") StrucTexTv2:端到端文檔圖像理解預(yù)訓(xùn)練框架
StrucTexTv2:端到端文檔圖像理解預(yù)訓(xùn)練框架
本文簡(jiǎn)要介紹ICLR 2023錄用論文“StrucTexTv2: Masked Visual-Textual Prediction for Document Image Pre-training”的主要工作。針對(duì)當(dāng)前主流多模態(tài)文檔理解預(yù)訓(xùn)練模型需要同時(shí)輸入文檔圖像和OCR結(jié)果,導(dǎo)致欠缺端到端的表達(dá)能力且推理效率偏低等問題,論文提出了一種全新的端到端文檔圖像多模態(tài)表征學(xué)習(xí)預(yù)訓(xùn)練框架StrucTexTv2。該框架設(shè)計(jì)了一種基于詞粒度圖像區(qū)域掩碼、多模態(tài)自監(jiān)督預(yù)訓(xùn)練任務(wù)(MIM+MLM),僅需要圖像單模態(tài)輸入,使得編碼器網(wǎng)絡(luò)能在大規(guī)模無標(biāo)注文檔圖像上充分學(xué)習(xí)視覺和語言聯(lián)合特征表達(dá),并在多個(gè)下游任務(wù)的公開基準(zhǔn)上取得SOTA效果。
一、研究背景
視覺富文檔理解技術(shù)例如文檔分類、版式分析、表單理解、OCR以及信息提取,逐漸成為文檔智能領(lǐng)域一個(gè)熱門研究課題。為了有效處理這些任務(wù),前沿的方法大多利用視覺和文本線索,將圖像、文本、布局等信息輸入到參數(shù)網(wǎng)絡(luò),并基于大規(guī)模數(shù)據(jù)上的自監(jiān)督預(yù)訓(xùn)練挖掘出文檔的多模態(tài)特征。由于視覺和語言之間的模態(tài)差異較大,如圖1所示,主流的文檔理解預(yù)訓(xùn)練方法大致可分為兩類:a)掩碼語言建模(Masked Language Modeling)[9],對(duì)輸入的掩碼文本Token進(jìn)行語言建模,運(yùn)行時(shí)文本的獲取依賴于OCR引擎,整個(gè)系統(tǒng)的性能提升需要對(duì)OCR引擎和文檔理解模型兩個(gè)部件進(jìn)行同步優(yōu)化;b)掩碼圖像建模(Masked Image Modeling)[10],對(duì)輸入的掩碼圖像塊區(qū)進(jìn)行像素重建,此類方法傾向應(yīng)用于圖像分類和版式分析等任務(wù)上,對(duì)文檔強(qiáng)語義理解能力欠佳。針對(duì)上述兩種預(yù)訓(xùn)練方案呈現(xiàn)的瓶頸,本文提出了StrucTexTv2:c)統(tǒng)一圖像重建與語言建模方式,在大規(guī)模文檔圖像上學(xué)習(xí)視覺和語言聯(lián)合特征表達(dá)。
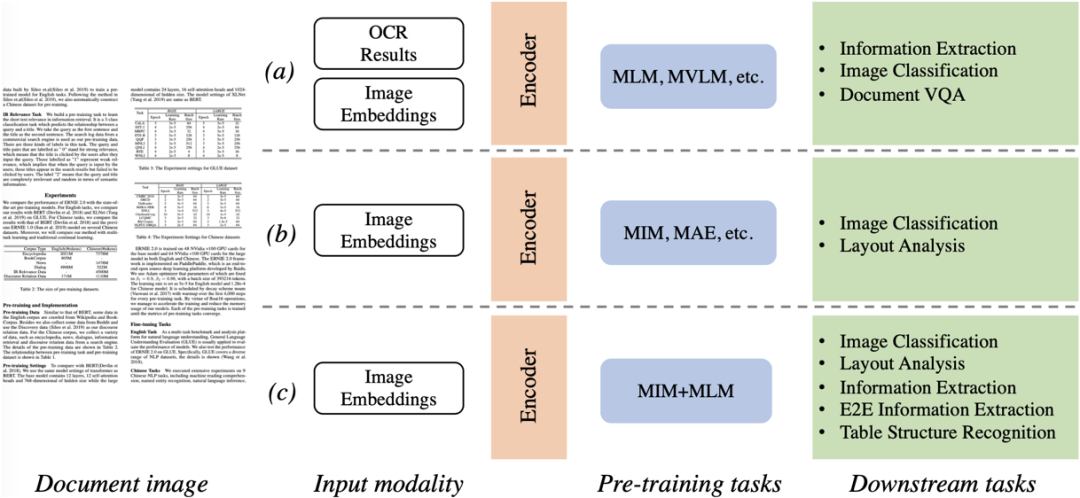
圖1 主流文檔圖像理解預(yù)訓(xùn)練框架比較
二、方法原理簡(jiǎn)述
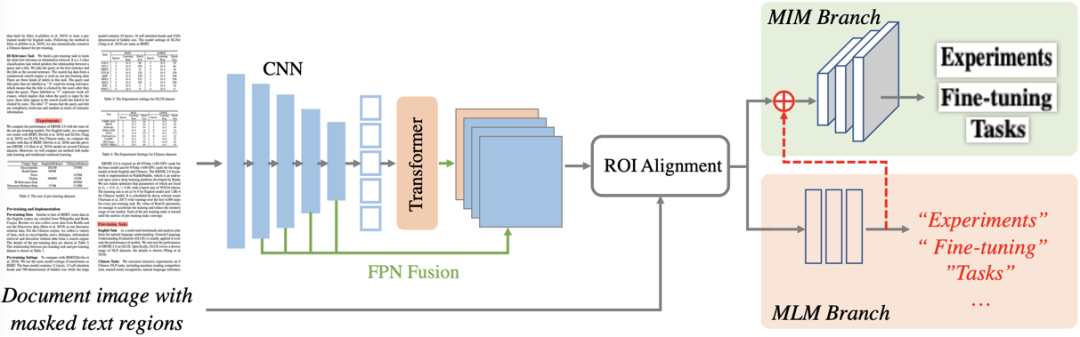
圖2 整體框架圖
圖2描繪了StrucTexTv2的整體框架,主要包含編碼器網(wǎng)絡(luò)和預(yù)訓(xùn)練任務(wù)分支兩部分。編碼器網(wǎng)絡(luò),主要通過FPN結(jié)構(gòu)串聯(lián)CNN組件和Transformer組件構(gòu)成;預(yù)訓(xùn)練分支則包含了掩碼語言建模(MLM)和掩碼圖像建模(MIM)雙預(yù)訓(xùn)練任務(wù)頭。
2.1 編碼器網(wǎng)絡(luò)
StrucTexTv2采用CNN和Transformer的串聯(lián)編碼器來提取文檔圖像的視覺和語義特征。文檔圖像首先經(jīng)過ResNet網(wǎng)絡(luò)以獲取1/4到1/32的四個(gè)不同尺度的特征圖。隨后采用一個(gè)標(biāo)準(zhǔn)的Transformer網(wǎng)絡(luò)接收最小尺度的特征圖并加上1D位置編碼向量,提取出包含全局上下文的語義特征。該特征被重新轉(zhuǎn)化為2D形態(tài)后,與CNN的其余三個(gè)尺度特征圖通過FPN[6]融合成4倍下采樣的特征圖,作為整圖的多模態(tài)特征表示。
2.2 預(yù)訓(xùn)練策略
為了統(tǒng)一建模MLM和MIM兩種模態(tài)預(yù)訓(xùn)練方式,論文提出了一種基于詞粒度圖像區(qū)域掩碼預(yù)測(cè)方式來學(xué)習(xí)視覺和語言聯(lián)合特征表達(dá)。首先,隨機(jī)篩選30%的詞粒度OCR預(yù)測(cè)結(jié)果(僅在預(yù)訓(xùn)練階段使用),根據(jù)OCR的位置信息直接在原圖對(duì)應(yīng)位置像素進(jìn)行掩碼操作(比如填充0值)。接著,掩碼后的文檔圖像直接送入編碼器網(wǎng)絡(luò)去獲得整圖的多模態(tài)特征表示。最后,再次根據(jù)選中的OCR位置信息,采用ROIAlign[11]操作去獲得每個(gè)掩碼區(qū)域的多模態(tài)ROI特征。
掩碼語言建模:借鑒于BERT[9]構(gòu)建的掩碼語言模型思路,語言建模分支使用一個(gè)2層的MLP將詞區(qū)域的ROI特征映射到預(yù)定義的詞表類別上,使用Cross Entropy Loss監(jiān)督。同時(shí)為了避免使用詞表對(duì)文本序列進(jìn)行標(biāo)記化時(shí)單個(gè)詞組被拆分成多個(gè)子詞導(dǎo)致的一對(duì)多匹配問題,論文使用分詞后每個(gè)單詞的首個(gè)子詞作為分類標(biāo)簽。此設(shè)計(jì)帶來的優(yōu)勢(shì)是:StrucTexTv2的語言建模無需文本作為輸入。
掩碼圖像建模:考慮到基于圖像Patch的掩碼重建在文檔預(yù)訓(xùn)練中展現(xiàn)出一定的潛力,但Patch粒度的特征表示難以恢復(fù)文本細(xì)節(jié)。因此,論文將詞粒度掩碼同時(shí)用作圖像重建,即預(yù)測(cè)被掩碼區(qū)域的原始像素值。詞區(qū)域的ROI特征首先通過一個(gè)全局池化操作被壓縮成特征向量。其次,為了提升圖像重建的視覺效果,論文將通過語言建模后的概率特征與池化特征進(jìn)行拼接,為圖像建模引入“Content”信息,使得圖像預(yù)訓(xùn)練專注于復(fù)原文本區(qū)域的“Style”部分。圖像建模分支由3個(gè)全卷積 Block構(gòu)成。每個(gè)Block包含一個(gè)Kernel=2×2,Stride=4的反卷積層,一個(gè)Kernel=1×1,以及兩個(gè)Kernel=3×1卷積層。最后,每個(gè)單詞的池化向量被映射成一個(gè)大小為64×64×3的圖像,并逐像素與原本的圖像區(qū)域做MSE Loss。
論文提供了Small和Large兩種參數(shù)規(guī)格的模型,并在IIT-CDIP數(shù)據(jù)集上使用百度通用高精OCR的文字識(shí)別結(jié)果預(yù)訓(xùn)練編碼網(wǎng)絡(luò)。
三、實(shí)驗(yàn)結(jié)果
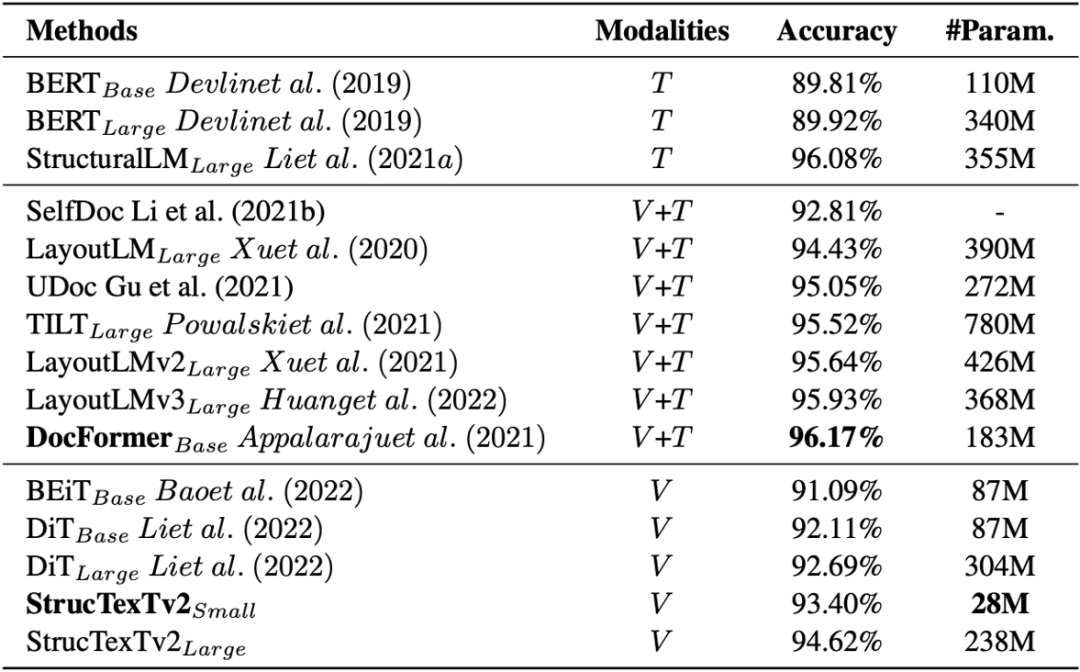
論文在四個(gè)基準(zhǔn)數(shù)據(jù)集上測(cè)試模型對(duì)文檔理解的能力,在五個(gè)下游任務(wù)上使用不同的Head進(jìn)行Fine-tune并給出實(shí)驗(yàn)結(jié)論。表1給出模型在RVL-CDIP[13]驗(yàn)證文檔圖像分類的效果。同比基于圖像單模態(tài)輸入的方法DiT[4],StrucTexTv2以更少的參數(shù)量取得了更優(yōu)的分類精度。
表1 RVL-CDIP數(shù)據(jù)集上文檔圖像分類的實(shí)驗(yàn)結(jié)果
如表2和表3所示,論文結(jié)合預(yù)訓(xùn)練模型和Cascade R-CNN[1]框架fine-tune去檢測(cè)文檔中的版式元素以及表格結(jié)構(gòu),在PubLaynet[8]以及WWW[12]數(shù)據(jù)集上取得了當(dāng)前的最好性能。
表2 PubLaynet數(shù)據(jù)集上版式分析的檢測(cè)結(jié)果
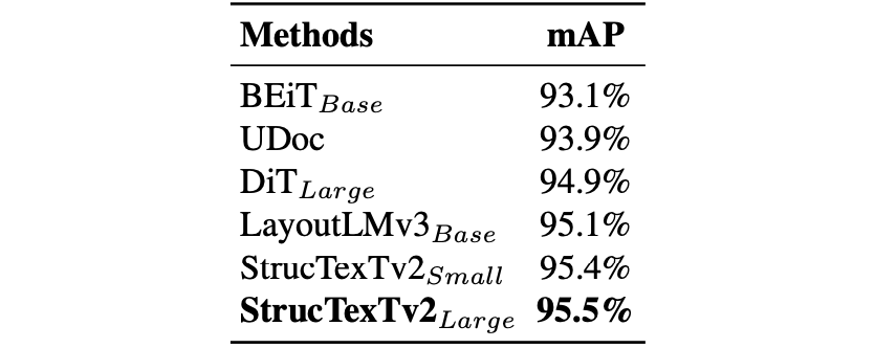
表3 WWW數(shù)據(jù)集上表格結(jié)構(gòu)識(shí)別的性能對(duì)比

在表4中,論文同時(shí)在FUNSD[3]數(shù)據(jù)集上進(jìn)行了端到端OCR和信息提取兩項(xiàng)實(shí)驗(yàn),在基準(zhǔn)測(cè)試中都取得了同期最優(yōu)的效果。對(duì)比如StrucTexTv1[5]和LayoutLMv3[2]等OCR+文檔理解的兩階段方法,證明了提出方法端到端優(yōu)化的優(yōu)越性。
表4 FUNSD數(shù)據(jù)集上端到端OCR以及信息抽取實(shí)驗(yàn)

接下來,論文對(duì)比了SwinTransformer[7]、ViT[10]以及StrucTexTv2的編碼網(wǎng)絡(luò)。從表5對(duì)比結(jié)果來看,論文提出CNN+Transformer的串聯(lián)結(jié)構(gòu)更有效地支持預(yù)訓(xùn)練任務(wù)。同時(shí),論文給出了不同預(yù)訓(xùn)練配置的模型在文檔圖像分類和版式分析的性能增益,對(duì)兩種模態(tài)預(yù)訓(xùn)練進(jìn)行了有效性驗(yàn)證。
表5 預(yù)訓(xùn)練任務(wù)以及編碼器結(jié)構(gòu)的消融實(shí)驗(yàn)
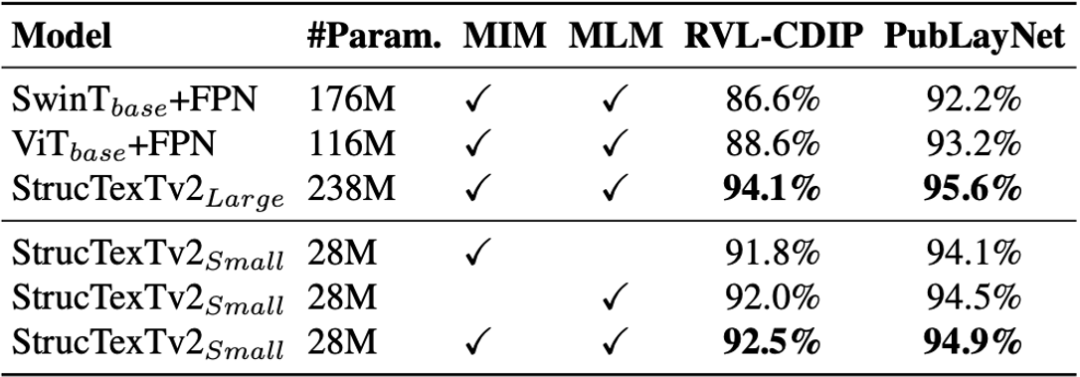
同時(shí),論文中評(píng)估了模型在預(yù)測(cè)時(shí)的耗時(shí)和顯存開銷。表6中給出了兩種OCR引擎帶來的開銷以及并與現(xiàn)階段最優(yōu)的多模態(tài)方法LayoutLMv3進(jìn)行了比較。
表6 與兩階段的方法LayoutLMv3的資源開銷對(duì)比
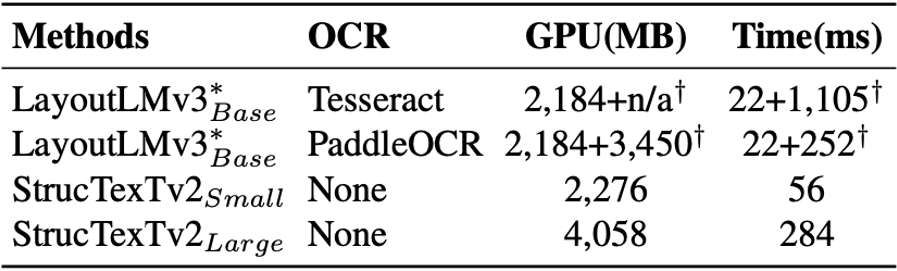
最后,論文評(píng)估了表7所示在圖像重建預(yù)訓(xùn)練中使用不同的掩碼方式對(duì)下游任務(wù)的影響。在RVL-CDIP和PubLaynet兩個(gè)數(shù)據(jù)集上,基于詞粒度掩碼的策略可以獲取到更有效的視覺語義特征,確保更好的性能。
表7 預(yù)訓(xùn)練任務(wù)以及編碼器結(jié)構(gòu)的消融實(shí)驗(yàn)

總結(jié)及討論
論文出的StructTexTv2模型用于端到端學(xué)習(xí)文檔圖像的視覺和語言聯(lián)合特征表達(dá),圖像單模態(tài)輸入條件下即可實(shí)現(xiàn)高效的文檔理解。論文提出的預(yù)訓(xùn)練方法基于詞粒度的圖像掩碼,能同時(shí)預(yù)測(cè)相應(yīng)的視覺和文本內(nèi)容,此外,所提出的編碼器網(wǎng)絡(luò)能夠更有效地挖掘大規(guī)模文檔圖像信息。實(shí)驗(yàn)表明,StructTexTv2在模型大小和推理效率方面對(duì)比之前的方法都有顯著提高。更多的方法原理介紹和實(shí)驗(yàn)細(xì)節(jié)請(qǐng)參考論文原文。
審核編輯 :李倩
-
圖像
+關(guān)注
關(guān)注
2文章
1083瀏覽量
40418 -
OCR
+關(guān)注
關(guān)注
0文章
144瀏覽量
16330
原文標(biāo)題:ICLR 2023 | StrucTexTv2:端到端文檔圖像理解預(yù)訓(xùn)練框架
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
爆火的端到端如何加速智駕落地?
連接視覺語言大模型與端到端自動(dòng)駕駛

端到端讓智駕強(qiáng)者愈強(qiáng)時(shí)代來臨?
端到端InfiniBand網(wǎng)絡(luò)解決LLM訓(xùn)練瓶頸

端到端測(cè)試用例怎么寫
端到端測(cè)試不正常如何處理
恩智浦完整的Matter端到端解決方案
單端預(yù)端接光纜怎么接
實(shí)現(xiàn)自動(dòng)駕駛,唯有端到端?

大語言模型的預(yù)訓(xùn)練
小鵬汽車發(fā)布端到端大模型
【大語言模型:原理與工程實(shí)踐】大語言模型的預(yù)訓(xùn)練
佐思汽研發(fā)布《2024年端到端自動(dòng)駕駛研究報(bào)告》

理想汽車自動(dòng)駕駛端到端模型實(shí)現(xiàn)

移動(dòng)協(xié)作機(jī)器人的RGB-D感知的端到端處理方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論