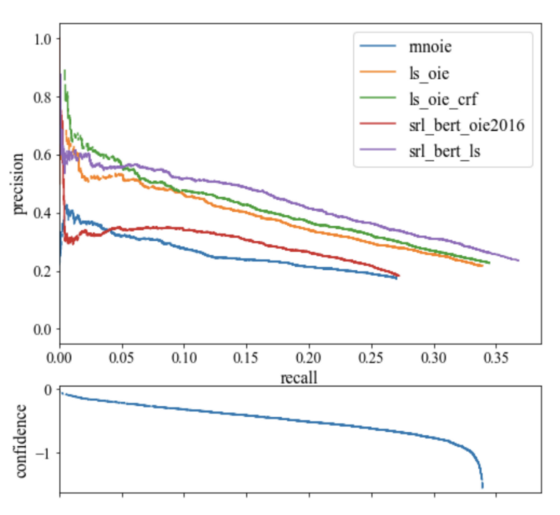
一個 NLP 項目中不同模型的精度、召回率和置信度
隨著模型越來越不穩(wěn)定,曲線向下傾斜,如果模型具有向上傾斜的精度和召回曲線,則該模型的置信度估計可能存在問題。
人工智能研究人員偏向于指標(biāo),并且可以在單個指標(biāo)中捕獲整個精確召回曲線。第一個也是最常見的是 F1,它結(jié)合了精度和召回措施,以找到最佳置信度閾值,其中精度和召回率產(chǎn)生最高的 F1 值。接下來是 AUC(曲線下面積),它集成了精確性和召回曲線下的繪圖量。
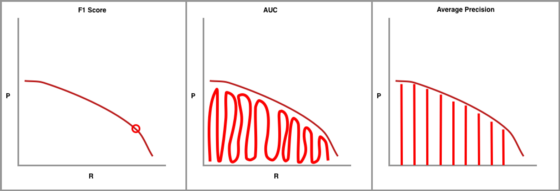
精確召回匯總指標(biāo)圖
最終的精確-召回曲線指標(biāo)是平均精度 (AP),它被計算為在每個閾值處實現(xiàn)的精度的加權(quán)平均值,并將前一個閾值的召回率增加用作權(quán)重。
AUC 和 AP 都捕獲了精確-召回曲線的整個形狀,選擇一個或另一個進(jìn)行目標(biāo)檢測是一個選擇問題,研究界已經(jīng)將注意力集中在AP 的可解釋性上。
通過并集上的交點測量正確性
目標(biāo)檢測系統(tǒng)根據(jù)邊界框和類標(biāo)簽進(jìn)行預(yù)測。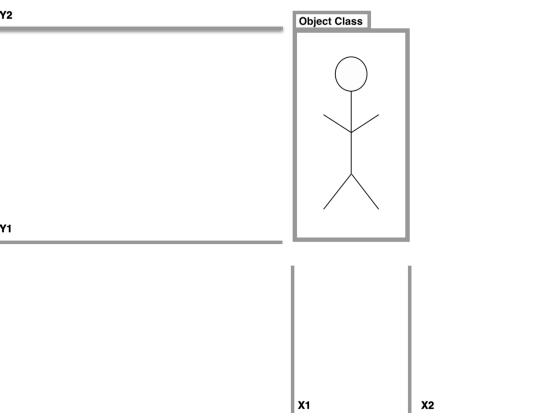
真正的目標(biāo)檢測圖
在實踐中,X1、X2、Y1、Y2 坐標(biāo)中預(yù)測的邊界框肯定會偏離地面真實標(biāo)簽(即使稍微偏離)。我們知道如果邊界框預(yù)測是錯誤的類,我們應(yīng)該將其視為不正確的,但是我們應(yīng)該在哪里繪制邊界框重疊的線?
Intersection over Union (IoU) 提供了一個度量來設(shè)置這個邊界,與地面真實邊界框重疊的預(yù)測邊界框的數(shù)量除以兩個邊界框的總面積。
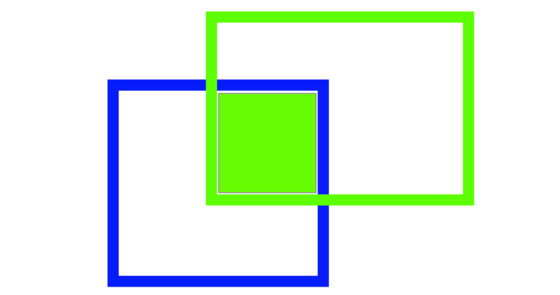 ?
?
真正對 IoU 指標(biāo)的圖形描述。
為 IoU 指標(biāo)選擇正確的單個閾值似乎是任意的,一位研究人員可能會證明 60% 的重疊是合理的,而另一位則認(rèn)為 75% 似乎更合理,那么為什么不在一個指標(biāo)中考慮所有閾值呢?
繪制mAP精度-召回曲線
為了計算 mAP,我們繪制了一系列具有不同難度級別的 IoU 閾值的精確-召回曲線。
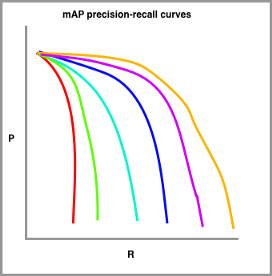
我們真正繪制的 mAP 精確召回曲線圖
在上圖中,紅色繪制的是對 IoU 的最高要求(可能是 90%),橙色線繪制的是對 IoU 的最低要求(可能是 10%),要繪制的線數(shù)通常由挑戰(zhàn)設(shè)置。例如,COCO 挑戰(zhàn)設(shè)置了十個不同的 IoU 閾值,從 0.5 開始,以 0.05 的步長增加到 0.95。
最后,我們?yōu)榘搭愋蛣澐值臄?shù)據(jù)集繪制這些精度-召回曲線。
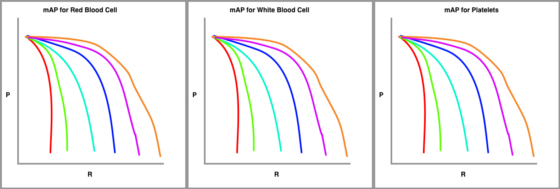
由我們真正按對象類別劃分的 mAP 圖
該指標(biāo)在所有 IoU 閾值上單獨計算每個類的平均精度 (AP),然后該指標(biāo)對所有類別的 mAP 進(jìn)行平均以得出最終估計值。
在實驗中使用平均精度均值(mAP)
我最近在一篇文章中使用了mAP,比較了最先進(jìn)的EfficientDet和YOLOv3檢測模型,我想看看哪個模型在識別血液中的細(xì)胞表現(xiàn)更好。
在對測試集中的每個圖像進(jìn)行推理后,我導(dǎo)入了一個 python 包來計算Colab筆記本中的mAP,結(jié)果如下!
EfficientDet 對細(xì)胞物體檢測的評價:
78.59% = Platelets AP 77.87% = RBC AP 96.47% = WBC AP mAP = 84.31%
YOLOv3對細(xì)胞物體檢測的評價:
72.15% = Platelets AP 74.41% = RBC AP 95.54% = WBC AP mAP = 80.70%
因此,與本文開頭的單一推斷圖片相反,事實證明EfficientDet在建模細(xì)胞目標(biāo)檢測方面做得更好!我們還將注意該指標(biāo)是按對象類劃分的,這告訴我們,白細(xì)胞比血小板和紅細(xì)胞更容易檢測,這是有道理的,因為它們比其他細(xì)胞大得多,并且不同。
地圖也經(jīng)常被分成小、中、大對象,這有助于識別模型(和/或數(shù)據(jù)集)可能出現(xiàn)錯誤的地方。
審核編輯:劉清
-
MAP
+關(guān)注
關(guān)注
0文章
49瀏覽量
15129 -
計算機(jī)視覺
+關(guān)注
關(guān)注
8文章
1696瀏覽量
45930 -
AUC
+關(guān)注
關(guān)注
0文章
9瀏覽量
6654 -
nlp
+關(guān)注
關(guān)注
1文章
487瀏覽量
22015
原文標(biāo)題:什么是目標(biāo)檢測中的平均精度均值(mAP)?
文章出處:【微信號:vision263com,微信公眾號:新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
電子信息產(chǎn)業(yè)已成為我國的國民經(jīng)濟(jì)支柱產(chǎn)業(yè)
公眾WiFi服務(wù)已成為商家的“標(biāo)配”
雷達(dá)回波發(fā)生器的主要技術(shù)指標(biāo)有什么?
一種基于Kalman濾波器的運動目標(biāo)檢測和跟蹤算法
Alignment已成為Inphi公司在中國的授權(quán)廠家代表
區(qū)塊鏈技術(shù)已成為電商的新風(fēng)口
FLIR紅外熱像儀已成為火山研究者檢測和分析火山熱活動不可或缺的工具
無線電技術(shù)已成為信息通信技術(shù)中的創(chuàng)新活力和發(fā)展?jié)摿?/a>
中國移動已成為全球5G發(fā)展的核心力量
海信75L9S激光電視成銷冠 激光電視已成為消費者的大屏首選
VPN已成為了攻擊入口,安全訪問該何去何從
日經(jīng)亞洲:中國已成為新興技術(shù)制定國際規(guī)則的核心參與者
WSL中運行Linux GUI應(yīng)用已成為現(xiàn)實
天翼云領(lǐng)跑政務(wù)云駛?cè)肟燔嚨溃毺貎?yōu)勢成為政府上云首選
- 設(shè)計技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測量儀表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動
- 處理器/DSP
- EDA/IC設(shè)計
- 存儲技術(shù)
- 光電顯示
- EMC/EMI設(shè)計
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計資源
- 設(shè)計技術(shù)
- 電子百科
- 電子視頻
- 元器件知識
- 工具箱
- VIP會員
- 最新技術(shù)文章
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會
- 活動策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測驗
- 設(shè)計大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟(jì)技術(shù)開發(fā)區(qū)航空路6號手機(jī)智能終端產(chǎn)業(yè)園2號廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
評論