 什么是業務補償?業務補償設計的實現方式
什么是業務補償?業務補償設計的實現方式
我們知道,應用系統在分布式的情況下,在通信時會有著一個顯著的問題,即一個業務流程往往需要組合一組服務,且單單一次通信可能會經過 DNS 服務,網卡、交換機、路由器、負載均衡等設備,而這些服務于設備都不一定是一直穩定的,在數據傳輸的整個過程中,只要任意一個環節出錯,都會導致問題的產生。
這樣的事情在微服務下就更為明顯了,因為業務需要在一致性上的保證。也就是說,如果一個步驟失敗了,要么不斷重試保證所有的步驟都成功,要么回滾到以前的服務調用。
因此我們可以對業務補償的過程進行一個定義,即當某個操作發生了異常時,如何通過內部機制將這個異常產生的「不一致」狀態消除掉。
一、關于業務補償機制
1、什么是業務補償
我們知道,應用系統在分布式的情況下,在通信時會有著一個顯著的問題,即一個業務流程往往需要組合一組服務,且單單一次通信可能會經過 DNS 服務,網卡、交換機、路由器、負載均衡等設備,而這些服務于設備都不一定是一直穩定的,在數據傳輸的整個過程中,只要任意一個環節出錯,都會導致問題的產生。
這樣的事情在微服務下就更為明顯了,因為業務需要在一致性上的保證。也就是說,如果一個步驟失敗了,要么不斷重試保證所有的步驟都成功,要么回滾到以前的服務調用。
因此我們可以對業務補償的過程進行一個定義,即當某個操作發生了異常時,如何通過內部機制將這個異常產生的「不一致」狀態消除掉。
2、業務補償設計的實現方式
業務補償設計的實現方式主要可分為兩種:
回滾(事務補償) ,逆向操作,回滾業務流程,意味著放棄,當前操作必然會失敗;
重試 ,正向操作,努力地把一個業務流程執行完成,代表著還有成功的機會。
一般來說,業務的事務補償都是需要一個工作流引擎的。這個工作流引擎把各式各樣的服務給串聯在一起,并在工作流上做相應的業務補償,整個過程設計成為最終一致性的。
Ps:因為「補償」已經是一個額外流程了,既然能夠走這個額外流程,說明時效性并不是第一考慮的因素。所以做補償的核心要點是:寧可慢,不可錯。
二、關于回滾
“回滾” 是指當程序或數據出錯時,將程序或數據恢復到最近的一個正確版本的行為。在分布式業務補償設計到的回滾則是通過事務補償的方式,回到服務調用以前的狀態。
1、顯示回滾
回滾一般可分為 2 種模式:
顯式回滾 ;調用逆向接口,進行上一次操作的反操作,或者取消上一次還沒有完成的操作(須鎖定資源);
隱式回滾 :隱式回滾意味著這個回滾動作你不需要進行額外處理,往往是由下游提供了失敗處理機制的。
最常見的就是「顯式回滾」。這個方案無非就是做 2 個事情:
首先要確定失敗的步驟和狀態,從而確定需要回滾的范圍。一個業務的流程,往往在設計之初就制定好了,所以確定回滾的范圍比較容易。但這里唯一需要注意的一點就是:如果在一個業務處理中涉及到的服務并不是都提供了「回滾接口」,那么在編排服務時應該把提供「回滾接口」的服務放在前面,這樣當后面的工作服務錯誤時還有機會「回滾」。
其次要能提供「回滾」操作使用到的業務數據。「回滾」時提供的數據越多,越有益于程序的健壯性。因為程序可以在收到「回滾」操作的時候可以做業務的檢查,比如檢查賬戶是否相等,金額是否一致等等。
2、回滾的實現方式
對于跨庫的事務,比較常見的解決方案有:兩階段提交、三階段提交(ACID)但是這 2 種方式,在高可用的架構中一般都不可取,因為跨庫鎖表會消耗很大的性能。
高可用的架構中一般不會要求強一致性,只要達到最終的一致性就可以了。可以考慮:事務表、消息隊列、補償機制、TCC 模式(占位 / 確認或取消)、Sagas模式(拆分事務 + 補償機制)來實現最終的一致性。
三、關于重試
“重試” 的語義是我們認為這個故障是暫時的,而不是永久的,所以,我們會去重試。這個操作最大的好處就是不需要提供額外的逆向接口。這對于代碼的維護和長期開發的成本有優勢,而且業務是變化的。逆向接口也需要變化。所以更多時候可以考慮重試。
1、重試的使用場景
相較于回滾,重試使用的場景要少一些:下游系統返回請求超時,被限流中等臨時狀態的時候,我們就可以考慮重試了。而如果是返回余額不足,無權限的明確業務錯誤,就不需要重試。一些中間件或者 RPC 框架,返回 503,404 這種沒有預期恢復時間的錯誤,也不需要重試了。
2、重試策略
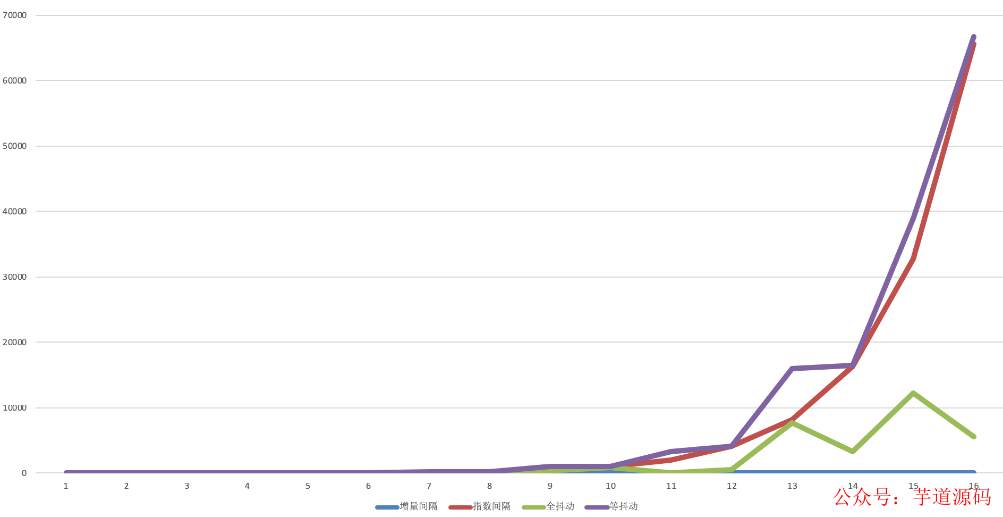
重試的時間和重試的次數。這種在不同的情況下要有不同的考量,主流的重試策略主要是以下幾種:
策略 1 - 立即重試 :有時候故障是暫時性的,可能因為網絡數據包沖突或者硬件組件高峰流量等事件造成的,在這種情況下,適合立即重試的操作。不過立即重試的操作不應該超過一次,如果立即重試失敗,應該改用其他策略;
策略 2 - 固定間隔 :這個很好理解,比如每隔 5 分鐘重試一次。PS:策略 1 和策略 2 多用于前端系統的交互操作中;
策略 3 - 增量間隔 :每一次的重試間隔時間增量遞增。比如,第一次 0 秒、第二次 5 秒、第三次 10 秒這樣,使得失敗次數越多的重試請求優先級排到越后面,給新進入的重試請求讓路;
return(retryCount-1)*incrementInterval;
策略 4 - 指數間隔: 每一次的重試間隔呈指數級增加。和增量間隔一樣,都是想讓失敗次數越多的重試請求優先級排到越后面,只不過這個方案的增長幅度更大一些;
return2^retryCount;
策略 5 - 全抖動: 在遞增的基礎上,增加隨機性(可以把其中的指數增長部分替換成增量增長。)適用于將某一時刻集中產生的大量重試請求進行壓力分散的場景;
returnrandom(0,2^retryCount);
策略 6 - 等抖動: 在「指數間隔」和「全抖動」之間尋求一個中庸的方案,降低隨機性的作用。適用場景和「全抖動」一樣。
intbaseNum=2^retryCount; returnbaseNum+random(0,baseNum);
策略 - 3、4、5、6 的表現情況大致是這樣(x軸為重試次數):
3、重試時的注意事項
首先對于需要重試的接口,是需要做成冪等性的,即不能因為服務的多次調用而導致業務數據的累計增加或減少。
滿足「冪等性」其實就是需要想辦法識別重復的請求,并且將其過濾掉。思路就是:
給每個請求定義一個唯一標識。
在進行「重試」的時候判斷這個請求是否已經被執行或者正在被執行,如果是則拋棄該請求。
Ps:此外重試特別適合在高負載情況下被降級,當然也應當受到限流和熔斷機制的影響。當重試的“矛”與限流和熔斷的“盾”搭配使用,效果才是最好。
四、業務補償機制的注意事項
1、ACID 還是 BASE
ACID 和 BASE 是分布式系統中兩種不同級別的一致性理論,在分布式系統中,ACID有更強的一致性,但可伸縮性非常差,僅在必要時使用;BASE的一致性較弱,但有很好的可伸縮性,還可以異步批量處理;大多數分布式事務適合 BASE。
而在重試或回滾的場景下,我們一般不會要求強一致性,只要保證最終一致性就可以了!
2、業務補償設計的注意事項
業務補償設計的注意事項:
因為要把一個業務流程執行完成,需要這個流程中所涉及的服務方支持冪等性。并且在上游有重試機制;
我們需要小心維護和監控整個過程的狀態,所以,千萬不要把這些狀態放到不同的組件中,最好是一個業務流程的控制方來做這個事,也就是一個工作流引擎。所以,這個工作流引擎是需要高可用和穩定的;
補償的業務邏輯和流程不一定非得是嚴格反向操作。有時候可以并行,有時候,可能會更簡單。總之,設計業務正向流程的時候,也需要設計業務的反向補償流程;
我們要清楚地知道,業務補償的業務邏輯是強業務相關的,很難做成通用的;
下層的業務方最好提供短期的資源預留機制。就像電商中的把貨品的庫存預先占住等待用戶在 15 分鐘內支付。如果沒有收到用戶的支付,則釋放庫存。然后回滾到之前的下單操作,等待用戶重新下單。
審核編輯:劉清
-
數據傳輸
+關注
關注
9文章
1853瀏覽量
64499 -
交換機
+關注
關注
21文章
2624瀏覽量
99288 -
路由器
+關注
關注
22文章
3709瀏覽量
113569 -
DNS
+關注
關注
0文章
217瀏覽量
19803
原文標題:淺談分布式系統中的補償機制設計問題
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
突破傳統監測模式:業務狀態監控HM的新思路

無功補償隨機補償和隨器補償的區別






 工商網監
工商網監
評論